NNDL 实验六 卷积神经网络(3)LeNet实现MNIST
目录
5.3 基于LeNet实现手写体数字识别实验
5.3.2 模型构建
5.3.3 模型训练
5.3.4 模型评价
5.3.5 模型预测
使用前馈神经网络实现MNIST识别,与LeNet效果对比。(选做)
可视化LeNet中的部分特征图和卷积核,谈谈自己的看法。(选做)
手写体数字识别是计算机视觉中最常用的图像分类任务,让计算机识别出给定图片中的手写体数字(0-9共10个数字)。由于手写体风格差异很大,因此手写体数字识别是具有一定难度的任务。
我们采用常用的手写数字识别数据集:MNIST数据集。
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。
这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28×28像素)。

5.3 基于LeNet实现手写体数字识别实验
LeNet-5虽然提出的时间比较早,但它是一个非常成功的神经网络模型。
基于LeNet-5的手写数字识别系统在20世纪90年代被美国很多银行使用,用来识别支票上面的手写数字。
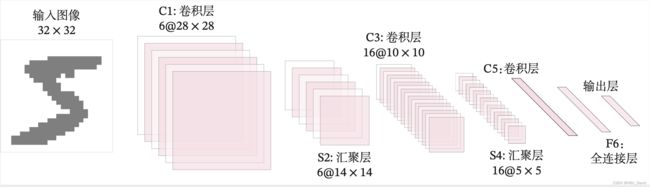
5.3.2 模型构建
这里的LeNet-5和原始版本有4点不同:
- C3层没有使用连接表来减少卷积数量。
- 汇聚层使用了简单的平均汇聚,没有引入权重和偏置参数以及非线性激活函数。
- 卷积层的激活函数使用ReLU函数。
- 最后的输出层为一个全连接线性层。
网络共有7层,包含3个卷积层、2个汇聚层以及2个全连接层的简单卷积神经网络接,受输入图像大小为32×32=1024,输出对应10个类别的得分。
1.测试LeNet-5模型,构造一个形状为 [1,1,32,32]的输入数据送入网络,观察每一层特征图的形状变化。
2.
使用自定义算子,构建LeNet-5模型
自定义的Conv2D和Pool2D算子中包含多个for循环,所以运算速度比较慢。
飞桨框架中,针对卷积层算子和汇聚层算子进行了速度上的优化,这里基于paddle.nn.Conv2D、paddle.nn.MaxPool2D和paddle.nn.AvgPool2D构建LeNet-5模型,对比与上边实现的模型的运算速度。
使用pytorch中的相应算子,构建LeNet-5模型
torch.nn.Conv2d();torch.nn.MaxPool2d();torch.nn.avg_pool2d()
3.测试两个网络的运算速度。
4.令两个网络加载同样的权重,测试一下两个网络的输出结果是否一致。
5.统计LeNet-5模型的参数量和计算量。
在飞桨中,还可以使用paddle.flopsAPI自动统计计算量。pytorch可以么?
5.3.3 模型训练
使用交叉熵损失函数,并用随机梯度下降法作为优化器来训练LeNet-5网络。
用RunnerV3在训练集上训练5个epoch,并保存准确率最高的模型作为最佳模型。
5.3.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失变化情况。
5.3.5 模型预测
同样地,我们也可以使用保存好的模型,对测试集中的某一个数据进行模型预测,观察模型效果。
使用前馈神经网络实现MNIST识别,与LeNet效果对比。(选做)
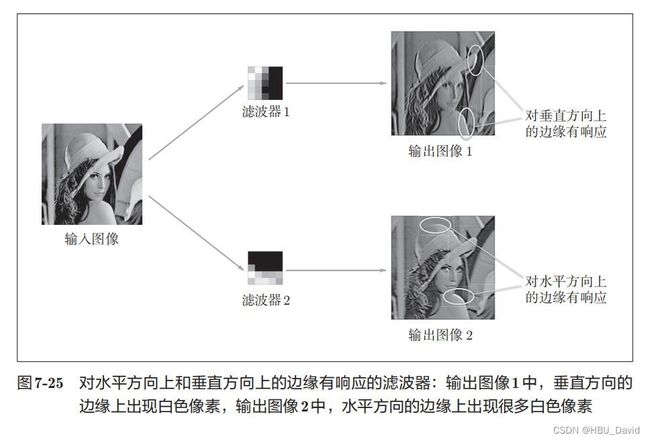
可视化LeNet中的部分特征图和卷积核,谈谈自己的看法。(选做)
斋藤康毅:
深度学习入门:基于Python的理论与实现 (ituring.com.cn)






ref:
NNDL 实验5(上) - HBU_DAVID - 博客园 (cnblogs.com)
NNDL 实验5(下) - HBU_DAVID - 博客园 (cnblogs.com)
6. 卷积神经网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
7. 现代卷积神经网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)