人工智能-强化学习-算法:DQN(Deep Q-Learning Network)【Deep Learning Network + Q-Learning 】
DQN(Deep Q-Learning Network)可谓是深度强化学习(Deep Reinforcement Learning,DRL)的开山之作,是将深度学习与强化学习结合起来从而实现从感知(Perception)到动作( Action )的端对端(End-to-end)学习的一种全新的算法。由DeepMind在NIPS 2013上发表1,后又在Nature 2015上提出改进版本2。
- DQN(Deep Q-Learning Network)创新点:
- 基于Q-Learning构造Loss Function(不算很新,过往使用线性和非线性函数拟合Q-Table时就是这样做)。
- 通过experience replay(经验池)解决相关性及非静态分布问题;
- 使用TargetNet解决稳定性问题。
- DQN(Deep Q-Learning Network)优点:
- 算法通用性,可玩不同游戏;
- End-to-End 训练方式;
- 可生产大量样本供监督学习。
- DQN(Deep Q-Learning Network)缺点:
- 无法应用于连续动作控制;
- 只能处理只需短时记忆问题,无法处理需长时记忆问题(后续研究提出了使用LSTM等改进方法);
- CNN不一定收敛,需精良调参。
一、Deep “Reinforcement Learning”
- 在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不现实。通常做法是把Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作。如下式,通过更新参数 θ 使Q函数逼近最优Q值
Q ( s , a ; θ ) ≈ Q ′ ( s , a ) Q(s,a;θ)≈Q'(s,a) Q(s,a;θ)≈Q′(s,a) - 而深度神经网络可以自动提取复杂特征,因此,面对高维且连续的状态使用深度神经网络最合适不过了。
- DRL(Deep Reinforcement Learning)是将深度学习(DL)与强化学习(RL)结合,直接从高维原始数据学习控制策略。而DQN是DRL的其中一种算法,它要做的就是将卷积神经网络(CNN)和Q-Learning结合起来。
- DQN中的CNN的输入是原始图像数据(作为状态State),
- DQN中的Q-Learning输出则是每个动作Action对应的价值评估Value Function(Q值)。
二、DL(Deep Learning)与RL(Reinforcement Learning)结合的问题
- DL需要大量带标签的样本进行监督学习;RL只有reward返回值,而且伴随着噪声,延迟(过了几十毫秒才返回),稀疏(很多State的reward是0)等问题;
- DL的样本独立;RL前后state状态相关;
- DL目标分布固定;RL的分布一直变化,比如你玩一个游戏,一个关卡和下一个关卡的状态分布是不同的,所以训练好了前一个关卡,下一个关卡又要重新训练;
- 过往的研究表明,使用非线性网络表示值函数时出现不稳定等问题。
三、DQN(Deep Q-Learning Network)解决DL与RL结合的问题的方法
- 通过Q-Learning使用reward来构造标签(对应问题1)
- 通过experience replay(经验池)的方法来解决相关性及非静态分布问题(对应问题2、3)
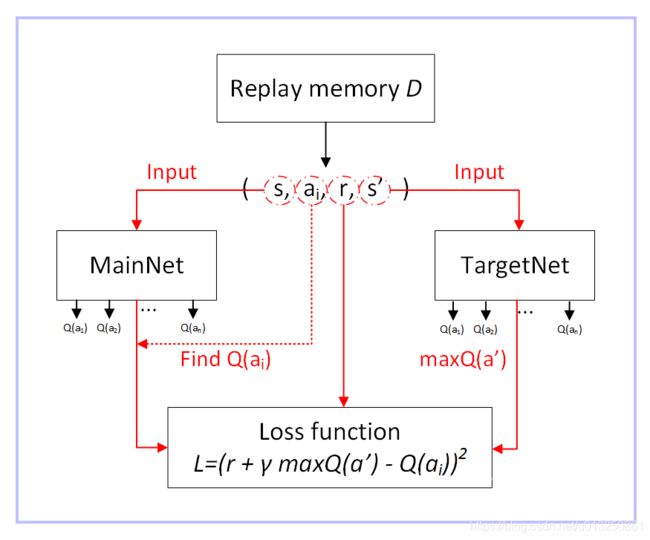
- 使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值(对应问题4)
1、构造标签
- 前面提到DQN中的CNN作用是对在高维且连续状态下的Q-Table做函数拟合,而对于函数优化问题,监督学习的一般方法是先确定Loss Function,然后求梯度,使用随机梯度下降等方法更新参数。DQN则基于Q-Learning来确定Loss Function。
- Q-Learning的更新公式:
