谣言检测文献阅读五—Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection
系列文章目录
- 谣言检测文献阅读一—A Review on Rumour Prediction and Veracity Assessment in Online Social Network
- 谣言检测文献阅读二—Earlier detection of rumors in online social networks using certainty‑factor‑based convolutional neural networks
- 谣言检测文献阅读三—The Future of False Information Detection on Social Media:New Perspectives and Trends
- 谣言检测文献阅读四—Reply-Aided Detection of Misinformation via Bayesian Deep Learning
- 谣言检测文献阅读五—Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection
- 谣言检测文献阅读六—Tracing Fake-News Footprints: Characterizing Social Media Messages by How They Propagate
- 谣言检测文献阅读七—EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
- 谣言检测文献阅读八—Detecting breaking news rumors of emerging topics in social media
文章目录
- 系列文章目录
- 前言
- 1 介绍
- 2. 数据集和数据收集
-
- 数据集
- 3.发现突发谣言
-
- 3.1 隐式链接
-
- 3.1.1 标签链接(Twitter中为“ #H7N9” , 在新浪微博中为“ #H7N9#”)
- 3.1.2 网络链接
- 4. 结果
-
- 4.1 零修剪分类
- 4.2 早期检测和检测截止时间
- 4.3 剪枝分类
- 5.相关工作
-
- 5.1 流行病模型
- 5.2 基于用户和消息的分类
- 5.3 传播增强分类
- 6.结论和今后的工作
前言
文章:Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection
发表会议:2016 CIKM (International Conference on Information and Knowledge Management)
时间:2016年10月
1 介绍
- 对话M,M具有 m i m_i mi相关对话(message),其中 i ∈ { 1 , . . . , ∣ M ∣ } i ∈\{1, ..., |M|\} i∈{1,...,∣M∣}
- F ( M t ) = α F (M_t) = α F(Mt)=α,其中 t t t是检测时限( F ( M 1 ) < F ( M t ) < F ( M ∣ M ∣ F(M_1) < F(M_t) < F(M_{|M|} F(M1)<F(Mt)<F(M∣M∣)。),α是检测准确率
- 假设我们可以找到一些具有相同性质的相关会话(conversation)N,并且 N i < M 1 N_i
Ni<M1 ,是否有可能利用N中的附加信息,使 F ( N i + M t ) > F ( M t ) F(N_i+M_t)>F(M_t) F(Ni+Mt)>F(Mt)? - 很重要的一点是要知道 F ( M ∣ M ∣ ) > F ( N i + M t ) F(M_{| M |})>F(N_i+M_t) F(M∣M∣)>F(Ni+Mt)在哪一点(如果有的话),因为从直觉上看,近似值 N i + M t N_i+M_t Ni+Mt的表现可能不如 M ∣ M ∣ M_{| M |} M∣M∣
