STARK & STARK_LT 复现(2021)
提示:有关
VOT数据集如何下载请参考这篇文章:https://blog.csdn.net/qq_40750972/article/details/124057012?spm=1001.2014.3001.5501
一、STARK
github 主页:https://github.com/researchmm/Stark
1. 环境搭建
OS: Ubuntu18.04 LTSCUDA: 11.1TORCH: 1.8.1
创建一个新的虚拟环境:
conda create -n stark python=3.8
注意:这里首先只创建一个最基础的环境,以后差什么包,自己写在
requirements.txt文件里面,然后通过pip install -r requirements.txt安装缺少的包即可,最好不要使用官方提供的requirements.txt或者environment.yml部署工具来安装!!!因为里面包含了一些和硬件相关的信息,直接进行安装的话会出现各种错误,这也是长期以来踩坑的一个小小总结。
这里要说明一下,安装 TORCH 的时候,需要根据自己的机器来确定安装的版本,具体要和 nvcc -V 显示的 CUDA TOOLKIT 版本一致,
对应到 PyTorch 官网下载时,不要选择下载最新的 TORCH,本文选择的是 1.8.1 版本,在这个页面进行下载:https://pytorch.org/get-started/previous-versions/
注意:下载的时候如果在官方提供的下载命令中,没有找到自己对应的
CUDA版本的安装命令,可以使用后面的PIP来进行安装!
由于TORCH 1.8.1没有提供CUDA下载,如果直接使用conda install安装的话,默认安装的是CPU版本,因此后面import torch就会报错!这里选择使用PIP来进行下载。

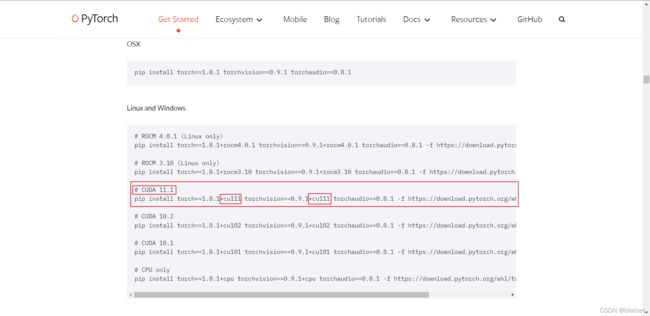
# CUDA 11.1
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 10.2
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 10.1
pip install torch==1.8.1+cu101 torchvision==0.9.1+cu101 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
这里我们选择与自己机器 CUDA 版本匹配进行下载。
再次强调下:不是nvidia-smi而是nvcc -V中的CUDA版本!!!因为后者对应着RUN TIME版本,运行的时候,实际调用的是这个!一般前者的版本一般都比后者高,后者只要不高于前者的版本即可。
这里再啰嗦一句,使用 CONDA 与 PIP 的区别:两者管理扩展包的方式不一样。
conda install默认安装包的位置在anaconda3/pkgs/里面,只要这里面有现成的扩展包,就首先引用(复制)这里的扩展包,不用重复下载。pip install默认的安装位置是anaconda3/envs/虚拟环境名字/pkgs/,它的管理范围只局限在当前的虚拟环境,不能跨越不同的环境,所以就算其他虚拟环境中有已经安装好的扩展包,每次安装的的时候,都会重新下载。管理的范围更小,更加独立。
以上是查阅资料后的个人理解,如果有不当的地方,望指正,谢谢!
安装好 PyTorch 之后,接下来有两种方法安装相应的扩展包,作者一般都会提供,一般有三种方法。
1.1 使用 shell 命令直接进行安装
由于 STARK 的作者提供的是 shell 脚本来进行安装扩展包的,因此相对来说还是比较方便。但还是需要查看里面的安装命令,看里面的某些命令是否和硬件环境相关,如果有,更改为和自己硬件匹配的安装命令(主要是版本的修改,比如说 PyTorch 的 CUDA 版本)。
echo "****************** Installing pytorch ******************"
conda install -y pytorch==1.7.0 torchvision==0.8.1 cudatoolkit=10.2 -c pytorch
echo "****************** Installing thop tool for FLOPs and Params computing ******************"
pip install --upgrade git+https://github.com/Lyken17/pytorch-OpCounter.git
pip install onnx onnxruntime-gpu==1.6.0
以上就是从作者提供的脚本中发现的存在 BUG 隐患的地方,就拿第一条来说,这里就是一个大坑,第二条也是,把安装的 torch 更新到了最新版本,好气!最后一条还好,不需要修改,将以上中的前两条删除,然后运行这个安装脚本就可以(可以使用 source 或者 bash,这里不再解释这两个命令的区别,感兴趣的自行 GOOGLE)。
source install_pytorch17.sh
# or
bash install_pytorch17.sh
1.2 使用 requirements.txt 安装(推荐)
思路:把作者提供的各种下载包复制到 requirements.txt 文件里面。
requirements.txt官方文档:https://pip.pypa.io/en/stable/reference/requirements-file-format/
Step1. 找到需要 pip install 的包
(stark) xxx@xxx:~/username/proj/stark$ grep "install*" install_pytorch17.sh
conda install -y pytorch==1.7.0 torchvision==0.8.1 cudatoolkit=10.2 -c pytorch
pip install PyYAML
pip install easydict
pip install cython
pip install opencv-python
pip install pandas
conda install -y tqdm
pip install pycocotools
apt-get install libturbojpeg
pip install jpeg4py
pip install tb-nightly
pip install tikzplotlib
pip install --upgrade git+https://github.com/Lyken17/pytorch-OpCounter.git
pip install colorama
pip install lmdb
pip install scipy
pip install visdom
pip install git+https://github.com/votchallenge/vot-toolkit-python
pip install onnx onnxruntime-gpu==1.6.0
pip install timm==0.3.2
(stark) xxx@xxx:~/username/proj/stark$
这里作者使用的是 shell 脚本批量安装的命令,因此没有绑定一大堆的版本信息,这里还是比较方便的,把这里得到的所有安装包信息复制到 VSCode 里面,然后使用 VSCode 的查找替换功能删除指定的版本信息。
注意:由于这里演示的是使用
requirements.txt部署安装(PIP对应的部署管理工具,我之前写过一篇相关的博客,感兴趣的可以去看:使用配置文件创建conda环境),因此需要将里面和pip install安装无关的都删除,虽然比较麻烦,但是安装管理是分开的,不会很混乱,不容易出错!
