Zynq Fpga图像处理之AXI接口应用——axi_lite接口使用
摘要
本文介绍了zynq系统中常用的AXI Lite 协议接口的具体使用方法。简述了AXI协议的特点及结构,说明了其实现的基本机制与时序。此外,结合xilinx官方的AXI Lite设计模板,给出了灵活自定义修改的一般方法。最后通过简要的的读写模块对此自定义AXI Lite 模块进行了PS端对PL端的读写测试。测试结果表明,此自定义模块高效实用,读写准确,本文提供的方法可灵活应用到各类zynq设计架构中去。
1.前言
先看一个图像处理工程架构:

图1.1 基于zynq的图像系统架构
图1.1 我们可以看出基于zynq的图像处理往往需要PS系统和PL端的联合工作。他们之间的交互至关重要,往往通过axi接口进行交互,所以xilinx推出了各类具有axi接口的IP供用户调用。比如图中的AXI DMA IP,其自带封装好的axi接口,我们无需编写实现,只要正确配置IP就可以工作。
然而当需要实现PS端读写PL的自定义模块的某些参数,怎么实现呢?
比如,PS控制图像采集模块中的帧频、行频、曝光时间等。这时就需要我们自定义AXI模块,自由的实现PS和PL的读写交互。我们可以自己编写AXI模块,也可以在官方模板中修改。总之这些自定义模块是图像处理中常见的,需要掌握。
2.理论介绍
2.1 特点
AXI 的英文全称是 Advanced eXtensible Interface, 即高级可扩展接口,它是 ARM 公司所提出的 AMBA( Advanced Microcontroller Bus Architecture)协议的一部分。
AXI 协议是一种高性能、高带宽、低延迟的片内总线,具有如下特点:
1、 总线的地址/控制和数据通道是分离的;
2、 支持不对齐的数据传输;
3、支持突发传输, 突发传输过程中只需要首地址;
4、 具有分离的读/写数据通道;
5、 支持显著传输访问和乱序访问;
6、 更加容易进行时序收敛。
AXI4 协议支持以下三种类型的接口:
1、 AXI4: 高性能存储映射接口。
2、 AXI4-Lite:简化版的 AXI4 接口, 用于较少数据量的存储映射通信。
3、 AXI4-Stream: 用于高速数据流传输,非存储映射接口。(直接访问ddr)
AXI4 协议支持突发传输,主要用于处理器访问存储器等需要指定地址的高速数据传输场景。 AXI-Lite为外设提供单个数据传输,主要用于访问一些低速外设中的寄存器。而 AXI-Stream 接口则像 FIFO 一样,数据传输时不需要地址,在主从设备之间直接连续读写数据,主要用于如视频、高速 AD、 PCIe、 DMA 接口等需要高速数据传输的场合。
2.2 工作机制
axi协议实现的是master主机与slave从机间的数据读写。其不仅可以实现单对主从模块间的数据通信,此外其还可以基于内存映射机制实现多个主从模块的自由连接,后者就要用到用来实现路由机制的 Axi_SmartConnect IP核。
AXI4和AXI4-Lite 接口由以下5个部分(通道)组成:
1、Read Address Channel
2、Write Address Channel
3、Read Data Channel
4、Write Data Channel
5、Write Response Channel
