手把手教你在FPGA上移植NVDLA+Tengine并且跑通任意神经网络(1)
手把手教你在FPGA上移植NVDLA+Tengine并且跑通任意神经网络(1)
- 一.简介
-
- 1.1 什么是NVDLA
- 1.2 什么是Tengine
- 1.3 模型部署过程简介
- 1.4 项目目标
- 二.NVDLA硬件移植以及验证
- 2.1 硬件平台选择
-
- 2.2 RTL代码生成
-
- 2.2.1 什么是docker
- 2.2.2 用docker构建NVDLA硬件环境
- 2.3 IP核封装
-
- 2.3.1 新建VIVADO工程
- 2.3.2 建立顶层文件,修改接口电路
- 2.3.3 关闭时钟电路
- 2.3.4 综合与布局布线
- 2.3.5 封装IP核
- 2.3.6 BLOCK DESIGN
- 2.3.7 SDK中进行NVDLA硬件功能测试
- 三.小结
一.简介
1.1 什么是NVDLA
官方开源仓库:
(软件)https://github.com/nvdla/sw
(硬件)https://github.com/nvdla/hw
(文档)https://github.com/nvdla/doc
NVDLA是英伟达公司在2017年开源的深度学习加速框架。目前硬件部分和软件部分均已开源。官方提供了硬件和软件的开源代码与基本模块解释文档。硬件部分由几个用于专门算子的子处理器构成:如卷积核,池化模块,线性运算模块。还内置了CSB和AXI总线与主处理器CPU进行通信。每个子处理器可以单独运行也可以协调运行。开发人员可以根据需要自由的配置硬件资源和核数。软件层拥有较强的可移植性可以成为Linux内核的一个子模块。NVDLA SMALL架构图如下:

1.2 什么是Tengine
项目github地址:https://github.com/OAID/Tengine
Tengine 由 OPEN AI LAB 主导开发,该项目实现了深度学习神经网络模型在嵌入式设备上的快速、高效部署需求。为实现在众多 AIoT 应用中的跨平台部署,本项目使用 C 语言进行核心模块开发,针对嵌入式设备资源有限的特点进行了深度框架裁剪。同时采用了完全分离的前后端设计,有利于 CPU、GPU、NPU 等异构计算单元的快速移植和部署,降低评估、迁移成本。Tengine软件框架目前已经支持NVDLA后端。可以将NVDLA软件栈作为Tengine后端统一调度。丰富前端框架的支持种类,和后端支持的算子类型。如果后端NVDLA不支持将切图给CPU去执行。

1.3 模型部署过程简介
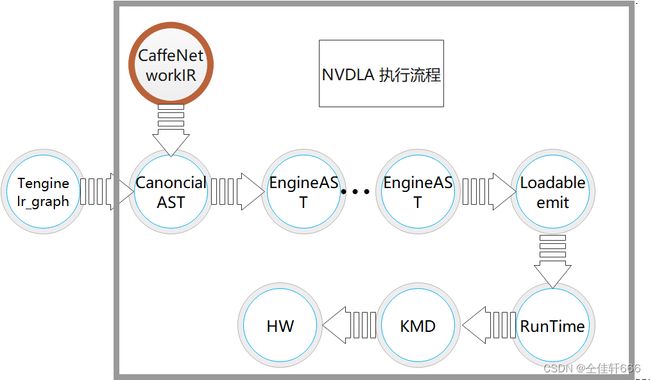
为了更好的理解验证平台互联结构的设计思路,本文首先介绍一下模型的推理过程。如下图,方框中的是NVDLA官方的开源的软件架构,方框外部是Tengine调度NVDLA框架的流程,NVDLA原来的工具链只支持caffe模型的读入,极大的限制了应用场景。而Tengine框架可以将各大框架模型翻译成特定的中间层表示。利用Tengine架构将市场上最常见的网络模型读入,极大的丰富了模型推理场景。Tengine框架的切图机制支持NVDLA后端不支持的算子切图给CPU进行运算,丰富了NVDLA可执行的网络类型(NVDLA支持的运算有限,不支持的运算将由Tengine框架调度到通用处理器上执行)。其中Ir_graph为Tengine前端对神经网络图模型的抽象表示,CanoncialAST为NVDLA编译器中不带硬件信息的抽象语法树,EngineAST为NVDLA编译器中带硬件信息的抽象语法树。
执行一次网络推理时,首先利用谷歌公司开源的protobuf库将训练好的网络模型读入。如下图所示,在未使用Tengine框架进行调度的时候,编译器工具链前端只能将Caffe模型通过CaffeNetworkIR转换为中间表示。在使用Tengine框架进行调度后,可以将神经网络推理框架如Pytorch,TensorFlow等转换为Ir_graph中间表示,紧接着转换为CanoncialAST层进行和硬件无关的网络优化。最后,将优化后的网络通过EngineAST抽象语法树的优化,完成网络模型的算子融合,模型权重、偏置的量化、为网络模型的张量分配内存等过程。所有流程执行完后,编译好的网络文件将形成Loadable文件。
完成模型编译过程后,编译的生成文件Loadable将被Runtime对编译文件进行解析。根据解析结果为张量分配内存。通过Linux的内核态与用户态交换系统,将用户态有关于神经网络的数据递交给内核态。内核态将根据用户态传递来的数据对硬件层HW进行配置。硬件层完成一次配置后将发出中断,内核驱动程序接收中断,并且判断是否继续对硬件层配置,直到完成整个模型推理过程。
