深度学习EMA的注意事项
目录
EMA介绍
概念
弥补不足:初始数据积累不足的情况
深度学习训练中的作用
实现
典型步骤
一个EMA影子变量的例子
进一步接近真实情景,让w1变动
例2:global_step的trainable设置
最后,怎么用影子变量来测试?
模拟训练与存储模型
错误的模型读取方式
正确的模型读取方式
补一发手写的映射通用写法
EMA介绍
概念
滑动平均exponential moving average,指数加权平均。
默认情况:
变量v在t时刻的取值
v_t = Theta_t
EMA:
v_t = Beta * v_t-1 + (1-Beta)*Theta_t
公式中如果Beta=0,就完全等于前者。
看公式,直觉理解也很简单:旧的平均值乘以一个大系数维持稳定,新的数值乘以一个小的系数减少影响,总的来说就是类似Momentum的一个维持稳定的机制,对于新数值,比Momentum还要“打压”。
如果Beta取一个典型值,如0.9,其实具体含义就是,
vt~= 1/(1-Beta)个数据的平均值
约等于:在此之前十个数据的平均值!(没这么整,每个新加的都是0.1的系数,旧的还有0.1的衰减)
1/(1-Beta)|Beta=0.9=10
1/(1-Beta)|Beta=0.98=50
不过,什么叫新和旧?怎么理解?新的Theta怎么得来的?(其实是有两套东西,拿维护变量w举例,w是正常更新的,而EMA是独立维护的,所以整个流程就是,wt-1更新到wt,取新的wt来更新EMA,更具体的,是你调用ema的apply的时候取一次,理论上w本身不一定发生了变动,不过一般都是同步的,见例子。)
关于EMA到底是维护变量还是数据集:其实实际使用中,EMA主要还是维护W和b,举例说明典型的使用场景。
直觉上,有点momentum的意思,不过momentum是梯度下降用的,滑动平均主要针对变量。
也可以用来平滑数据,减少噪音和异常。 和Momentum的相似处,都有惯性,如果Beta太大,整个曲线会有滞后性,和真正的数据产生偏差。。 和Adagrad的一个类似点:不过多占用额外内存,只维护一个值就好,不用真正把数据都调出来。
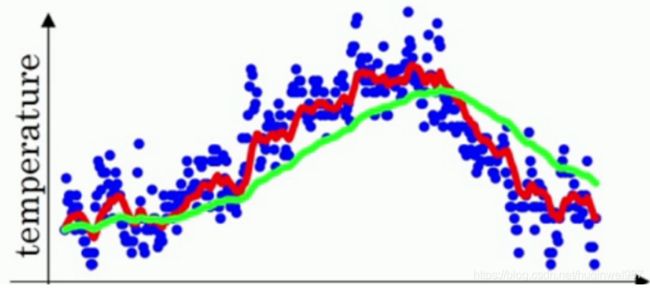
下图是温度数据(蓝点)和拟合曲线(红线)、EMA曲线(绿线),可以看到绿线有明显滞后性,这也算一个缺点,下边会提到补救措施。(不过这个图并不一定算深度学习的一个环节,只是一个demo,深度学习训练中ema不是干这个的。)
弥补不足:初始数据积累不足的情况
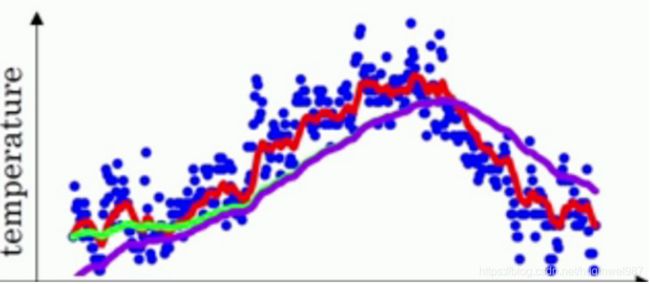
这是global_step参数的存在意义(global_step并不是ema更新的驱动力,只是一种弥补手段)
因为这个惯性的存在,所以就有了滞后性,所以就需要修正。
图中紫线,甚至升高都有滞后性,因为之前没有数据累积。但是物理惯性仍然大(Beta高),所以有一个维持“0"的趋势在,所以升不起来。
这个公式二选一:
Beta = min(decay,(1+num_updates)/(10+num_updates))
前期后者小,后期前者小,(极端来说,后者是从1/10到1/1的趋势。)
所以,decay=0.98,updates=5时,6/15=0.4,选择0.4而不选择0.98.。。。
深度学习训练中的作用
说白了,TF中,给W和b使用EMA,就是防止训练过程遇到异常数据或者随机跳跃(毕竟是随机批量,数据不确定)影响训练效果的,让W和b维持相对稳定。
影子变量,说是影子,不光是惯性和尾随的含义,他是独立的个体。测试的时候使用的就是影子变量,取代变量。理解这个概念很重要,包括BatchNormalization等,如果不理解,很可能会用错。
所以,感觉这个东西在数据量小或者数据不稳定或者batch_size小的情况下尤其有用。
每个iteration使用全部数据的梯度下降肯定是不太需要EMA了,除非learning_rate大,不然方向不可能有偏差(所以,根据learning_rate的不同,也算有点用),但是实际上mini-batch更多吧,所以EMA有使用的必要。
实现
典型步骤
在TensorFlow中,ExponentialMovingAverage()可以传入两个参数:衰减率(decay)和数据的迭代次数(step),这里的decay和step分别对应我们的β和num_updates,所以在实现滑动平均模型的时候,步骤如下:
1、定义训练迭代次数step
2、然后定义滑动平均的类,传衰减率和step给类。
3、给这个类指定需要用到滑动平均模型的变量(w和b,也就是所有可训练变量tf.trainable_variables())
4、利用依赖项执行训练和滑动操作,把(影子)变量变为指数加权平均值
-
# 定义训练的轮数,False避免这个变量被计算滑动平均值
-
global_step = tf.Variable(
0, trainable=
False)
-
-
# 给定滑动衰减率和训练轮数,初始化滑动平均类
-
