pandas算术运算、逻辑运算、统计运算describe()函数、统计函数、累计统计函数及自定义函数运算
一、pandas算术运算
直接对数据进行加、减、乘、除等运算,可使用函数add()、sub()、mul()、div()或+、-、×、÷
代码如下
数据生成
import pandas as pd
import numpy as np
# 数据生成代码
num = np.random.randint(50, 100, (3, 5))
# 传入标签索引
column = ['第一列', '第二列', '第三列', '第四列', '第五列'] # 列标签索引
# ind = ['第一行', '第二行', '第三行'] # 行标签索引
ind = ['第_' + str(i) + '_行' for i in range(num.shape[0])] # 行标签索引,num.shape[0]即获取num数组的行号,此处为3
data2 = pd.DataFrame(num, columns=column, index=ind)
data2
---------------------------------------------------
data2['第二列'].add(10) # 第二列的值加10
data2['第二列'].sub(10) # 第二列的值减10
data2['第二列'] - 20 # 第二列的值减20
data2['第二列'] / 2 # 第二列的值除2

二、pandas逻辑运算
2.1 运算符合
使用>、<、=、&、|、~等运算符对数据进行筛选
使用示范代码如下
# 数据生成
import pandas as pd
import numpy as np
# 数据生成代码
num = np.random.randint(50, 100, (3, 5))
# 传入标签索引
column = ['语文', '数学', '英语', '物理', '政治'] # 列标签索引
# ind = ['name1', 'name2', 'name3'] # 行标签索引
ind = ['name' + str(i) for i in range(num.shape[0])] # 行标签索引,num.shape[0]即获取num数组的行号,此处为3
data3 = pd.DataFrame(num, columns=column, index=ind)
data3
-------------------------------------------
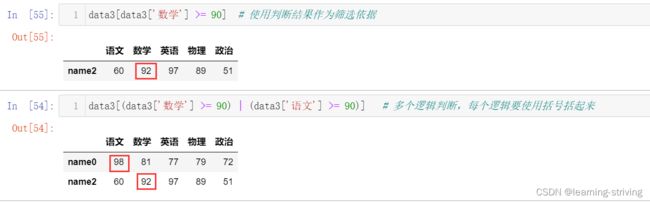
data3['数学'] >= 90 # 逻辑判断
data3[data3['数学'] >= 90] # 使用判断结果作为筛选依据
data3[(data3['数学'] >= 90) | (data3['语文'] >= 90)] # 多个逻辑判断,每个逻辑要使用括号括起来操作如下

2.2 运算函数
- query(expr):根据要评估的条件进行过滤查询
- expr:查询字符串
- isin(values):对指定values值进行逻辑判断
具体使用代码如下
data3.query('数学 >= 90 | 语文>= 90') # 多个逻辑判断,条件要加上引号
data3.query('~(语文 >= 90)') # ~为非,即取反,条件要加上引号
data3[data3['数学'].isin([60, 92, 99])] # 判断是否在指定值中并筛选操作演示如下