根据显式链接的定义,即那些显式创建为会话响应函数的链接,我们将隐式链接定义为基于某种相似性连接会话结构,但不是社交媒体结构固有的链接。隐式链接可以通过使用相关对话中的额外信息来减少紧急对话结构固有的噪音,这可以显著提高新谣言对话的检测率。相关的对话统计数据也可以用来改善已有谣言中的鉴别特征,以提高分类准确性。然而,这也是一个具有挑战性的命题,因为决定应该连接哪些数据、应该应用哪些增强数据源、应该采取哪些步骤来减少类之间的交叉污染,以及哪些类型的链接提供了最佳的区分功能,这并不是一件小事。本文的主要贡献有: - 我们设计了一种以对话为中心的方法来收集谣言数据以及策划的基本事实;
- 我们识别和分析隐含的链接、它们的分布以及它们在发现谣言出现阶段的影响;
- 我们提出了两种发现隐式链接的方法,包括:Hashtag Linkage 和 Web Linkage。
2. 数据集和数据收集
数据集
Castillo 等人创建,该数据集由 280 个独立的推文组组成,是基于关键词进行收集的,即给每个事件一组关键词,然后根据关键词收集该事件的数据,我们将与特定标签关联的所有推文组称为对话(conversation)。该基于关键词进行数据收集特征:
- 无法包含回复推文中对话结构或重要上下文信息
- 平均 对话生命周期长达29.57小时
- 推文中的内容可变性较低。
研究对话结构、回复内容和用户参与度的影响对于早期发现谣言是必要的,因为新闻报道固有的滞后时间会降低发现速度。为了解决这个问题,我们通过Snopes构建了一个新的数据集,可以自动捕获与谣言相关的对话树。
注:Snopes是一个谣言识别网站(谣言指的应该是虚假的消息),作者通过这个网站收集虚假新闻和真实新闻
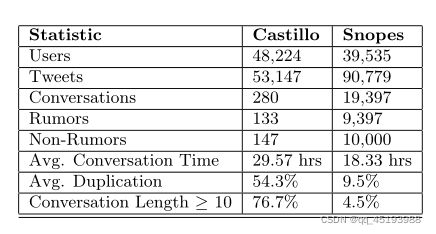
注:Avg Duplication 应该是所有对话的平均复制率,有些对话中可能存在大量复制的对话
3.发现突发谣言
于会话(conversation)中的每条给定推文,我们使用Ma等人提出的一组特征提取一个特征向量 t ^ \hat{t} t^。然后,用于分类的会话(Conversation)特征向量可以使用给定会话(Conversation)中带有链接的推文特征的 z-score 归一化平均值来构建。
z分数(z-score),也叫标准分数(standard score)是一个数与平均数的差再除以标准差的过程
处理后的数据均值为0,方差为1,符合标准正态分布,且无量纲。其主要目的是将不同量级的数据统一化为同一个量级,统一用计算出的Z-Score值衡量,保证了数据间具有可比性。
 其中 θ i θ_i θi是聚合会话特征集 θ θ θ中的第 i i i个特征, t i t_i ti是所有会话(conversation)的第 i i i个特征的平均值(average), µ t i µ_{t_i} µti是平均值(mean), σ t i σ_{t_i} σti是标准偏差。(非要解释的话,只能解释为每个conversation一个特征向量,但是这样解释同样存在一些问题 t i t_i ti是所有会话(conversation)的第 i i i个特征的平均值,这样算出来的实际上就应该是所有对话的特征值的第i个特征的 z-score 归一化平均值,即280个会话的第i个特征的分数,那么这个如果是共有20个特征,这个算的就是20个值,整个数据集20个值,但是这么看还是有问题 µ t i µ_{t_i} µti还是不能解释的很清晰,按照这个推测,那么 µ t i µ_{t_i} µti应该写作 µ t µ_{t} µt)因此,我们可以将所有对话向量分组到集合R中(怎么分组,以什么标准分组,也没说)。