由于 shell 脚本中还有使用 apt 安装到系统中的扩展包,只需要找到,然后单独执行即可。
sudo apt-get install libturbojpeg
Step2. 使用 requirements.txt 安装部署
修改后的 requirements.txt 内容为:
torch==1.8.1+cu111 ## 注意这里修改为自己机器适应的 CUDA 版本!!!
torchvision==0.9.1+cu111 ## 注意这里修改为自己机器适应的 CUDA 版本!!!
torchaudio==0.8.1
-f https://download.pytorch.org/whl/torch_stable.html
PyYAML
easydict
cython
opencv-python
pandas
tqdm
pycocotools
jpeg4py
tb-nightly
tikzplotlib
colorama
lmdb
scipy
visdom
git+https://github.com/votchallenge/vot-toolkit-python
onnx
onnxruntime-gpu==1.6.0
timm==0.3.2
black
yacs
ipython
然后执行(当然是在激活的 stark 虚拟环境里面):
pip install -r requirements.txt
完成安装。这里有一个小技巧,如果你已经有了 requirements.txt 文件,那么可以直接使用下面的命令创建新的环境:
conda create -n env_name --file requirements.txt
1.3 使用 environment.yml 安装(不推荐,因为只要某一个包没下载成功,后面所有的都不会下载,而该环境已经创建)
environment.yml官方说明文档:https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html?highlight=environment.yml
直接看官方文档就可以了,个人基本没有用到该工具。简单地给个官方的示例:
name: stats2
channels:
- javascript
- nodefaults # 禁用默认的下载源,使得这里配置的下载源生效,自己看情况使用
dependencies:
- python=3.6 # or 2.7
- bokeh=0.9.2
- numpy=1.9.*
- nodejs=0.10.*
- flask
- pip # 安装 pip,不然后面无法执行 pip 命令,不然你都没安装怎么执行后面的操作
- pip:
- Flask-Testing
这里说下和 requirements.txt 的区别,前者使用 == 指定版本号,而后者的 dependencies (注意为什么要强调下这个,因为 pip 中也要使用 == 指定版本)使用 = 指定。
2. 修改创建数据集等文件路径的 Python 文件
方法1
按照官方给的说明文档(README.md)操作之前,需要更改下文件,更改之后就不用再手动修改创建的 local.py 文件了,方便很多。首先看看作者的说明:


create_default_local_file_ITP_train 函数中修改训练集相关路径:
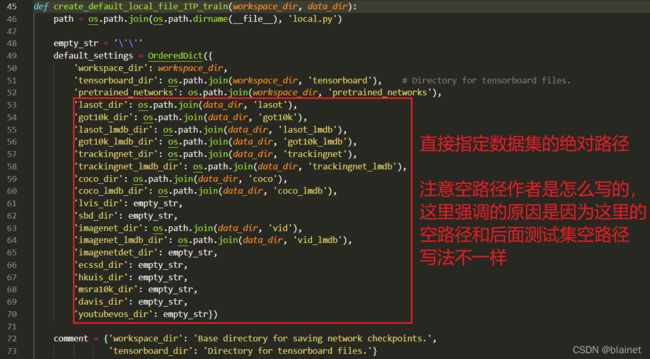
EnvSettings_ITP 类初始化函数 __init__ 中修改路径(注意和 trainning 设置不一样!!!主要是调用方法不一样):

方法2
根据官方提供的数据集目录树,通过创建软链接的方法,将其联系起来,到之后直接就可以访问到相应的数据,如果某些存放结果的目录需要修改,还是要按照 方法1 来操作。
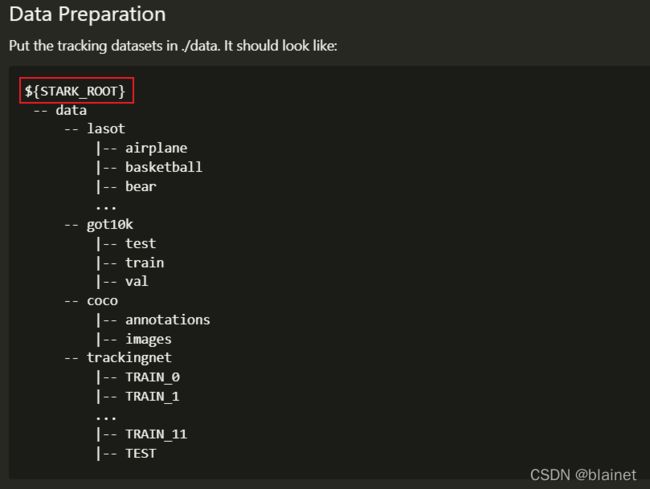
创建软链接的方法示例。
ln -s /data/GOT-10k ${STARK_ROOT}/data/got10k # 注意这里最后不要和注释里面的一样加一个/
# ln -s /data/GOT-10k/ ${STARK_ROOT}/data/got10k # 这样会在原来的文件夹中创建一个新的文件 GOT-10k
## 如果创建错误,或者不需要了,直接使用下面的方法删除软链接就是
rm got10k
3. 下载预训练模型
用于测试的预训练模型,老规矩,根据官方提供的目录树创建好相应的目录。
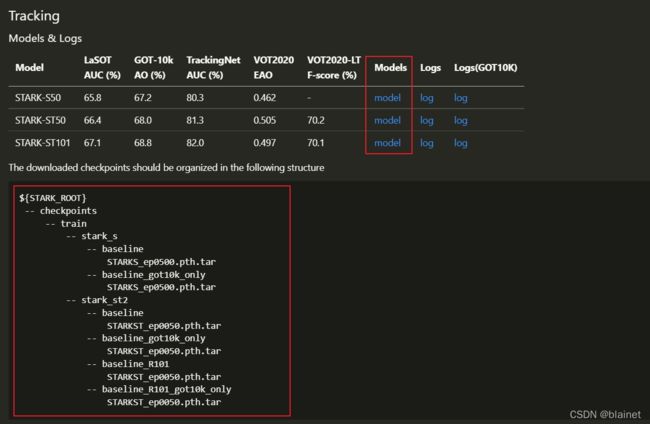
然后把这些下载好的预训练模型放入到对应的文件夹中就可以了,这里提供下载好的预训练模型(阿里云盘) ,解压后直接放入到 STARK_ROOT 目录中就可以。
scp -r xxx@xxx:/home/xxx/checkpoints/stark/* .\Desktop\
这里只是个人记录下
scp怎么从远程拷贝文件!!!
4. 运行和测试
首先运行:
python tracking/create_default_local_file.py --workspace_dir . --data_dir ./data --save_dir .
生成 local.py 文件(train & test 文件夹下分别生成)。
4.1 train
这里直接引用作者原句:
Training with multiple GPUs using DDP(多 GPU 训练).
