常见CPU调度算法
CPU调度
初衷:
In a system with a single CPU core, only one process can run at a time. Others must wait until the CPU’s core is free and can be rescheduled. The objective of multiprogramming is to have some process running at all times, to maximize CPU utilization.
抢占式和非抢占式
preemptive and nonpreemptive scheduling
通常只会在以下4中情况发生时,产生CPU调度:
- 进程从 running 状态 转变为 waiting 状态(比如 等待I/O请求 或者 等待子进程而调用 wait() 系统调用)
- 进程从 running 状态 转变为 ready 状态(比如 产生中断)
- 进程从 waiting 状态转变为 ready 状态(比如 I/O请求完成后)
- 进程结束 terminate
如果 scheduling 调度只发生在情景1和情景4之下,则系统是 nonpreemptive 非抢占系统或称 cooperative 系统 ,因为这两种情况不可避免必然发生调度。反之,则是 preemptive 可抢占系统,Windows、MacOS、Linux、UNIX 都是使用的 preemptive algorithm。
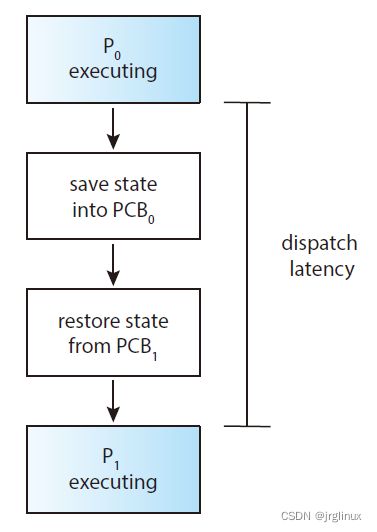
dispatcher
CPU调度中有个角色,dispatcher,其负责:
- Switching context from one process to another
- Switching to user mode
- Jumping to the proper location in the user program to resume that program
调度器算法衡量标准
| 评价因子 | 目的 |
|---|---|
| CPU utilization | 因为我们总是想让CPU尽可能的一直运行 |
| Throughput | 单位时间内CPU完成运行进程的数量 |
| Turnaround time | 周转时间,一个进程从submission到完成的时间,包括 ready状态时等待时间 + CPU执行时间 + I/O操作时间 |
| Waiting time | CPU调度并不能影响一个进程的执行完成本身所需的时间以及I/O操作完成本身所需的时间 它影响的是该进程在 ready 状态下等待被运行的时间。waiting time 就是 ready 状态下等待被运行的等待时间总和 |
| Response time | 交互式系统下,周转时间指标还不够。从用户请求的第一次提交到系统做出反应(不一定是请求完成)的时间就是response time |
调度算法
1. First-Come, First-Served Scheduling
FCFS 先来先得调度算法,进程先来的先运行。非抢占式系统。
比如三个进程P1,P2,P3,先后到来,则它们的平均turnaround time是 (24+27+30)/3 = 27

该算法的代码很好处理,即使考虑抢占和时间片,代码逻辑也不难,自定义调度器一开始的版本就是 FCFS+时间片+可抢占
2. Shortest-Job-First Scheduling
SJF 最短任务优先的调度算法,可以是抢占式系统也可以是非抢占式系统
还是上面的3个进程的例子:
短任务先运行,则它们的平均 turnaround time 是 (3+6+30)/3 = 13

该算法较为理想化,因为代码不太好实现,因为没办法事先知道每个任务所需要的CPU执行时间。所以,需要预测任务的执行时间,根据之前的任务使用CPU的表现来 predict 后面的执行时间,然后选择预测的最短任务先来运行。
估算方法:可以联想CFS中的负载估算法,同出一辙
tn be the length of the nth CPU burst, and let τn+1 be our predicted value for the next CPU burst. Then, for α, 0 ≤ α ≤1, define
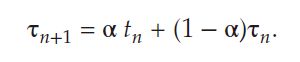
The value of tn contains our most recent information, while τn stores the past history.
