DSNet:Joint Semantic Learning for Object Detection in Inclement Weather Conditions
参考 DSNet:Joint Semantic Learning for Object - 云+社区 - 腾讯云
目录
摘要
1、简介
2、相关工作
2.1、目标检测
2.2、图像去雾
2.3、多任务学习
3、提出的方法
3.1、检测子网络
3.2、恢复子网络
3.2.1、CB模块
3.2.2、FR模块
4、实验结果
4.1.1、FOD数据集
4.1.2、有雾驾驶数据集
4.2、实现细节
4.3、结果在FOD数据集和Foggy驾驶数据集
4.3.1、FOD数据集消融研究
4.3.2、定性和定量结果
4.4、推理时间
5、结论
摘要
近五十年来,基于卷积神经网络的目标检测方法得到了广泛的研究,并成功地应用于许多计算机视觉应用中。然而,由于能见度低,在恶劣天气条件下检测物体仍然是一项重大挑战。在本文中,我们通过引入一种新型的双子网(DSNet)来解决雾环境下的目标检测问题。该双子网可以端到端训练并共同学习三个任务:能见度增强、目标分类和目标定位。通过包含检测子网和恢复子网两个子网,DSNet的性能得到了完全的提高。我们采用RetinaNet作为骨干网络(也称为检测子网),负责学习分类和定位目标。恢复子网通过与检测子网共享特征提取层,采用特征恢复模块增强可见性来设计。实验结果表明我们的DSNet在合成的有雾数据集上达到了50.84%的mAP,在公开的有雾自然图像数据集上达到了41.91%的精度。性能优于许多最先进的目标检测器和除雾和检测方法之间的组合模型,同时保持高速。
1、简介
近年来,智能自动驾驶汽车(IAVs)的发展吸引了相当多的研究关注,因为它有帮助人类驾驶的潜力,减少交通事故的数量,并改变城市景观。设计一个健壮可靠的IAV需要集成许多重要功能,包括但不限于目标检测[1]、[2]、跟踪[3]、[4]和人机交互[5]、[6]。目标检测在IAVs中起着至关重要的作用,它不仅可以确定每个目标所属的类别,在给定的图像中定位目标,而且可以帮助系统在复杂的驾驶环境中进行安全导航。近年来,人们引入了大量的目标检测方法和技术,并取得了令人印象深刻的效果,特别是使用深度卷积神经网络[7]、[18]、[18]、[10]、[11]、[12]、[13]、[14]、[15]、[16]、[17]、[18]的方法。虽然这些检测器在正常图像上显示出高性能,但在恶劣天气条件下,特别是在雾中,它们通常无法检测到物体,雾是驾驶场景中最常见的天气现象之一。原因是被捕获物体和相机之间的特定光谱被悬浮的小水滴、冰晶、灰尘和其他粒子吸收和散射,使从这些图像中提取的用于物体检测的特征降低。
传统上,为了提高存在雾霾情况下的目标检测性能,通常采用增强模糊图像的可见性作为预处理步骤。图像去雾既有利于人类对图像质量的视觉感知,也有利于许多必须在不同天气条件下运行的系统,如交通监控系统、智能车辆和户外物体识别系统。但是,将恢复性能较好的去雾模型预处理后的图像作为目标检测器的输入,并不一定能保证[19]的目标检测性能有所提高。此外,将除雾模型与检测方法相结合会增加去雾任务,从而降低检测速度。
本文提出了一种基于多任务学习的双子网目标检测方法来解决能见度较差的目标检测问题。为了实现这一目标,DSNet采用了最好的物体检测器之一,即RetinaNet[15]作为骨干网(表示检测子网),并在此基础架构上提出了特征恢复(FR)模块,构建了增强可见性的恢复子网,如图1所示。检测和恢复子网将在第3节中进一步介绍。我们以端到端的方式训练DSNet,以同时学习能见度增强、目标分类和目标定位。通过联合优化方案,将模糊输入图像中用于增强可见性的恢复子网络生成的清洁特征共享,在检测子网络中学习更好的目标分类和目标定位,帮助DSNet在恶劣天气条件下提高目标检测性能。