数据的读写可以在主机与从机之间同时进行,并且数据位数可以调整。AXI4中的限制是最多256个数据传输的突发事务。AXI4-Lite只允许每个事务进行一次数据传输。

图2.1 主机读通道

图2.2 主机写通道
AXI 总线中的每个通道都包含了一组信息信号,还有一个 VALID 和一个 READY 信号。 VALID 信号由源端( source) 产生,表示当前地址或者数据线上的信息是有效的;而 READY 信号由目的端( destination)产生,则表示已经准备好接收地址、数据以及控制信息。 VALID 和 READY 信号提供了 AXI 总线中的握手机制,如下图所示:
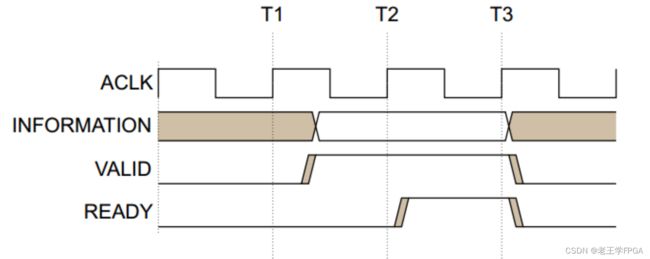
图2.3 握手机制
其中, ACLK 为时钟信号, 在 AXI 协议中,所有的输入信号都在是 ACLK 的上升沿采样,所有的输出信号必须在 ACLK 的上升沿之后才能改变。在 T1 之后, 源端将 VALID 拉高,表明 INFORMATION信号线上传输的是有效的地址、数据或者控制信息。目的端在 T2 之后将 READY 拉高, 表明它已经准备好接收数据,此时源端必须保持 INFORMATION 数据稳定不变, 直到 T3 时刻进行数据传输。需要注意,一次传输中,信息(数据或地址)源端会主动将 VALID 信号置为有效状态,而且,一旦 VALID 拉高,源端必须保持其处于有效状态, 直至目的端拉高ready实现成功握手。
AXI 协议的五个通道都有各自的 VALID/READY 握手信号对,每个通道握手信号对的名称如下图所示:

图2.4 各通道对应的握手信号
当然握手信号只是每个通道所包含的接口信号的一部分,协议的具体接口信号以及实现都很繁杂,具体可以参考《AMBA AXI and ACE Protocol Specification》手册。这里只是介绍怎么使用此接口,将其应用到自己的设计里面。
3.实践应用
简单了解到axi协议的信息后,好像我们一头雾水,还并不能写出axi协议模块。不过vivado里面提供了实现模板。接下来就介绍一下怎么利用vivado工具获得模板或是设计出AXI 接口的IP。
3.1模板生成
本次试验按照以下步骤操作:涉及到的参数或设置根据自己需求调整




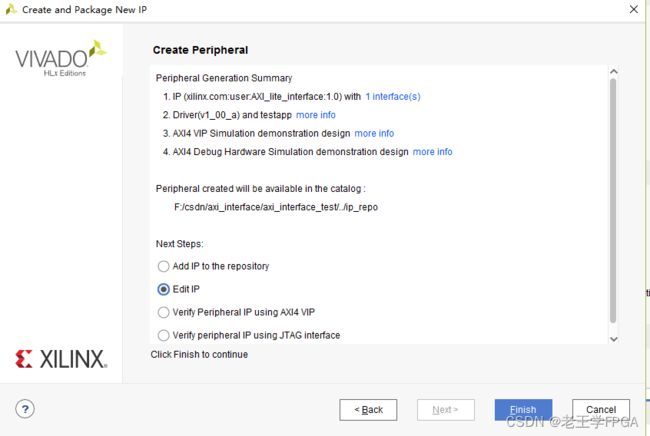
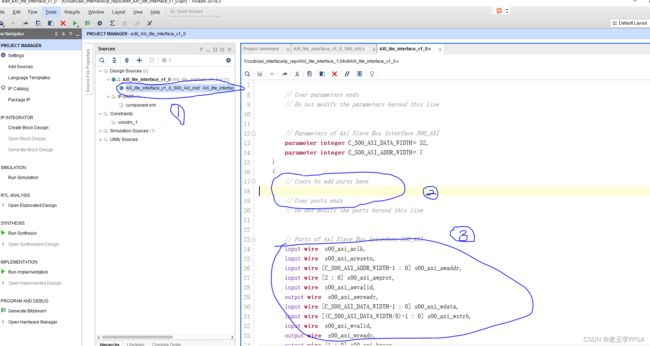
打开1处的源文件,这就是官方提供的axi_lite协议源文件,我们可以看到3处是axi协议相关的端口信号,2处是用户添加自定义端口的区域。
3.2模板修改
本文添加了8个只读寄存器端口和24个写寄存器端口,并将它们连接到内部寄存器上去,
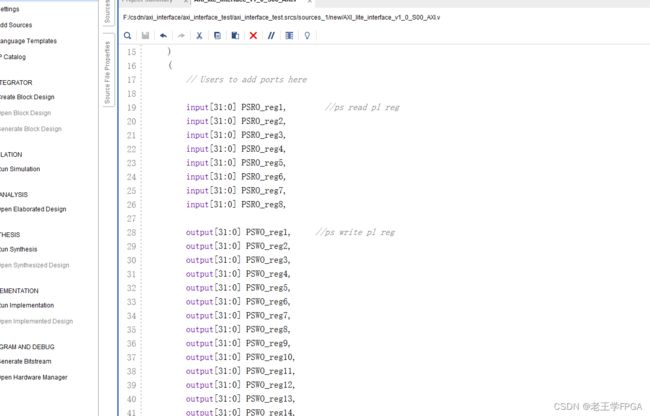
AXI-lite协议的实现分为 ready信号的产生、地址的锁存、寄存器的映射和读写等部分。可以对这几个部分做简单的修改,匹配我们的读写端口。
注释掉写部分的只读寄存器信号。
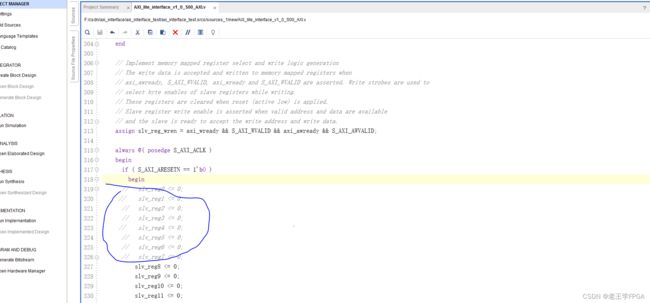

注释掉读部分的只写寄存器信号。
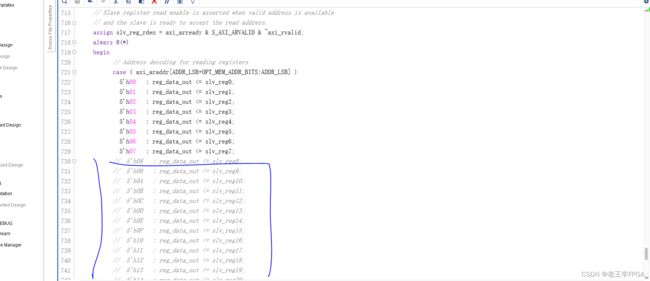