其中 θ i θ_i θi是聚合会话特征集 θ θ θ中的第 i i i个特征, t i t_i ti是所有会话(conversation)的第 i i i个特征的平均值(average), µ t i µ_{t_i} µti是平均值(mean), σ t i σ_{t_i} σti是标准偏差。(非要解释的话,只能解释为每个conversation一个特征向量,但是这样解释同样存在一些问题 t i t_i ti是所有会话(conversation)的第 i i i个特征的平均值,这样算出来的实际上就应该是所有对话的特征值的第i个特征的 z-score 归一化平均值,即280个会话的第i个特征的分数,那么这个如果是共有20个特征,这个算的就是20个值,整个数据集20个值,但是这么看还是有问题 µ t i µ_{t_i} µti还是不能解释的很清晰,按照这个推测,那么 µ t i µ_{t_i} µti应该写作 µ t µ_{t} µt)因此,我们可以将所有对话向量分组到集合R中(怎么分组,以什么标准分组,也没说)。
这个是被引用文献【9】的公式:
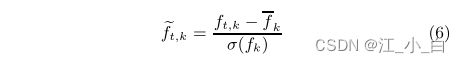
为了提高辨别质量,我们创建了几种类型的隐式链接,我们将其定义为其他不相关对话之间的潜在上下文线索或相似性。例如,如果对话A正在讨论事件C,我们可以确定对话B也在讨论事件C,那么我们可以声称这些对话之间存在隐含的联系。 这是有益的,因为额外的用户和内容信息有助于减少由连接响应太少的异常讨论引起的噪音。为了实现这一点,我们需要一个适当的转换,可以容纳各种类型的隐式链接。我们的表述如下:

其中 I I I 是任何定义的隐式链路发现公式, N N N 是发现链路的数量(根据是否大于评定是否在 R ′ {R}' R′中 N N N没有存在的必要), I θ \mathbb{I}_θ Iθ 是定义隐式链路 I I I 是否存在于 θ θ θ 中的指示函数(同样没说指示函数是什么)。对集合的附加约束提供了过滤,可以在没有任何倾斜特征值的情况下减少这些对话(conversations)(减少对话,不明白,要判断的就是对话的真假,为什么要减少对话,而不是减少推特或者message )。实际上这种转换会丢弃任何不会随时间变化并且也无法链接到其他收集到的对话的对话。 (感觉公式中的不应该用 θ θ θ,应该用 θ i θ_i θi)
3.1 隐式链接
隐式链接是在没有链接的对话之间可以发现的任何形式的相似性。
3.1.1 标签链接(Twitter中为“ #H7N9” , 在新浪微博中为“ #H7N9#”)
标签的使用在社交媒体交流中变得非常普遍。由于主题标签(hashtag)是一种通用抽象,因此很容易在推文中找到链接。因此,很难确定使用主题标签(hashtag)形成的隐式链接能在多大程度上影响提取的对话特征。
3.1.2 网络链接
虽然网络链接形成的隐性链接很少,但有更强的相似性证据。在这种情况下,当两个没有链接的会话使用相同的web链接时,就形成了一个会话链接。这是一个非常严格的要求,它强制相似性下降到一个web域的单个页面级别。直观地说,可以放宽这一要求,允许在提供相同域或类似web内容类型链接的对话之间形成链接。然而,为了量化其对于准确率的影响,我们坚持一个严格的网站链接政策,哪怕以牺牲额外的常规链接发现为代价。
推测是推特中的相关链接,如果推特A和推特B的含有同一个链接,则将A、B同时作为某个对话中的推特
4. 结果
为了验证隐式链接技术的有效性,我们通过三个不同的实验来检查这个问题。第一个实验涉及在两个数据集上使用建议的链接方法执行分类而不执行修剪。这使我们能够研究链接方法与标准分类方法的关系。第二个实验涉及使用检测期限来确定添加外部数据的影响,以及在什么时候(如果有的话)算法将获得最佳性能。第三个实验涉及使用多个分类器对修剪后的数据集进行分类,以了解链接方法、可分离性和分类性能之间的关系。
4.1 零修剪分类