下面就是一个估算的CPU运行时间的例子,取 α = 1/2 and τ0 = 10
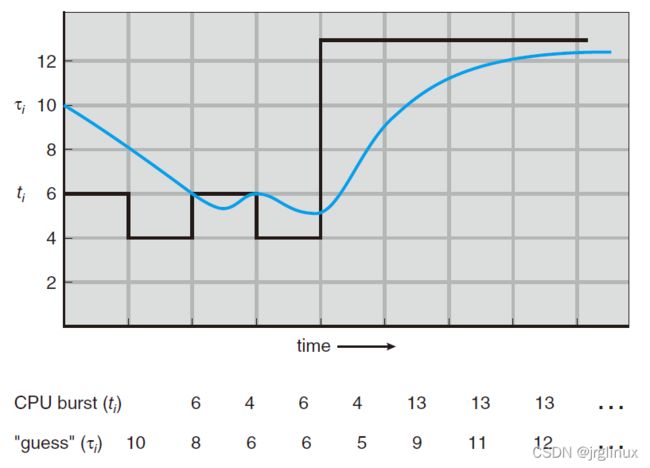
看这个公式立马就想到了CFS中的计算过去负载以及loadavg中的估算算法:
![]()
如果是抢占式系统,则叫做 剩余最短时间任务优先,shortest-remaining-time-first scheduling。

SJF优于FCFS
如果只是考虑平均周转时间或者平均等待时间,且是非抢占式系统下,从数学公式可以证明SJF优于FCFS算法。
3. Round-Robin Scheduling
轮询调度算法,round robin 来源于法语ruban rond(round ribbon),意思是环形丝带。该算法很类似 FCFS 算法,只不过多了一个时间片的概念。
ready 队列可以看做一个FIFO的环形队列,新进程插入到队尾,调度器每次从队首取第一个进程去运行,时间片到,则产生调度切换。
- 进程本身没有使用完时间片,发生调度切换
- 进程还在运行,时间片到了,发生调度切换,进程放回队尾
轮询调度算法的平均等待时间一般都比较长了,比如:
先后来了3个进程,以及它们所需要的运行时间如下图所示,
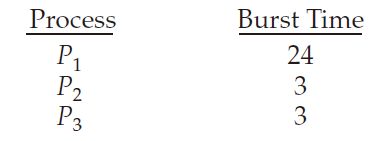
假设时间片是4ms,则执行过程如下:

P1 等待了6ms,P2等待了4ms,P3等待7ms,平均等待5.6ms
RR调度算法的性能很大程度上取决于该时间片的大小:
- 如果时间片(quantum)很大,则RR调度算法等同于了FCFS调度算法
- 如果时间片(quantum)很小,则会产生大量的context switch,性能严重受损
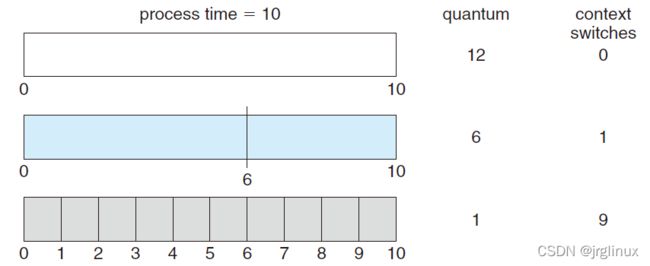
所以:
In practice, most modern systems have time quanta ranging from 10 to 100 milliseconds. The time required for a context switch is typically less than 10 microseconds; thus, the context-switch time is a small fraction of the time quantum.
