Meta R-CNN : Towards General Solver for Instance-level Low-shot Learning 论文笔记
前言
本文提出了一种实现小样本目标检测的通用方法,基于Faster R-CNN生成的RoI feature进行元学习。目前的元学习方法在小样本识别方面非常有用,这主要是因为只需识别单个目标。但如果一张图像中包含多个目标,并且还混合的有背景信息,那么这些元学习方法就不再有用了,因为它不能将这些复杂的信息分开。本文发现,可以通过Faster R-CNN产生的RoI feature对这些混合的目标进行预处理,由于每个RoI feature都指向单个目标或背景,因此Faster R-CNN能够解开这些复杂的信息,进而进行元学习。
基于此,本文构建了Faster R-CNN和元学习之间的联系,通过引入Predictor-head Re-modeling Network (PRN)对Faster R-CNN进行扩增。PRN是一个全卷积网络,并且与Faster R-CNN共享main backbone的参数,也就是Faster R-CNN的前半部分。PRN与Faster R-CNN的后半部分,也就是R-CNN的不同之处在于,它接收的是从基类(base class)和新类(novel class)中得到的小样本目标,包括目标的bbox,然后得到这些目标所属的类的类注意向量(class-attentive vector),每个向量对所有的RoI feature进行channel-wise的attention操作,从而进行针对类的检测。那么这样就对Faster R-CNN的predictor head进行了改造,使它能够检测出与PRN的输入相关的目标,包括目标的类别和位置信息。这个框架可以被归结为典型的元学习范式,称为Meta R-CNN。
方法实现
如下图所示是Meta R-CNN的结构,它主要由两部分组成:Faster R-CNN和PRN,Faster R-CNN提供RoI feature,PRN提供类注意向量,两者相结合以检测属于新类的目标。

1. Faster R-CNN
Faster R-CNN主要包括两个阶段:
- 第一个阶段:RPN接收输入图像 x i x_i xi,在 x i x_i xi中生成proposal;
- 第二个阶段:也就是Fast R-CNN,经过RoIAlign从proposal n i ^ \hat{n_i} ni^中提取RoI feature { z i , j ^ } j = 1 n i ^ \lbrace \hat{z_{i,j}} \rbrace ^{\hat{n_i}}_{j=1} {zi,j^}j=1ni^,从而通过predictor head h ( z i , j ^ , θ ) h(\hat{z_{i,j}}, \theta) h(zi,j^,θ)进行分类和定位。
由于Faster R-CNN中的 h ( z i , j ^ , θ ) h(\hat{z_{i,j}}, \theta) h(zi,j^,θ)并不适合进行小样本目标检测,因此本文提出PRN对 h ( z i , j ^ , θ ) h(\hat{z_{i,j}}, \theta) h(zi,j^,θ)重新进行建模,生成新的meta-predictor head h ( ⋅ , D m e t a ; θ ) h(\cdot,D_{meta};\theta) h(⋅,Dmeta;θ)
2. PRN
通过PRN对元数据集 D m e t a D_{meta} Dmeta中的目标进行推断,得到类注意向量 v m e t a v^{meta} vmeta,然后与RoI feature相结合,从而实现channel-wise上的特征选择。假设PRN表示为 v m e t a = f ( D m e t a ; ϕ ) v^{meta}=f(D_{meta};\phi) vmeta=f(Dmeta;ϕ),给定属于图像 x i x_i xi的RoI feature z i , j ^ \hat{z_{i,j}} zi,j^,那么predictor head可表示为:
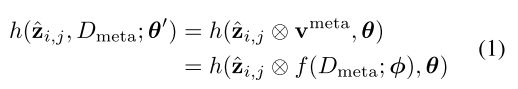
上式说明了如何通过PRN将 h ( ⋅ , θ ) h(\cdot,\theta) h(⋅,θ)重新建模为 h ( ⋅ , D m e t a ; θ ) h(\cdot,D_{meta};\theta) h(⋅,Dmeta;θ),这是一种很灵活的方法,它允许端到端的训练。
假设图像 x i x_i xi是Meta R-CNN的输入,在经过RoIAlign之后,转变为一系列RoI feature { z i , j ^ } j = 1 n i ^ \lbrace \hat{z_{i,j}} \rbrace ^{\hat{n_i}}_{j=1} {zi,j^}j=1ni^,接下来说一下PRN是如何对这些RoI feature进行操作的:
1、推断出类注意向量
PRN f ( D m e t a ; ϕ ) f(D_{meta};\phi) f(Dmeta;ϕ)接收 D m e t a D_{meta} Dmeta中的所有目标作为输入, D m e t a D_{meta} Dmeta中的类属于 C m e t a C_{meta} Cmeta,每个类中有 K K K个目标,每个目标在作为输入时都有4个通道——RGB图像 x x x(有3个通道)和相同空间大小的前景结构标签 s s s( s s s是从目标的bbox中派生的二进制掩码)。假设 C m e t a C_{meta} Cmeta的大小是 m m m,那么PRN就要接收 m K mK mK个4通道的目标作为输入。为了降低计算量,将目标的空间大小标准化为 224 × 224 224 \times 224 224×224。在inference时,输入在经过PRN的第一个卷积层后,然后将输出送入与R-CNN对应的第二层,之后在RoIAlign之前PRN和R-CNN都共享一个backbone,如下图中的蓝圈儿所示:

在PRN中,在共享的backbone之后,特征图通过一个channel-wise soft-attention层以生成目标注意向量(object attentive vector) v v v,总共能得到 m K mK mK个目标注意向量。然后,应用平均池化以获得类注意向量 v c m e t a v_c^{meta} vcmeta, v c m e t a = 1 K ∑ j = 1 K v k ( c ) v_c^{meta}=\frac{1}{K} \sum^K_{j=1}v_k^{(c)} vcmeta=K1∑j=1Kvk(c)。
2、对R-CNN的predictor head进行重新建模
在得到 v c m e t a v_c^{meta} vcmeta之后,PRN利用它们对每个RoI feature进行channel-wise soft-attention。假设图像 x i 的 x_i的 xi的RoI feature矩阵为 Z i ^ = [ z i , 1 ^ ; . . . ; z i , 128 ^ ] \hat{Z_i}=[\hat{z_{i,1}};...;\hat{z_{i,128}}] Zi^=[zi,1^;...;zi,128^], 128 128 128表示RoI的数量。那么PRN就将 Z i ^ \hat{Z_i} Zi^替换为 Z i ^ ⨂ v c m e t a = [ z i , 1 ^ ⨂ v c m e t a ; . . . ; z i , 128 ^ ⨂ v c m e t a ] \hat{Z_i} \bigotimes v_c^{meta}=[\hat{z_{i,1}} \bigotimes v_c^{meta};...;\hat{z_{i,128}} \bigotimes v_c^{meta}] Zi^⨂vcmeta=[zi,1^⨂vcmeta;...;zi,128^⨂vcmeta],然后将变换后的矩阵送入Faster R-CNN中的原始predictor head中。这种修改使得模型能够检测图像 x i x_i xi中的所有属于类别 c c c的目标。由于总的类别数为 m m m,因此每个RoI feature z i , j ^ \hat{z_{i,j}} zi,j^能够生成 m m m个二值检测结果(是否属于这个类)。如果类 c ∗ c^* c∗的置信度最高,那么Meta R-CNN就将 z i , j ^ \hat{z_{i,j}} zi,j^归为类 c ∗ c^* c∗,并且利用分支 z i , j ^ ⨂ v c ∗ m e t a \hat{z_{i,j}} \bigotimes v^{meta}_{c*} zi,j^⨂vc∗meta来定位目标。但是如果最高的置信度仍然比objectness的阈值低,那么这个RoI就会被当作是背景被丢弃。
具体实现
1. mini-batch的构建
Meta R-CNN中的mini-batch共有 m m m个类( C m e t a C_{meta} Cmeta ~ C b a s e ⋃ C n o v e l C_{base} \bigcup C_{novel} Cbase⋃Cnovel),包括 K K K-shot m m m-class的元数据集 D m e t a D_{meta} Dmeta和 m m m-class的训练集 D t r a i n D_{train} Dtrain, D m e t a D_{meta} Dmeta和 D t r a i n D_{train} Dtrain中的类与 C m e t a C_{meta} Cmeta一致。 D t r a i n D_{train} Dtrain中的目标就是Faster R-CNN的输入 x x x中的目标。为了保持类的一致性,选择 C m e t a C_{meta} Cmeta作为图像 x x x所涉及到的类,并且仅使用属于 C m e t a C_{meta} Cmeta的类来推断注意向量(attentive vector)。 因此,如果R-CNN模块接收的输入图像 x x x中包含 m m m个类的目标,那么mini-batch将由 x ( D t r a i n ) x(D_{train}) x(Dtrain)和 m K mK mK个带有结构标签 s s s的图像组成。
2. channel-wise soft-attention层
该层接收从backbone中得到的特征,并在这些特征上进行空间池化,以对齐目标特征,并保持相同的RoI feature大小。然后对这些特征进行element-wise sigmoid以产生注意向量。
3. meta-loss
给定一个RoI feature z i , j ^ \hat{z_{i,j}} zi,j^,为了避免在soft-attention后的预测产生歧义,来自不同类的注意向量应导致 z i , j ^ \hat{z_{i,j}} zi,j^的特征选择效果不同。为了实现这一点,本文提出meta-loss L ( ϕ ) L(\phi) L(ϕ),以使元学习中推断的注意向量多样化。它是通过交叉熵损失实现的,该交叉熵损失促使目标的注意向量落入目标所属的类。这个辅助类型的损失可大大提高Meta R-CNN的性能。
4. RoI元学习
Meta R-CNN的元学习分为两个阶段:
- 在第一个阶段(meta-train),在每次迭代过程中仅考虑使用基类的目标来构建 D m e t a D_{meta} Dmeta和 D t r a i n D_{train} Dtrain,如果一个图像同时包含基类和新类的目标,那么在meta-train中忽略新类的目标。
- 在第二个阶段(meta-test),同时考虑基类和新类的目标。最终的目的是使下式最小化:
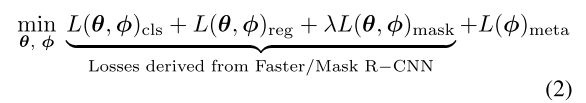
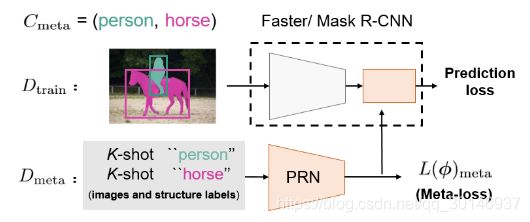
Meta R-CNN的元学习过程如下图所示:
结论
本文主要研究的是小样本目标检测,主要是基于Faster R-CNN,利用的是Faster R-CNN中的RoI feature,在RoI feature上进行元学习。PRN的主要作用是得到类注意向量,它与Faster R-CNN共享RoIAlign之前的backbone,类注意向量与RoI feature进行channel-wise的相乘,然后进行分类与定位。