论文解读1《TA2N: Two-Stage Action Alignment Network for Few-Shot Action Recognition》少镜头动作识别
《TA2N: Two-Stage Action Alignment Network for Few-Shot Action Recognition》少镜头动作识别
TA2N:用于少镜头动作识别的两阶段动作对齐网络
链接:https://arxiv.org/abs/2107.04782v3
1.摘要
少数镜头动作识别旨在仅使用几个样本(支持)识别新的动作类(查询)。当前的大多数方法遵循度量学习范式,该范式学习比较视频之间的相似性。然而直接测量这种相似性并不理想,因为不同的动作实例可能显示出不同的时间分布,从而导致查询和支持视频之间的严重错位问题。 本文从两个不同的方面来解决这个问题——动作持续时间偏差和动作演化偏差。我们通过两阶段行动协调网络(TA2N)依次解决这些问题。 1. 第一阶段通过学习时间仿射变换来定位动作,该变换将每个视频特征扭曲到其动作持续时间,同时消除与动作无关的特征(例如背景)。 2.第二阶段通过执行时间重排和空间偏移预测来协调查询特征以匹配支持的时空动作演变。 在基准数据集上的大量实验表明,所提出的方法在实现最先进的少量动作识别性能方面具有潜力。
2.绪论
2.1Few-shot Learning
The Prototypical Network使用前馈神经网络嵌入任务示例,并使用类质心执行最近邻分类等,虽然这些方法在图像识别任务中表现良好,但将它们直接转移到动作识别中并不理想。
2.2Few-shot Action Recognition
OTAM 明确地将视频序列与动态时间扭曲(DTW)算法的变体对齐。TA2N在时空方面对齐行动,而OTAM只考虑时间维度。
2.3动作持续时间偏差(ADM)和动作进化失准(AEM)在三种数据集上的情况
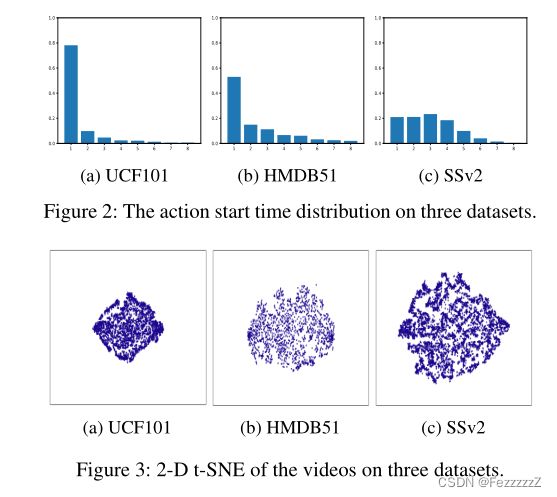
ssv2数据集的开始时间非常分散,错位问题也更严重
3.方法
1.数据集
训练集包含每个类足够的标记数据,而测试集中只有少量的标记样本。验证集仅用于在训练期间评估模型。此外,这三个集合之间没有重叠的类别。通常,少镜头动作识别的目的是训练一个分类网络,它能很好地泛化到测试集中的新类。
N-way K-shot 代表query种N种类别,每种有K张
2.特征嵌入
对于每个输入视频,视频分成T段进行采样,特征嵌入网络f(·)以其为输入,将序列X嵌入到T帧级特征fX = f(X) = {f(x1), f(x2),…, f(xT)}
fs、fq来表示支持样本和查询样本的视频级特征
3.TTM模块(时间转换模块)
首先通过时间转换模块(TTM)对嵌入式视频特征进行转换,以解决动作持续时间不一致的问题。
时间转换模块(TTM)由两个部分组成:局部网络L和时间仿射变换T。
3.1局部网络 Localization Net
给定输入帧级特征序列fX,定位网络首先生成扭曲参数φ = (a, b) = L(fX)。
L在我们的实现中由几个轻可训练的层组成
theta_support=self.locnet(support)
theta_query=self.locnet(query)
3.2 时间仿射变换Affine transform:
具体地,给定输入帧级特征序列fx,定位网络首先生成扭曲参数φ=(a,b)=L(fx)
然后通过仿射变换Tφ对输入特征序列进行扭曲。
扭曲support和query
动作持续时间失调在帧序列之间具有线性特征,因此扭曲用线性时间插值表示。这也促进了整个pipline的可微性,因此我们可以以端到端方式联合训练我们的分类器和TTM。
在集训练和测试过程中,首先将支持和查询样本的所有特征序列送入TTM进行第一阶段时间对齐,将它们的视频特征大致对齐到它们的动作周期。这样,TTM阶段迎合了缓解动作持续时间失调问题的需要。
4.ACM模块(动作坐标模块)
ACM(动作坐标模块)沿时间和空间维度对支持和查询功能进行精细协调。
动作进化不对中,是由于视频中动作的非线性进化造成的,这是基于线性的TTM无法充分解决的。为此,我们从时间和空间两个方面协调视频之间的动作演化。
4.1时间TC
为了使视频之间的动作演化在时间上保持一致,视频之间相似的运动模式应该聚合到相同的时间位置。为全局协调任务,查询视频的运动演化可以被临时重新安排以匹配支持视频.