我们所提出的方法的主要特点如下:
1)、所提出的FR模块将学习与检测子网络协同完成目标定义,提高了在能见度较差的情况下目标检测的准确性。
2)、目标检测是通过增强可见性、目标分类和目标定位的联合优化来完成的。
3)、与基础检测网络相比,该模型保持了较高的速度。为了证明我们的方法的目标检测效率,我们评估了提出的模型在合成和自然雾数据集。定量和定性评价结果表明,我们提出的方法的精度超过了目前最先进的目标检测器和级联的去雾和检测模型。
本文的其余部分组织如下:第2节提供了目标检测、雾霾去除、多任务学习等相关工作。第3节描述了提出的目标检测方法,用于雾天图像。第4节给出了我们的方法与其他方法的综合实验结果。第5节总结了我们的工作。
2、相关工作
文献中介绍了许多目标检测、图像去雾和多任务学习方法。在本节中,我们简要回顾了一些当前的方法,并将注意力集中在基于深度学习的方法上,这些方法在这些领域中已经取得了显著的成果。
2.1、目标检测
基于卷积神经网络(CNNs)的目标检测在提高性能方面得到了广泛的关注,主要分为两大类:
1)基于region proposal的方法[7],[8],[9],[10],2)回归/基于分类的方法[11],[12],[13],[14],[15],[16],[17]。
在属于第一类的方法中,区域建议与CNNs (R-CNN族)[7]、[8]、[9]和基于区域的全卷积网络(R-FCN)[10]提出了基于区域建议方法创建感兴趣区域(RoIs)用于目标检测的方法。R-CNN[7]以一个输入图像,生成区域建议使用一个算法来计算分层分组相似的地区对许多兼容的元素如质地,颜色,大小,形状,等等,这是被称为选择性搜索[21],然后为每个提议雇佣了一个CNN来提取特征,最后采用支持向量机(SVM)进行分类。R-CNN在目标检测和语义分割方面与之前的[22]、[23]方法相比有了显著的改进。虽然R-CNN取得了令人印象深刻的准确性,但它仍然在训练和推理中消耗了相当多的时间。与R-CNN不同的是,Fast R-CNN[8]不是对每个区域建议提取特征,而是使用一个CNN提取整个图像的特征,补充一个RoI池化层,从每个区域建议中生成固定长度的特征向量,并用softmax层代替SVM分类器进行分类。受R-CNN和Fast R-CNN的启发,Ren等[9]提出了Faster R-CNN,通过引入一个额外的区域建议网络(RPN)来代替选择性搜索算法,以提高准确率和速度。RPN是一个全卷积网络,它以Fast R-CNN网络的特征图作为输入,输出一组候选边界框坐标及其得分。Dai等人[10]提出了R-FCN方法,采用101层的残差网络(ResNet-101)[24]骨干网和添加一个卷积的一层一层称为位置敏感RoI池最后卷积块这个网络地图和网格生成![]() 个位置敏感得分为每个类k×k。这个过程帮助R-FCN比更快的R-CNN获得更高的速度,因为每个RoI所需的计算量都大大减少。
个位置敏感得分为每个类k×k。这个过程帮助R-FCN比更快的R-CNN获得更高的速度,因为每个RoI所需的计算量都大大减少。
在属于第二类的方法中,YOLO族[11]、[12]、[13]、单阶段多框检测器(SSD)[14]和RetinaNet[15]提出了基于回归问题的方法,通过单个CNN直接从图像中预测边界框坐标和类概率。为了实现实时检测,Redmon et[11]等人提出了YOLO模型,该模型受GoogleNet[25]启发,采用24个卷积层和2个全连接层进行端到端训练,使用最顶层预测边界框、这些框的置信分数和类概率。YOLO家族的其他成员YOLO- v2[12]和YOLO- v3[13]通过改进特征提取的骨干架构、增加多尺度预测网络、改变联合训练的训练策略等,取得了较好的检测性能。Liu等人[14]提出了一种SSD方法,通过在主骨网VGG16[26]的基础上增加几个卷积层来处理小目标问题,并利用网络内的多尺度特征层次来检测不同尺度下的目标。Lin等[15]观察到在训练单一目标检测器时,前景类和背景类之间存在较大的差异。Lin的方法,即RetinaNet,通过引入基于交叉熵损失的focal loss进行分类训练,并采用特征金字塔网络进行多尺度预测,显示出了优越的准确率。
2.2、图像去雾
大气散射模型描述的模糊像的形成是由[28]的作者首先引入的,随后Nayar et al.[29]和Narasimhan et al.[30]对其进行了改进。大气散射模型可以写成:
![]()
式中,I(x)为相机捕捉到的模糊图像,J(x)为可视为无模糊图像的场景亮度,
![]()
式中,![]() 为大气散射系数,d(x)为场景深度。
为大气散射系数,d(x)为场景深度。
在大气散射模型的基础上,为了提高系统在恶劣天气条件下的性能,许多去雾方法被提出用于退化图像的能见度恢复。早期的去雾方法通常基于多种技术计算中间的模糊相关特征,包括但不限于,暗道先验[31],[32],最大对比度[33],色彩衰减[34],色调差异[35],来完成雾霾的去除。
