CNN基础论文 精读+复现----LeNet5 (三)
文章目录
- 训练集
- 测试集
- 绘图
- 结果分析
- 总结
- 完整代码
前面两章已经把概念数据准备网络搭建等等弄完了,没看的可以看一下 ,
CNN基础论文复现----LeNet5 (一)
CNN基础论文复现----LeNet5 (二)
现在开始就是训练和结果分析了。
训练集
先放上这一块的代码 后面再逐句解释。
def train(epoch):
runing_loss = 0.0
for i, data in enumerate(train_loader):
x, y = data
x, y = x.to(device), y.to(device)
# 清零 正向传播 损失函数 反向传播 更新
optimizer.zero_grad()
y_pre = model(x)
loss = criterion(y_pre, y)
loss.backward()
optimizer.step()
runing_loss += loss.item()
# 每轮训练一共训练1W个样本,这里的runing_loss是1W个样本的总损失值,要看每一个样本的平均损失值, 记得除10000
print("这是第 %d轮训练,当前损失值 %.5f" % (epoch + 1, runing_loss / 938))
return runing_loss/938
runing_loss = 0.0
用这个来记录后面的损失值。
x, y = data
x, y = x.to(device), y.to(device)
这两行就是把数据拿出来给 X,Y并且放到了GPU上运行。
optimizer.zero_grad()
训练之前先把优化器清零。
y_pre = model(x)
loss = criterion(y_pre, y)
先把我们的x放到模型里去训练,训练的结果返回给y_pre,然后把训练出来的预测值y和真实值给损失函数去计算损失。
loss.backward()
optimizer.step()
runing_loss += loss.item()
第一句拿到损失 反向传播回去。
第二句 用反向传播来的损失计算需要更新的参数值。
最后一句就是累加我们的损失值。 这里要用loss.item()取值~~~~
print("这是第 %d轮训练,当前损失值 %.5f" % (epoch + 1, runing_loss / 938))
每次训练完一轮都打印输出看一下当前的损失值, 这里要除以938,因为可以看到前面设置的 batch_size 为64 所以这里的循环每一次都取出64组样本进行训练,一共是6W个样本(可以在数据加载的时候 用 len(train_dataset) 来看一下训练集长度)
,所以就是 60000 / 64 =937.5 就是938次循环,这里也可以直接在for循环里设置个变量记数看看循环跑了多少次。
然后我们将得到的损失用return返回,记录一下 方便后面绘图。
测试集
然后就是测试集,先放上整体代码。
def test(epoch):
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
x, y = data
x, y = x.to(device), y.to(device)
pre_y = model(x)
# 这里拿到的预测值 每一行都对应10个分类,这10个分类都有对应的概率,
# 我们要拿到最大的那个概率和其对应的下标。
j, pre_y = torch.max(pre_y.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += y.size(0) # 统计方向0上的元素个数 即样本个数
correct += (pre_y == y).sum().item() # 张量之间的比较运算
print("第%d轮测试结束,当前正确率:%d %%" % (epoch + 1, correct / total * 100))
return correct / total * 100
with torch.no_grad():
这句话的意思就是 这里面的过程是不计算梯度的,因为在测试集嘛,主要是看看上面训练出来的参数怎么样,所以不需要再计算新的梯度了。
j, pre_y = torch.max(pre_y.data, dim=1)
函数 torch.max()用于取最大值,第一个参数传入一个tensor变量,后面的dim表示按照那个轴来取最大值(这个轴应该和axis是一样的)。
看下面的示例就懂了,
a = torch.tensor([[1,5,62,54], [2,6,3,9], [2,65,2,6]])
print("这是a",a)
i,j = torch.max(a, 1)
print("这是返回的第一个值i",i)
print("这是返回的第二个值j",j)
输出
这是a tensor([[ 1, 5, 62, 54],
[ 2, 6, 3, 9],
[ 2, 65, 2, 6]])
这是返回的第一个值i tensor([62, 9, 65])
这是返回的第二个值j tensor([2, 3, 1])
返回的就是最大值及其下标,所以在复现程序中,这里的最大值是最大的概率,其里面存储的是 对应0-9数字的概率 ,一共十个,概率没有什么用,主要是要他的下标,这个下标其实就相当于系统识别出来的预测数字。
total += y.size(0)
这句话就是统计测试集上有多少个样本,统计0方向上的个数。
实际这里直接写 len(test_dataset) 也可以,都一样。
correct += (pre_y == y).sum().item()
这句话就是用来算有多少个正确识别的样本,乍一看可能不太理解,先看一下此时的pre_y是这样样的.
