使用Tesseract+OpenCV+Python进行光学字符识别 (OCR)

介绍
我们人类几乎每时每刻都在阅读文本。如果我们的机器或系统也能像我们一样阅读文本,那不是很好吗?但更大的问题是“我们如何让我们的机器阅读”?这就是光学字符识别 (OCR) 出现的地方。
光学字符识别 (OCR)
光学字符识别 (OCR) 是一种从打印或扫描的照片、手写图像中读取或抓取文本并将其转换为可编辑和可搜索的数字格式的技术。
应用
OCR 在当今的业务中有很多应用。下面列出了其中的一些:
机场护照识别
数据录入自动化
车牌识别
将名片信息提取到联系人列表中
将手写文档转换为电子图像
创建可搜索的 PDF
创建可听文件(文本到音频)
一些开源 OCR 工具是 Tesseract、OCRopus。
Tesseract:https://en.wikipedia.org/wiki/Tesseract_(software)
OCRopus:https://en.wikipedia.org/wiki/OCRopus
在本文中,我们将重点介绍 Tesseract OCR。为了读取图像,我们需要 OpenCV。
Tesseract OCR 的安装
从“ https://github.com/UB-Mannheim/tesseract/wiki ”下载最新的 Windows 10 安装程序。下载后执行 .exe 文件。
注意:不要忘记复制文件软件安装路径。我们稍后会需要它,因为如果安装目录与默认目录不同,我们需要在代码中添加 tesseract 可执行文件的路径。
Windows 系统中典型的安装路径是C:Program Files。
所以,就我而言,它是“ C: Program FilesTesseract-OCRtesseract.exe ”。
接下来,要安装 Tesseract 的 Python 包装器,请打开命令提示符并执行命令“ pip install pytesseract ”。
OpenCV
OpenCV(开源计算机视觉)是一个用于计算机视觉、机器学习和图像处理应用程序的开源库。
OpenCV-Python 是 OpenCV 的 Python API。
要安装它,请打开命令提示符并执行命令“ pip install opencv-python ”。
构建示例 OCR 脚本
1. 读取示例图像
import cv2
使用 cv2.imread() 方法读取图像并将其存储在变量“img”中。
img = cv2.imread("image.jpg")
如果需要,使用 cv2.resize() 方法调整图像大小
img = cv2.resize(img, (400, 400))
使用 cv2.imshow() 方法显示图像
cv2.imshow("Image", img)
无限显示窗口(防止内核崩溃)
cv2.waitKey(0)
关闭所有打开的窗口
cv2.destroyAllWindows()
2. 图像转字符串
import pytesseract
在代码中设置tesseract路径
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
如果我们不设置路径,则会发生以下错误。

要将图像转换为字符串,请使用 pytesseract.image_to_string(img) 并将其存储在变量“text”中
text = pytesseract.image_to_string(img)
打印结果
print(text)
完整代码:
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
img = cv2.imread("image.jpg")
img = cv2.resize(img, (400, 450))
cv2.imshow("Image", img)
text = pytesseract.image_to_string(img)
print(text)
cv2.waitKey(0)
cv2.destroyAllWindows()
上述代码的输出:
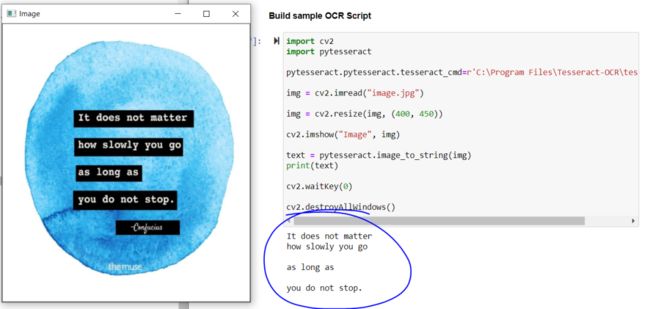
如果我们观察输出,可以完美地提取主要的语句,但没有获得哲学家的名字和图像最底部的文字。
为了准确提取文本,避免精度下降,我们需要对图像进行一些预处理。我发现这篇文章 (https://towardsdatascience.com/pre-processing-in-ocr-fc231c6035a7) 很有帮助。请参阅它以更好地理解预处理技术。
现在我们已经掌握了所需的基础知识,让我们来看看 OCR 的一些简单应用。
1. 在评论图片上构建词云
词云是词频的直观表示。词云中出现的词越大,该词在文本中的使用频率越高。
为此,我截了一些亚马逊对 Apple iPad 8th Generation 的评论图。
示例图像

步骤:
创建所有可用评论图像的列表
如果需要,使用 cv2.imshow() 方法查看图像
使用 pytesseract 从图像中读取文本
创建数据框
预处理文本——去除特殊字符、停用词
构建正面、负面的词云
步骤 1:创建所有可用评论图像的列表
import os
folderPath = "Reviews"
myRevList = os.listdir(folderPath)
步骤 2:如果需要,使用 cv2.imshow() 方法查看图像
for image in myRevList:
img = cv2.imread(f'{folderPath}/{image}')
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
步骤 3 :使用 pytesseract 从图像中读取文本
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
corpus = []
for images in myRevList:
img = cv2.imread(f'{folderPath}/{images}')
if img is None:
corpus.append("Could not read the image.")
else:
rev = pytesseract.image_to_string(img)
corpus.append(rev)
list(corpus)
corpus
上面代码的输出:

步骤 4 :创建数据框
import pandas as pd
data = pd.DataFrame(list(corpus), columns=['Review'])
data

步骤5:预处理文本——去除特殊字符、停用词
#removing special characters
import re
def clean(text):
return re.sub('[^A-Za-z0-9" "]+', ' ', text)
data['Cleaned Review'] = data['Review'].apply(clean)
data

从“Cleaned Review”中删除停用词并将所有剩余的词附加到列表变量“final_list”中。
# removing stopwords import nltk from nltk.corpus import stopwords nltk.download("punkt") from nltk import word_tokenize stop_words = stopwords.words('english') final_list = [] for column in data[['Cleaned Review']]: columnSeriesObj = data all_rev = columnSeriesObj.values for i in range(len(all_rev)): tokens = word_tokenize(all_rev[i]) for word in tokens: if word.lower() not in stop_words: final_list.append(word)
步骤6:构建正面、负面的词云
使用命令“ pip install wordcloud ”安装词云库。
在英语中,我们有一组预定义的正面和负面词,称为 Opinion Lexicons。这些文件可以从链接(https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html)下载
或直接从我的GitHub 存储库下载(https://github.com/harika-bonthu/Pytesseract/tree/main/opinion-lexicon-English)
下载文件后,阅读代码中的这些文件并创建正面词和负面词的列表。
with open(r"opinion-lexicon-Englishpositive-words.txt","r") as pos:
poswords = pos.read().split("n")
with open(r"opinion-lexicon-Englishnegative-words.txt","r") as neg:
negwords = neg.read().split("n")
导入库以生成和显示词云。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
正面词云
# Choosing the only words which are present in poswords
pos_in_pos = " ".join([w for w in final_list if w in poswords])
wordcloud_pos = WordCloud(
background_color='black',
width=1800,
height=1400
).generate(pos_in_pos)
plt.imshow(wordcloud_pos)

“good”这个词是最常用的词,引起了我们的注意。如果我们回顾一下评论,人们会写评论说 iPad 具有良好的显示效果、良好的声音、良好的软件和硬件。
负面词云
# Choosing the only words which are present in negwords
neg_in_neg = " ".join([w for w in final_list if w in negwords])
wordcloud_neg = WordCloud(
background_color='black',
width=1800,
height=1400
).generate(neg_in_neg)
plt.imshow(wordcloud_neg)
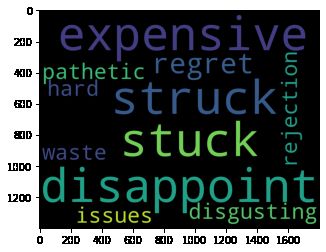
expensive、struck、stuck、disappoint等词在负面词云中脱颖而出。如果我们查看stuck(卡住)这个词的上下文,它会是“虽然它只有 3 GB 内存,但它永远不会卡住”,这对设备来说是一件好事。
因此,构建二元/三元词云以避免错过上下文也很重要。
2. 创建音频文件(文本到音频)
gTTS 是一个带有 Google Translate 的文本到语音 API 的 Python 库。
要安装,请在命令提示符下执行命令“ pip install gtts ”。
导入必要的库
import cv2
import pytesseract
from gtts import gTTS
import os
设置tesseract路径
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
使用 cv2.imread() 读取图像并使用 pytesseract 从图像中获取文本并将其存储在变量中。
rev = cv2.imread("Reviews\15.PNG")
# display the image using cv2.imshow() method
# cv2.imshow("Image", rev)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# grab the text from image using pytesseract
txt = pytesseract.image_to_string(rev)
print(txt)
设置语言并使用 gTTS 绕过文本、语言创建将文本转换为音频
language = 'en'
outObj = gTTS(text=txt, lang=language, slow=False)
将音频文件另存为“rev.mp3”
outObj.save("rev.mp3")
播放音频文件
os.system('rev.mp3')

完整代码:
import cv2 import pytesseract from gtts import gTTS import os rev = cv2.imread("Reviews\15.PNG") # cv2.imshow("Image", rev) # cv2.waitKey(0) # cv2.destroyAllWindows() txt = pytesseract.image_to_string(rev) print(txt) language = 'en' outObj = gTTS(text=txt, lang=language, slow=False) outObj.save("rev.mp3") print('playing the audio file') os.system('rev.mp3')
尾注
到本文结束时,我们已经了解了光学字符识别 (OCR) 的概念,并且熟悉了使用 OpenCV 读取图像和使用 pytesseract 从图像中抓取文本。我们已经看到了 OCR 的两个基本应用 - 构建词云,通过使用 gTTS 将文本转换为语音来创建可听文件。
参考
gTTS 文档:https://gtts.readthedocs.io/en/latest/
OpenCV 文档:https://docs.opencv.org/4.5.2/d6/d00/tutorial_py_root.html
pytesseract 文档:https://pytesseract.readthedocs.io/en/latest/
从我的GitHub 存储库查看完整的 Jupyter Notebook:https://github.com/harika-bonthu/Pytesseract/blob/main/OCR.ipynb
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