这样我们就完成了axi-lite模块了,将其添加到设计中去,可以完成ps对pl端的读写。
3.3 读写测试
将修改后的axi_lite模块在顶层中例化,并连接至PS端的AXI主机接口,进行读写测试。

由上图可以看出,已经将PS端的AXI_GP0主机端口连接至AXI Interconcect ,并配置成AXI_lite 引出。
在顶层中将次引出端口与修改好的AXI_lite 模块的端口对应连接,则完成例化连接工作,如下面代码所示。
design_1 design_1_i
(.DDR_addr(DDR_addr),
.DDR_ba(DDR_ba),
.DDR_cas_n(DDR_cas_n),
.DDR_ck_n(DDR_ck_n),
.DDR_ck_p(DDR_ck_p),
.DDR_cke(DDR_cke),
.DDR_cs_n(DDR_cs_n),
.DDR_dm(DDR_dm),
.DDR_dq(DDR_dq),
.DDR_dqs_n(DDR_dqs_n),
.DDR_dqs_p(DDR_dqs_p),
.DDR_odt(DDR_odt),
.DDR_ras_n(DDR_ras_n),
.DDR_reset_n(DDR_reset_n),
.DDR_we_n(DDR_we_n),
.FIXED_IO_ddr_vrn(FIXED_IO_ddr_vrn),
.FIXED_IO_ddr_vrp(FIXED_IO_ddr_vrp),
.FIXED_IO_mio(FIXED_IO_mio),
.FIXED_IO_ps_clk(FIXED_IO_ps_clk),
.FIXED_IO_ps_porb(FIXED_IO_ps_porb),
.FIXED_IO_ps_srstb(FIXED_IO_ps_srstb),
.FCLK_CLK(FCLK_CLK),
.peripheral_aresetn_0(rst_n),
.M_AXI_araddr(M_AXI_araddr),
.M_AXI_arprot(M_AXI_arprot),
.M_AXI_arready(M_AXI_arready),
.M_AXI_arvalid(M_AXI_arvalid),
.M_AXI_awaddr(M_AXI_awaddr),
.M_AXI_awprot(M_AXI_awprot),
.M_AXI_awready(M_AXI_awready),
.M_AXI_awvalid(M_AXI_awvalid),
.M_AXI_bready(M_AXI_bready),
.M_AXI_bresp(M_AXI_bresp),
.M_AXI_bvalid(M_AXI_bvalid),
.M_AXI_rdata(M_AXI_rdata),
.M_AXI_rready(M_AXI_rready),
.M_AXI_rresp(M_AXI_rresp),
.M_AXI_rvalid(M_AXI_rvalid),
.M_AXI_wdata(M_AXI_wdata),
.M_AXI_wready(M_AXI_wready),
.M_AXI_wstrb(M_AXI_wstrb),
.M_AXI_wvalid(M_AXI_wvalid));
AXI_lite_interface_v1_0_S00_AXI u_AXI_lite_interface_v1_0_S00_AXI
(