tensor([9, 4, 0, 9, 5, 1, 3, 7, 6, 9, 3, 0, 7, 2, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 2, 1, 7, 2,
5, 0, 8, 0, 2, 7, 8, 8, 3, 0, 6, 0, 2, 7, 6, 4], device=‘cuda:0’)
此时的真实值y是这样的,
tensor([9, 2, 0, 9, 5, 1, 3, 7, 6, 9, 3, 0, 2, 2, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 2, 1, 7, 2,
5, 0, 8, 0, 2, 7, 8, 8, 3, 0, 6, 0, 2, 7, 6, 6], device=‘cuda:0’)
当程序运行 pre_y == y 就是将我们预测出来的值和真实的值进行对比,是张量层面的比较运算。 单独运行这一句话是这样的:
tensor([ True, False, True, True, True, True, True, True, True, True,
True, True, False, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, False], device=‘cuda:0’)
之后加上sum,在单独运行这一句话,(pre_y == y).sum() 是这样的:
tensor(61, device=‘cuda:0’)
最后再加上 item() 就简单了 直接就是取出来57了 最后可以得到 当前轮测试的正确数量是 61个(一轮64个,正确率还蛮高的),累加到correct 中。
print("第%d轮测试结束,当前正确率:%d %%" % (epoch + 1, correct / total * 100))
记得除以样本总数然后乘以100 (要百分比嘛)。
返回的时候也要把这个正确率返回,记录一下用于后面的画图。
绘图
先放上来这一块的代码
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.title("训练模型")
plt.plot(plt_epoch,loss_ll)
plt.xlabel("循环次数")
plt.ylabel("损失值loss")
plt.rcParams['font.sans-serif'] = ['KaiTi']
因为我标题和XY轴都用的中文,所以写上这一句话,不然绘图出来中文会乱码。
plt.figure(figsize=(12,6))
用于多图绘制,设置长和宽 12,6
plt.subplot(1,2,1)
这里就是说下面的子图放在什么位置, 参数表示 1行2列 位置为1。
plt.title("训练模型")
plt.plot(plt_epoch,loss_ll)
plt.xlabel("循环次数")
plt.ylabel("损失值loss")
这几行就是设置标题,设置xy轴数据和xy轴名称。
因为要绘制训练次数和损失值的图,还有一个训练次数和正确率的图,所以还有一个图,照葫芦画瓢就行了。
结果分析
看一下训练20轮之后的结果:
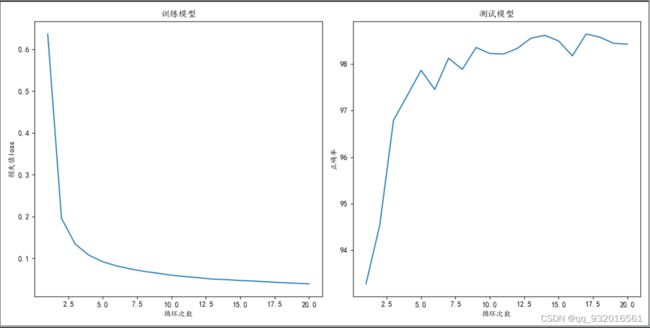

仅跑了20轮,由于复现程序并没有完全按照论文中的过程来实现,所以论文里的损失值和错误率都没办法参考了。
我这里是直接使用了plt的绘图库实现的,因为比较方便(另一个熟练度不高),也可以使用tensorboard实现。
总结
总的来说这篇论文有很多值得学习的地方,比如 对于全连接网络的平移不变性优化方法,引入的池化模糊概念,近似于drpoout的算法,,RBF的处理,还有近似于交叉熵的损失函数,以及最后设计的人工编码方式等等。。。。。。
但实际上由于我刚刚入门,可能连入门都没算上,对于Pytorch的源码都没有看过,导致很多问题,比如上面的特殊的S2层 C3层还有最后的F6层等都没办法重写,直接都是使用的现有API,还有很多的理论性很强给概念我都没有弄懂,比如说归一化的概念 RBF层的设计,与其说没有弄懂,倒不如说没有深究,我觉得把没有必要花大量时间去弄懂纯理论,感觉并不能用上,明白一般性理论就行了吧应该或许估计,所以对于这篇论文的复现也不完全。
不过对于Pytorch框架的熟悉,深度学习概念和各种周围思想的了解更加的深刻了一些,也会了一些复现论文的套路,后面可能会尝试一下 AlexNet,等有一定的基本功以后可能会回来将这篇论文完全性复现。整体的代码我会贴到最后,Github上也会放一份,然后还有我看到的一个基本完全性复现的代码也会放到Github上。
Github地址: 点我直达~~
完整代码
import torch
from torch import optim
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor (),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../data/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../data/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
print("训练集长度",len(train_dataset))
print("测试集长度",len(test_dataset))
# 模型类设计
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.mode1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=4*4*16, out_features=120),
nn.Linear(in_features=120, out_features=84),
nn.Linear(in_features=84, out_features=10),
)
def forward(self, input):
x = self.mode1(input)
return x
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = LeNet5()
model.to(device)
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
def train(epoch):
runing_loss = 0.0
for i, data in enumerate(train_loader):
x, y = data
x, y = x.to(device), y.to(device)
# 清零 正向传播 损失函数 反向传播 更新
optimizer.zero_grad()
y_pre = model(x)
loss = criterion(y_pre, y)
loss.backward()
optimizer.step()
runing_loss += loss.item()
# 每轮训练一共训练1W个样本,这里的runing_loss是1W个样本的总损失值,要看每一个样本的平均损失值, 记得除10000
print("这是第 %d轮训练,当前损失值 %.5f" % (epoch + 1, runing_loss / 938))
return runing_loss / 938
def test(epoch):
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
x, y = data
x, y = x.to(device), y.to(device)
pre_y = model(x)
# 这里拿到的预测值 每一行都对应10个分类,这10个分类都有对应的概率,
# 我们要拿到最大的那个概率和其对应的下标。
j, pre_y = torch.max(pre_y.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += y.size(0) # 统计方向0上的元素个数 即样本个数
correct += (pre_y == y).sum().item() # 张量之间的比较运算
print("第%d轮测试结束,当前正确率:%d %%" % (epoch + 1, correct / total * 100))
return correct / total * 100
if __name__ == '__main__':
plt_epoch = []
loss_ll = []
corr = []
for epoch in range(20):
plt_epoch.append(epoch+1) # 方便绘图
loss_ll.append(train(epoch)) # 记录每一次的训练损失值 方便绘图
corr.append(test(epoch)) # 记录每一次的正确率
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.title("训练模型")
plt.plot(plt_epoch,loss_ll)
plt.xlabel("循环次数")
plt.ylabel("损失值loss")
plt.subplot(1,2,2)
plt.title("测试模型")
plt.plot(plt_epoch,corr)
plt.xlabel("循环次数")
plt.ylabel("正确率")
plt.show()