最近,由于深度CNN在计算机视觉任务中的能力和成功,引入了使用深度CNN的去雾方法来提高雾霾去除性能。为了避免单幅图像对物理参数的估计不准确,DehazeNet[36]通过提供端到端的CNN从整幅图像生成一个媒介传输图来恢复模糊图像的能见度,然后将其应用到大气散射模型中来检索无模糊图像。MSCNN[37]采用了两种结构相似的网络,即粗尺度网络和细尺度网络。两种网络都由卷积、最大池、上采样和线性组合四部分组成,用于恢复模糊图像的可见性。首先,MSCNN利用粗尺度网络生成基于整幅图像的粗糙场景传输图。然后利用精细比例尺网络对传输图进行逐步细化。最后,利用精细传输,利用公式(1)得到无雾图像。Li等[38]认为,分别计算介质透射光和大气光会导致图像恢复过程中的误差累积。他们提出了一种一体化的去雾CNN,称为AOD-Net,将模糊图像作为输入,生成去雾图像作为模型的输出。Zhang等[39]提出了一种单图像去雾模型DCPDN,该模型在训练时同时估计传输图、大气光和去雾图像。利用多层特征进行透射估计,采用8块U-net[40]结构进行大气光估计,利用大气散射模型生成去雾图像。
2.3、多任务学习
多任务学习是指学习到的多个相关任务,同时从一个任务中学到的东西对其他任务也有好处。许多多任务学习方法被提出,并被证明是有效的计算机视觉领域的各种深度学习应用。Kendall等[42]引入了一种通过考虑每个任务的同方差不确定性来权重多个损失函数的方法,对三个任务进行联合推理,包括深度回归、语义和实例分割。Liao等人[43]提出了一种卷积神经网络,用于同时学习语义分割和分类,以增强机器人应用中的场景理解。在[44]中,作者成功地将多任务学习应用于实时自主驾驶应用中,其中分类、检测和语义分割任务被合并到一个称为多网络的模型中,该模型使用三个子网络。Lin等人[15]和Kokkinos[45]使用的方法也被用于在单一体系结构中学习回归和分类任务,用于目标检测。
在这项工作中,与[15]和[45]中报道的方法不同,我们的DSNet模型共同学习了三个任务,包括增强能见度、目标分类和在恶劣天气条件下检测目标的目标定位。据我们所知,我们是第一个证明了目标分类和定位可以通过结合可见性增强的联合学习来解决退化图像中目标检测问题的研究小组。
3、提出的方法
在本节中,我们将介绍一种新的双子网(DSNet),它可以在保持快速预测运行时间的同时,显著提高在恶劣天气条件下目标检测的准确性。我们的方法通过共同学习三个任务来实现这一目标,即增强可见性、目标分类和目标定位。提出的DSNet包括两个子网:1)检测子网络和2)恢复子网络。检测子网是利用一个CNN,即RetinaNet[15],与恢复子网共用一个block (CB)模块,负责目标分类和目标定位。通过在CB模块上附加一个提出的feature recovery (FR)模块来增强可见性,设计恢复子网,如图1所示。这两个子网共享CB模块,以确保该模块产生的clean feature (fC2)可以在两个子网进行联合学习时使用。利用检测子网可以对DSNet进行端到端的训练,并对目标进行预测。
3.1、检测子网络
正如在第2节中讨论的,许多基于CNN的目标检测器已经被提出来提高检测性能。然而,这些方法评估每个图像中不同的候选位置,尽管事实上只有少数位置包含目标。因此,现有的方法通常会遇到大量的类不平衡问题,在训练过程中,由于容易分类的背景例子占优势,会导致模型结果退化。RetinaNet[15]提出了使用focal loss来降低与良分类样本相关的loss的权重,并将更多的注意力放在难分类样本的学习上,以实现训练过程中各班之间的平衡。此外,RetinaNet采用了特征金字塔网络(FPN)[27],该网络提供了自上而下的路径和横向连接,使得从丰富的语义层构建更高分辨率的层,可以显著提高在霾存在下检测小物体的准确性。由于深层包含丰富的语义信息,但在汇集后缺乏位置信息,因此在深层与对应的浅层之间增加横向连接,丰富位置信息,提高准确性。基于这些原因,RetinaNet有潜力应对在低能见度条件下检测目标的挑战。因此,我们采用RetinaNet作为骨干网络,它与恢复子网络共享一些特征提取层称为CB模块,并在学习过程中与恢复子网络联合完成目标检测(CB模块在3.2小节中详细描述)。鉴于现有的众多RetinaNet模型,我们在模型中选择了具有ResNet-50[24]和输入图像尺度为500的RetinaNet(表示为RetinaNet或检测子网)。
为了有效地检测目标,检测子网遵循特定的策略。首先,利用ResNet-50架构提取整幅图像的feature map。接下来,在ResNet-50架构的顶部,构建并附加一个FPN[27]来构建多尺度特性,以应对不同尺度的目标。最后,通过在每个FPN级别上添加小的全卷积网络(FCNs)来完成目标分类和定位任务,实现卷积目标分类和边界框回归。
为了训练分类,检测子网采用了具有调优平衡变量的Focal Loss,描述为:

其中 代表类1,
代表类1, 为类-1,
为类-1,![]() 是一个可调的聚焦参数
是一个可调的聚焦参数 ,并且
,并且 的定义为:
的定义为:

其中y指定了ground-truth类别,![]() ,p是y=1时的概率,由模型估计,
,p是y=1时的概率,由模型估计,![]() 。
。
对定位,检测网络在预测框(k)和ground truth框参数(p)之间采用了![]() 损失,并且表示为
损失,并且表示为![]() ,其中q是匹配的数量。对每个匹配的锚框,ground truth框回归可以定义为
,其中q是匹配的数量。对每个匹配的锚框,ground truth框回归可以定义为![]() ,并且对应的预测框为
,并且对应的预测框为![]() ,其中x,y,w和h分别是两个框的中心坐标、宽度和高度。定位损失可以写为:
,其中x,y,w和h分别是两个框的中心坐标、宽度和高度。定位损失可以写为:

其中

3.2、恢复子网络
在我们的DSNet中,恢复子网负责生成![]() ,并在联合学习中与检测子网共享这些特性,以提高在能见度较差的情况下检测目标的精度。该子网在转换大气散射模型的基础上完成目标,使用两个模块:1)CB模块和2)FR模块,如图2所示。由式(1)中的大气散射模型得到的场景辐射亮度为:
,并在联合学习中与检测子网共享这些特性,以提高在能见度较差的情况下检测目标的精度。该子网在转换大气散射模型的基础上完成目标,使用两个模块:1)CB模块和2)FR模块,如图2所示。由式(1)中的大气散射模型得到的场景辐射亮度为:

如第2节所述,去除雾霾的方法是基于(6)中转换公式来增强模糊图像的能见度,其中分别评估介质传输(t(x))和全球大气光(次于)。但是,这种方法通常需要更多的步骤并增加模型的复杂性。受[38]的启发,恢复子网在增强可见性的过程中,将t(x)和次视图合并为一个变量。为此,将式(6)改写为:

其中

通过我们的模型对G(x)的估计和对J(x)的计算将在第2小节中更详细地表达。
3.2.1、CB模块
在我们的模型中,CB模块提取包含重要信息的输入图像的特征,用于同时学习增强能见度、目标分类和目标定位。CB模块不是单独设计的,而是配备了检测子网的部分剩余块。这种方法使我们能够保持提议的网络的简单架构。具体来说,在检测子网中将16个残块划分为4个残块阶段(分别为C2, C3, C4, C5)。鉴于特性从浅层次可能含有更多的空间信息,有利于更深层的可见性增强而降低在池中,我们选择第一个10的卷积层检测子网组成CB模块和以C2为该模块的输出,如图1中所示。生成的特征图被同时交付到FR模块用于增强可见性和Conv3 x用于检测物体。
3.2.2、FR模块
CB模块提取的输入图像的特征会受到雾霾的影响,导致目标检测性能较差。为了恢复![]() ,为了在联合学习过程中有效的推理出目标检测和目标分类,恢复子网提出使用FR模块。FR模块受[38]启发,由三个子模块组成:1)上采样子模块,2)多尺度映射(MM)子模块,3)图像生成(IP)子模块,如图2所示。
,为了在联合学习过程中有效的推理出目标检测和目标分类,恢复子网提出使用FR模块。FR模块受[38]启发,由三个子模块组成:1)上采样子模块,2)多尺度映射(MM)子模块,3)图像生成(IP)子模块,如图2所示。
3.2.2.1 上采样子模块:在我们的恢复子网中,输出图像和输入图像的大小相等。而使用CB模块提取特征后,fC2的大小为输入大小的1 / 4。因此,FR模块使用上采样子模块来匹配![]() 的分辨率和输入图像。
的分辨率和输入图像。
在[46]中,双线性插值技术已经被证明是重要的基于CNN的雾霾去除方法,其中合并的特征图是双线性上采样,为生成去雾输出做准备。受此方法启发,我们的上采样子模块首先采用1×1卷积层来降低特征维数;特别是![]() 的频道数减少了8倍。然后利用双线性插值将
的频道数减少了8倍。然后利用双线性插值将![]() 的大小放大到与输入图像相同的大小。
的大小放大到与输入图像相同的大小。
3.2.2.2 MM子模块:利用上采样子模块提高![]() 的分辨率后,得到的特征图
的分辨率后,得到的特征图![]() 被送到MM子模块进行多尺度特征提取。多尺度特征被广泛应用于多种除霾方法中,是提高能见度的有效方法。例如,在[36]中,通过使用不同内核大小的平行卷积层来形成介质传输估计的多尺度特征。在[38]中,作者提出了一种获取多尺度特征的方法,该方法是将所有网络层的特征串联起来,在一个统一的模型中生成去雾输出。
被送到MM子模块进行多尺度特征提取。多尺度特征被广泛应用于多种除霾方法中,是提高能见度的有效方法。例如,在[36]中,通过使用不同内核大小的平行卷积层来形成介质传输估计的多尺度特征。在[38]中,作者提出了一种获取多尺度特征的方法,该方法是将所有网络层的特征串联起来,在一个统一的模型中生成去雾输出。
受多尺度特征提取成果的启发,MM子模块基于Inception架构[25]并行采用卷积层提取多尺度特征,增强可见性。MM子模块由四个并行卷积组成,分别是一个1×1卷积、一个3×3卷积、一个5×5卷积和一个7×7卷积,其通道数相同,设为4。将得到的特征融合,然后再进行另一个3×3卷积,以估计包含介质传输(t(x))和全球大气光(![]() )的G(x),如Eq.(8)所示。
)的G(x),如Eq.(8)所示。
3.2.2.3 IP子模块:作为恢复子网的最后一步,利用IP子模块对场景辐射进行恢复。IP子模块以G(x)为输入,采用element-wise乘法层、element-wise减法层和element-wise加法层来计算变换后的式(7)。为了训练增强可见性,恢复子网络采用均方误差(MSE)损失,描述为:

其中n为bactch大小,![]() 为ground truth图像,
为ground truth图像,![]() 为估计的恢复图像。
为估计的恢复图像。
我们强调,虽然恢复子网可以直接生成无雾图像,但其目的不是生成无雾图像作为检测子网的输入,而是通过学习增强可见任务,从CB模块生成干净特征(![]() )。通过对可见性增强、目标分类和目标定位的联合优化,提高了模型的检测性能。
)。通过对可见性增强、目标分类和目标定位的联合优化,提高了模型的检测性能。
4、实验结果
本节总结了我们在恶劣天气条件下的目标检测方法的实验结果。为了进行实验,我们组成了一个用于检测雾中目标的数据集,称为雾目标检测数据集。通过对合成雾天数据集(FOD数据集)和自然雾天数据集(雾天驾驶数据集[47])预测质量和数量的评价,实现了本方法与目标检测方法的综合比较。第一个场景将我们提出的DSNet与四种最先进的目标检测模型进行比较,包括RetinaNet[15]、YOLO- v3[13]、SSD512[14]和Faster R-CNN[9]。在第二个场景中,我们的DSNet相比RetinaNet和三个最先进的dehazing模型:1)AOD-Net[38]与RetinaNet(表示AOD-RetinaNet), 2) DCPDN[39]与RetinaNet(表示DCPDN-RetinaNet),和3)CAP[34]和RetinaNet CAP-RetinaNet(表示)。