1.4 项目目标
NVDLA虽然文档已经开源但是如何开发扩展十分匮乏。为了方便验证,本项目的目标是从NVDLA的编译脚本生成的RTL代码开始,经过编译综合和VIVADO EDA工具后端布局布线形成硬件描述性文件。使用Petalinux根据硬件描述文件构建属于FPGA-ARM板卡的inux操作系统。为了方便后续环境所依赖的包,为linux操作系统移植了ubuntu16.04根文件系统。在操作系统上下载编译器和runtime工具链所需的环境,并且编译运行compiler和runtime得到神经网络推理结果,验证它的准确性。
二.NVDLA硬件移植以及验证
2.1 硬件平台选择
tips:本章末尾有源码
NVDLA的驱动程序应运行在Linux操作系统上,要求查找表资源在七万以上,综合以上要求考虑,符合要求的板卡如下:
-
.ZYNQ 7000系列,该芯片的SoC平台继承好了ARM双核主处理器,为满足NVDLA逻辑资源的需求,至少为ZYNQ7045系列芯片
-
.ZYNQ MPSoC系列,该芯片的主控制器为ARM53,价格偏高在两万元左右
-
纯硬件逻辑器件,查找表资源足够,可同时生成RISC-V处理器与硬件资源,并且也可以在处理器上移植操作系统,实现难度较大。
综上所述,本设计选取的芯片型号为XC7Z045系列,板卡为如下图5ZC706评估板,价格为一万元人民币。

2.2 RTL代码生成
生成RTL代码需要根据NVDLA硬件官方仓库提供的教程搭建环境,在搭建过程需要安装很多的工具链,如cmake、git、gcc等。这些环境很可能和日常开发环境相互冲突,故使用 容器隔离封装Docker的手段搭建环境并且生成电路。
2.2.1 什么是docker
Docker是一种完全开放的容器引擎架构,它能够把所有软件和软件所依赖的工作环境都封装在一个容器里,然后可以在Linux或者Window下启动,Docker容器与其他容器与主机之间没有任何结构连接,处于独立状态。
2.2.2 用docker构建NVDLA硬件环境
docker如何安装运用请看博主写的另外一篇博客:https://mp.csdn.net/mp_blog/creation/editor/121117430
- 第一步,首先拉取封装好的DOCKER 镜像,镜像中集成了所有有关于NVDLA硬件电路生成的环境与文件。
docker pull farhanaslam/nvdla
- 启动 docker 容器后进入特定的目录下, 使用tmake 工具链, 完成硬件电路的一键生成。
root@1d0954a2d18b:/usr/local/nvdla/nvdla_hw# ./tools/bin/tmake -build vmod
[TMAKE]: building nv_small in spec/defs
[TMAKE]: building nv_small in spec/manual
[TMAKE]: building nv_small in spec/odif
[TMAKE]: building nv_small in vmod/vlibs
[TMAKE]: building nv_small in vmod/include
[TMAKE]: building nv_small in vmod/rams/model
[TMAKE]: building nv_small in vmod/rams/synth
[TMAKE]: building nv_small in vmod/rams/fpga/model
[TMAKE]: building nv_small in vmod/fifos
[TMAKE]: building nv_small in vmod/nvdla/apb2csb
[TMAKE]: building nv_small in vmod/nvdla/cdma
[TMAKE]: building nv_small in vmod/nvdla/cbuf
[TMAKE]: building nv_small in vmod/nvdla/csc
[TMAKE]: building nv_small in vmod/nvdla/cmac
[TMAKE]: building nv_small in vmod/nvdla/cacc
[TMAKE]: building nv_small in vmod/nvdla/sdp
[TMAKE]: building nv_small in vmod/nvdla/pdp
[TMAKE]: building nv_small in vmod/nvdla/cfgrom
[TMAKE]: building nv_small in vmod/nvdla/cdp