4. Priority Scheduling
优先级调度算法。SJF 调度算法是优先级调度算法的一个具体实例,只不过 SJF 的优先级是按进程的下一段估算耗时来排的,耗时越多,优先级越低,越后运行。
支持抢占式系统或者非抢占式系统。相同优先级的按FCFS算法调度。
一个典型的问题是:低优先级进程饿死或者长期阻塞得不到CPU运行。
一种解决方法就是:aging。就是低优先级进程每等待一次,优先级提升一次,这样总会有机会得到运行。
可以将 RR 轮询调度算法 与 Priority 优先级调度算法结合使用:
比如如下的5个进程
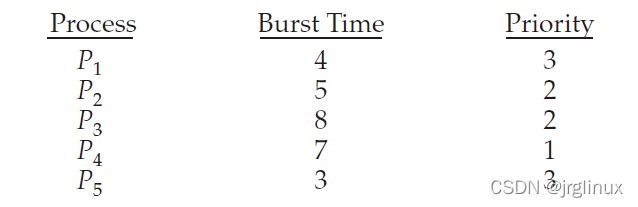
如果时间片是2ms,则运行结果如下:

5. Multilevel Queue Scheduling
多级队列调度算法,这是结合 RR轮询算法和 priority优先级调度算法。
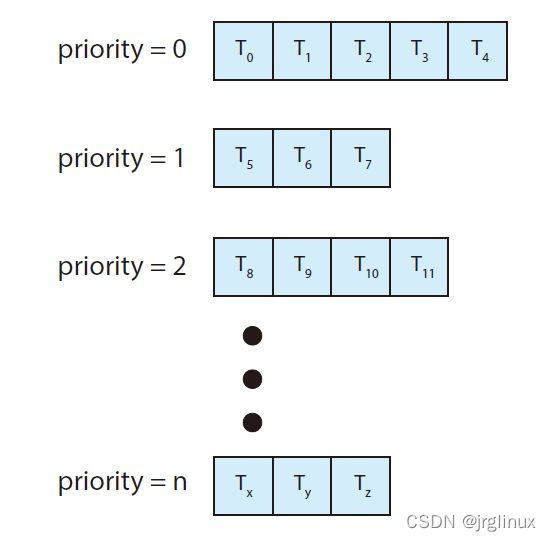
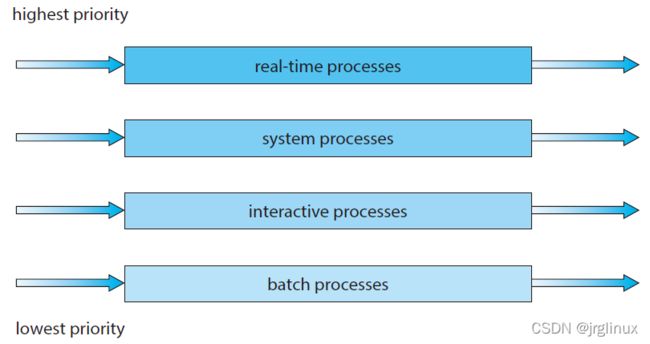
以上图为例,只有real-time、system、interactive队列为空了,才能运行batch队列的进程。
还有一种方案,可以总体设置队列之间能占CPU的百分比,比如CFS中的给实时进程队列最多95%,普通进程最少5%的CPU分配。
6. Multilevel Feedback Queue Scheduling
多级反馈队列调度算法。在多级队列调度算法中,一个进程进入某个队列后,就一直在该队列中,并不会移动到其他队列,这样虽然减少了调度本身产生的消耗,但这无疑是固执的。
多级反馈队列调度算法则允许进程在不同级别队列之间移动。比如一个进程使用过了很多CPU时间,则可以把它移到低优先级队列中去,一个进程长时间在低优先级队列排队等待运行,则可以把它移动到高优先级队列中去。
举例:
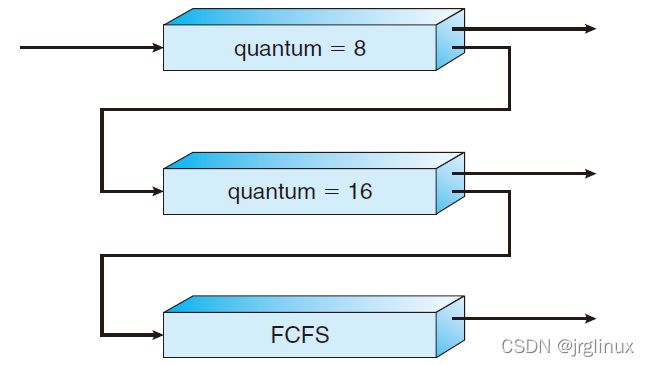
如下有三个队列,queue0,queue1,queue2。
- queue1中的进程只有在queue0队列为空后才得到运行,queue2中的进程只有在queue0和queue1都为空后才运行
- queue0中时间片为8ms,如果该队列中进程在时间片内未完成,则被追加到queue1的队尾
- 当queue0队列为空,queue1队首的进程得到CPU运行,时间片16ms,如果时间片内进程未完成,则被抢占,该进程被追加到queue2的队尾
- qeueu2采用FCFS调度算法,且是在queue0和queue1都为空后才执行
- 避免低优先级进程饥饿,低优先级队列中等待时间过长的进程会被移动到高优先级去排队执行
多级队列反馈调度算法关键点:
- 队列的数量
- 每个队列中使用的调度算法
- 何时将进程从低优先级队列移动到更高优先级队列