我们所有的实验都使用Keras,并在一个系统上运行,该系统使用Intel Core i5-8500 CPU @3.00 GHz, 16gb RAM和NVIDIA GeForce GTX 1070 Ti卡。
4.1.1、FOD数据集
为在恶劣天气条件下的目标检测而发表的数据集很少。Boyi等人[19]介绍了RTTS数据集,涉及4;322幅自然模糊图像,物体类别标注:公共汽车、自行车、汽车、摩托车、人。此数据集仅用于测试目的。为了评价真实雨天天气条件下的目标检测算法,Li[48]引入了两个集合,分别是driving set中的rainy和surveillance set中的rain。2000幅图像和5个物体(人、公共汽车、自行车、汽车、摩托车)被标记为边界框。在[47]中,作者收集了一个Foggy cityscapes精制数据集,包含550幅图像(498幅训练集图像,52幅验证集图像)。然而,这些数据集的规模太小,对于提高目标检测性能的深度CNN训练策略来说。
为了进行我们所有的实验,我们通过从公共雾天城市景观数据集[47]中收集图像,并标记两个类,即person和car,来组成一个FOD数据集。在FOD数据集中,从大雾城市景观的三种版本:浓雾、中雾和轻雾中精心挑选出6000张合成雾图像,衰减系数值分别为0.02、0.01和0.005。共有119979个目标实例按照Cityscapes[49]注释协议进行标记,其中person实例的数量为60279, car实例的值是59700。我们将FOD数据集分为三个集:训练集、验证集和测试集;每组图像之间不重复给定的图像。覆盖边框标注的示例图像和FOD数据集的统计结果分别如图3和表1所示。另外,考虑到提出的FOD数据集是基于Cityscapes数据集[49],我们可以使用ground-truth图像来训练恢复子网。
4.1.2、有雾驾驶数据集
雾驾驶数据集[47]是一个自然的雾数据集,用于测试目标检测和语义场景理解。它由超过500个车辆实例(汽车、卡车、公共汽车、火车、摩托车和自行车)和大约300个人类实例(人和骑手)组成,这些实例从101个自然雾图像中得到注释。
虽然雾驾驶数据集有少量的图像,它是一个具有挑战性的数据集,因为雾下高度复杂的场景。
4.2、实现细节
训练策略:我们对我们的DSNet应用微调方法来联合训练检测子网(RetinaNet)和恢复子网。在第一步,我们在ImageNet[50]上训练ResNet-50[24],因为提出的模型基于ResNet架构作为计算特征图提取的主干。然后在COCO[51]上训练检测子网用于目标预测。这个步骤不是从头开始训练,而是通过使用[15]中经过良好训练的模型来完成的。在第二步中,我们的模型在FOD数据集上进行端到端的训练,同时学习能见度增强、目标分类和目标定位。
损失函数:将Eq.(3)中定义的![]() 损失、Eq.(5)中定义的
损失、Eq.(5)中定义的![]() 损失和Eq.(9)中定义的
损失和Eq.(9)中定义的![]() 损失相加为联合训练的loss。
损失相加为联合训练的loss。
初始化:利用高斯随机变量对恢复子网络的权值进行初始化。检测子网不随机初始化权值,而是采用COCO数据集上经过训练的RetinaNet[15]模型,将该模型完全训练好的权值从80个类下采样到两个类(person和car)进行微调。
评估:利用PASCAL VOC度量[53]来评价雾天图像中目标检测的性能,[53]是一个众所周知的标准度量,其表示如下。对于每个目标类别,预测边界框与ground-truth边界框的并集相交定义为:

其中 是GT框的面积,
是GT框的面积, 是预测框的面积。
是预测框的面积。
如果IoU得分(阈值)大于0.5,则认为检测是正确的(真阳性),否则认为检测是错误的(假阳性)。为了测量目标检测器的性能,采用了基于精确回忆曲线的AP度量。PRC表示不同阈值的precision(记为![]() )和recall(记为
)和recall(记为![]() )之间的关系,其中
)之间的关系,其中![]() 和
和![]() 表示为:
表示为:

其中TP、FP和F N分别为真阳性、假阳性和假阴性的数量。AP表示曲线下面积PRC,定义为:

平均平均精度(average average precision, mAP)是所有对象类别AP的平均值,计算方法如下:
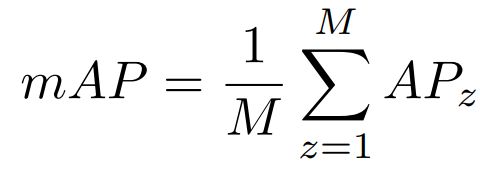
其中M是目标类别的数量。

4.3、结果在FOD数据集和Foggy驾驶数据集
4.3.1、FOD数据集消融研究
在本节中,为了确定所提模型的最佳设计,我们描述了我们的模型在FOD数据集上使用许多不同的设置运行,包括CB模块的结构、上采样技术,以及检测和恢复子网的单独使用。
CB模块和上采样的结构
我们研究了四种不同的结构,以有效地选择CB模块的因素。如图1所示,第一个结构由检测子网(RetinaNet[15])的前10个特征提取层组成。我们称这个版本为CB_C2,因为它的输出对应于剩余阶段C2的输出。第二种结构称为CB_C3,它利用比CB_C2模块多4个残差块(Conv3 x)来学习更深层次的特征,并以C3作为模块的输出。我们将继续研究CB模块的更深层次的体系结构,第三个和最后一个实现分别称为CB_C4和CB_C5。CB_C4丢弃ResNet的最后三个残块(Conv5 x)在C4进行输出,CB_C5使用所有16个残块输出C5的特征图。
上采样技术
我们探索了两种技术,即上采样技术。,双线性插值和反卷积,增加特征图的大小,以匹配恢复子网络输入和输出的分辨率。
表2比较了CB模块的不同结构和DSNet模型中使用的上采样技术。表2的第二列显示了应用双线性插值技术得到的结果。使用CB_C2模块获得的mAP为50.84%,分别比使用CB_C3、CB_C4和CB_C5模块获得的mAP高0.63%、1.37%和3.08%。表2的第三列显示了采用反卷积技术时的结果。使用CB_C2模块得到的地图为50.51%,比使用CB_C3、CB_C4和CB_C5模块分别高出0.74%、1.65%和3.21%。
这些结果可以解释为:当使用CB模块与更深的架构时,可以用于增强可见性的丰富空间信息的数量减少了。因此,恢复子网可能不能很好地提高雾天图像的能见度,从而导致学习目标分类和定位的CB模块生成的fC2质量较差。由于双线性插值技术和CB_C2模块的模型效果最好,因此我们选择它们来设计我们的DSNet模型。
重建模块的影响
在本节中,我们进行了消融研究,以调查恢复子网络对所提议的模型的影响。实验结果如图4所示。子网恢复被删除时,模型只包含检测子网(表示DSNet-1)中在式(5)定义的定位损失和式(3)定义的Focal Loss。(3)。在这种情况下,网络架构是相同的RetinaNet[15],并获得平均精度(mAP)汽车和人的55%和40.96%,分别。由图4可知,DSNet模型对汽车的准确率为58.01%,对人的准确率为43.67%,分别比DSNet-1模型提高3.01%和2.71%。这种不需要额外计算的性能提升的主要原因是:在训练过程中,为了让FR模块从![]() 中生成一幅干净的无模糊图像,CB模块将学习提取包含更多无模糊空间相关特征的特征,从而使恢复损失最小化。而特征
中生成一幅干净的无模糊图像,CB模块将学习提取包含更多无模糊空间相关特征的特征,从而使恢复损失最小化。而特征![]() 包含更多的无雾空间特征,检测子网能够利用这些特征对模糊图像中的目标进行准确的检测。
包含更多的无雾空间特征,检测子网能够利用这些特征对模糊图像中的目标进行准确的检测。
4.3.2、定性和定量结果
目标检测器
在本节中,我们定性和定量评估DSNet模型的性能,并比较我们的发现的基础检测器(RetinaNet[15])和当前最先进的目标探测器,即YOLO-V3 [13], SSD- 512[14],和Faster R-CNN [9] FOD数据集和有雾驾驶数据集。
在我们的实验中,所有的比较方法都采用微调方法进行训练。各比较型号的损失功能和设置(即除了Faster R-CNN,它使用ResNet-50[24]作为基础网络,而不是VGG16[26]。此外,虽然测试是在两个不同的数据集上进行的,但所有的方法都是通过仅使用FOD数据集来训练的。