三、统计运算
3.1 describe()函数
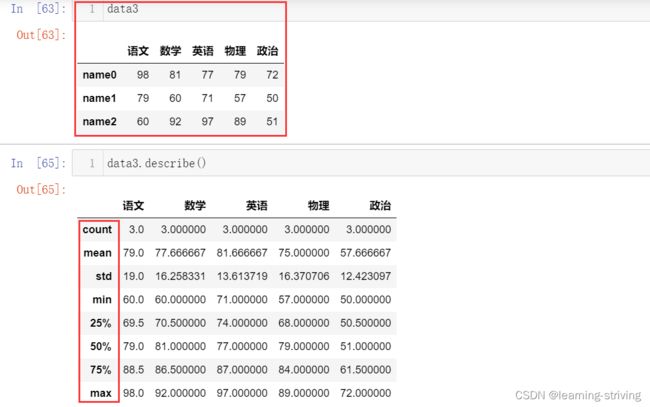
- describe():综合分析,能够直接得出很多统计结果,用来返回series和DataFrame两个核心数据结构的统计变量,如
count,mean,std,min,max等,含义如下- count:统计元素个数,此列共有多少有效值
- mean:均值
- std:标准差
- min:最小值
- 25%、50%、75%:返回数组的三个不同百分位置的数值,即统计学中的四分位数,其中50%对应的是中位数,分别为四分之一分位数、二分之一分位数、四分之三分位数
- max:最大值
3.2 统计函数
对单个函数进行统计的时候,坐标轴按默认列,即axis=0统计,如要对行统计,需要指定axis=1,如sum(1)
| 函数方法 | 含义功能 |
|---|---|
count() |
非空元素个数 |
sum() |
值的总和 |
mean() |
平均值 |
median() |
中位数 |
min() |
最小值 |
max() |
最大值 |
mode() |
模式,每一列/行按从小到大显示 |
abs() |
绝对值 |
prod() |
价值的乘积,每一列/行的每个数相乘 |
std() |
标准差 |
var() |
均方差 |
idxmax() |
计算具有最大值的索引标签 |
idxmin() |
计算具有最小值的索引标签 |
代码如下
import pandas as pd
import numpy as np
# 数据生成代码
num = np.random.randint(50, 100, (3, 5))
# 传入标签索引
column = ['语文', '数学', '英语', '物理', '政治'] # 列标签索引
# ind = ['name1', 'name2', 'name3'] # 行标签索引
ind = ['name' + str(i) for i in range(num.shape[0])] # 行标签索引,num.shape[0]即获取num数组的行号,此处为3
data3 = pd.DataFrame(num, columns=column, index=ind)
data3
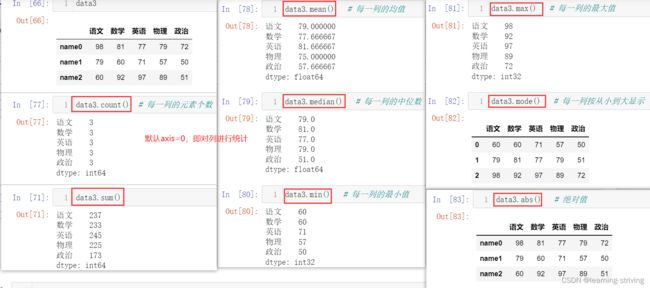
data3.count() # 每一列的元素个数
data3.sum()
data3.mean() # 每一列的均值
data3.median() # 每一列的中位数
data3.min() # 每一列的最小值
data3.max() # 每一列的最大值
data3.mode() # 每一列按从小到大显示
data3.abs() # 绝对值
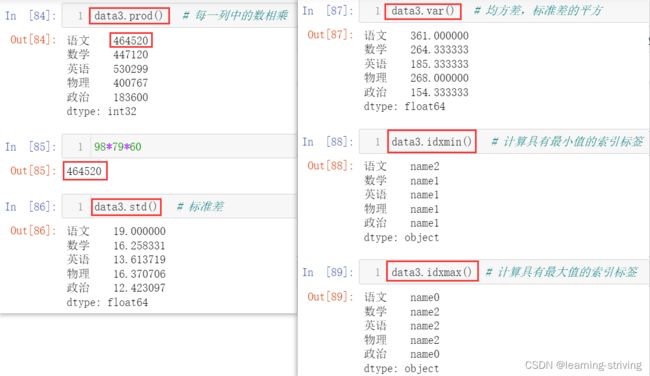
data3.prod() # 每一列中的数相乘
data3.std() # 标准差
data3.var() # 均方差,标准差的平方
data3.idxmin() # 计算具有最小值的索引标签
data3.idxmax() # 计算具有最大值的索引标签
data3.sum(1) # 计算每一行的和,不填1默认为0,即统计列
data3.mean(1) # 计算每一行的均值操作演示如下

3.3 累计统计函数
| 函数 | 作用 |
|---|---|
cumsum() |
计算前1/2/3/…/n个数的和 |
cummax() |
计算前1/2/3/…/n个数的最大值 |
cummin() |
计算前1/2/3/…/n个数的最小值 |
cumprod() |
计算前1/2/3/…/n个数的积 |
代码如下
import pandas as pd
import numpy as np
# 数据生成代码
num = np.random.randint(50, 100, (3, 5))
# 传入标签索引
column = ['语文', '数学', '英语', '物理', '政治'] # 列标签索引
# ind = ['name1', 'name2', 'name3'] # 行标签索引
ind = ['name' + str(i) for i in range(num.shape[0])] # 行标签索引,num.shape[0]即获取num数组的行号,此处为3
data4 = pd.DataFrame(num, columns=column, index=ind)
data4
-----------------------------------------------
data4['数学'].cumsum() # 计算指定列中前n个数的和
data4.cumsum() # 计算前1/2/3/…/n个数的和
data4.cummax() # 计算前1/2/3/…/n个数的最大值
data4.cummin() # 计算前1/2/3/…/n个数的最小值
data4.cumprod() #计算前1/2/3/…/n个数的积
84*90*84演示操作如下


3.4 自定义运算
- apply(func, axis=0):自动根据func遍历每一个数据,然后返回一个数据结构为Series的结果
- func:自定义函数
- axis:取0默认是列,axis=1为行
代码及操作如下
data4.apply(lambda i : i.max() - i.min()) # 求每一列中最大值与最小值的差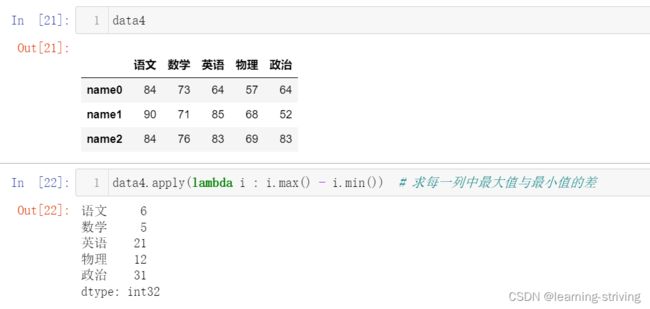
学习导航:http://xqnav.top/