与标准谣言检测相比,隐式链接谣言检测的一个主要优势是能够对数据集进行分类,而不会删除那些会产生过多噪音的数据。为了证明这一点,我们使用线性支持向量机(SVM)和10重交叉验证进行分类。对每种方法进行十次实验,并对结果进行平均。首先,所有280个对话都在Castillo数据集中进行了分类。如图1所示,当未采用修剪策略时,标准分类无法捕获区分模式。然而,随着隐式链接的增加,我们使用这三种方法进行的分类测量都有所增加。特别是,与未链接的性能相比,标签链接显示所有指标平均提高30%。网络链接也能在辨别能力上取得微小的提高。然而,这是可以接受的,因为Castillo新闻数据集的极度重复性在对话中包含非常低的可变性,导致很少有web链接匹配。对 Snopes 数据集中的所有 19,397 个对话重复相同的过程。遵循与 Castillo 数据相同的模式,当不使用隐式链接来缓解问题时,未修剪的分类再次失败。此外,较大的数据集会导致召回率严重下降。幸运的是,这两种链接方法都极大地提高了分类性能。

图 1:对 Castillo 数据集进行分类而不删除小对话会导致近乎随机的分类性能。 Hashtag 链接表现良好,而 Web 链接提高了性能,但由于难以在数据集中找到链接而受到阻碍。
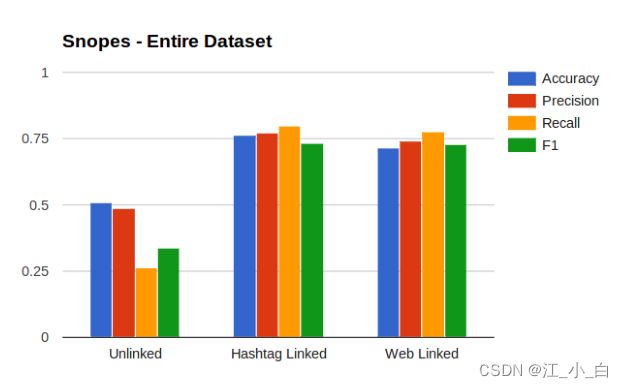 图 2:与 Castillo 数据集类似,Snopes 数据集上的分类表现不佳。由于真实对话数据的广泛可变性,所有链接方法都表现良好。
图 2:与 Castillo 数据集类似,Snopes 数据集上的分类表现不佳。由于真实对话数据的广泛可变性,所有链接方法都表现良好。
4.2 早期检测和检测截止时间
通过 1.1 节给出的问题公式,之前的实验能够表明,将会话 N 中的会话数据添加到 M 中能够显着提高性能。为了确定随着时间的推移改进的程度,我们通过添加检测期限进行分类。在初始状态下,检测截止日期 t t t 从第 0 小时开始,第一条推文被公开以进行分类。因此,在时间 t = 0 t = 0 t=0 时,使用 F ( N t + M 1 ) F (N_t + M_1) F(Nt+M1) 执行分类,其中 N N N 是任何隐式可链接对话,如果使用隐式链接,则具有推文时间戳 t ≤ M 1 t ≤ M_1 t≤M1,否则为 M 1 M_1 M1。在每个连续的小时期限,即时间戳小于t的时间内的 M t M_t Mt和 N t N_t Nt中的所有推文都可以用于分类。
按照这个过程,在最初的检测截止日期,未链接的Snopes数据集能够正确地对大约350条推文进行分类,而隐式链接的分类正确数目是未链接的数据的两倍,即七百条推文进行分类。同样,Castillo隐式链接的数据优于未链接的分类,但差距较小。然而,随着检测截止日期的增加,更多的数据能够被合并到N中,对于两个隐式链接的数据集,在最初的六个小时内,可正确分类的实例数量显著增加。此外,与直觉相反,虽然随着时间的增加,改善增益变得微不足道,但由于合并估计的对话数据而导致的性能下降不会在前十个小时内发生。这表明,随着会话的增长,从估计数据中获得的性能增益并没有完全消除,而引入的错误变得可以忽略不计。虽然这与直觉相反,但这个结果可以通过使用平均聚合统计数据的分类过程来解释。这也表明,使用原则性的匹配过程,来自外部对话的数据可以改善一般情况下的分类结果。
4.3 剪枝分类
最佳情况下,应在不执行修剪的情况下应用隐式链接。然而,有必要使用当前最先进的方法进行分类,以便与以前的工作进行比较。使用几种最先进的谣言分类方法进行分类,包括决策树(DT)、动态序列时间结构(DSTS)、带SVM分类器的混合DSTS和RBF核方法。在之前的工作之后,只使用了10条或更多推文的对话,并使用10倍交叉验证进行分类。首先,这两个数据集在没有应用任何形式的隐式链接的情况下进行了分类。对于Castillo和Snopes数据集,使用RBF核,我们的分类准确率分别为66.2%和84.3%,如表2所示。对于这两个数据集,RBF核能够通过将特征向量投影到高维空间来提供改进的类间区分。与较简单的模型相比,很明显,未链接数据的性能差距可归因于无法线性分离的特征。

随着隐式标签链接发现的应用,Castillo 和 Snopes 数据集的分类准确率分别提高了 13.5% 和 9.9%。使用剪枝标签链接的分类结果如表 3 所示。同时,两个数据集的可分类对话量都有所提高。最大的收获是在经过显着修剪的 Snopes 数据集内——可分类实例的数量提高了三倍以上。此外,在未链接数据上看到的由可分离性困难引起的分类性能差距消失了。