# STARK-S50
python tracking/train.py --script stark_s --config baseline --save_dir . --mode multiple --nproc_per_node 8 # STARK-S50
# STARK-ST50
python tracking/train.py --script stark_st1 --config baseline --save_dir . --mode multiple --nproc_per_node 8 # STARK-ST50 Stage1
python tracking/train.py --script stark_st2 --config baseline --save_dir . --mode multiple --nproc_per_node 8 --script_prv stark_st1 --config_prv baseline # STARK-ST50 Stage2
# STARK-ST101
python tracking/train.py --script stark_st1 --config baseline_R101 --save_dir . --mode multiple --nproc_per_node 8 # STARK-ST101 Stage1
python tracking/train.py --script stark_st2 --config baseline_R101 --save_dir . --mode multiple --nproc_per_node 8 --script_prv stark_st1 --config_prv baseline_R101 # STARK-ST101 Stage2
(Optionally) Debugging training with a single GPU
python tracking/train.py --script stark_s --config baseline --save_dir . --mode single
4.2 test
这部分暂时只测试了 GOT-10k,VOT 部分遇到了很多困难,后续更新…
Test and evaluate STARK on benchmarks.
- LaSOT
python tracking/test.py stark_st baseline --dataset lasot --threads 32
python tracking/analysis_results.py # need to modify tracker configs and names
- GOT10K-test
python tracking/test.py stark_st baseline_got10k_only --dataset got10k_test --threads 32
python lib/test/utils/transform_got10k.py --tracker_name stark_st --cfg_name baseline_got10k_only
运行效果:
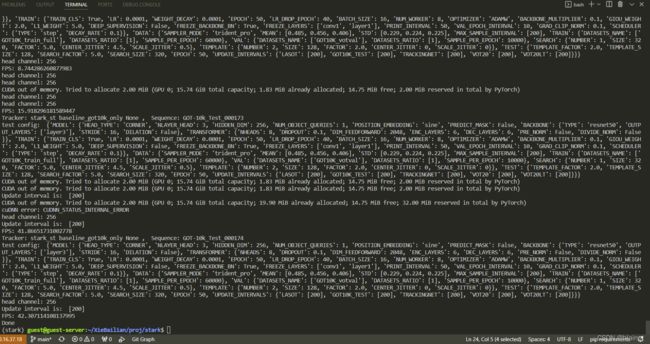
- TrackingNet
python tracking/test.py stark_st baseline --dataset trackingnet --threads 32
python lib/test/utils/transform_trackingnet.py --tracker_name stark_st --cfg_name baseline
- VOT2020
Before evaluating “STARK+AR” on VOT2020, please install some extra packages following external/AR/README.md
cd external/vot20/<workspace_dir>
export PYTHONPATH=<path to the stark project>:$PYTHONPATH
bash exp.sh
- VOT2020-LT
cd external/vot20_lt/<workspace_dir>
export PYTHONPATH=<path to the stark project>:$PYTHONPATH
bash exp.sh
二、问题记录
2.1 关于 VOT 测试运行记录
由于只能使用官方提供的工具包进行测试,整个过程遇到很多错误,这里特地记录下来。
首先是 trackers.ini 文件的修改:
[stark_st101] ## tracker 的名称,后面执行命令时需要使用到
label = stark_st101 ## 这个目前不知道是什么意思
protocol = traxpython ## 指定通信协议
command = stark_st101 ## paths 路径下必须有该模块文件,作为启动
paths = >/lib/test/vot20 ## 指定与 trax 通信的模块路径
修改 config.yaml 配置文件:
registry:
- ./trackers.ini
stack: vot2021
主要是修改 stack,对应哪个年份哪种数据集,名称可以在 vot-toolkit GitHub 仓库中的 vot/stack 中找到。
1. 有关 evaluate 时总是自动下载数据集的问题
推荐
VOT数据集下载toolkit工具(虽然是个人写的,有点厚脸皮啦 hhh,主要是今天看后面推荐的那位大佬闭源了,需要VIP才能查看),其实也很简单,如果会爬虫的话:https://blog.csdn.net/qq_40750972/article/details/124057012?spm=1001.2014.3001.5501
Solution #1 (推荐使用)
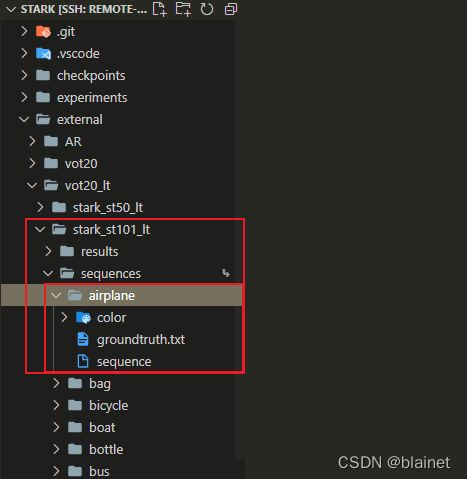
在当前 workspace(即包含 config.yaml trackers.ini 的文件夹) 下创建一个软链接 sequences 指向对应的数据集即可。比如说:
ln -s /data/VOT2021 sequences
创建完之后大概是这样的:

Solution #2(不推荐使用,虽然有效,但是很麻烦)
修改 vot-toolkit 的源码。
find ~/anaconda3/envs/stark/ -name "vot" ## 找到 vot 的安装目录

修改以下文件:
vim /home/guest/anaconda3/envs/stark/lib/python3.8/site-packages/vot/workspace/__init__.py +155
## 打开后,修改成如下,然后保存即可
155 #if not self.stack.dataset is None:
156 #Workspace.download_dataset(self.stack.dataset, dataset_directory)
157
158 # self._dataset = load_dataset(dataset_directory)
159 self._dataset = load_dataset("/data/VOT2021") ## 这里是 VOT 数据集的路径
这是一种比较笨的方法,应该是可以通过其他方法解决的,不过目前这是最有效的方法,阅读源码有点费时间,看作者的注释可以猜到和 Workspace.load() 这个 staticmethod 有关。
这里附上一个大神写的手动下载
VOT数据集的方法:https://blog.csdn.net/laizi_laizi/article/details/122492396最好不要使用这个官方的工具集来下载,会出现各种问题,什么不能解压
.rar文件错误(这里修改官方源码后,还是会报错),网络错误等等。
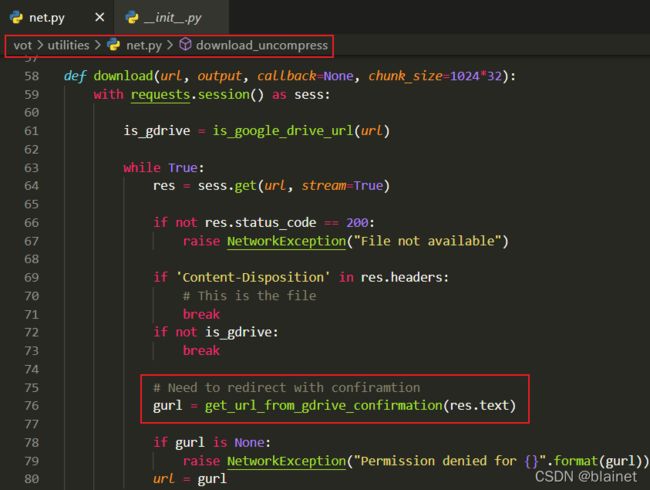
这里作者只提供了zip解压缩的方法,没有写rar文件(对应annotation.rar)解压缩,因此文件格式不匹配发生异常,程序中断。至于为什么作者得到的文件是rar格式,这个不是很清楚。个人猜测和转换下载链接那里有关,将原始的下载链接转换为了从GOOGLE DRIVE链接。

2. evaluate 失败,提示找不到 lib 模块
数据集加载成功之后,在评估的时候出了问题,具体调用情况如下,如果没有看 vot-toolkit-python 源码,看不懂正常,这里只个人纪录下。
