CReFF缓解长尾数据联邦学习(IJCAI 2022)
关注公众号,发现CV技术之美
本篇分享 IJCAI 2022 论文『Federated Learning on Heterogeneous and Long-Tailed Data via Classifier Re-Training with Federated Features』,通过联合特征的分类器再训练在异质和长尾数据上的联合学习。
论文链接:https://arxiv.org/abs/2204.13399
项目链接:https://github.com/shangxinyi/CReFF-FL
01
背景与概述
作者首先提出挑战性问题:同时出现数据异质性和长尾分布问题,将会严重损害FL模型性能。作者进一步发现,实际上,不同Clients上的分类器间的差异是导致全局模型性能不佳的主要因素。基于此,作者提出:通过使用联邦特征对不同Clients上的分类器进行重训练,从而处理数据异构和长尾分布问题,同时在联邦特征上重新训练的分类器可以产生与在真实数据上重新训练的分类器相当的性能,不存在隐私或类分布泄露问题。
联邦学习使多个客户机能够协作地学习一个强大的全局模型,而无需将本地私有数据传输给服务器,这是一种高效通信和隐私保护的学习框架。但是,在FL模型训练过程中,一个主要挑战是数据的异质性问题,由于数据来源不同从而导致客户端之间的分布差异;同时真实世界的数据往往显示出长尾分布与严重的类不平衡,样本数量在某些类(head classes)的数量严重超过了其他一些类(tail classes)。因此,如果跨客户端的训练数据同时是长尾和异构的,那么将变得复杂和具有挑战性,因为每个客户端可能持有不同的尾类以及不同的数据分布。
作者受到长尾学习解耦方法启发:即在固定已经训练后的特征提取器的情况下,使用一组平衡的数据对一个有偏的分类器进行再训练,进行两阶段学习。因此提出,通过聚合模型的特征提取器(聚合客户端模型)+重训练模型分类器层,对全局模型进行改善以缓解异构数据+长尾分布问题。
由于隐私问题,在服务器上使用共享平衡数据集的这个先决条件对于大多数FL实际场景是不可行的。因此,基于两阶段学习的思想和FL对隐私的关注,作者提出了一种新的、保护隐私的FL方法,称为联邦特征分类器再训练(CReFF)。在服务器上学习了一组被称为联邦特征的平衡特征用于重训练分类器层,基于一个直观的思想:即在联邦特征上重新训练的分类器应该与在真实数据上重新训练的分类器的性能相当,这可以通过使两个分类器相似来实现。具体来说,我们优化联邦特征,使得其在分类器上的梯度接近于真实数据的梯度。
如下图1所示,作者首先在CIFAR-10-LT(CIFAR-10的长尾版本)实验,以表明两阶段学习(长尾学习解耦方法)在FL的异质性和长尾数据上可以表现良好。作者分别使用不平衡因子(IF)和狄利克雷分布系数α来控制长尾分布和异质性的程度(IF程度越高,不平衡程度越高,α程度越低,异质性程度越高),给定一个在异构和长尾数据上预先训练的全局模型,然后固定其特征提取器,再使用从客户端收集的小平衡数据集(每个类100个)在服务器上重新训练其分类器。
通过图1,我们可以发现,CReFF方法的有效性,当使用联邦特征代替真实数据进行重训练分类器,在性能损失很低的情况下充分保护了隐私。
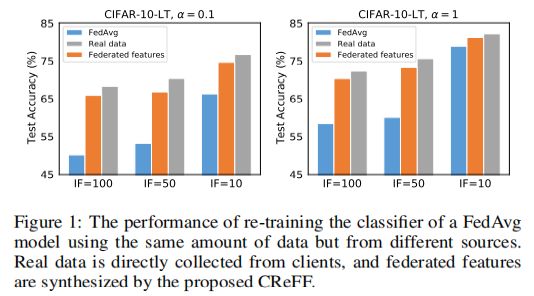
图1:CReFF效果图对比
02
CReFF方法
Motivation:分类器再训练策略对异构数据和长尾数据分别都是有效的,我们发现其也适用于联合问题。换句话说,有偏差的分类器是导致在异构和长尾数据上训练的全局模型性能不佳的主要因素。为了验证猜想,作者设计了一个实验,即将ResNet-8分为=4 blocks+one classifier,作为模型参与训练,然后使用从客户端收集的一组平衡数据(每个类100个)来重新训练每个组件,同时保持其他组件固定。