Q ∗ ( s , a ) = Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q^∗(s,a)=Q(s,a)+α[r+γ\max_{a'}Q(s',a')−Q(s,a)] Q∗(s,a)=Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)] - DQN的Loss Function为:
L ( θ ) = E [ ( T a r g e t Q − Q ( s , a ; θ ) ) 2 ] L(θ)=E[(TargetQ−Q(s,a;θ))^2] L(θ)=E[(TargetQ−Q(s,a;θ))2]
其中 θ 是网络参数 - 目标为
T a r g e t Q = r + γ max a ′ Q ( s ′ , a ′ ; θ ) TargetQ=r+γ\max_{a′}Q(s',a';θ) TargetQ=r+γa′maxQ(s′,a′;θ) - 显然Loss Function是基于Q-Learning更新公式的第二项确定的,两个公式意义相同,都是使当前的Q值逼近Target Q值。
- 接下来,求 L ( θ ) L(θ) L(θ) 关于 θ θ θ 的梯度,使用SGD等方法更新网络参数 θ θ θ。
2、Experience Replay Buffer(经验池)
经验池的功能主要是解决相关性及非静态分布问题。具体做法是把每个时间步agent与环境交互得到的转移样本 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1) 储存到回放记忆单元,要训练时就随机拿出一些(minibatch)来训练。(其实就是将游戏的过程打成碎片存储,训练时随机抽取就避免了相关性问题)

- replay buffer 的意思是说:现在我们会有某一个 policy pi 去跟环境做互动,然后它会去收集 data,我们会把所有的 data 放到一个 buffer 里面,那 buffer 里面就排了很多 data,那你 buffer 设比如说5 万,这样它里面可以存 5 万笔数据。
- 每一笔数据就是记得是之前在某一个 state s t s_t st 采取某一个 action a t a_t at,接下来我们得到的 reward r t r_t rt,然后接下来跳到 state s t + 1 s_{t+1} st+1 这么一个过程。
- π π π 跟环境互动很多次,把所有收集到的数据通通都放到这个 replay buffer 里面,这个 replay buffer 它里面的 experience 可能是来自于不同的 actor/policy π π π,因为每次拿 π π π 去跟环境互动的时候,你可能只互动 10,000 次,然后接下来你就更新 π π π 了,但是你的这个 buffer 里面可以放 5 万笔数据,所以那 5 万笔数据,它们可能是来自于不同更新程度的 π π π。
- buffer 只有在它装满的时候才会把旧的资料丢掉。所以这个 buffer 里面它其实装了很多不同更新程度的 actor/policy π π π 所计算出来的不同的 π π π 的 experiences。
- 就跟一般的 network training 一样,从这个 buffer 里面随机挑一个 batch 出来,里面有一把的 experiences,根据这把 experiences 去 update 你的 Q function。
- 实际上存在你的 replay buffer 里面的这些experiences 不是通通来自于 某一个更新程度的 π π π,有些是过去其他更新程度的 π π π所遗留下来的 experience,因为你不会拿某一个 π π π 就把整个 buffer 装满去测 Q function。这个 π π π 只是 sample 了一些 data塞到那个 buffer 里面去,然后接下来就让 Q 去 train。所以 Q 在 sample 的时候,它会 sample 到过去的一些数据。这么做有两个好处:
- 第一个好处:其实在做 reinforcement learning 的时候,往往最花时间的 step是在跟环境做互动,train network 反而是比较快的,因为你用 GPU train 其实很快。replay buffer的使用 可以减少跟环境做互动的次数,因为今天你在做 training 的时候,你的 experience 不需要通通来自于某一个 actor/policy π π π,一些过去的 actor/policy π π π 所得到的 experience可以放在 buffer 里面被使用很多次,被反复的再利用,这样让你的 sample 到 experience 的利用是比较 efficient。
- 第二个好处:在 train network 的时候,其实我们希望一个 batch 里面的 data越 diverse 越好。如果你的 batch 里面的 data 通通都是同样性质的,你 train 下去,其实是容易坏掉的。如果你 batch 里面都是一样的 data,你 train 的时候,performance 会比较差,所以我们希望 batch data 越 diverse 越好。如果这个 buffer 里面的那些 experience 通通来自于不同的 policy 的话,那 sample 到的一个 batch 里面的 data 会是比较 diverse 的。
- 但是接下来你会问的一个问题是:我们明明是要观察最新更新的 π π π 的 value,里面混杂了一些不是最新更新的 π π π 的 experience,到底有没有关系?一个很简单的解释,也许这些不同更新程度的 π π π 也没有差别那么多,所以也没有关系,就算过去的 π π π 和最新更新的 π π π 根本不想其实也是没有关系的,今天主要的原因是因为,我们并不是去 sample 一个 trajectory,我们只是 sample 了一笔 experience。
3、Target Network(目标网络)
- 在Nature 2015版本的DQN中提出了这个改进,使用另一个网络(这里称为TargetNet)产生Target Q 值。具体地, Q ( s , a ; θ i ) Q(s,a;θ_i) Q(s,a;θi) 表示当前网络MainNet的输出,用来评估当前状态动作对的值函数; Q ( s , a ; θ ‾ i ) Q(s,a;\overline{θ}i) Q(s,a;θi) 表示TargetNet的输出,代入求 TargetQ 值的公式 T a r g e t Q = r + γ max a ′ Q ( s ′ , a ′ ; θ ) TargetQ=r+γ\max_{a′}Q(s',a';θ) TargetQ=r+γa′maxQ(s′,a′;θ) 中得到目标Q值。根据Loss Function
L ( θ ) = E [ ( T a r g e t Q − Q ( s , a ; θ ) ) 2 ] L(θ)=E[(TargetQ−Q(s,a;θ))^2] L(θ)=E[(TargetQ−Q(s,a;θ))2]
更新MainNet的参数,每经过N轮迭代,将MainNet的参数复制给TargetNet。 - 引入TargetNet后,在一段时间里目标Q值使保持不变的,一定程度降低了当前Q值和目标Q值的相关性,提高了算法稳定性。
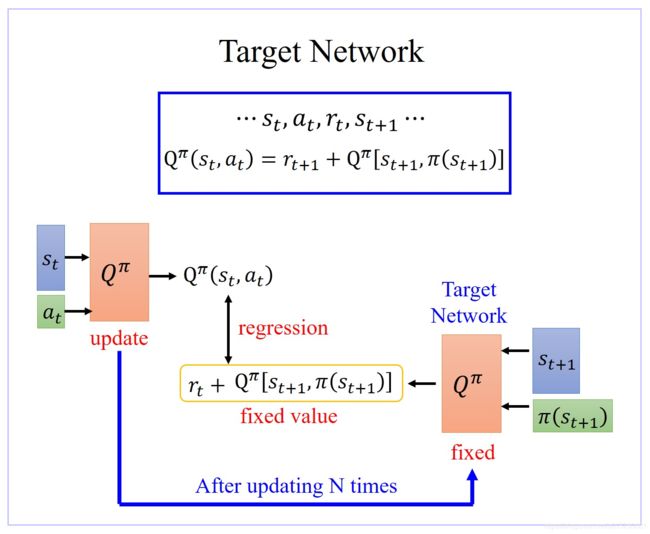
- 在 learn Q π ( s , a ) Q^π(s,a) Qπ(s,a) 过程中,在 state s t s_t st,你采取 action a t a_t at 以后得到 reward r t r_t rt,然后进入下一个 state s t + 1 s_{t+1} st+1,根据 Temporal-difference(TD) approach 方法可知: Q π ( s t , a t ) = r t + 1 + Q π [ s t + 1 , π ( s t + 1 ) ] Q^π(s_t,a_t)=r_{t+1}+Q^π[s_{t+1},π(s_{t+1})] Qπ(st,at)=rt+1+Qπ[st+1,π(st+1)]。 Q π ( s t , a t ) Q^π(s_t,a_t) Qπ(st,at) 与 Q π [ s t + 1 , π ( s t + 1 ) Q^π[s_{t+1},π(s_{t+1}) Qπ[st+1,π(st+1) 之间差了一项就是 r t r_t rt。