vot --- (vot-toolkit)__main__.py(main) --- cli.py(do_evaluate) --- do_evaluate(run_experient 到这里就出错了)
提示的错误是 TraxException,通过日志文件 log 的内容查看,提示是模块没有导入成功,控制台输出的错误提示如下。
vot.tracker.TrackerException: Unable to connect to tracker
Tracker output written to file: /home/xxx/xxx/proj/stark/external/vot20/stark_st101/logs/stark_st101_2022-04-14T10-42-04.069526.log
Evaluation interrupted by tracker error: ('Experiment interrupted', TrackerException(TraxException('Unable to connect to tracker')))
log 文件中的日志信息如下。
Traceback (most recent call last):
File "/home/xxx/anaconda3/envs/stark/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/xxx/anaconda3/envs/stark/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/xxx/xxx/proj/stark/lib/test/vot20/stark_st101.py", line 1, in <module>
from lib.test.vot20.stark_vot20 import run_vot_exp
ModuleNotFoundError: No module named 'lib'
Process not alive anymore, unable to retrieve return code
Solution #1
按照提示来操作,在提示出错的文件前加入:
import sys
sys.path.append("${STARK_ROOT}")
不过这种方法比较耗时耗力,会修改很多文件,不推荐。
Solution #2
修改 trackers.ini 配置文件。
[stark_st101] ## tracker name
label = stark_st101
protocol = traxpython
## ini 文件中,";" 以及 "#" 都表示注释
; command = import pytracking.run_vot as run_vot; run_vot.run_vot('dimp', 'dimp50_vot18') # 这只是一个示例,作为参考记录
; command = stark_st101 # 作者提供的原始命令,要修改成以下的命令
command = import lib.test.vot20.stark_st101 as stark_st101
## Specify a path to trax python wrapper if it is not visible (separate by ; if using multiple paths)
## 修改 paths,和 command 对应,使得 paths 匹配 command 中的路径
; paths = /home/guest/XieBailian/proj/stark/lib/test/vot20
paths = /home/guest/XieBailian/proj/stark
## Additional environment paths: 尝试解决的过程,这种方式不起作用
; env_PATH = /home/guest/anaconda3/envs/stark/bin/python;${PATH}
; export PYTHONPATH=/home/guest/anaconda3/envs/stark/:$PYTHONPATH
参考链接:https://github.com/votchallenge/toolkit/issues/26
3. 以上第二步解决了 lib 模块等路径的问题后,再次运行,又出现了以下错误
vot.tracker.TrackerException: Unable to connect to tracker
Tracker output written to file: /home/xxx/xxx/proj/stark/external/vot20/stark_st101/logs/stark_st101_2022-04-14T09-59-45.809897.log
Evaluation interrupted by tracker error: ('Experiment interrupted', TrackerException(TraxException('Unable to connect to tracker')))
其实这个错误类型和第二步中的一样,但是 log 中的信息不一样了。
test config: {'MODEL': {'HEAD_TYPE': 'CORNER', 'NLAYER_HEAD': 3, 'HIDDEN_DIM': 256, 'NUM_OBJECT_QUERIES': 1, 'POSITION_EMBEDDING': 'sine', 'PREDICT_MASK': False, 'BACKBONE': {'TYPE': 'resnet101', 'OUTPUT_LAYERS': ['layer3'], 'STRIDE': 16, 'DILATION': False}, 'TRANSFORMER': {'NHEADS': 8, 'DROPOUT': 0.1, 'DIM_FEEDFORWARD': 2048, 'ENC_LAYERS': 6, 'DEC_LAYERS': 6, 'PRE_NORM': False, 'DIVIDE_NORM': False}}, 'TRAIN': {'TRAIN_CLS': True, 'LR': 0.0001, 'WEIGHT_DECAY': 0.0001, 'EPOCH': 50, 'LR_DROP_EPOCH': 40, 'BATCH_SIZE': 16, 'NUM_WORKER': 8, 'OPTIMIZER': 'ADAMW', 'BACKBONE_MULTIPLIER': 0.1, 'GIOU_WEIGHT': 2.0, 'L1_WEIGHT': 5.0, 'DEEP_SUPERVISION': False, 'FREEZE_BACKBONE_BN': True, 'FREEZE_LAYERS': ['conv1', 'layer1'], 'PRINT_INTERVAL': 50, 'VAL_EPOCH_INTERVAL': 10, 'GRAD_CLIP_NORM': 0.1, 'SCHEDULER': {'TYPE': 'step', 'DECAY_RATE': 0.1}}, 'DATA': {'SAMPLER_MODE': 'trident_pro', 'MEAN': [0.485, 0.456, 0.406], 'STD': [0.229, 0.224, 0.225], 'MAX_SAMPLE_INTERVAL': [200], 'TRAIN': {'DATASETS_NAME': ['LASOT', 'GOT10K_vottrain', 'COCO17', 'TRACKINGNET'], 'DATASETS_RATIO': [1, 1, 1, 1], 'SAMPLE_PER_EPOCH': 60000}, 'VAL': {'DATASETS_NAME': ['GOT10K_votval'], 'DATASETS_RATIO': [1], 'SAMPLE_PER_EPOCH': 10000}, 'SEARCH': {'NUMBER': 1, 'SIZE': 320, 'FACTOR': 5.0, 'CENTER_JITTER': 4.5, 'SCALE_JITTER': 0.5}, 'TEMPLATE': {'NUMBER': 2, 'SIZE': 128, 'FACTOR': 2.0, 'CENTER_JITTER': 0, 'SCALE_JITTER': 0}}, 'TEST': {'TEMPLATE_FACTOR': 2.0, 'TEMPLATE_SIZE': 128, 'SEARCH_FACTOR': 5.0, 'SEARCH_SIZE': 320, 'EPOCH': 50, 'UPDATE_INTERVALS': {'LASOT': [200], 'GOT10K_TEST': [200], 'TRACKINGNET': [25], 'VOT20': [10], 'VOT20LT': [100]}}}