- 何时将进程从高优先级队列移动到低优先级队列
- 决定将新来进程插入哪个queue队列的算法
通过多对反馈队列调度算法模型设计出的调度算法一般都是操作系统中比较能通用的,但通常也是最为复杂的调度算法。
【Linux中的调度算法stop–deadline–rt–cfs–idle不就是这个设计模型设计出来的嘛】
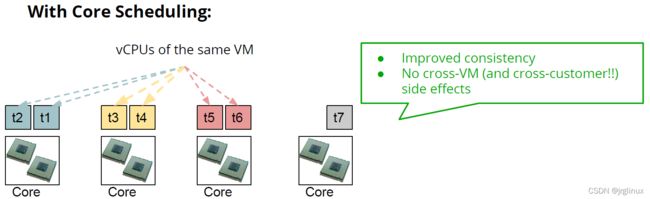
core-scheduling
已被合入主线,Linux-5.14开始支持
介绍
主要目的是为了让SMT(simultaneous multi-threading,或者"hyperthreading",超线程)能更加安全,不受speculative-execution类型的攻击。一个SMT 核包含两个或者更多的CPU(有时候也被称为“hardware threads”)都共享很多底层硬件。这里共享的包括一部分cache,这样导致SMT可能会受基于cache进行的side-channel攻击。core-scheduling它可以让互不信任的进程不会同时执行在同一个core核心上。
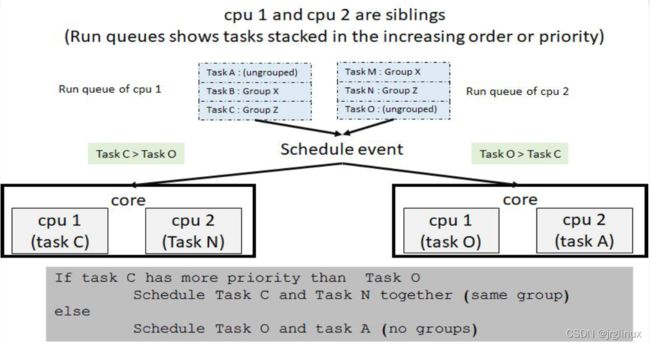
core scheduling group会信赖运行在同一个core上的任务。它会把SMT core内部的多个CPU作为同一个实体,在其内部的所有CPU上寻找最高优先级的任务,然后决定下一步调度哪个任务。如果这时候看到另一个任务能跟这个高优先级任务兼容(互信)的话,就让兄弟CPU来执行这个任务,否则只好让兄弟CPU空闲了。
第一版本的core scheduling是针对KVM实现的,只允许同一个虚拟机里的virtual CPU thread共享同一个core。后来有了更通用的实现,是依靠系统管理员来定义trust boundaries(信任边界)。最开始的实现方法是利用cgroup,然后系统管理员来标记哪些任务是互相兼容(信赖)的,从而放到同一个group里去,或者对多个group设置相同的cpu.tag值。
core scheduling 功能并不适合每个人,它只对对一些用户群体有用。
同步多线程(SMT,simultaneous multithreading,或称 “超线程,hyperthreading”)是一种可以在一个处理器中实现两个或更多的在执行的线程的硬件功能,这样一来,单个 CPU 看起来就像是有一组 “sibling(兄弟)” 的 CPU。当其中一个兄弟 CPU 在执行时,其他的就必须等待了。SMT 很有用,因为 CPU 在等待某些 event 时经常会空闲下来,通常是在等待从内存获取到的数据。当一个 CPU 在等待时另一个就可以执行了。SMT 并不是对所有 workload 的性能都有提升,但对大多数 workload 来说它都是一个重大的改进。