. PSRO_reg1(RO_reg1), //ps read pl reg
. PSRO_reg2(RO_reg2),
. PSRO_reg3(RO_reg3),
. PSRO_reg4(RO_reg4),
. PSRO_reg5(RO_reg5),
. PSRO_reg6(RO_reg6),
. PSRO_reg7(RO_reg7),
. PSRO_reg8(RO_reg8),
. PSWO_reg1(WO_reg1), //ps write pl reg
. PSWO_reg2(WO_reg2),
. PSWO_reg3(WO_reg3),
. PSWO_reg4(WO_reg4),
. PSWO_reg5(WO_reg5),
. PSWO_reg6(WO_reg6),
. PSWO_reg7(WO_reg7),
. PSWO_reg8(WO_reg8),
. PSWO_reg9(WO_reg9),
. PSWO_reg10(WO_reg10),
. PSWO_reg11(WO_reg11),
. PSWO_reg12(WO_reg12),
. PSWO_reg13(WO_reg13),
. PSWO_reg14(WO_reg14),
. PSWO_reg15(WO_reg15),
. PSWO_reg16(WO_reg16),
. PSWO_reg17(WO_reg17),
. PSWO_reg18(WO_reg18),
. PSWO_reg19(WO_reg19),
. PSWO_reg20(WO_reg20),
. PSWO_reg21(WO_reg21),
. PSWO_reg22(WO_reg22),
. PSWO_reg23(WO_reg23),
. PSWO_reg24(WO_reg24),
.S_AXI_ACLK(FCLK_CLK),
.S_AXI_ARESETN(rst_n),
.S_AXI_AWADDR(M_AXI_awaddr),
.S_AXI_AWPROT(M_AXI_awprot),
.S_AXI_AWVALID(M_AXI_awvalid),
.S_AXI_AWREADY(M_AXI_awready),
.S_AXI_WDATA(M_AXI_wdata),
.S_AXI_WSTRB(M_AXI_wstrb),
.S_AXI_WVALID(M_AXI_wvalid),
.S_AXI_WREADY(M_AXI_wready),
.S_AXI_BRESP(M_AXI_bresp),
.S_AXI_BVALID(M_AXI_bvalid),
.S_AXI_BREADY(M_AXI_bready),
.S_AXI_ARADDR(M_AXI_araddr),
.S_AXI_ARPROT(M_AXI_araddr),
.S_AXI_ARVALID(M_AXI_arvalid),
.S_AXI_ARREADY(M_AXI_arready),
.S_AXI_RDATA(M_AXI_rdata),
.S_AXI_RRESP(M_AXI_rresp),
.S_AXI_RVALID(M_AXI_rvalid),
.S_AXI_RREADY(M_AXI_rready)
);然后,综合,实现,生成比特流,建立SDK工程,利用如下代码进行读写测试。
#define reg_base_add XPAR_M_AXI_BASEADDR