[TMAKE]: building nv_small in vmod/nvdla/bdma
[TMAKE]: building nv_small in vmod/nvdla/rubik
[TMAKE]: building nv_small in vmod/nvdla/car
[TMAKE]: building nv_small in vmod/nvdla/glb
[TMAKE]: building nv_small in vmod/nvdla/csb_master
[TMAKE]: building nv_small in vmod/nvdla/nocif
[TMAKE]: building nv_small in vmod/nvdla/retiming
[TMAKE]: building nv_small in vmod/nvdla/top
[TMAKE]: Done nv_small
[TMAKE]: nv_small: PASS
如果直接从vivado工程中直接导入生成的RTL代码则会产生资源不足的问题。这也就是NVDLA的硬件电路以及片上RAM电路的设计问题,在原本设计基础上将这部分替换为FPGA上的BRAM,完成硬件资源的缩减。替换成BRAM简单的方式就是使用rams\fpga这个文件夹里面的文件将rams\synth删除,之后再把vmod中所有内容全部添加到Vivado工程中。
2.3 IP核封装
2.3.1 新建VIVADO工程
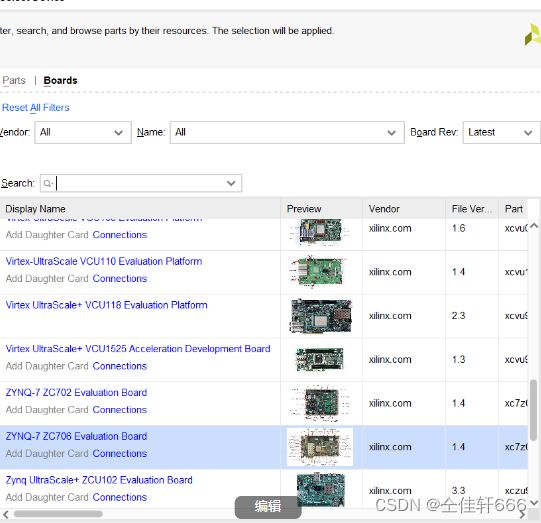
在创建VIVADO工程的时候不仅要导入芯片型号信息,还要加入xiangy板卡信息,否则会导致DDR3内存不正确,资源无法正确映射。如下图要分别在Parts和Boards选中芯片型号和板卡型号。
2.3.2 建立顶层文件,修改接口电路
因为NVDLA的接口电路csb并不常用,需要使用官方提供的csb转apb电路,然后建立顶层文件去调用二者。在本章末提供的封装好的NVDLA工程文件中可以看见具体例化方式。需要在VIVADO中将该文件设置为顶层文件。
顶层的代码如下:
module NV_nvdla_wrapper(
input core_clk,
input csb_clk,
input rstn,
input csb_rstn,
output dla_intr,
// dbb AXI
output nvdla_core2dbb_aw_awvalid,
input nvdla_core2dbb_aw_awready,
output [7:0] nvdla_core2dbb_aw_awid,
output [3:0] nvdla_core2dbb_aw_awlen,
output [2:0] nvdla_core2dbb_aw_awsize,
output [64 -1:0] nvdla_core2dbb_aw_awaddr,
output nvdla_core2dbb_w_wvalid,
input nvdla_core2dbb_w_wready,
output [64 -1:0] nvdla_core2dbb_w_wdata,
output [64/8-1:0] nvdla_core2dbb_w_wstrb,
output nvdla_core2dbb_w_wlast,
output nvdla_core2dbb_ar_arvalid,
input nvdla_core2dbb_ar_arready,
output [7:0] nvdla_core2dbb_ar_arid,
output [3:0] nvdla_core2dbb_ar_arlen,
output [2:0] nvdla_core2dbb_ar_arsize,
output [64 -1:0] nvdla_core2dbb_ar_araddr,
input nvdla_core2dbb_b_bvalid,
output nvdla_core2dbb_b_bready,
input [7:0] nvdla_core2dbb_b_bid,
input nvdla_core2dbb_r_rvalid,
output nvdla_core2dbb_r_rready,
input [7:0] nvdla_core2dbb_r_rid,
input nvdla_core2dbb_r_rlast,
input [64 -1:0] nvdla_core2dbb_r_rdata,
output [1:0] m_axi_awburst,
output m_axi_awlock,
output [3:0] m_axi_awcache,
output [2:0] m_axi_awprot,
output [3:0] m_axi_awqos,