Downloading: "https://download.pytorch.org/models/resnet101-5d3b4d8f.pth" to /home/xxx/.cache/torch/hub/checkpoints/resnet101-5d3b4d8f.pth
0%| | 0.00/170M [00:00<?, ?B/s]
0%| | 40.0k/170M [00:00<18:14, 163kB/s]
0%| | 88.0k/170M [00:00<11:29, 259kB/s]
0%| | 120k/170M [00:00<11:34, 257kB/s]
0%| | 184k/170M [00:00<08:36, 346kB/s]
0%| | 264k/170M [00:00<06:17, 473kB/s]
0%| | 360k/170M [00:00<04:49, 617kB/s]
0%| | 488k/170M [00:00<03:38, 816kB/s]
0%| | 696k/170M [00:01<02:31, 1.18MB/s]
1%| | 952k/170M [00:01<01:51, 1.59MB/s]
1%| | 1.27M/170M [00:01<01:21, 2.18MB/s]
1%| | 1.76M/170M [00:01<00:58, 3.03MB/s]
1%|Process not alive anymore, unable to retrieve return code
原因,下载 resnet101 预训练模型失败,解决方法,直接手动下载放到提示的文件夹中(根据以上日志文件中的 Downloading 得出的判断):
wget https://download.pytorch.org/models/resnet101-5d3b4d8f.pth -P /home/xxx/.cache/torch/hub/checkpoints/
4. 关于 CUDA 的配置错误
以上修改之后,直接运行还是会报错。
test config: {'MODEL': {'HEAD_TYPE': 'CORNER', 'NLAYER_HEAD': 3, 'HIDDEN_DIM': 256, 'NUM_OBJECT_QUERIES': 1, 'POSITION_EMBEDDING': 'sine', 'PREDICT_MASK': False, 'BACKBONE': {'TYPE': 'resnet101', 'OUTPUT_LAYERS': ['layer3'], 'STRIDE': 16, 'DILATION': False}, 'TRANSFORMER': {'NHEADS': 8, 'DROPOUT': 0.1, 'DIM_FEEDFORWARD': 2048, 'ENC_LAYERS': 6, 'DEC_LAYERS': 6, 'PRE_NORM': False, 'DIVIDE_NORM': False}}, 'TRAIN': {'TRAIN_CLS': True, 'LR': 0.0001, 'WEIGHT_DECAY': 0.0001, 'EPOCH': 50, 'LR_DROP_EPOCH': 40, 'BATCH_SIZE': 16, 'NUM_WORKER': 8, 'OPTIMIZER': 'ADAMW', 'BACKBONE_MULTIPLIER': 0.1, 'GIOU_WEIGHT': 2.0, 'L1_WEIGHT': 5.0, 'DEEP_SUPERVISION': False, 'FREEZE_BACKBONE_BN': True, 'FREEZE_LAYERS': ['conv1', 'layer1'], 'PRINT_INTERVAL': 50, 'VAL_EPOCH_INTERVAL': 10, 'GRAD_CLIP_NORM': 0.1, 'SCHEDULER': {'TYPE': 'step', 'DECAY_RATE': 0.1}}, 'DATA': {'SAMPLER_MODE': 'trident_pro', 'MEAN': [0.485, 0.456, 0.406], 'STD': [0.229, 0.224, 0.225], 'MAX_SAMPLE_INTERVAL': [200], 'TRAIN': {'DATASETS_NAME': ['LASOT', 'GOT10K_vottrain', 'COCO17', 'TRACKINGNET'], 'DATASETS_RATIO': [1, 1, 1, 1], 'SAMPLE_PER_EPOCH': 60000}, 'VAL': {'DATASETS_NAME': ['GOT10K_votval'], 'DATASETS_RATIO': [1], 'SAMPLE_PER_EPOCH': 10000}, 'SEARCH': {'NUMBER': 1, 'SIZE': 320, 'FACTOR': 5.0, 'CENTER_JITTER': 4.5, 'SCALE_JITTER': 0.5}, 'TEMPLATE': {'NUMBER': 2, 'SIZE': 128, 'FACTOR': 2.0, 'CENTER_JITTER': 0, 'SCALE_JITTER': 0}}, 'TEST': {'TEMPLATE_FACTOR': 2.0, 'TEMPLATE_SIZE': 128, 'SEARCH_FACTOR': 5.0, 'SEARCH_SIZE': 320, 'EPOCH': 50, 'UPDATE_INTERVALS': {'LASOT': [200], 'GOT10K_TEST': [200], 'TRACKINGNET': [25], 'VOT20': [10], 'VOT20LT': [100]}}}
head channel: 256
########################
torch.cuda.is_available: False
torch.cuda.device_count: 0
########################
Traceback (most recent call last):
File "" , line 1, in <module>
File "/home/guest/XieBailian/proj/stark/lib/test/vot20/stark_st101.py", line 5, in <module>
run_vot_exp("stark_st", "baseline_R101", vis=True)
File "/home/guest/XieBailian/proj/stark/lib/test/vot20/stark_vot20.py", line 67, in run_vot_exp
tracker = stark_vot20(tracker_name=tracker_name, para_name=para_name)
File "/home/guest/XieBailian/proj/stark/lib/test/vot20/stark_vot20.py", line 32, in __init__
self.tracker = tracker_info.create_tracker(params)
File "/home/guest/XieBailian/proj/stark/lib/test/evaluation/tracker.py", line 101, in create_tracker
tracker = self.tracker_class(params, self.dataset_name)
File "/home/guest/XieBailian/proj/stark/lib/test/tracker/stark_st.py", line 19, in __init__
network = build_starkst(params.cfg)
File "/home/guest/XieBailian/proj/stark/lib/models/stark/stark_st.py", line 65, in build_starkst
box_head = build_box_head(cfg)