# global_step可以加快训练前期的迭代速度,弥补惯性带来的滞后
-
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,
-
global_step)
-
# 用tf.trainable_variable()获取所有可以训练的变量列表,全部指定为使用滑动平均模型
-
# global_step虽然不在计算图中,但是是会被ema处理到的,一定要设False
-
variables_averages_op = variable_averages.apply(tf.trainable_variables())
-
-
# 绑定操作:反向传播更新参数之后,再更新每一个参数的滑动平均值
-
# 用下面的代码可以用一次sess.run(train_op)完成这两个操作。
-
with tf.control_dependencies([train_step, variables_averages_op]):
-
train_op = tf.no_op(name=
"train")
一个EMA影子变量的例子
为了更生动,手动模拟了多次训练和滑动,给w1赋值相当于训练操作,执行apply相当于执行滑动操作。
ema.average(w1)是提取w1的影子变量数值的正确方法。
-
import tensorflow
as tf
-
w1 = tf.Variable(
0, dtype=tf.float32)
-
global_step = tf.Variable(
0,dtype=tf.float32,trainable=
False)
-
MOVING_AVERAGE_DECAY =
0.99
-
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
-
ema_op = ema.apply([w1])
#参数列表,本例可以手动指定w1.
-
#w1直接模拟N次变动,从1变10,让ema追w1的值
-
with tf.Session()
as sess:
-
init = tf.global_variables_initializer()
-
sess.run(init)
-
print(
'init w:',sess.run([w1,ema.average(w1)]))
#用.average获得w1的滑动平均,也就是影子吧。
-
sess.run(tf.assign(w1,
1))
#手动修改w1的值
-
sess.run(tf.assign(global_step,
1))
-
sess.run(ema_op)
#滑动一次。
-
print(
'after an ema op')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
sess.run(ema_op)
#滑动一次。
-
print(
'after an ema op')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
#global_step不变动,不影响ema更新
-
sess.run(ema_op)
#滑动一次。
-
print(
'after an ema op')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
print(
'assign global_step:')
-
#假装进行了100轮迭代,w1变成10(其实ema没有更新中间那一百步)
-
sess.run(tf.assign(global_step,
100))
-
sess.run(tf.assign(w1,
10))
-
sess.run(ema_op)
-
print(
'after 100 ema ops')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
sess.run(ema_op)
-
-
#再拿同样的w=10多更新几次影子,让影子逼近w1
-
for i
in range(
100):
-
sess.run(ema_op)
-
if i %
10 ==
0:
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
init w: [
0.0,
0.0]
-
after an ema op
-
w: [
1.0,
0.8181818]
-
after an ema op
-
w: [
1.0,
0.96694213]
-
after an ema op
-
w: [
1.0,
0.99398947]
-
assign global_step:
-
after
100 ema ops
-
w: [
10.0,
1.7308447]
-
w: [
10.0,
3.0286236]
-
w: [
10.0,
7.031032]
-
w: [
10.0,
8.735577]
-
w: [
10.0,
9.461507]
-
w: [
10.0,
9.770666]
-
w: [
