论文阅读: Disentangled lmage Colorization via Global Anchors
Disentangled lmage Colorization via Global Anchors发表于SIGGRAPH ASIA 2022,是一篇基于深度学习的图像彩色化的工作,简单介绍一下。之前曾分享过一篇彩色化的经典论文:经典论文回顾: Colorization using Optimization。 作者认为图像彩色化是一个多模态的问题,也就是同一个物体可以被着色成多种颜色,只要合理即可。现有基于深度学习的算法存在一个很严重的问题就是颜色不一致,如下的teaser所示, 注意其它几个算法在公交车上以及男士的衣服上的着色效果,可以看出一致性较差。
之所以容易出现这种颜色不一致的问题,主要的原因就是之前的方法独立的预测每一个像素的颜色,没有考虑像素间的相似性。为此本文将彩色化的问题分为两个阶段,首先预测图像中的锚点(color anchors)的颜色,然后将锚点的颜色传播到图像的其他区域。
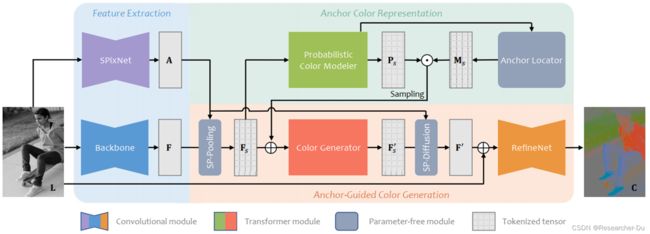
一、网络结构
本文的网络如下所示, 网络工作在LAB颜色空间,是一个有监督学习,输入是彩色图像的灰度图(L通道),需要预测图像的颜色(ab通道),最后合成彩色图像(Lab = 输入的L + 预测的ab)。网络分为三个模块:
- 为了降低复杂度,先使用SpixNet对输入图像进行超像素分割;
- 使用transformer网络预测超像素的颜色分布,使用聚类的算法提取代表性的超像素作为锚点,保留锚点颜色,mask掉非锚点的超像素;
- 使用transformer,根据锚点颜色预测其它超像素的颜色,并通过超像素的颜色恢复出图像逐像素的颜色,得到输出的彩色图。
二、超像素分割
作者认为图像包含大量像素且像素间存在高度相关性,为了降低计算复杂度以及提升后续的着色一致性,可以先将图像进行超像素分割。本文使用的SpixNet来自于 SpixNet: Yang et al. Superpixel Segmentation With Fully Convolutional Networks, CVPR 2020. 输出为一个Soft association map:
A ∈ R H × W × ∣ N p ∣ \mathbf{A} \in \mathbb{R}^{H \times W \times\left|\mathcal{N}_{p}\right|} A∈RH×W×∣Np∣
即输出每个像素属于周围 N p = 9 \mathcal{N}_{p}=9 Np=9 个超像素的可能性,且 ∑ s ∈ N p A ( p , s ) = 1 \sum_{\mathrm{s} \in \mathcal{N}_{p}} \mathrm{~A}(\mathrm{p}, \mathrm{s})=1 ∑s∈Np A(p,s)=1。
- SP-Pooling
基于此,对于每一个超像素 s s s, 可以统计有多少像素对其有贡献(即 A ( p , s ) > 0 A(p,s)>0 A(p,s)>0), 并计算超像素 s s s 中心的特征和位置。这个过程称为SP-Pooling,输入是SpixNet输出的Soft association map A A A 以及 通过CNN 提取到的图像特征 F F F. SP-Pooling 定义为:
v s = ∑ p ∈ P s F ( p ) ⋅ A ( p , s ) ∑ p ∈ P s A ( p , s ) , l s = ∑ p ∈ P s p ⋅ A ( p , s ) ∑ p ∈ P s A ( p , s ) (1) \mathbf{v}_{s}=\frac{\sum_{\mathbf{p} \in \mathcal{P}_{s}} \mathbf{F}(\mathbf{p}) \cdot \mathbf{A}(\mathbf{p}, \mathbf{s})}{\sum_{\mathbf{p} \in \mathcal{P}_{s}} \mathbf{A}(\mathbf{p}, \mathbf{s})}, \quad \mathbf{l}_{s}=\frac{\sum_{\mathbf{p} \in \mathcal{P}_{s}} \mathbf{p} \cdot \mathbf{A}(\mathbf{p}, \mathbf{s})}{\sum_{\mathbf{p} \in \mathcal{P}_{s}} \mathbf{A}(\mathbf{p}, \mathbf{s}) \tag1} vs=∑p∈PsA(p,s)∑p∈PsF(p)⋅A(p,s),ls=∑p∈PsA(p,s)∑p∈Psp⋅A(p,s)(1)
- SP-Diffusion
反过来,如果已知每个超像素的中心特征和位置 以及 Soft association map A A A , 也可以恢复出每个像素的特征(比如颜色)和位置,这个过程称为SP-Diffusion, 定义为:
F ~ ( p ) = ∑ s ∈ N p v S ⋅ A ( p , s ) , p ~ ( p ) = ∑ s ∈ N p l s ⋅ A ( p , s ) (2) \tilde{\mathbf{F}}(\mathbf{p})=\sum_{\mathbf{s} \in \mathcal{N}_{p}} \mathbf{v}_{S} \cdot \mathbf{A}(\mathbf{p}, \mathbf{s}), \quad \tilde{\mathbf{p}}(\mathbf{p})=\sum_{\mathbf{s} \in \mathcal{N}_{p}} \mathbf{l}_{s} \cdot \mathbf{A}(\mathbf{p}, \mathbf{s} \tag2) F~(p)=s∈Np∑vS⋅A(p,s),p~(p)=s∈Np∑ls⋅A(p,s)(2)
之后就是预测出每个超像素中心的颜色,然后通过上述公式恢复出图像中其他像素的颜色。
这部分是预先预先训练的,所以一并给出其损失函数:
L a g g r = 1 N ∑ p ∥ C g t ( p ) − C ~ g t ( p ) ∥ 2 + α S ∥ p − p ~ ∥ 2 (3) \mathcal{L}_{aggr}=\frac{1}{N} \sum_{\mathbf{p}}\left\|\mathbf{C}^{g t}(\mathbf{p})-\tilde{\mathbf{C}}^{g t}(\mathbf{p})\right\|_{2}+\frac{\alpha}{S}\|\mathbf{p}-\tilde{\mathbf{p}}\|_{2} \tag3 Laggr=N1p∑∥∥∥Cgt(p)−C~gt(p)∥∥∥2+Sα∥p−p~∥2(3)
其中, C g t \mathbf{C}^{g t} Cgt 和 p \mathbf{p} p 表示graound truth图像每个像素的颜色 和 位置。 C g t ( p ) \mathbf{C}^{g t}(\mathbf{p}) Cgt(p) 和 p ~ \tilde{\mathbf{p}} p~ 表示根据 Soft association map A A A 和 超像素中心的真实颜色和位置恢复出的逐像素的颜色和位置。上述loss主要考虑这两方面的误差,期望获得更准确的超像素分割,完美的重建图像。
三、锚点颜色预测
通过transformer模型 Probabilistic Color Modeler 生成所有超像素可能的颜色的概率分布,输出是:
P s ∈ R H ~ × W ~ × 313 \mathbf{P}_{s} \in \mathbb{R}^{\tilde{H} \times \tilde{W} \times 313} Ps∈RH~×W~×313
即每个超像素最多只有313种可能的颜色(将ab通道量化为313种颜色),这里给出每个超像素属于这313种颜色的概率分布。比如人脸属于黄色,黑色,白色的可能性大一些,而属于绿色,蓝色可能性为0.
