机器学习笔记-密度聚类_DBSCAN
密度聚类:DBSCAN
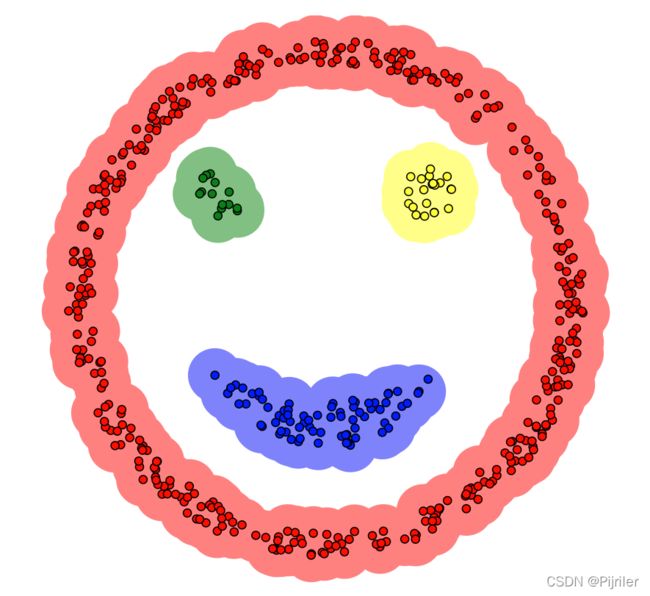
前面一节介绍了K-means聚类算法,但是K-means算法不能解决非球形的簇和不同大小的,比如说下面这种情况

如果使用K-means来对上述样本进行聚类,那么肯定没法运行,因为笑脸的外围轮廓是圆形,如果使用K-means算法这一圈一定不会聚类成一类。
如果遇到这种情况,就需要引入一个新的算法:密度聚类
密度聚类顾名思义就是基于密度的聚类,在了解密度聚类前,我们需要先明白一些定义。
给定数据集 D = { x 1 , x 2 , ⋯ , x m } D = \{x_1,x_2,\cdots,x_m\} D={x1,x2,⋯,xm},相关定义如下:
- ε − \varepsilon- ε−领域:对 x j ∈ D x_j\in D xj∈D,其 ε − \varepsilon- ε−领域包含样本集 D D D中与 x j x_j xj的距离不大于 ε − \varepsilon- ε−的样本,即 N ε ( x j ) = { x i ∈ D ∣ d i s t ( x i , x j ) ≤ ε } N_\varepsilon(x_j)=\{x_i \in D | dist(x_i,x_j)\le \varepsilon\} Nε(xj)={xi∈D∣dist(xi,xj)≤ε};
- 核心对象:若 x j x_j xj的 ε − \varepsilon- ε−领域至少包含 M i n P t s MinPts MinPts个样本,即 ∣ N ε ( x j ) ∣ ≥ M i n P t s |N_\varepsilon(x_j) | \ge MinPts ∣Nε(xj)∣≥MinPts,则 x j x_j xj是一个核心对象;
- 密度直达:若 x j x_j xj位于 x i x_i xi的 ε − \varepsilon- ε−领域中,且 x i x_i xi是核心对象,则称 x j x_j xj由 x i x_i xi密度直达;
- 密度可达:对 x i x_i xi与 x j x_j xj,若存在样本序列 p 1 , p 2 , ⋯ , p n p_1,p_2,\cdots,p_n p1,p2,⋯,pn,其中 p 1 = x i , p n = x j p_1 = x_i,p_n = x_j p1=xi,pn=xj且 p i + 1 p_{i+1} pi+1由 p i p_i pi密度直达,则称 x j x_j xj由 x i x_i xi密度可达。
- 密度相连:对 x i x_i xi与 x j x_j xj,若存在 x k x_k xk使得 x i x_i xi与 x j x_j xj均有 x k x_k xk密度可达,则称 x i x_i xi与 x j x_j xj密度相连;
上面介绍的这些概念是《西瓜书》中的内容,从定义上可以知道,DBSCAN聚类有两个参数:领域 ε \varepsilon ε和 M i n P t s MinPts MinPts。
在K-means算法中我们了解了簇这个概念,一个簇的其实就是一些聚类样本的集合,我们给出不同的簇定义,也就是给聚类样本的集合划分范围。在DBSCAN算法中,簇的定义是:由密度可达关系导出的最大的密度相连样本集合。我们的任务就是在给定的数据集和参数中找到符合簇定义的所有簇,算法的流程如下:

(算法流程来自西瓜书)
DSBCAN算法的第一步是找到各样本的 ε \varepsilon ε并确定核心对象集合 Ω \Omega Ω。现在数据集被分为两个集合: Ω \Omega Ω和 D D D \ Ω \Omega Ω后者表示数据集 D D D去掉 Ω \Omega Ω的部分。第12步时,算法应该是进入主题部分了,先在核心对象中随机抽取一个样本点。然后从这个样本点出发,找到所有和这个样本点密度可达的样本点,把它们组成一个集合,这个集合就是生成的第一个簇。在得到新的簇后需要对原始数据进行更新,包括核心对象 Ω \Omega Ω和剩余样本集 Γ o l d \Gamma_{old} Γold。具体怎么生成的,算法中写的很清楚。
代码实现
数据任然来自《西瓜书》
主函数main.m
% 密度聚类
clc;
clear;
tic
load data
e = 0.11;
MinPts = 5;
data = data(:,1:2);
[result] = DBSCAN(data,e,MinPts);
data_index = zeros(length(data),1);
for m = 1:length(result)
data_index(result{m}) = m;
end
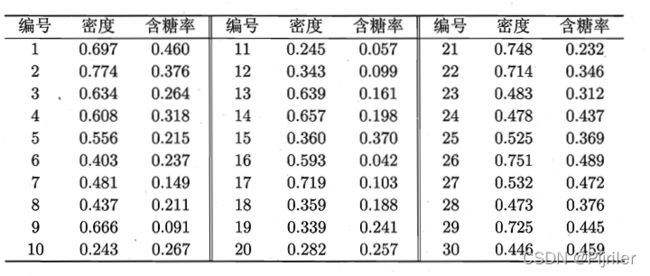