- 所以在 learn 的时候,就是将 Q π ( s t , a t ) Q^π(s_t,a_t) Qπ(st,at) function 输入 [ s t + 1 , π ( s t + 1 ) ] [s_{t+1},π(s_{t+1})] [st+1,π(st+1)] 得到的值与输入 ( s t , a t ) (s_t,a_t) (st,at) 得到的Output 之间的差尽可能接近 r t r_t rt。
- 但是实际上在 learn 的时候,这样的一个 function 并不好 learn。因为假设这是一个 regression 的 problem,假设右边的 Q π Q^π Qπ 是target,你会发现你的 target 是会动的,training 会变得不太稳定。这种一直在变的 target 的 training 其实是不太好 train 的。
- 解决方案:
- 先让Target Network 固定住,也就是说你在 training 的时候,你并不 update 这个 Target Network 的参数,只 update 左边 Target Network 的参数,而右边这个 Q 的参数,它会被固定住。target network 负责产生 target。因为 target network 是固定的,所以你现在得到的 target,也就是 r t + 1 + Q π [ s t + 1 , π ( s t + 1 ) ] r_{t+1}+Q^π[s_{t+1},π(s_{t+1})] rt+1+Qπ[st+1,π(st+1)] 的值也会是固定的。那我们只调左边这个 network 的参数。它就变成是一个 regression 的 problem。我们希望我们 model 的 output,它的值跟你的目标越接近越好,minimize 它的 mean square error 或 minimize 它们 L2 的 distance。问题就转换为 regression 问题。
- 在实操上,一开始这两个 network 是一样的,先让Target Network 固定住,把左边的 Q update 好几次,再去把右边的 Target network 用 update 过的左边的 Q 替换掉。但它们两个不要一起动,他们两个一起动的话,结果会很容易坏掉。用 update 后的 Target network 再一次迭代训练左边的 Q。如此反复迭代。
四、DQN算法
1、网络模型
下图所示,输入的是被处理成灰度图的最近4帧 84×84 图像(state s s s),经过几个卷积层(没有池化层)后接两个全连接层,输出是所有动作/action 的 Q Q Q 值。

2、算法伪代码
2.1 NIPS 2013版

2.2 Nature 2015版
3、Loss Function 的构造
四、DQN进阶版本
4.1 DDQN(Double DQN)
- 在DDQN之前,基本上所有的目标Q值都是通过贪婪法直接得到的,无论是Q-Learning, DQN(NIPS 2013)还是 Nature DQN,都是如此。比如对于Nature DQN,虽然用了两个Q网络并使用目标Q网络计算Q值,其第j个样本的目标Q值的计算还是贪婪法得到的,计算入下式:
y j = { R j i s _ e n d j i s t r u e R j + γ max a ′ Q ′ ( ϕ ( S j ′ ) , A j ′ , w ′ ) i s _ e n d j i s f a l s e \begin{aligned} y_j= \begin{cases} R_j \qquad \qquad \qquad \qquad \qquad \qquad \qquad is\_end_j\ is\ true\\ R_j+γ\max_{a'}Q^{'}(ϕ(S^{'}_j),A^{'}_j,w^{'}) \qquad is\_end_j\ is\ false\\ \end{cases} \end{aligned} yj={Rjis_endj is trueRj+γmaxa′Q′(ϕ(Sj′),Aj′,w′)is_endj is false - 使用max虽然可以快速让Q值向可能的优化目标靠拢,但是很容易过犹不及,导致过度估计(Over Estimation),所谓过度估计就是最终我们得到的算法模型有很大的偏差(bias)。为了解决这个问题, DDQN通过解耦目标Q值动作的选择和目标Q值的计算这两步,来达到消除过度估计的问题。