10.0,
9.90233]
-
w: [
10.0,
9.958405]
-
w: [
10.0,
9.982285]
-
w: [
10.0,
9.9924555]
-
w: [
10.0,
9.996786]
进一步接近真实情景,让w1变动
-
#同样的例子,修改一下,让w1动态变化,ema在后边追。
-
import tensorflow
as tf
-
w1 = tf.Variable(
0, dtype=tf.float32)
-
global_step = tf.Variable(
0,dtype=tf.float32,trainable=
False)
#不会被ema做平均
-
MOVING_AVERAGE_DECAY =
0.99
-
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
-
-
ema_op = ema.apply(tf.trainable_variables())
-
with tf.Session()
as sess:
-
init = tf.global_variables_initializer()
-
sess.run(init)
-
print(
'init w:',sess.run([w1,ema.average(w1)]))
#用.average获得w1的滑动平均,也就是影子吧。
-
sess.run(tf.assign(w1,
1))
#手动修改w1的值
-
sess.run(tf.assign(global_step,
1))
-
sess.run(ema_op)
#滑动一次。
-
-
print(
'after an ema op')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
#假装进行了100轮迭代,w1变成10(其实ema没有更新中间那一百步)
-
sess.run(tf.assign(global_step,
100))
-
sess.run(tf.assign(w1,
10))
-
sess.run(ema_op)
-
print(
'after 100 ema ops')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
sess.run(ema_op)
-
-
#再拿同样的w=10多更新几次影子,让影子逼近w1,同时,w1也变化。
-
for i
in range(
100):
-
sess.run(tf.assign_add(w1,
1))
-
sess.run(ema_op)
-
if i %
10 ==
0:
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
print(
'global_step:',sess.run(global_step))
-
# print('global_step ema:',sess.run([global_step,ema.average(global_step)]))#global_step的ema
-
init w: [
0.0,
0.0]
-
after an ema op
-
w: [
1.0,
0.8181818]
-
after
100 ema ops
-
w: [
10.0,
1.5694213]
-
w: [
11.0,
2.9743524]
-
global_step:
100.0
-
w: [
21.0,
11.1391325]
-
global_step:
100.0
-
w: [
31.0,
20.35755]
-
global_step:
100.0
-
w: [
41.0,
30.024689]
-
global_step:
100.0
-
w: [
51.0,
39.882935]
-
global_step:
100.0
-
w: [
61.0,
49.822563]
-
global_step:
100.0
-
w: [
71.0,
59.79685]
-
global_step:
100.0
-
w: [
81.0,
69.7859]
-
global_step:
100.0
-
w: [
91.0,
79.78124]
-
global_step:
100.0
-
w: [
101.0,
89.77926]
-
global_step:
100.0
例2:global_step的trainable设置
如果你不限制global_step为不可训练,并且ema直接获取所有可训练变量,global_step的ema就会变,不过不影响global_step变量自身的值(但是如果你还打算restore,那就可能有影响了,所以这也是个坑,参数列表指定)
-
import tensorflow
as tf
-
-
w1 = tf.Variable(
0, dtype=tf.float32)
-
global_step = tf.Variable(
0,dtype=tf.float32,trainable=
True)