SMT 中的这些兄弟 CPU 共享了 CPU 内部几乎所有硬件,其中也包括 CPU 在维护的这些 cache。这就提供了一种可能性,即其中一个 sibling CPU 可以通过观察 cache 中可以观察到的一些变动,从而提取来自另一个 sibling CPU 操作的数据。Spectre 硬件漏洞使得这个问题变得更加严重了,而且几乎没有办法解决。要想用目前的内核来安全地运行两个互不信任的进程的话,唯一可靠的办法就是完全禁用 SMT,这可是很多人(尤其是云计算供应商)明显感到很不爽的一种做法。
虽然人们可能会争辩说,云计算供应商总是看什么都不满意,不用去管他们的抱怨。但实际上如果有办法能让他们满意的话,那就非常有价值了。其中一种可能性就是允许他们在自己的系统上启用 SMT,同时又能避免他们的一些客户利用其缺陷来攻击其他人。只要能相互不信任的进程不在同一 CPU core 上同时运行,就可以实现这个效果了。云服务的客户经常同时有许多进程在运行(毕竟,大规模地向互联网用户发送垃圾邮件就需要很多并发活动)。如果这些进程可以被限制起来,使得任何一个 CPU core 中的所有 sibling CPU 都只会运行来自同一客户的进程的话,那么我们就可以避免某个垃圾邮件发送者来窃取另一位垃圾邮件发送者的客户列表了,当然也会保护了其他用户的私钥等重要信息。
core scheduling 就可以提供这种隔离。抽象来说,每个进程都被分配了一个 “cookie”,代表了它的某种特性。比如可以给每个用户分配一个独特的 cookie。然后,scheduler 会确保实行一条规则:进程只有在具有相同的 cookie 值时才能共享 SMT core,换句话说,也就是只有在它们能相互信任的情况下。
core scheduling 是通过 prctl() 系统调用来管理的,该系统调用通常定义如下:
int prctl(int option, unsigned long arg2, unsigned long arg3,
unsigned long arg4, unsigned long arg5);
在 core-scheduling 这种操作的情况下,option 值为 PR_SCHED_CORE,其余参数定义为:
int prctl(PR_SCHED_CORE, int cs_command, pid_t pid, enum pid_type type,
unsigned long *cookie);
通过 cs_command 可以选择四种可能的操作:
- PR_SCHED_CORE_CREATE,使内核生成一个新的 cookie,并将其分配给进程号为 pid 的进程。type 参数控制这个分配动作的影响范围。例如,PIDTYPE_PID 就是指明只改变它所代表的进程,而 PIDTYPE_TGID 则将 cookie 分配给整个 thread group 线程组。cookie 参数的值必须为 NULL。