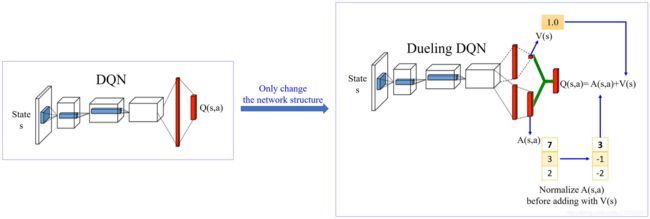
4.2 Dueling DQN
-
Dueling DQN相比较DQN唯一优化的地方就是:修改Network的架构,可以更有效率地使用data来更新Network。
-
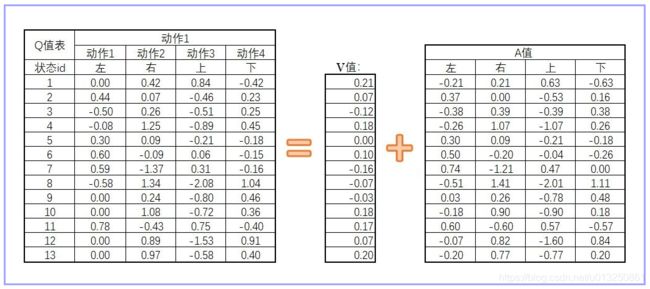
现在我们回到Qtable,虽然不精确,但Qtabel能够直观地把原理呈现出来。我们先改变Q值表的记录方式,原来我们会直接预估Q值表的数据,现在我们需要预估两个值:V值和A值。S值可以看成是该state下的Q值的平均数。A值是有所限制的,A值的平均数为0,V值与A值的和,就是原来的Q值。
-
搞这么复杂有什么好处呢?我们仍然可以用理解Qlearning的方式,把图像可视化出来理解。
-
我们之前说过,DQN的Q网络,可以理解用一个曲线去拟合Qtable的Q值。现在我们取一个截面,表示当我们取某个V下,各个动作的Q值。
-
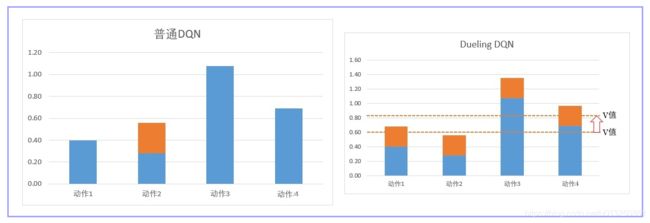
在普通DQN,当我们需要更新某个动作的Q值,我们会直接更新Q网络,令这个动作的Q值提升。
-
如上图大家看到,一般DQN在提升某个状态下的S值时,只会提升某个动作。
-
但是在Dueling DQN中: 在网络更新的时候,由于有A值之和必须为0的限制,所以网络会优先更新V值。V值是Q值的平均数,平均数的调整相当于一次性V下的所有Q值都更新一遍。如上图,橙色虚线是平均值,也就是V值。所以网络在更新的时候,不但更新某个动作的Q值,而是把这个状态下,所有动作的Q值都调整一次。在图上就相当于直接提着橙色虚线调整。这样,我们就可以在更少的次数让更多的值进行更新。有同学可能会担心,这样调整最后的数值是对的吗?放心,在DuelingDQN,我们只是优先调整S值。但最终我们的target目标是没有变的,所以我们最后更新出来也是对的。
-
DeulingDQN在实现的过程中,有可能说,反正 machine 就学到说我们也不要管什么 V 了,V 就永远都是 0。然后反正 A 就等于 Q,那你就没有得到任何 Dueling DQN 可以带给你的好处,就变成跟原来的 DQN 一模一样。所以为了避免这个问题,实际上你会对 A设定一些 constrain,你要给 A 一些 constrain,让 update A 其实比较麻烦,让 network 倾向于 会想要去用 V 来解问题。
-
我们可以把dueling DQN分为三部分。
- 第一部分:和普通DQN一样,用来处理和学习数据。
- 第二部分:计算 V 的值,就是让网络预估的平均值。
- 第三部分:计算A的值,和计算 V 的值一样,我们都是从h2层输入到该层。然后我们对A的值进行归一化处理,也就是增加“A值的平均值为0”的限制/Constrain。归一化的处理步骤是 network 的一部分,它没有参数,它就是一个 normalization 的 operation,那它可以放到 network 里面跟 network 的其他部分 jointly trained。这样 A 就会有比较大的 constrain,这样 network 就会给它一些 benefit,倾向于去 update V 的值。
-
DeulingDQN的实现很简单,只需要修改Q网络的网络架构就可以了。而且可以和其他DQN的技巧,例如经验回放,固定网络,双网络计算目标等可以共用。
参考资料:
深度强化学习——DQN
Playing Atari with Deep Reinforcement Learning
Human-level control through deep reinforcement learning
强化学习(十)Double DQN (DDQN)
强化学习(十)Double DQN (DDQN)
[番外篇]DuelingDQN为何那么强?(附代码及代码分析)