支持与查询之间的运动演化相关性M:
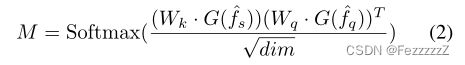
attentions=torch.einsum('ncx,mcy->nmxy',keys,querys)/(self.dim[1]**0.5)
其中Wk, Wq为线性投影层:
keys =self.keynet(support)
querys=self.querynet(query)
G为空间维的全局平均池化,其输出张量形状为C × T × 1 × 1,即只在时间维上计算相关性
support=rawsupport.mean((-2,-1))
query =rawquery .mean((-2,-1))
Softmax将M中的值限制为[0,1]。
计算归一化运动相关矩阵M与查询特征之间的矩阵乘法,我们可以暂时重新排列查询特征
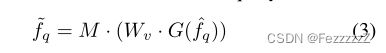
同样,支持特征fs也做同样的处理:在一致的演化过程中具有相同的时间位置,可以缓解时间方面的AEM。
时间协调(TC)保证动作在持续时间内以相同的过程发展。然而,角色进化的空间变异,如角色的位置,对动作识别也至关重要,这是TC无法模拟的。因此,我们进一步设计了一种空间操作来减少动作进化的空间变异。在时间对齐良好的特征的基础上,我们的目标是预测每个成对帧的空间偏移量,然后只在相交区域测量它们的相似性。
4.2空间SC
具体来说,空间协调包括两个步骤:轻型偏移预测和偏移掩模生成。
4.2.1轻型偏移预测:
给定时间上对齐良好的特征fs,fq,被馈送到偏移预测器S(self.mvnet)中,
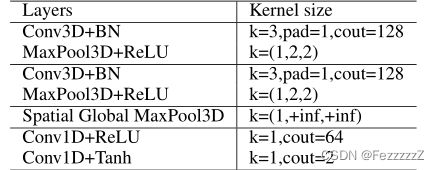
以预测所有时间戳在x和y坐标中的空间偏移O
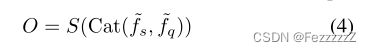
offsets=self.mvnet(pairs).transpose(1,2)
4.2.2偏移掩模生成
为了以可微的方式计算交集区域的相似度,对于每一帧,使用生成的偏移掩码I来计算每个特征在交集上的平均特征。此外,在相交区域内掩模值为1,在边缘处逐渐减小为0。
然后对查询和支持特征同时执行掩码,作为加权平均的权重:
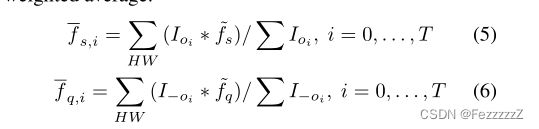
为了扩大偏移量预测器的探索空间,在预测偏移量上增加一些扰动,并使用不同扰动对应特征的平均值。
其中掩码oi的生成:
二维偏移掩模Io = mx × my
mask=mask_y.unsqueeze(-1)*mask_x.unsqueeze(-2)
加在偏移量上的扰动是8向矢量,振幅每40个周期衰减一次。我们对不同扰动下产生的掩模进行平均得到最终的掩模。
通过TC和SC,消除了视频之间动作演化的时空错位。
在最终的距离测量和分类中,使用了良好对齐的配对特征fs和fq作为原型网络方案
5.训练
我们用与ProtoNet 框架类似的方式训练,具有标准的软最大交叉熵。已知查询样本fq的对齐特征,加上c类的支持原型pcs(对k-shot支持特征应用TC并求平均值),可得分类概率为:

其中d(f, p)是帧方向的余弦距离度规。则分类损失计算为:
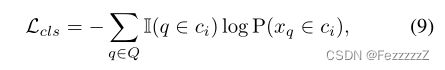
其中Ⅱ是一个指标函数。D表示距离度量,因此我们在实现中采用了时变余弦距离。Q和C分别表示查询集及其对应的类标签集合。
6.实验结论
采用TSN引入的标准方法对每个视频统一采样8帧。提取的帧首先调整为256×256,并应用随机水平翻转。然后在训练过程中应用大小为224×224的随机裁剪。使用ImageNet预先训练的ResNet50作为特征提取器,以便与之前的方法进行公平的比较。
在四个基准测试中,TA2N比SSv2获得了最显著的改进。这一发现与数据集失调状态的定量分析相一致,其中SSv2表现出最严重的失调问题。这进一步证明了对齐模块的有效性。