- PR_SCHED_CORE_GET,查找 pid 对应的 cookie 值,将其存放在 cookie 中。注意,用户空间进程就算拿到 cookie 值,也没有太多用处,仅仅能够用来检查两个进程是否有相同的 cookie。
- PR_SCHED_CORE_SHARE_TO,将调用者进程的 cookie 值分配给 pid(如上所述,也是使用 type 来控制影响范围)。
- PR_SCHED_CORE_SHARE_FROM,根据 pid 获取 cookie 并将其分配给调用者进程。
一个进程不能随意获取和分配 cookie,这里的判断条件跟一般人们考虑的 "这个进程能否对目标进程调用 trace() " 的条件差不多。它也不可能在用户空间生成 cookie 值,这个限制确保了不相关的进程只会获得完全不相同的 cookie 值。内核只允许 cookie 值在已经有一定程度相互信任的进程之间传播,这样一来就可以阻止恶意进程将自己的 cookie 改为跟目标进程一样的 cookie 值来进行攻击了。
机制核心:
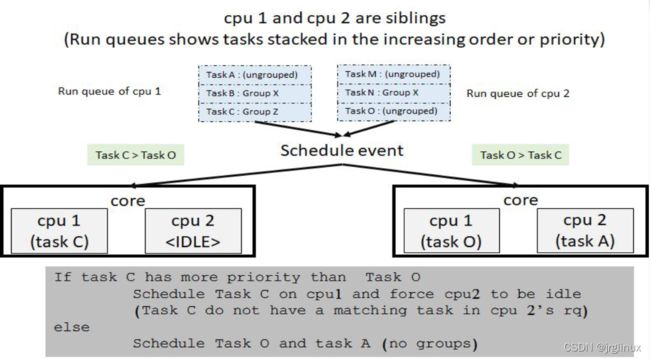
每当一个 CPU 来执行 scheduler 代码时,会先挑出最高优先级的任务,按正常方式运行。如果 core scheduling 启用了,那么接下来就会向 sibling CPU 发送一个 IPI 中断(inter-processor interrupt),每个 sibling CPU 就会相应地来检查这个刚刚得到调度的进程的 cookie 值与本地已经在运行进程的 cookie 值是否相等。如果有必要的话,被中断打断的 CPU 就会切换到另一个拥有相同 cookie 的进程去执行,即使当前正在运行的进程具有更高的优先级也不影响这个结果。如果没有能互相信任的其他进程,那么这个 sibling CPU 就直接闲置下来,直到情况发生变化为止。如果可能的话,scheduler 会在各个 CPU 之间迁移进程来避免这个 sibling CPU 被强制空闲下来。
示例
cpu1和cpu2是一个core上的SMT sibling CPU
情况一:cpu1和cpu2的队列里有相同cookie的进程
情况二:cpu1和cpu2的队列里没有相同cookie的进程,那么其中一个sibling cpu就可能空闲了
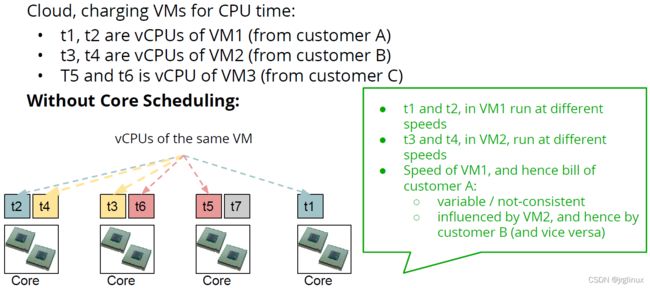
vcpu场景应用
【综合看,core-scheduling的价值可能更体现在虚拟机安全,对提升性能有待评测】
实时调度算法
| 两种实时方案 | |
|---|---|
| 软实时 | 当一个严格的实时进程需要执行时,无法100%保证实时得到立即执行 |
| 硬实时 | 严格的实时 |
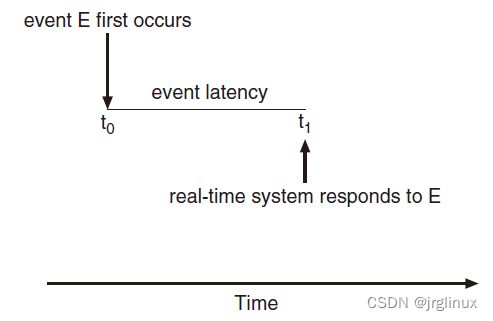