#define RO_reg1 reg_base_add+4*0
#define RO_reg2 reg_base_add+4*1
#define RO_reg3 reg_base_add+4*2
#define RO_reg4 reg_base_add+4*3
#define RO_reg5 reg_base_add+4*4
#define RO_reg6 reg_base_add+4*5
#define RO_reg7 reg_base_add+4*6
#define RO_reg8 reg_base_add+4*7
#define WO_reg1 reg_base_add+4*8
#define WO_reg2 reg_base_add+4*9
#define WO_reg3 reg_base_add+4*10
#define WO_reg4 reg_base_add+4*11
#define WO_reg5 reg_base_add+4*12
#define WO_reg6 reg_base_add+4*13
#define WO_reg7 reg_base_add+4*14
#define WO_reg8 reg_base_add+4*15
#define WO_reg9 reg_base_add+4*16
#define WO_reg10 reg_base_add+4*17
#define WO_reg11 reg_base_add+4*18
#define WO_reg12 reg_base_add+4*19
#define WO_reg13 reg_base_add+4*20
#define WO_reg14 reg_base_add+4*21
#define WO_reg15 reg_base_add+4*22
#define WO_reg16 reg_base_add+4*23
#define WO_reg17 reg_base_add+4*24
#define WO_reg18 reg_base_add+4*25
#define WO_reg19 reg_base_add+4*26
#define WO_reg20 reg_base_add+4*27
#define WO_reg21 reg_base_add+4*28
#define WO_reg22 reg_base_add+4*29
#define WO_reg23 reg_base_add+4*30
#define WO_reg24 reg_base_add+4*31
int main(){
int i;
int j;
for (i=8;i<32;i++){
Xil_Out32(reg_base_add+4*i,i);
}
int read_out[8];
sleep(2);
for (j=0;j<8;j++){
read_out[j]= (int)Xil_In32( reg_base_add+4*j);
printf("R0_reg %d is %d\n",j,read_out[j]);
}
}
测试结果如下图所示,符合设计预期

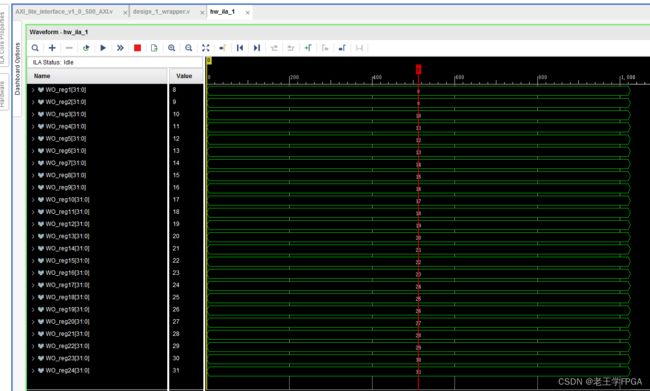
完毕!
本次分享到此结束,感谢阅读,有错误或不足之处,欢迎大家批评指正,一块进步!