 在这两个数据集中,特征的鉴别质量都得到了提高,使用更简单、耗时更少的分类器,不依赖于将特征投影到更高维空间,可以获得更高的准确度。网络链接是在Snopes数据集上执行的,然而,Castillo数据集的可分类实例和高度冗余的数据数量较少,不允许发现适当数量的链接。网页链接的分类结果见表4。网络链接将几种表现不佳的方法的分类准确率提高了2-3%,同时也对召回率产生了积极影响。
在这两个数据集中,特征的鉴别质量都得到了提高,使用更简单、耗时更少的分类器,不依赖于将特征投影到更高维空间,可以获得更高的准确度。网络链接是在Snopes数据集上执行的,然而,Castillo数据集的可分类实例和高度冗余的数据数量较少,不允许发现适当数量的链接。网页链接的分类结果见表4。网络链接将几种表现不佳的方法的分类准确率提高了2-3%,同时也对召回率产生了积极影响。
5.相关工作
5.1 流行病模型
社交媒体中的信息和谣言传播与流行病有许多共同特点。有几项研究在网络和信息流上使用了流行病模型
5.2 基于用户和消息的分类
提到了之前的一些基于机器学习的研究,但是这些研究没有实用性,并且所有这些先前的工作都执行某种形式的数据修剪方法,以减少数据中的噪声并提高分类准确性。虽然当早期发现谣言不是一个因素时,这通常是一个合理的权衡,但这种做法已经在专门设计用于提供早期结果的作品中变得普遍。这会导致没有实际适用性的误导性结果。幸运的是,我们的工作为谣言检测方法提供了一个重要的基石,这将使最新的工作能够正常运行,而无需通过利用相关数据来修剪数据。
5.3 传播增强分类
最近,对话传播统计数据被证明是检测谣言的有效信息来源。Wu等人[16]采用随机游走核来衡量底层对话网络中的相似性。结果表明,这种形式的结构信息几乎与所有其他分类特征的组合一样有效。与其他方法相比,这种形式的检测加上其他特征,准确率提高了6%。虽然这种对网络结构的依赖可以取得特别好的结果,但只有在允许对话结构发展超过24小时后,才能看到最高水平的准确性。其他工作[18,9]提出了一种基于时间序列的方法,该方法可以捕捉谈话过程中标准统计数据的变化。虽然我们的贡献主要集中在早期检测上,但我们确实提出了对这些方法的修改,使谣言能够准确分类,而不管统计数据的初始数量如何,从而克服了时间序列建模固有的少数几个重大问题之一。
6.结论和今后的工作
通过利用相关对话中的信息,隐性联系可以显著提高在谣言形成阶段对谣言进行分类的能力。通过使用隐式链接,研究表明,谣言分类可以通过历史数据进行扩充,以便通过计算成本低廉的分类模型获得最先进的结果。这一发现为谣言检测方法的发展铺平了道路,使其超越了删减方法,同时在仅一条推文上保持高度的准确性。
我们发现,通过添加隐式结构,不仅可以显着改善对单个推文的谣言检测,而且通过添加估计数据获得的性能增益不会随着对话的增长而削弱性能。我们发现,基于标签的链接提供了最强的改进,与未修剪数据集上的未链接分类相比,增益高达 30%。此外,我们发现表现不佳的分类方法从剩余的隐式链接类型中得到了改进。进一步的分析表明,必须谨慎使用隐式链接,因为过多的外部对话统计数据可能会损害检测准确性。我们的实验结果表明,通过将形成的链接数量限制在 5 到 10 之间,可以获得一致的精度增益。这项工作有许多可能的扩展。虽然主题标签对于发现类似对话非常有益,但对话之间的主题标签图结构揭示了可能为早期谣言检测提供额外线索的使用模式。同样,可以将在每种类型的对话中找到的某些类型的隐式链接的亲和力用作检测特征。最后,还有许多其他形式的潜在隐含链接,例如通过文档嵌入的内容相似性,这可以为信息真实性问题提供新的见解。虽然在这项工作中没有明确探索,但多标签数据集的创建允许许多令人兴奋的探索途径。例如,隐式链接分布可能会因谣言类型而异,就像非谣言一样。这可以允许发现与谣言的真实性相关的其他特征,这些特征可以用于隐式链接创建以及改进的真实性推断。