File "/home/guest/XieBailian/proj/stark/lib/models/stark/head.py", line 441, in build_box_head
corner_head = Corner_Predictor(
File "/home/guest/XieBailian/proj/stark/lib/models/stark/head.py", line 83, in __init__
self.indice.repeat((self.feat_sz, 1))
File "/home/guest/anaconda3/envs/stark/lib/python3.8/site-packages/torch/cuda/__init__.py", line 170, in _lazy_init
torch._C._cuda_init()
RuntimeError: No CUDA GPUs are available
Process not alive anymore, unable to retrieve return code
最前面输出的是配置文件 experiments/stark_st2/baseline_R101.yaml 里面的信息,关于 cuda 的打印输出为自己添加的调试输出,从最后的报错可以看到,没有检测到可用的 GPU,但是通过在终端中进行测试,完全没有问题。问题主要出现在这个文件里,入口处 lib/test/vot20/stark_st101.py。

这里修改为自己机器对应的数量,注意不是机器 (更正: 理解错误,应该是 GPU 的数量,比如说我用的服务器为一台,带有 3 张 GPU,那么这里就只能填写 0,而不是显卡的数量!!!对应的是机器的数量。个人猜测作者使用的是分布式训练,有 8 台机器,然后同时使用。GPU 对应的索引,从 0 开始,指定在哪一张 GPU 上进行测试!如果有多张,只需指定要使用的 GPU 的索引,比如这里我用第一张和第三张来跑,那么就可以这样改)
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 2"
修改之后的效果如下:
test config: 这里就不复制,太长了
head channel: 256
########################
torch.cuda.is_available: True
torch.cuda.device_count: 1
########################
Update interval is: [10]
Traceback (most recent call last):
File "" , line 1, in <module>
File "/home/guest/XieBailian/proj/stark/lib/test/vot20/stark_st101.py", line 5, in <module>
run_vot_exp("stark_st", "baseline_R101", vis=True)
File "/home/guest/XieBailian/proj/stark/lib/test/vot20/stark_vot20.py", line 68, in run_vot_exp
handle = vot.VOT("mask")
AttributeError: module 'vot' has no attribute 'VOT'
Process not alive anymore, unable to retrieve return code
可以看到,成功检测到了 GPU,但是只检测到了一张,这里不是很清楚……
参考链接1:https://blog.csdn.net/qq_42815385/article/details/88582035
参考链接2:https://www.cnblogs.com/ccorz/p/osenviron-xiang-jie.html
好了,又产生了新的 BUG,又是开心改 BUG 的一天。
5. 提示找不到 VOT
这个比较简单,作者写了一个 vot.py 模块,里面就有 VOT 这个类,但是由于已经安装了 ,这里截图验证下。(更正:不是这个原因,是由于没有将该模块所在的目录添加到 vot-toolkit,应该是相冲突,优先调用的是后者里面的 vot.py 模块sys.path 中,而 Python 解释器就是从 sys.path 按照列表的顺序引入对应的包和模块,这里只是恰好 vot-toolkit 中有 vot.py 这个模块而已,如果没有,肯定会报错。如果按照之前的理解,是由于重名引起的,那么没有 vot-toolkit/vot.py 就不会报错,而事实上并不是这样)
按照更改里面的理解,可以有三种修改的方法。
Solution #1. 最开始的做法(有效)
首先,来到 lib/test/vot20/stark_vot20.py 目录下,找到 vot.VOT,然后查看 vot 定义:
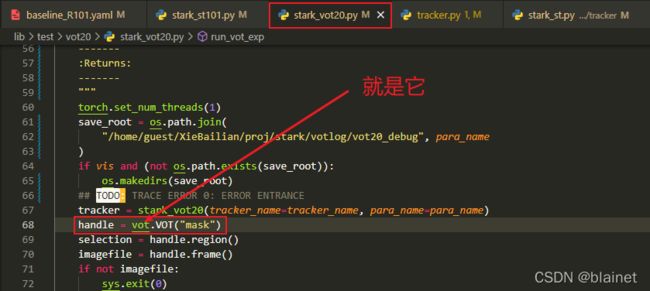
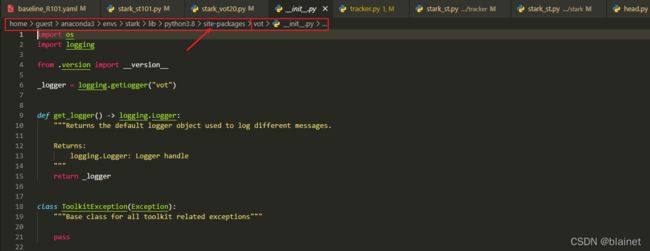
而这里本来要实现的是,调用作者自己写的 lib/test/vot20/vot.py 里面的 VOT,以实现对应的功能。

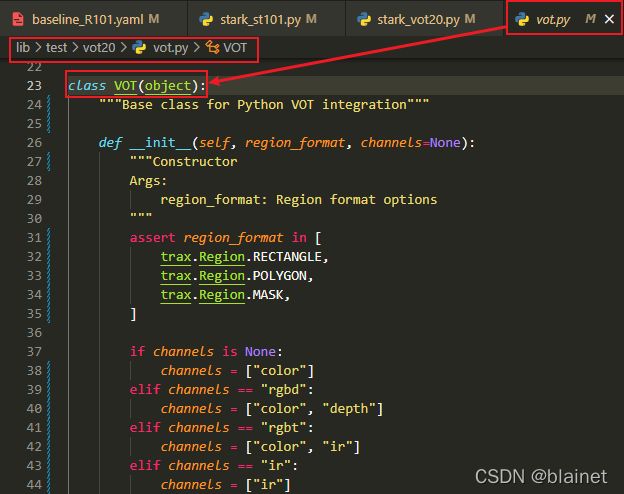
解决方法很简单,只需要正确地引入 lib/test/vot20/vot.py 模块:修改 lib/test/vot20/stark_vot20.py


Solution #2. 将 vot.py 所在的目录添加进入 PYTHONPATH(经检验,无效)
Python 中模块的调用顺序:当前执行文件的工程目录–> Python 内置模块(已安装)–>第三方模块(anaconda3/envs/env_name/sites-packages 里面),官方说明:

参考链接1:Python模块调用顺序
参考链接2:https://docs.python.org/zh-cn/3/tutorial/modules.html#the-module-search-path
参考链接3:https://www.jianshu.com/p/04701cb81e38
参考链接4:Python module & package
按照以上教程,可以输出 sys.path 进行验证,因此,也可以不用修改上述源码,通过将模块路径添加进 PYTHONPATH。
export PYTHONPATH=${STARK_ROOT}/lib/test/vot20
Solution #3. 将 vot.py 所在目录添加到 trackers.ini 文件的 paths 中(经检验,无效)
[stark_st101] # 按照生成的注释说明 Specify a path to trax python wrapper if it is not visible (separate by ; if using multiple paths,也可以验证这种做法也是有效的。
这里做个小小的总结:最开始的时候理解不到位,误打误撞就解决了,在 #1 中,我们修改的是 from lib.test.vot import VOT,这里使用了绝对路径,由于已经在 trackers.ini 中配置了 paths=/home/guest/XieBailian/proj/stark/,因此可以找到,所以这里的等效写法是:import lib.test.vot。
END
到此,基本上就结束了,成功运行的效果图如下。

终端查看显存实时占用情况:
watch -n 0.5 -t nvidia-smi
- 参考链接1:vot-toolkit-python 工具使用说明
- 参考链接2:官方提供的一个跟踪器 NCCPython,主要用于测试环境是否有问题。如果这个能够运行成功,而自己写的追踪器跑不起来,说明是内部代码的问题,逐步调试就可以
- 参考链接3:https://www.votchallenge.net/howto/tutorial_python.html VOT Challenge 官方说明文档
- 参考链接4:https://blog.csdn.net/weixin_40367515/article/details/123818030
三、STARK_LT
这个 github 暂时没有提供,只能通过 VOT Challenge 官网进行获取。
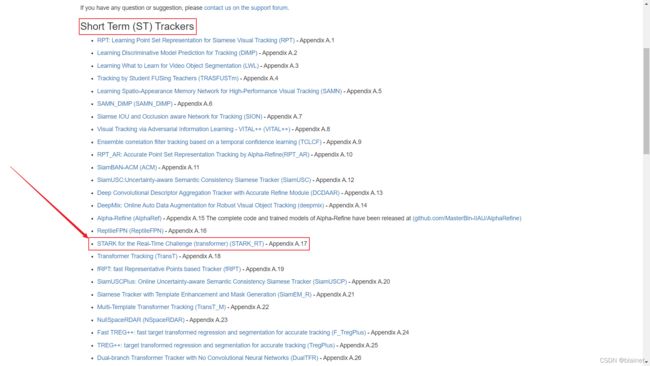
ST Trackers 获取链接:https://www.votchallenge.net/vot2021/trackers.html