gscatter(data(:,1),data(:,2),data_index,'rkgby')
legend('孤立值','类别1','类别2','类别3','类别4')
grid on
axis([0,1,0,0.8])
title("DBSCAN散点图")
toc
DBSCAN.m
function [result] = DBSCAN(D,e,MinPts)
%{
Solve 密度聚类算法DBSCAN实现
Input D——训练样本集
e——邻域值
MinPts——最小邻域样本数
Output result——聚类类别
%}
% 错误判断
if nargin < 2
error(message('stats:kmeans:TooFewInputs'));
end
% 获得数据集大小
[Sample_number,~] = size(D);
% 初始化核心对象集合
Core_Object = [];
for i =1:Sample_number
N_i = 0;
for j = 1:Sample_number
% if i~=j
if norm(D(i,:) - D(j,:)) <= e
N_i = N_i + 1;
end
% end
end
if N_i>=MinPts
Core_Object = [Core_Object,i];
end
end
% 初始化簇分类
C = cell(1);
% 初始化聚类簇数
k = 0;
% 初始化未访问样本集合
T = 1:Sample_number;
Index = 1:Sample_number;
while ~isempty(Core_Object)
% 记录当前未访问样本集合
T_old = T;
% 随机选择一个核心对象random_o
% if length(Core_Object)==1
% random_o = Core_Object;
% else
% random_o = Core_Object(round(length(Core_Object)*rand));
% end
random = randperm(length(Core_Object));
random_o = Core_Object(random(1));
Q = random_o;
% 在未访问集合中删除random_o
T(T == random_o) = [];
while ~isempty(Q)
% 取出Q集合的第一个样本,从Q集合中移除
q = Q(1);
Q(Q == q) = [];
% 计算N_q
N_q_number = 0;
N_q = [];
for i =1:Sample_number
if norm(D(q,:) - D(i,:)) <= e
N_q_number = N_q_number + 1;
N_q = [N_q,i];
end
end
% 如果选取的q样本是核心样本
if N_q_number >= MinPts
% 计算核心邻域样本与未访问样本的交集
Delta = intersect(N_q,T);
Q = [Q,Delta];
for j = 1:length(Delta)
T(T == Delta(j)) = [];
end
end
end
k = k + 1;
C_k = T_old;
for j = 1:length(T)
C_k(C_k == T(j)) = [];
end
for j = 1:length(C_k)
Core_Object(Core_Object == C_k(j)) = [];
end
C{k} = C_k;
end
result = C;
end
运行结果:
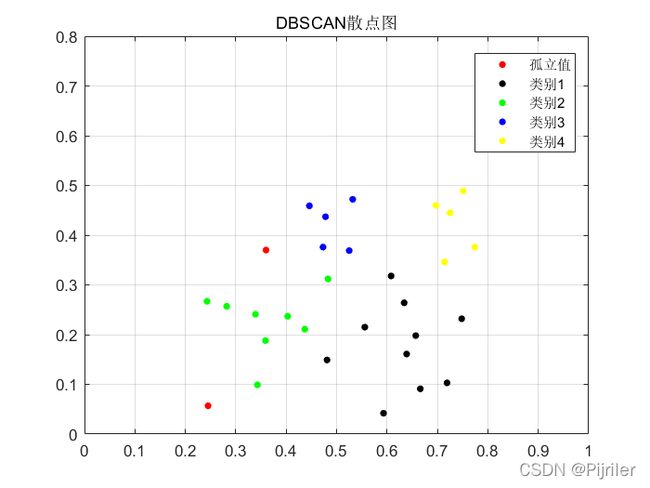
DBSCAN算法还有一个作用,就是检测异常值。由密度聚类的定义可知,我们不需要给定聚类多少类别,最终的结果全部由算法运行得到,但是我们需要为算法输入两个参数。如果存在异常点,即不和任何其它样本存在密度可达,那么这种点在算法运行之后就会被记录下来,系统定为异常值。
文章开头的笑脸数据集使用DBSCAN算法运行的结果如下,生成四个聚类簇,并且效果很好。
DSBCAN与K-means对比
- K-means算法需要提前确定聚类簇数,DBSCAN算法不需要提前规定聚类簇数但是需要确定两个参数 ε \varepsilon ε和 M i n P t s MinPts MinPts,并且这两个参数还是比较敏感的。
- K-means算法无法解决不规则形状的数据集,例如上文的笑脸状,密度聚类不会受限,在任何基于密度分布的数据集上都能运行成功。
- DSBCAN算法能够用做检测异常值,K-means算法会将所有数据集都归为某一簇,这其实也说明K-means算法容易受到异常值的影响。