机器学习(一)——线性回归介绍及案例实战(Python实现)
目录
前言
一、线性模型介绍
二、一元线性回归
1、介绍
2、案例
3、模型优化
总结
前言
线性回归模型是机器学习中非常基础且经典的模型,是利用线性拟合的方式探寻数据背后的规律,特征变量的个数可将线性回归模型分为一元线性回归和多元线性回归。
一、线性模型介绍
其实线性模型的原型是我们非常熟悉的一元一次方程(一元线性回归),二元一次方程等函数。“元”的概念就是指自变量,在线性模型中,特征变量是自变量的大名,反应变量是因变量的大名,私下也可以用小名称呼,只要能辨别的出来就行。
类似于小学时已知自变量和函数求因变量的值,线性回归是先通过搭建线性回归模型寻找样本点背后的趋势线(也称回归曲线),再利用回归曲线进行一些简单的预测分析或因果关系分析。
二、一元线性回归
1、介绍
形式:y=ax+b
其中,y为因变量,x为自变量,a为回归系数,b为截距
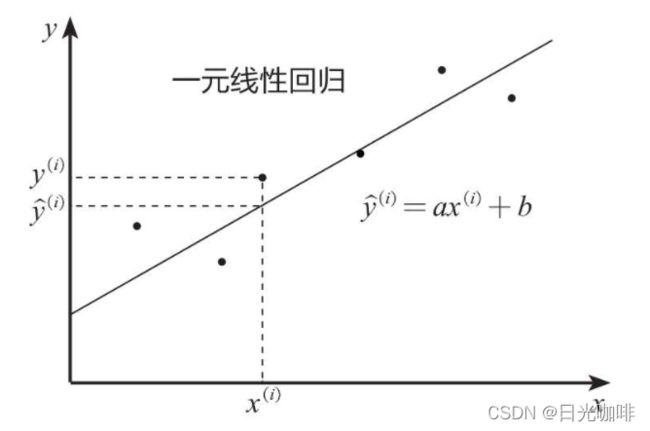
如上图所示,![]() 是实际值,
是实际值,![]() 是预测值,一元线性回归的目的就是拟合出一条线来使预测值和实际值尽可能接近,如果大部分点都落在拟合出来的线上,那么这个模型拟合的比较好。
是预测值,一元线性回归的目的就是拟合出一条线来使预测值和实际值尽可能接近,如果大部分点都落在拟合出来的线上,那么这个模型拟合的比较好。
2、案例
使用Jupyter notebook编写代码,数据集可以在我的主页找已上传的资源,“IT行业收入表.xlsx”
用一元线性回归模型探索工龄对薪水的影响,搭建薪水预测模型。
首先,查看IT行业收入表,df.head默认展示前5行。需注意的是,使用%matplotlib inline后不需要使用show()函数,运行后即可显示图像。
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_excel('IT行业收入表.xlsx')
df.head()接下来,绘制数据集的散点图
X = df[['工龄']]
Y = df['薪水'] # 也可以写成Y = df[['薪水']]
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.scatter(X,Y)
plt.xlabel('工龄')
plt.ylabel('薪水')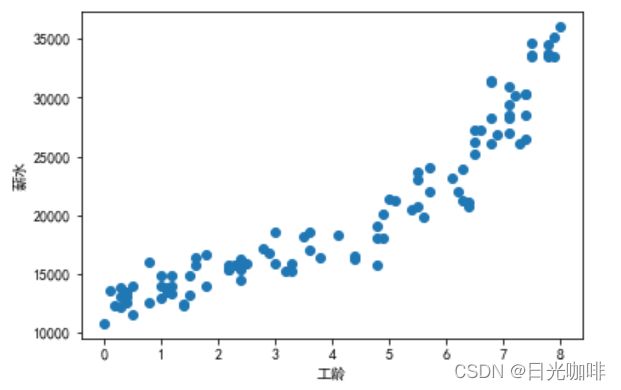
接下来调用线性回归函数,生成回归曲线,regr.predict(X)是预测的Y值
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)
plt.scatter(X,Y)
plt.plot(X,regr.predict(X),color = 'red')
plt.xlabel('工龄')
plt.ylabel('薪水')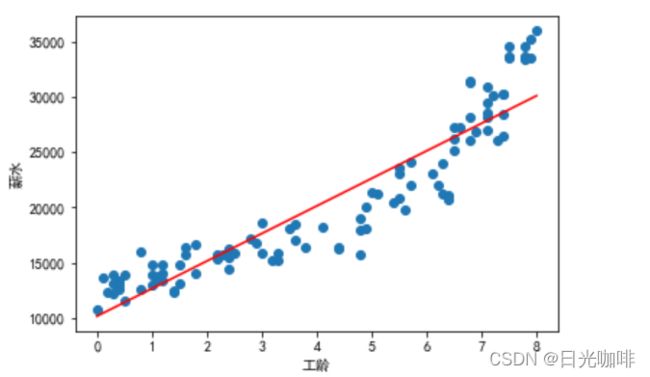
我们可以通过如下两个函数得到生成的回归曲线的截距和回归系数
print('系数a:'+str(regr.coef_[0]))
print('截距b:'+str(regr.intercept_))结果为:
系数a:2497.1513476046866 截距b:10143.131966873787