STARK_LT 下载链接:http://data.votchallenge.net/vot2021/trackers/STARK_RT-code-2021-05-30T13_54_26.067770.zip
下载与训练模型:
- Download STARKST_ep0050.pth.tar and put it under checkpoints/train/stark_st2/baseline
- Download STARKST_ep0500.pth.tar and put it under checkpoints/train/stark_ref/baseline
注意:这里第二个
ep0500链接失效,无法下载,而测试的时候默认使用的是这个预训练模型,因此需要将第一个改下名字,改成ep0500后,才可以进行测试。
由于是在 STARK 的基础上修改的,因此配置运行基本差不多,直接参考 STARK 的即可,只是需要注意的是。
Step #1. 修改数据集路径
1. 基本数据集路径修改
和 STARK 一样,这里不再赘述。直接看1.2修改创建数据集等文件路径的 Python 文件。
2. VOT 测试数据集路径修改
这部分也是一样的,只是修改下数据集的名字即可。对应到: (更正:以下不推荐使用了,和 STARK 操作相同,只需要在当前 workspace 创建一个软链接 sequences 指向我们的数据集的真实路径即可)
cd ${YOUR_WORKSPACE}
ln -s /data/VOT2021_LT sequences
config.yaml中的stack~/anaconda3/envs/stark/lib/python3.8/site-packages/vot/workspace/__init__.py文件中数据集的修改,具体怎么修改,参考下面第三部分的操作。修改以下文件:
vim /home/guest/anaconda3/envs/stark/lib/python3.8/site-packages/vot/workspace/__init__.py +155
## 打开后,修改成如下,然后保存即可
155 #if not self.stack.dataset is None:
156 #Workspace.download_dataset(self.stack.dataset, dataset_directory)
157
158 # self._dataset = load_dataset(dataset_directory)
159 self._dataset = load_dataset("/data/VOT2020_LT") ## 这里是 VOT 数据集的路径
这里的
VOT2020_LT实际上是今年最新的longterm tracking datasets,使用官方提供的toolkits下载时也是这个名字。
Step #2. 修改配置文件
1. config.yaml
同样,这里只需要修改下数据集的路径即可。
registry:
- ./trackers.ini
# stack: votlt2021
stack: vot2022/lt
注意:
2022年最新的格式不一样,配置文件单独写在了一个新的文件夹vot2022里面,否者会提示无法在stack中找到该配置文件,也就无法正确加载数据集!
2. trackers.ini
这里主要修改的就是一些路径信息。
[STARK_LT] # 注意:
command表示要执行的Python脚本文件的名称(后面运行起来我们可以看到执行的命令,以及调用的一个过程,-c参数表示按脚本的方式在命令行中执行,如果某些要运行的模块没有被正确加载到sys.path中,那么就会出错,提示以下的错误!)
/home/guest/anaconda3/envs/stark/bin/python: No module named lt_stark_st50_ref_baseline_R0
Process not alive anymore, unable to retrieve return code
Setp #3. 调试运行
修改以上配置文件之后,运行测试:
cd stark_st50_ref_baseline_R0
vot evaluate --workspace . STARK_LT
ERROR 运行错误,终端控制台输出的错误日志信息:
vot.tracker.TrackerException: Unable to connect to tracker
Tracker output written to file: /home/xxx/xxx/proj/stark_lt/stark_st50_ref_baseline_R0/logs/STARK_LT_2022-04-15T10-34-47.582308.log
Evaluation interrupted by tracker error: ('Experiment interrupted', TrackerException(TraxException('Unable to connect to tracker')))
注意:实际上所有的控制台错误日志基本上都是
TrackerException(TraxException('Unable to connect to tracker'))),所以调试的时候不必理会这个,只需要查看.log日志文件中的内容即可。
比如说,这次运行失败的日志文件内容为:
# 前面这些没什么用,太多了,直接截取后面核心部分
from lib.utils.multitracker import AsscoiateTracker
File "/home/xxx/xxx/proj/stark_lt/lib/test/vot21/../../../lib/utils/multitracker.py", line 7, in <module>
from .matching import *
File "/home/xxx/xxx/proj/stark_lt/lib/test/vot21/../../../lib/utils/matching.py", line 1, in <module>
import lap
ModuleNotFoundError: No module named 'lap'
Process not alive anymore, unable to retrieve return code
到随后出错的文件 matching.py 里面查看,这里提示缺少 lap 和 cython_bbox 模块,直接 pip install lap cython_bbox 安装即可,然后再次运行,进行下一步调试。
提示:这里有一个小技巧,在
VSCode中,如果环境变量等信息已经更改,VSCode一般需要重新启动才能重新导入,但是还可以通过切换Python虚拟环境来使得环境生效,而不必重启!
再次调试,提示缺少 mmcv terminaltables,这里先替你们踩下坑,直接使用下面的命令将所有缺少的包一次安装完毕:
pip install lap cython_bbox mmcv terminaltables
安装完毕之后,再次调试运行,报以下错误:
# 内容太多,这里只粘贴部分,可以看到,是和 `GlobalTrack` 相关的
# 由于作者使用了 GlobalTrack,因此需要配置 GlobalTrack 环境
# 即 重新编译 mmdetection!!!
"/home/guest/XieBailian/proj/stark_lt/Global_Track/_submodules/mmdetection/mmdet/ops/dcn/__init__.py", line 1, in <module>
from .deform_conv import (DeformConv, DeformConvPack, ModulatedDeformConv,
File "/home/guest/XieBailian/proj/stark_lt/Global_Track/_submodules/mmdetection/mmdet/ops/dcn/deform_conv.py", line 10, in <module>
from . import deform_conv_cuda
ImportError: libcudart.so.10.0: cannot open shared object file: No such file or directory
Process not alive anymore, unable to retrieve return code
这里再次强调下,由于作者使用了 GlobalTrack,因此需要配置 GlobalTrack 环境,即重新编译 mmdetection!!!