如下图2所示,我们可以观察到,再训练任何单个组件都可以实现一定的改进,特别是再训练分类器获得了最高的性能增益;可以表明,有偏分类器是导致全局模型性能较差的主要因素,因为其他组件受的影响较小。但是,在实际的FL应用程序中,在服务器上使用外部数据重训练是不现实的,从客户端传输数据违反了FL的关键隐私保护原则,并且服务器本身收集的数据可能不遵循与客户端训练数据相同的分布,作者使用联邦特征来解决。
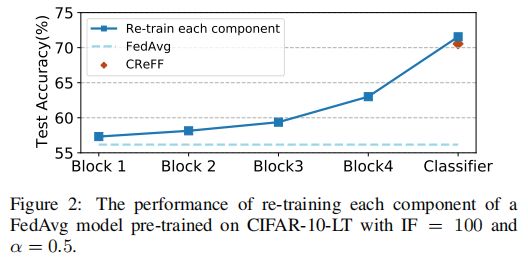
图2:验证实验
CReFF框架:作者提出了CReFF方法来处理数据异质性和长尾分布的联合问题:它是一种基于FedAvg的简单有效的设计方法,使用服务器上的一组可学习特征(称为联邦特征)重新训练分类器classifier。具体地说,我们优化联邦特征,使其梯度接近真实数据的梯度,使训练真实特征和联邦特征的分类器在参数空间中收敛到类似的解。
这样的话,在联邦特征上重新训练的分类器就可以通过以保护隐私的方式与在真实数据上重新训练的分类器近似。从整体上而言,如下图3所示,CReFF方法主要由客户端上的本地培训 + 服务器上的联邦特征优化两部分组成。
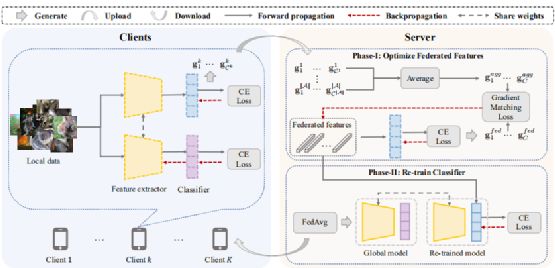
图3:CReFF方法整体框架
Step1客户端上的本地培训:首先定义,全局模型 Wt = 特征提取器 Ut + 分类器 Vt,再训练模型则是拥有相同的特征提取器,只是分类器不同(重训练)。对于每个接收到的模型,局部训练由一个相应的部分组成,第一部分就是普通的本地模型训练,第二部分则是计算真实特征梯度用于服务器上优化联邦特征:客户端k产生d-dim真实特征维度,基于特征提取器Ut得到类特征表示,再通过再训练模型得到梯度信息并进行平均:

最后,客户端k将两个部分(局部模型参数+真实特征梯度)上传到服务器,客户端只将每个类的平均梯度上传到服务器,可以将本地数据的私有信息擦除(隐私保护)。
Step2服务器上的联邦特征优化:服务器接受从客户端发送的两个部分,分别用于FedAvg模型聚合以及优化联邦特征(用于再训练分类器层)。第二部分(优化联邦特征)旨在学习一组平衡的d-dim联邦特征:首先,服务器通过对所有选定的客户端进行平均来聚合每个类c的真实特征梯度:
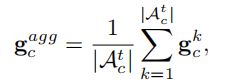
然后,服务器基于再训练模型的分类层计算也可以得到一组联邦特征梯度:
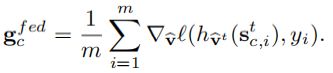
接着,作者使用gradient matching loss作为损失函数来度量差异:
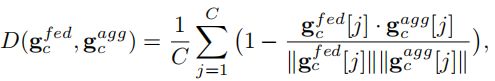
最后,则是通过优化后的联邦特征来重训练分类器。
进一步发现,使用CReFF通过优化梯度匹配损失来学习联邦特征,主要有两方面优点:(1)一方面,CReFF可以产生与真实特征几乎相同的梯度来更新分类器,从而缓解异构与长尾数据问题;(2)另一方面,CReFF以更能保护隐私的方式进行(因为收集每个客户端的类平均梯度并不需要本地类分布的信息)。
03
实验结果
实验设置:
数据集:CIFAR-10/100-LT,基于IF=100/50/10形成长尾分布,再基于Dirichlet分布形成异构数据,α=0.5;ImageNet-LT,α=0.1;其中IF越大则数据不平衡程度越大,α越小则数据异构程度越大。
模型baseline:使用ResNet-8模型在CIFAR-10/100-LT数据集上,使用ResNet-50模型在ImageNet-LT数据集上。
超参数设置:使用标准的交叉熵损失,并运行200轮通信;将客户端总数设置为20以及活跃客户端比率设为40%;批次大小设置为32;联邦特征初始化为随机噪声,并且dim=100;使用学习率为0.1的SGD作为优化器。