output m_axi_awuser,
output m_axi_wuser,
input [1:0] m_axi_bresp,
input m_axi_buser,
output [1:0] m_axi_arburst,
output m_axi_arlock,
output [3:0] m_axi_arcache,
output [2:0] m_axi_arprot,
output [3:0] m_axi_arqos,
output m_axi_aruser,
input [1:0] m_axi_rresp,
input m_axi_ruser,
// cfg APB
input psel,
input penable,
input pwrite,
input [31:0] paddr,
input [31:0] pwdata,
output [31:0] prdata,
output pready,
output pslverr
);
wire m_csb2nvdla_valid;
wire m_csb2nvdla_ready;
wire [15:0] m_csb2nvdla_addr;
wire [31:0] m_csb2nvdla_wdat;
wire m_csb2nvdla_write;
wire m_csb2nvdla_nposted;
wire m_nvdla2csb_valid;
wire [31:0] m_nvdla2csb_data;
NV_NVDLA_apb2csb apb2csb (
.pclk (csb_clk)
,.prstn (csb_rstn)
,.csb2nvdla_ready (m_csb2nvdla_ready)
,.nvdla2csb_data (m_nvdla2csb_data)
,.nvdla2csb_valid (m_nvdla2csb_valid)
,.paddr (paddr)
,.penable (penable)
,.psel (psel)
,.pwdata (pwdata)
,.pwrite (pwrite)
,.csb2nvdla_addr (m_csb2nvdla_addr)
,.csb2nvdla_nposted (m_csb2nvdla_nposted)
,.csb2nvdla_valid (m_csb2nvdla_valid)
,.csb2nvdla_wdat (m_csb2nvdla_wdat)
,.csb2nvdla_write (m_csb2nvdla_write)
,.prdata (prdata)
,.pready (pready)
);
NV_nvdla nvdla_top (
.dla_core_clk (core_clk)
,.dla_csb_clk (csb_clk)
,.global_clk_ovr_on (1'b0)
,.tmc2slcg_disable_clock_gating (1'b0)
,.dla_reset_rstn (rstn)
,.direct_reset_ (1'b1)
,.test_mode (1'b0)
,.csb2nvdla_valid (m_csb2nvdla_valid)
,.csb2nvdla_ready (m_csb2nvdla_ready)
,.csb2nvdla_addr (m_csb2nvdla_addr)
,.csb2nvdla_wdat (m_csb2nvdla_wdat)
,.csb2nvdla_write (m_csb2nvdla_write)
,.csb2nvdla_nposted (m_csb2nvdla_nposted)
,.nvdla2csb_valid (m_nvdla2csb_valid)
,.nvdla2csb_data (m_nvdla2csb_data)
,.nvdla2csb_wr_complete () //FIXME: no such port in apb2csb
,.nvdla_core2dbb_aw_awvalid (nvdla_core2dbb_aw_awvalid)
,.nvdla_core2dbb_aw_awready (nvdla_core2dbb_aw_awready)
,.nvdla_core2dbb_aw_awaddr (nvdla_core2dbb_aw_awaddr)
,.nvdla_core2dbb_aw_awid (nvdla_core2dbb_aw_awid)
,.nvdla_core2dbb_aw_awlen (nvdla_core2dbb_aw_awlen)
,.nvdla_core2dbb_w_wvalid (nvdla_core2dbb_w_wvalid)
