【pytorch训练验证自己的分类数据集,全流程】
pytorch训练自己的分类网络(高自由度)全流程
- 项目介绍
- 项目基本介绍
-
- 基本项目管理介绍
- 数据处理与准备
- 直接开训
- eval and infer
- 备注
项目介绍
本人调试代码环境windows,python38,pytorch1.8+cu111;代码内容应该对环境没有强制要求。
PS:windows问题,本人类别名均采用了英文,linux应该不需要这样(还没试)
github地址:https://github.com/jdddp/personal_codes/
项目目前功能:
1.网络可选择,集成了pytorch开源的大部分分类网络,可根据实际需求选择网络类型,想要自己搭网络的同学也可以在model那边自行集成网络类(个人认为从项目角度出发现有pytorch网络够用了),我没有全部继承啊,可以自己去pytorch官网找需要的往里面塞;
2.可控参数清晰,调试所用,目前项目每个epoch会进行一次eval,保存每一次权重,并实时更新最佳权重;
3.管理操作容易,项目结构个人认为十分清晰(迷之自信╮( ̄▽  ̄)╭),想偷懒的同学根据下文提示,只需五行代码(走过路过,不要错过)即可凭借一个分类数据集训练出自己的网络;
4.实时记录log,train和infer分别具有。infer的log优点小设计,下文可见 p(o)q(抄了一波paddleClas)
4.流程基本完整,从训练数据处理到指标计算应有尽有,适合新手入门;
项目基本介绍
基本项目管理介绍
个人建议对所有项目统一管理,本人是在projects文件夹里放置不同分类项目(方便后续迭代追踪)。
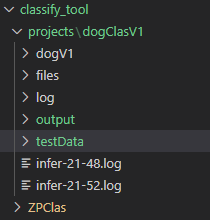
如图,我建了一个{projects}文件夹,dogClasV1是本次调试所用项目,初始状态其目录下只有{dogV1}文件夹,内有10个子文件夹(十分类嘛),其他先不用管。
话不多说直接开干。
数据处理与准备
1.数据格式统一,咱也不知道那些文件夹里面是不是全是图片,而且乱七八糟的啥名字都有,我会对它进行一个重命名以及格式判断。
代码: https://github.com/jdddp/personal_codes/blob/main/tools/common_use/image_format.py
执行脚本:
1、
python path/to/image_format.py format_folders path/to/dogV1 path/to/dogV1_format
图上所示{dogV1}是我处理过的
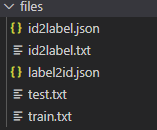
2.训练文件准备,准备一些id和label的映射关系文件,以及训练所需train.txt和test.txt.
代码:
ZPClas/tools/prepare_files.py
执行脚本:
2、
python path/to/prepare_files makeMapFileRandom path/to/dataset path/to/files
3、
python path/to/prepares_files makeTrainFiles path/to/dataset path/to/files
这边两个入参就是图上所示{dogV1}以及{files}
结果如下图:
直接开训
这边直接提供了一个shell脚本(4、train.sh,供参考),把第一行搞到终端执行就完了(记得换自己的文件目录)
可控参数:model_name(选择时可参见models目录),batchsize,分类类别数,模式(train or test)。
这边训练过程调试方便是每1个epoch(100个)会保存一个权重同时,eval1次(实际项目不需要);没有集成到args里面(偷波懒),可以在函数入参里改一改,在tools/train_model.py 最后三个入参(num_epochs,save_interval,eval_interval)就是了。
训练结束就出现了图一几个文件夹,log存放训练日志(按月日时分命名),output下分{model_name}存放所得权重。
eval and infer
eval没有单独写出来噢。我选择直接根据infer结果计算eval指标。
1.为了方便计算,会对验证集做个处理:
5、
脚本: ZPClas/tools/prepare_files.py
执行脚本: python path/to/prepare_files makeEvalData path/to/dataset path/to/project
入参也就是{dogV1}和{dogClasV1}
这一步完了就出现了图一testData文件夹
用它作为datasetPath去infer,参见6、infer.sh第一行。
PS:实际使用时也可以是单张图片,代码里面有加自动判断
输出会出现在终端和图一所示{infer-时-分.log},可控参数:infer的batch_size以及较高的概率的量(也就是score_list的长度),这边抄了一手paddleClas
每行一个list,长度为batch_size,list元素为字典
[{“score_list”:[score,score,score],
“label_list”:[labelA,labelB,labelC],
“imgPath”:顾名思义}, {…} ,{…}]
这边score_list由高到低已排序,索引位置对应于label_list
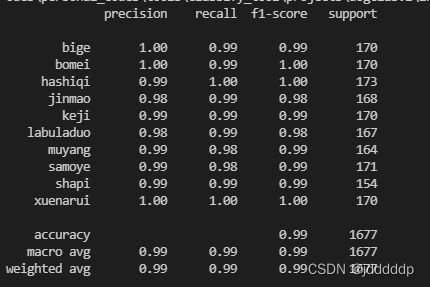
2.指标计算
脚本:
eval_tools/eval.py
执行脚本:
python path/to/eval/py calcu_pre_rec path/to/files/label2id.json path/to/{infer-时-分.log}
结果展示:
OK,就写到这里了,后面有时间可能会考虑集成一些loss(目前是随便搞得交叉熵),optim进去。然后eval可能会添加一些画图啥的方便分析。有需要的同学自己先搞吧,搞好让我crtl c/v一波 <※
备注
有一些没处理的问题:
1、第一步格式化的时候只是简单根据后缀做了个判断,有兴趣的可以去自己找一下怎么读写,就不用局限于三种图片格式了
2、没有加多卡计算,设备有限( ̄(工) ̄),懒得弄了
3、个人感觉代码模块化还挺清晰,可以自己在这个基础上加东西(又来了),比如说dataset里面可以加一些小策略缓解一下数据不平衡,transform.py里面可以多搞一些pytorch有的,或者自己写点流行的,方便训练时调用
数了一下,是六行。。。
溜了溜了,搞检测去了