最小延迟
event latency 定义:event产生到其被响应的时间。
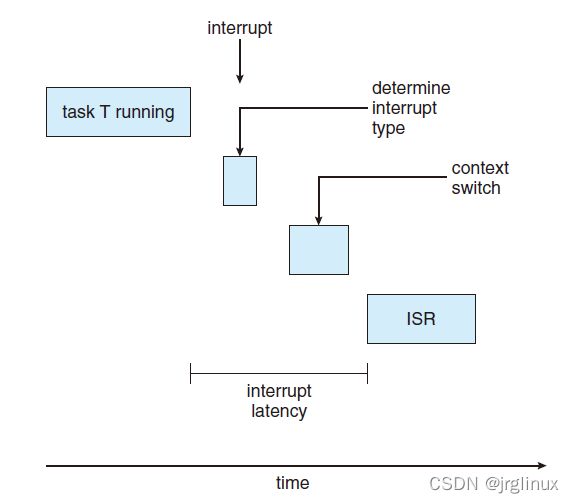
实时系统中比较关心的两种延迟:
| 延迟 | 含义 |
|---|---|
| interrupt latency | 中断延迟,从中断产生到被中断服务程序ISR(interrupt service routine)执行响应的总时间 |
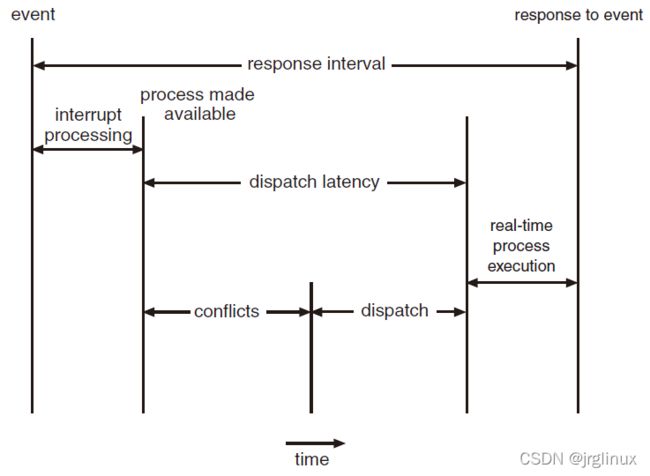
| dispatch latency | 调度延迟,调度器从开始停止一个进程到切换到另一个进程开始运行的总时间 |
interrupt latency
dispatch latency
其中,conflict(冲突阶段)一般是要处理这两种情况:
- 需要抢占preempt当前内核正在运行的进程
- 需要等待一些被低优先级进程占着的资源释放出来,给当前高优先级进程使用(【注:这里应该就是会发生优先级反转问题】)
Priority-Based Scheduling
基于优先级的调度算法
可抢占的基于优先级的实时调度算法,可实现软实时调度。
Rate-Monotonic Scheduling
RMS(单调速率调度算法)是一种静态优先级调度算法,是经典的周期性任务调度算法。
RMS的基本思路是任务的优先级与它的周期表现为单调函数的关系,任务的周期越短,优先级越高;任务的周期越长,优先级越低。如果存在一种基于静态优先级的调度顺序,使得每个任务都能在其期限时间内完成,那么RMS算法总能找到这样的一种可行的统调度方案。
一些假设:
(A1) 所有的任务请求都是周期性的,必须在限定的时限内完成;
(A2) 任务的作业必须在该任务的下一个作业发生之前完成,这样避免了考虑队列问题; 在这里,我们对任务和作业不作特别的区分,因为一个任务请求就是一个作业。
(A3) 任务之间都是独立的,每个任务的请求不依赖于其他任务请求的开始或完成;
(A4) 每个任务的运行时间是不变的,这里任务的运行时间是指处理器在无中断情况下用于处理该任务的时间;
(A5) 所有的非周期性任务都在特殊的情况下运行,比如系统初始化或系统非正常紧急处理程序。
(A6) 其它一些假设,比如,单处理器,可抢占调度,任务切换的时间忽略不计等等。
举例说明:
假设有两个进程:
| 进程 | periods周期 | 执行所需时间 | deadline期限 |
|---|---|---|---|
| P1 | p1 = 50 | t1 = 20 | 下一个period周期开始前执行完 |
| P2 | p2 = 100 | t2 = 35 | 下一个period周期开始前执行完 |
首先,计算是否有可能按时完成两个进程运行。
按公式**CPU 使用率 = ti/pi ** 计算:总的CPU使用率为0.75,理论上是可以按时完成两个任务的。