比较方法:FedAvg、FedAvgM、FedProx、FedDF、FedBE and FedNova基线方法。
Results on CIFAR-10/100-LT:如下表1所示,是在CIFAR-10/100-LT上所得结果,我们可以发现CReFF在具有不同IF的两个数据集上都获得了最高的测试精度,这表明了在全局类分布高度长尾时CReFF的泛化能力;
对于面向异质性的方法,大多数性能与FedAvg相似,因为它们只处理数据的异质性,而没有考虑到全局类的不平衡;对于面向不平衡的方法,其中一些方法某些情况与FedAvg相比表现良好,然而与CReFF相比仍然存在性能差距,因为它们的目标是处理全局不平衡问题,但通常忽略了跨客户端的数据异构性问题。
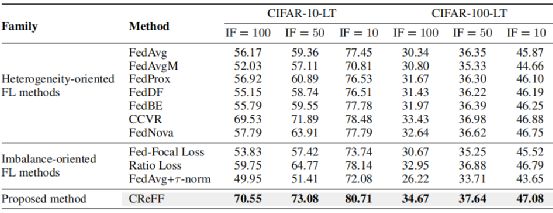
表1:Results on CIFAR-10/100-LT
Results on ImageNet-LT:如下表2所示,是在 ImageNet-LT上所得结果,为了更好地测试具有不同训练样本数量的类的性能,测试三种类的准确率:Many(超过100样本),Medium(20-100样本),Few(少于20样本),与其它FL方法相比,CReFF在所有情况下都取得了最好的结果,这表明CReFF提高了总体精度,并不会损害头部类的精度。
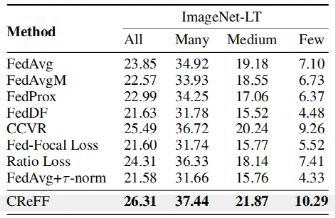
表2:Results on ImageNet-LT
Model Validation:为了进一步验证CReFF的有效性,作者研究了两个关键的研究问题:(1)为什么在联邦特征上重新训练的分类器表现得与在真实特征上重新训练的分类器相似? (2)每个类有多少个联邦特征就足以重新训练一个好的分类器。
针对问题1,作者设计实验,对于CIFAR-10-LT,分为三组:Many (more than 1500 samples), medium (200-1500 samples) and few (less than 200 samples),然后获取每个类的平均梯度匹配损失来显示联邦特征梯度和真实特征梯度之间的差异(实线),以及联邦特征和真实特征之间的差异(虚线)。
如下图4可知,梯度之间的差异在几轮内减少到0左右,这意味着对梯度匹配损失的优化成功地使联邦特征梯度接近真实的特征梯度;因此,分类器基于联邦特征再训练的优化路径与真实特征的优化路径相似。但是,随着训练的进行,联邦特征和真实特征之间的差异也在减少,但它们远非0,这意味着联邦特性不必与真实特性相似,尽管它们对应的梯度非常接近;因此,可以进一步保证真实特征的隐私性。
如下图5所示,则是探究每个类的联邦特征的数量对于模型性能影响,可以发现当联邦特征的数量为0时,CReFF等同于FedAvg,更多的联邦特性通常会产生更高的精度,随着联邦特征数量的增加,性能提升逐渐收敛;由于真实特征梯度所提供的信息有限,因此这一结果也是意料之中的。
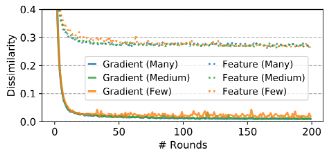
图4:联邦梯度/特征与真实梯度/特征差异比较
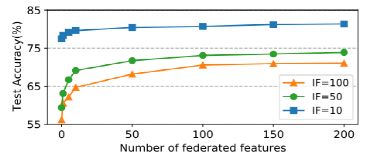
图5:联邦特征数量影响
04
总结
作者首先证明了分类器再训练是处理联合学习框架中数据异质性和长尾分布的联合问题的一种直接而有效的方法;在此基础上,提出了CReFF方法,在服务器上学习一组称为联邦特征的平衡特征,以保持隐私的方式进行分类器再训练。
实验表明,在联邦特征上重新训练的分类器可以产生与在真实数据上重新训练的分类器相当的性能,CReFF在异质性和长尾分布方面优于最先进的FL方法,并验证了CReFF的有效性。未来可以考虑,如何结合联邦学习和更多长尾分布相关算法,以及如何设计出针对长尾分布较严重的客户端的个性化模型。

END
欢迎加入「图像分类」交流群备注:分类