,.nvdla_core2dbb_w_wready (nvdla_core2dbb_w_wready)
,.nvdla_core2dbb_w_wdata (nvdla_core2dbb_w_wdata)
,.nvdla_core2dbb_w_wstrb (nvdla_core2dbb_w_wstrb)
,.nvdla_core2dbb_w_wlast (nvdla_core2dbb_w_wlast)
,.nvdla_core2dbb_b_bvalid (nvdla_core2dbb_b_bvalid)
,.nvdla_core2dbb_b_bready (nvdla_core2dbb_b_bready)
,.nvdla_core2dbb_b_bid (nvdla_core2dbb_b_bid)
,.nvdla_core2dbb_ar_arvalid (nvdla_core2dbb_ar_arvalid)
,.nvdla_core2dbb_ar_arready (nvdla_core2dbb_ar_arready)
,.nvdla_core2dbb_ar_araddr (nvdla_core2dbb_ar_araddr)
,.nvdla_core2dbb_ar_arid (nvdla_core2dbb_ar_arid)
,.nvdla_core2dbb_ar_arlen (nvdla_core2dbb_ar_arlen)
,.nvdla_core2dbb_r_rvalid (nvdla_core2dbb_r_rvalid)
,.nvdla_core2dbb_r_rready (nvdla_core2dbb_r_rready)
,.nvdla_core2dbb_r_rid (nvdla_core2dbb_r_rid)
,.nvdla_core2dbb_r_rlast (nvdla_core2dbb_r_rlast)
,.nvdla_core2dbb_r_rdata (nvdla_core2dbb_r_rdata)
,.dla_intr (dla_intr)
,.nvdla_pwrbus_ram_c_pd (32'b0)
,.nvdla_pwrbus_ram_ma_pd (32'b0)
,.nvdla_pwrbus_ram_mb_pd (32'b0)
,.nvdla_pwrbus_ram_p_pd (32'b0)
,.nvdla_pwrbus_ram_o_pd (32'b0)
,.nvdla_pwrbus_ram_a_pd (32'b0)
); // nvdla_top
assign nvdla_core2dbb_aw_awsize = 3'b011;
assign nvdla_core2dbb_ar_arsize = 3'b011;
assign m_axi_awburst = 2'b01;
assign m_axi_awlock = 1'b0;
assign m_axi_awcache = 4'b0010;
assign m_axi_awprot = 3'h0;
assign m_axi_awqos = 4'h0;
assign m_axi_awuser = 'b1;
assign m_axi_wuser = 'b0;
assign m_axi_arburst = 2'b01;
assign m_axi_arlock = 1'b0;
assign m_axi_arcache = 4'b0010;
assign m_axi_arprot = 3'h0;
assign m_axi_arqos = 4'h0;
assign m_axi_aruser = 'b1;
assign pslverr = 1'b0;
endmodule
2.3.3 关闭时钟电路
NVDLA 是针对专用芯片设计,其RTL代码中的随机存储器部分内置了时钟树电路来降低整体电路的功耗,这部分电路在赛灵思平台中已经开发好并不需要单独设计。打开 Settings|General|Language Options|Verilog Options,添加如下几个Global Define,关闭不必要的电路:
- VLIB_BYPASS_POWER_CG
- NV_FPGA_FIFOGEN
- FIFOGEN_MASTER_CLK_GATING_DISABLED
- FPGA
- SYNTHESIS
2.3.4 综合与布局布线
tips:impletation 要选择分布对ip综合,就是综合的第二个选项,如果选择第一个会报错。
综合和布局布线完全是VIVADO自动完成的和其他硬件电路的流程完全相同这里不再赘述
优化RAM前资源使用情况如下:
| 资源 | 已经使用 | 可以使用 | 利用率% |
|---|---|---|---|