| 进程 | CPU使用率 |
|---|---|
| P1 | 0.4 |
| P2 | 0.35 |
假设一:P2优先级高于P1
那么其执行过程时间表如下图所示,P2先执行,至35ms时执行完毕,然后P1开始执行,P1需要到55ms才执行完毕,但P1的deadline是50ms,那么P1则延迟了。
假设二:P1优先级高于P2
P1先执行,20ms执行完毕,然后P2开始执行,执行到50ms时,会被 P1 preemptive抢占(尽管此时P2就差5ms就执行完,但P1优先级高,会抢占),接着P1执行到70ms时完毕,然后P2继续执行到75ms,P2执行完毕。然后等下一个周期100ms开始,还是P1先来,然后P2,重复第一个100ms周期内的调度执行情况。

但是,也不是光看CPU使用率就能判断 rate-monotonic 调度算法就可以用的。比如,假设P1的周期p1=50ms,t1=25ms,P2的p2=80ms,t2=35ms,P1的周期p比P2短,优先级高于P2,则其:

如上图所示,P2会超过其deadline的80ms,同样不满足实时要求。
所以要使用 RMS 调度算法,CPU使用率有一定限定:
U < N(2^(1∕N) − 1)
Earliest-Deadline-First Scheduling
最早期限任务优先调度算法。EDF调度算法。
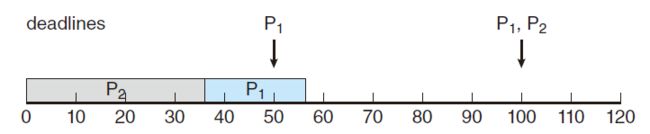
举例,两个进程P1和P2,进程P1的周期p1=50ms,t1=25ms,进程P2的周期p2=80ms,t2=35ms。

- 在开始时,因为P1的deadline 50ms 小于 P2的deadline 80ms,所以 P1优先级比 P2 高,先运行P1
- P1在25ms执行完,然后P2开始执行,等到50ms时,此时EDF算法和RMS算法就不一样了,因为此时P2的deadline为80ms,比P1此时的deadline为100ms要早,所以此时P2优先级高于P1,P2继续运行至60ms完毕
- 然后P1开始执行,直至85ms执行完毕,期间80ms时P2优先级没有P1高,无法抢占
- 然后P2开始执行,至100ms时,P1抢占
Proportional Share Scheduling
比列分享调度算法
举个例子:
假设按100总数计算,三个进程A/B/C,A设定分配50,B设定分配15,C设定分配20,也就是A占50%,B占15%,C占20%,总共占用了85%。此时如果有个进程D,设定占30,那么其如果加入进来就超了100%,所以系统就不会让D进入这个分享圈子。
POSIX Real-Time Scheduling
SCHED_FIFO
SCHED_RR
这两种调度策略算法,也可以参考Linux内核实现,Linux内核中保留了这两种实时调度算法。