3、模型优化
大家看散点图有木有很熟悉,就是初中最常见的函数,一元二次函数,其实一元线性回归还有一个进阶升级版,其形式为![]()
进行优化的代码如下:
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree=2) # 设置最高次项为2次
X_ = poly_reg.fit_transform(X) # 将原有的X转换为一个新的二维数组X_,该二维数组包含新生成的二次项数据和原有的一次项 数据
# print(X_)
regr = LinearRegression()
regr.fit(X_,Y) # 注意此处为X_
plt.scatter(X,Y) #绘制散点图
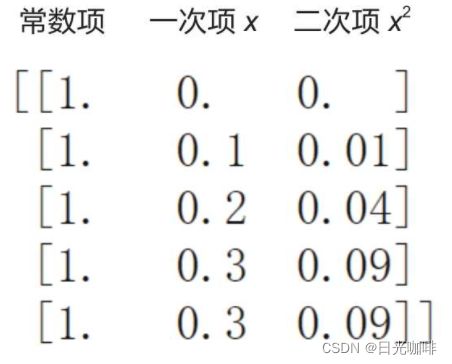
plt.plot(X,regr.predict(X_),color = 'red')# 注意此处为X_其实X_的形式就类似如下图的一个二维数组
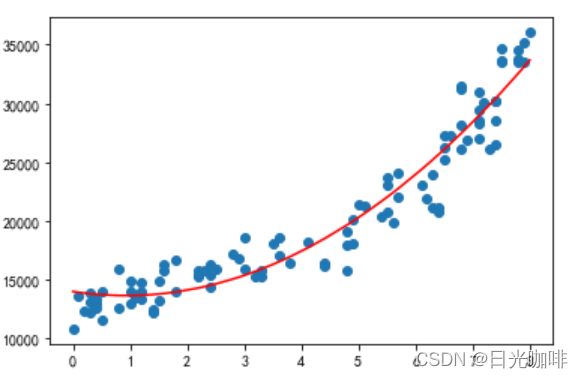
生成的拟合函数图像为
输出参数值代码和值分别问
print(regr.codf_)
print(regr.intercept_)[ 0. -743.68080444 400.80398224] 13988.159332096882
第一行列表里第一个参数0为X_中常数项的系数,第二个参数对应X_中一次项系数b,第三个参数对应X_中二次项系数a,第二行的参数代表常数项值c
三、多元线性回归
1、介绍
因为多元线性回归可以考虑到多个因素对目标变量的影响,所以在商业实战中应用更为广泛
形式:
其中
为特征变量,
是特征变量前的系数,
为常数项。数学上通过最小二乘法和梯度下降法求解系数,本文主要讲如何通过Python实现多元线性回归
2、案例
利用多元线性回归模型可以根据多个因素来预测客户价值
使用Jupyter notebook编写代码,数据集可以通过我的主页中我上传的资源找到“客户价值数据表.xlsx”
客户价值预测就是指预测客户在未来一段时间内能带来多少利润,其利润可能来自信用卡的年费、取现手续费、分期手续费、境外交易手续费等。在分析出客户的价值之后,就可以提供针对性服务。
首先读取数据
import pandas as pd
df = pd.read_excel("客户价值数据表.xlsx")
df.head()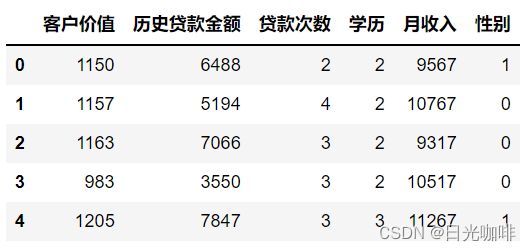
“客户价值”列为1年的客户价值,即在1年里能给银行带来的收益;“学历”列的数据已经做了预处理,其中2代表高中学历,3代表本科学历,4代表研究生学历;“性别”列中,0代表女,1代表男,多元线性回归预测的代码同一元线性类似,如下
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
X = df[['历史贷款金额','贷款次数','学历','月收入','性别']]
Y = df['客户价值']
regr.fit(X,Y)
print('各系数'+str(regr.coef_))
print('各常数项'+str(regr.intercept_))关于模型的评估,小编后面再进行讲解记录
总结
本文对线性回归模型进行了简单的介绍,通过案例实战讲解了代码。