| 查找表资源 | 421727 | 228500 | 191.81 |
| 片上RAM | 7 | 71400 | 0.01 |
| FIFO | 87988 | 427200 | 20.09 |
| 数字信号处理单元 | 32 | 900 | 3.66 |
| BUF | 11 | 32 | 36.5 |
优化RAM后资源使用情况如下:
| 资源 | 已经使用 | 可以使用 | 利用率% |
|---|---|---|---|
| 查找表资源 | 77237 | 228500 | 35.27 |
| 片上RAM | 371 | 71400 | 0.52 |
| FIFO | 92622 | 427200 | 22.33 |
| 数字信号处理单元 | 32 | 900 | 3.66 |
| BUF | 11 | 32 | 36.5 |
2.3.5 封装IP核
接下来打开Package IP,进入Tools|Create and Package New IP|Package your current project在Ports and Inference页面,.封装IP的过程中最后绑定时钟信号apb->csb clk axi->core clk 这个地方不做也可以,但是在Block Design处可能会出现严重警告。
之后还要做Memory Map,APB的memory block要自行添加,不像AXI会自己分配。如果我们不添加memory block,则在Block Design里没办法给APB自动分配地址,在Addressing and Memory里,选择我们刚刚包装好的APB总线,右击选择Add Address Block,默认添加一个块就行了。

封装IP工程文件如下:
Vivado NVDLA IP核:
链接:https://pan.baidu.com/s/1NE8eoGvwTiST8KnAn1EbGA
提取码:1999
2.3.6 BLOCK DESIGN
如何使用ZYNQ7000,进行BLOCK DESIGN请参考博主的另外一篇博客
https://mp.csdn.net/mp_blog/creation/editor/121355230
-
Axi Smart Connect的作用是用来自动配置AXI设备的内存映射,与Axi InterConnect的作用是一样的,但是Smart更紧密的嵌入到了Vivado内部,不需要用户太多的干涉。在本设计中用到了两个SmartConnect、其中一个是将ZYNQ的AXI Master接入了NVDLA的控制总线,这样可以通过内存映射机制读写NVDLA的寄存器,另一个SmartConnect将DLA的主内存接口接入了ZYNQ的AXI Slave,这样就可以NVDLA就可以访问挂在在ARM侧的DDR存储,与处理器共用内存,这样处理器可以通过硬件DMA搬移数据,加快访存速度。 有关ZYNQ的配置分配到的资源:
-
以太网,用来远程开发调试。
-
SD卡,用来存放BOOT、文件系统
-
UART,用来实现串口终端
-
FCLK_CLK0,默认的100Mhz,用来给csb时钟,控制总线占用的时间不长不需要太快的速度。根据前人所述,core时钟在ASIC仿真下可以运行到1Ghz,但在FPGA设计里,我只给了100Mhz作为输入(最多能200Mhz就不错了,频率过大会在寄存器读写的时候卡住)。
ADDRESS分配图如下:

-
BLOCK DESIGN如下图:

工程文件如下图
Vivado工程不带任何外设版本百度网盘链接:
链接:https://pan.baidu.com/s/1tX5IPMeRlKCTT8Wu26jHiw
提取码:1999
2.3.7 SDK中进行NVDLA硬件功能测试
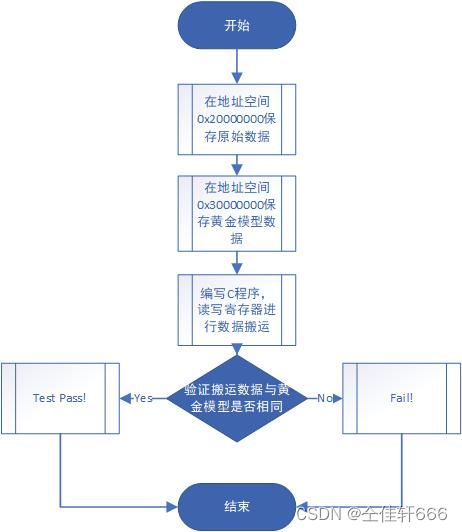
没有用到外部IO,可以不用编写XDC文件,直接一路Generate Bitstream生成bit。如果这个过程中没有报错,我们就可以Export Hardware到SDK内部了。
在SDK打开Xilinx|Dump/Restore Memory,把测试案例和Golden数据放到对应的位置。
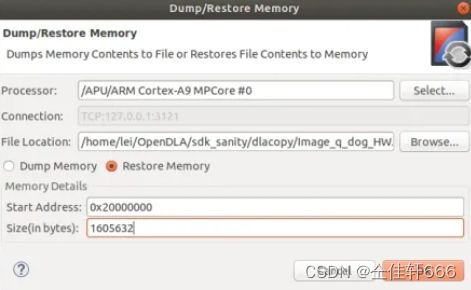
测试代码在上文提供的VIVADO BLOCK DESIGN版本中的 .sdk目录下。
测试前先在任意位置打断点,在run as debug 模式下全速运行到改位置。在打开串口后。否则会出现奇怪的错误。最后在串口中得到反馈信息如下图:

三.小结
先介绍硬件部分的移植,后续还会有操作系统移植和Tengine移植分析的教程,最后在自己搭建的AI加速器上运行用pytorch写的神经网络。