接下来对这些超像素进行聚类,将每个簇中尺寸最大的超像素作为该簇的锚点, 然后mask掉所有非锚点的超像素。
P a = P s ⊙ M s (4) \mathbf{P}_{a}=\mathbf{P}_{s} \odot \mathbf{M}_{s}\tag4 Pa=Ps⊙Ms(4)
接下来通过采样或认为指定的方式采样每一个锚点超像素的颜色 C s a C^a_s Csa。下一步的工作就是根据锚点超像素预测哪些被mask掉的超像素的颜色。
为什么要这么做呢?为什么不是直接在所有的超像素上采样颜色,而只是在部分锚点超像素上采样颜色,再到下一步预测别的超像素的颜色?其中一个主要的原因就是直接在超像素上采样颜色的话很可能造成颜色不一致,也就是说属于同一个object的超像素很可能采样到不同或者差异很大的颜色。
这一部分的损失函数主要度量 Probabilistic Color Modeler 预测的超像素的颜色的好坏:
L d i s t = 1 N ~ ∑ s − P s g t ( s ) log P s ( s ) (5) \mathcal{L}_{d i s t}=\frac{1}{\tilde{N}} \sum_{\mathbf{s}}-\mathbf{P}_{s}^{g t}(\mathbf{s}) \log \mathbf{P}_{s}(\mathbf{s})\tag5 Ldist=N~1s∑−Psgt(s)logPs(s)(5)
其中, P s \mathbf{P}_{s} Ps 表示预测的某个超像素的颜色分布(313维的向量), P s g t \mathbf{P}_{s}^{g t} Psgt 表示将 GT经过SpixNet后,每一个超像素的中心的真实颜色转换成one-hot向量的结果。 这里是一个交叉熵损失,主要度量超像素预测的颜色是或合理,比如人脸上的超像素预测黄色、白色、黑色概率大是合理的,但如果预测数来红色概率大,那就不合理了。
四、彩色图像生成
最后一部分通过Color Generator模型生成所有超像素中心的颜色,这也是一个transformer的模型,优点自然是可以考虑超像素间的相似性,将锚点超像素的颜色传播到其他mask掉的超像素。然后通过公式(2)所示的SP-Diffusion操作,反算出图像逐像素的颜色(注意这里输出的是ab通道),然后将输入图像的L通道 + 此处预测出的ab通道,合成一张彩色图像。最后,使用RefineNet对图像进行简单优化得到最终结果。
这一部分损失函数如下所示,需要注意的是,因为彩色化是一个一对多的问题,没有正确答案,因此只是度量感知距离,而非生成结果跟GT图像的视觉差异。详细参见论文。
L color = 1 N ~ ∑ s − P s g t ( s ) log P s ′ ( s ) + β ∑ l ω l ∥ Φ l ( C g t ) − Φ l ( C ) ∥ 1 (6) \mathcal{L}_{\text {color }}=\frac{1}{\tilde{N}} \sum_{s}-\mathbf{P}_{s}^{g t}(\mathbf{s}) \log \mathbf{P}_{s}^{\prime}(\mathbf{s})+\beta \sum_{l} \omega_{l}\left\|\Phi_{l}\left(\mathbf{C}^{g t}\right)-\Phi_{l}(\mathbf{C})\right\|_{1}\tag6 Lcolor =N~1s∑−Psgt(s)logPs′(s)+βl∑ωl∥∥Φl(Cgt)−Φl(C)∥∥1(6)
网络是在IMAGENET上训练,每张图像既有灰度图又有彩色图。训练过程中,先训练SpixNet,然后固定之,端到端训练网络中另外两个model。
五、实验结果
定性分析:本文结果好很多,但细节仍有待改进。
定量分析:只需关注FID,Colorfulness两个指标,这是度量感知距离的,其余指标不太具有参考性。

六、简单总结
- 本文将彩色化问题分解为两个阶段:代表性锚点超像素颜色预测 和 图像其他超像素颜色预测,实现了较好的一致性。
- 缺点是锚点数量固定,使得object较多的图像比如毕业照或人群图像,彩色化结果颜色会比较单调。