在训练RetinaNet、yolo-v3和SSD512时,我们分别采用[15]、[13]和[14]中报道的传统模型,这些模型都是在COCO数据集[51]上预先训练的。然后,我们将这些模型的分类器权重从80个类下采样到2个类(person和car),并在FOD训练集上对它们进行微调。
为了训练Faster RCNN,首先在ImageNet数据集上训练ResNet-50主干。我们没有从头开始训练ResNet-50,而是利用[50]中预训练的模型,在FOD训练集上对更快的R-CNN模型进行调优。
我们的DSNet、RetinaNet、YOLOV3、SSD512和Faster R-CNN在有雾情况下检测目标的定性结果如图5所示。DSNet在对大雾中的人和车辆的精确检测方面超过了其他方法。利用mAP度量,定量地比较了提出的DSNet与上述模型的检测精度。比较方法的mAP结果如表3所示。该方法在FOD和大雾驾驶数据集上的准确率均高于其他方法。
表3的第二列是FOD测试集上的比较结果,DSNet的检测准确率分别比RetinaNet、YOLO - v3、SSD512和Faster R-CNN高出2.86%、4.08%、5.19%和9.37%。表3的第三列给出了Foggy Driving数据集的比较结果。DSNet比RetinaNet, YOLO-V3, SSD512, R-CNN快1.99%,2.04%,2.66%,17.69%。
检测去雾
为了进一步验证我们的DSNet模型,我们将去雾方法应用于有雾情况下的目标检测问题,以提高性能,并与我们提出的方法进行比较。选取AODNet[38]、DCPDN[39]、CAP[34]三种常用的去hazing方法,与基础检测网络(RetinaNet[15])相结合,形成AOD-RetinaNet、DCPDNRetinaNet、CAP-RetinaNet三种组合模型。
通过对FOD训练集进行AOD-Net、DCPDN和CAP的除雾训练,得到三种组合模型的性能。然后,在FOD测试集上使用训练好的AOD-Net、DCPDN和CAP模型生成3个无雾图像集。然后,我们对FOD数据集的ground-truth图像进行RetinaNet训练,在洁净场景下进行目标检测。最后,将训练好的RetinaNet模型应用于三个无雾图像集,得到三种连接模型的结果。
图6展示了我们的DSNet和三种组合模型在有雾情况下的目标检测的定性比较。我们可以看到,DSNet比其他模型更准确地检测感兴趣的目标(人和汽车)。
表4显示了DSNet、RetinaNet和三种连接模型在FOD和Foggy Driving数据集上的定量比较。表4的第二列列出了FOD测试集上比较方法的mAP结果,我们的DSNet比RetinaNet、AOD-RetinaNet、CAP-RetinaNet和DCPDNRetinaNet分别好6.54%、6.11%、6.24%和9.17%。表4的第三列列出了比较方法在Foggy Driving数据集上的地图结果。我们的DSNet分别超过RetinaNet、AOD-RetinaNet、CAP-RetinaNet和DCPDN-RetinaNet 4.18%、7.22%、6.20%和10.59%。
4.4、推理时间
在我们的DSNet模型中,检测子网络与恢复子网络同时学习后,负责雾天图像中目标分类和目标定位的联合推理。因此,DSNet虽然在基础网络上增加了额外的卷积层,但仍保持了较高的检测速度。比较方法的推理速度列于表4的第四列。我们的方法可以在一个GTX 1070 Ti GPU上运行每幅图像47毫秒,等于RetinaNet;它比AOD-RetinaNet、CAP-RetinaNet和DCPDN-RetinaNet分别快104、108和122 ms,且准确率最高。
5、结论
在这篇论文中,我们提出了一种新的方法来提高在恶劣天气条件下的目标检测性能。我们的DSNet模型由两个子网组成,即检测子网和恢复子网,可以进行端到端的训练,进行增强可见性、目标分类和目标定位的联合学习。利用RetinaNet介绍了检测子网,通过将FR模块附加到检测网络第三残块的最后一层特征提取层,设计了恢复子网。在合成和自然雾数据集上的实验结果表明,我们提出的方法获得了最满意的检测性能。定性和定量评估的比较方法证明,我们的DSNet是明显比其他模型更准确的同时保持高速。