Setp #4. 编译 mmdetection(GlobalTrack 运行环境)
GlobalTrack官方:https://github.com/huanglianghua/GlobalTrack
按照教程,直接运行以下命令即可完成编译(然而事实上并不一定会这么顺利)。
好吧,那就按照官方的教程来走,有什么问题,解决就完事了!Let's go!
cd Global_Track/_submodules/mmdetection
python setup.py develop
emmm,好像和我预想的有点不一样,这次编译直接就成功了?!可以可以,应该是作者修改了 GlobalTrack 的源码,不然不会这么轻松,上一张编译成功的效果图!
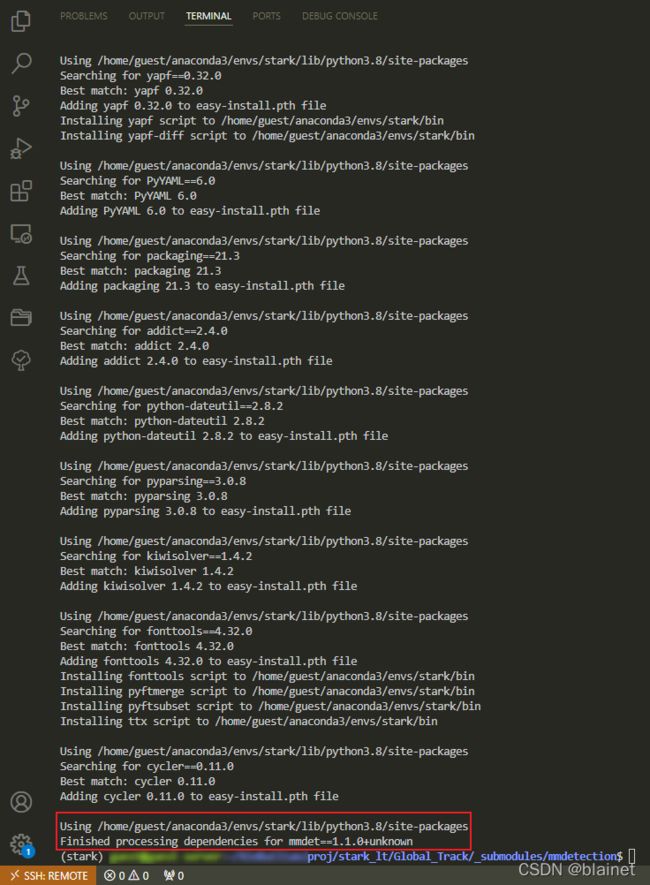
以下是哪一步会报这个错误 No module named ‘mmcv.cnn.weight_init,具体记不得了,这里的问题主要是 mmcv 版本和 mmdetection 版本不匹配,解决方法是:
pip install mmcv==0.4.3
参考链接:https://blog.csdn.net/qq_41375609/article/details/108011487 一步到位,非常感谢这个作者!
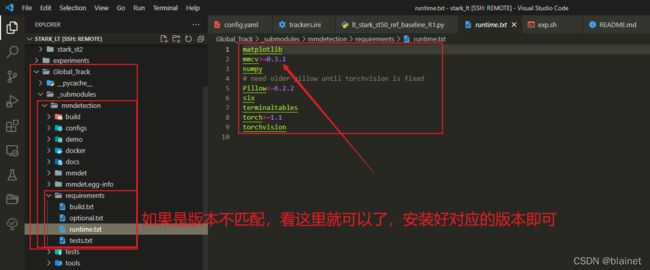
Step #5. 又回到了最初的地方,继续运行 VOT 进行调试
cd stark_st50_ref_baseline_R0
vot evaluate --workspace . STARK_LT
继续报错,提示缺少 shapely,
File "/home/xxx/xxx/proj/stark_lt/Global_Track/_submodules/neuron/neuron/ops/metrics.py", line 3, in <module>
from shapely import geometry
ModuleNotFoundError: No module named 'shapely'
Process not alive anymore, unable to retrieve return code
安装就是了 pip install shapely。
后面还是一些关于缺少包的错误 pip install sklearn。
提示预训练模型不存在:
FileNotFoundError: [Errno 2] No such file or directory: '/home/guest/XieBailian/proj/stark_lt/checkpoints/train/stark_ref/baseline/STARKST_ep0500.pth.tar'
Process not alive anymore, unable to retrieve return code
本来只要根据作者提供的下载链接下载,放入到对应的文件夹中即可,然而链接失效了!没办法,只能将已有的 STARKST_ep0050.pth.tar 复制一份,重命名为 STARKST_ep0500.pth.tar,然后运行测试,成功!(如果运行不成功,请看 Step #6)
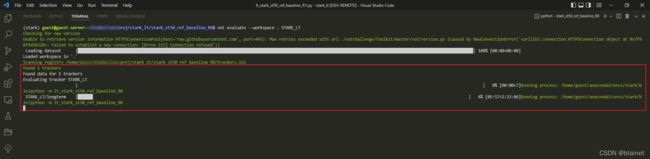
Step #6. 修改相关源代码
1. CUDA 相关

更正:以上注释有误!应该是指定机器哪些
GPU可见,也就是使用哪些GPU来进行计算。
即修改要运行的脚本文件的以下内容:
# os.environ["CUDA_VISIBLE_DEVICES"] = "7"
## 更改为
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1, 2"
2. vot 模块引入
原以为这部分会出问题,但是和 STARK 不一样,不用修改引入的代码,只需要按照 Step #1 修改好配置文件即可运行成功!
看了控制台的输出后,大致懂了:
Running process: /home/guest/anaconda3/envs/stark/bin/python -m lt_stark_st50_ref_baseline_R0
而 STARK 的控制台输出的启动命令如下:
Running process: /home/guest/anaconda3/envs/stark/bin/python -c "import sys;sys.path.insert(0, '/home/guest/XieBailian/proj/stark'); import lib.test.vot20.stark_st101_lt as stark_st101_lt"
stark_st101_lt/longt
应该就是这里的区别,以下是官方说明文档:
- When called with -c command, it executes the Python statement(s) given as command. Here command may contain multiple statements separated by newlines. Leading whitespace is significant in Python statements!
- When called with -m module-name, the given module is located on the Python module path and executed as a script.
参考链接:Python 命令行接口选项