#会被ema做平均。
-
MOVING_AVERAGE_DECAY =
0.99
-
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
-
# ema_op = ema.apply([w1])#参数列表,本例可以手动指定w1.
-
ema_op = ema.apply(tf.trainable_variables())
#注意这种情况,这种情况应该就会影响global_step了,所以得设False
-
with tf.Session()
as sess:
-
init = tf.global_variables_initializer()
-
sess.run(init)
-
print(
'init w:',sess.run([w1,ema.average(w1)]))
#用.average获得w1的滑动平均,也就是影子吧。
-
sess.run(tf.assign(w1,
1))
#手动修改w1的值
-
sess.run(tf.assign(global_step,
1))
-
sess.run(ema_op)
#滑动一次。
-
-
print(
'after an ema op')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
#假装进行了100轮迭代,w1变成10(其实ema没有更新中间那一百步)
-
sess.run(tf.assign(global_step,
100))
-
sess.run(tf.assign(w1,
10))
-
sess.run(ema_op)
-
print(
'after 100 ema ops')
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
sess.run(ema_op)
-
-
#再拿同样的w=10多更新几次影子,让影子逼近w1,同时,w1也变化。
-
for i
in range(
100):
-
sess.run(tf.assign_add(w1,
1))
-
sess.run(ema_op)
-
if i %
10 ==
0:
-
print(
'w:',sess.run([w1,ema.average(w1)]))
-
print(
'global_step and ema:',sess.run([global_step,ema.average(global_step)]))
-
init w: [
0.0,
0.0]
-
after an ema op
-
w: [
1.0,
0.8181818]
-
after
100 ema ops
-
w: [
10.0,
1.5694213]
-
w: [
11.0,
2.9743524]
-
global_step
and ema: [
100.0,
23.225294]
-
w: [
21.0,
11.1391325]
-
global_step
and ema: [
100.0,
67.30321]
-
w: [
31.0,
20.35755]
-
global_step
and ema: [
100.0,
86.075096]
-
w: [
41.0,
30.024689]
-
global_step
and ema: [
100.0,
94.069664]
-
w: [
51.0,
39.882935]
-
global_step
and ema: [
100.0,
97.47439]
-
w: [
61.0,
49.822563]
-
global_step
and ema: [
100.0,
98.924385]
-
w: [
71.0,
59.79685]
-
global_step
and ema: [
100.0,
99.541916]
-
w: [
81.0,
69.7859]
-
global_step
and ema: [
100.0,
99.80492]
-
w: [
91.0,
79.78124]
-
global_step
and ema: [
100.0,
99.916916]
-
w: [
101.0,
89.77926]
-
global_step
and ema: [
100.0,
99.96461]
最后,怎么用影子变量来测试?
我因为其他问题,去测了一把,其实变量本身,还是按变量来恢复的,影子怎么用上?
现在想看ema的值,用ema.average(w1)就可以,然后,怎么恢复他们?怎么把他们恢复到模型上?
restore自动做了吗?其实是用映射主动替换的!
不指定var_list的时候,原来的'weights'仍然对应'weights',如果指定了var_list映射(var_list有list和dict两种模式),原来的'weights/ema'会替代'weights',因为传进去的是个dict,手动的映射,所以说,无论什么变量,模型改过命名也不是一定就废弃了,还是可以手动映射来对上的,只不过比较繁琐,我这里就不弄了。
模拟训练与存储模型
-
import tensorflow
as tf
-
#这个变量为了观察变化,数值越大,惯性越大,相比实际的W,增长越小越缓慢
-
#实际应该使用0.9、0.99、0.999等
-
MOVING_AVERAGE_DECAY =
0.6
-
#0.1的衰减
-
# [array([ 10.49953651, 20.49953651, 30.49953651], dtype=float32),
-
# array([ 10.38866425, 20.38866425, 30.38866425], dtype=float32)]
-
#0.6的衰减
-
# [array([ 10.49953651, 20.49953651, 30.49953651], dtype=float32),
-
# array([ 10.34986782, 20.34986877, 30.34986877], dtype=float32)]
-
-
-
global_step = tf.Variable(
0, trainable=
False,name=
'global_step')
-
with tf.variable_scope(
"my_scope"):
-
W = tf.Variable([
10,
20,
30], dtype = tf.float32, name=
'weights')
-
-
y = tf.constant([
20,
30,
40],tf.float32)
-
loss = tf.reduce_mean(tf.square(W-y))
-
train_step = tf.train.AdamOptimizer(
0.1).minimize(loss,global_step=global_step)
-
-
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
#提前把EMA存起来
-
# ema_op = ema.apply(tf.trainable_variables())
-
ema_op = ema.apply([W])
-
-
with tf.control_dependencies([train_step, ema_op]):
-
train_op = tf.no_op(name=
'train')
-
-
saver = tf.train.Saver()
-
with tf.Session()
as sess:
-
tf.global_variables_initializer().run()
-
print(
'init,before assign:',sess.run(W))
-
for i
in range(
5):
-
sess.run(train_op)
-
print(
'global_step is ',sess.run(global_step))
-
# sess.run(train_step)
-
# sess.run(ema_op)
-
print(
'W and ema.average:',sess.run([W,ema.average(W)]))
-
-
save_path = saver.save(sess,
"my_net/save_net_3.ckpt")
-
print(
'Save to path:',save_path)
-
init,before assign: [
10.
20.
30.]
-
global_step
is
1
-
W
and ema.average: [
array([
10.1,
20.1,
30.1], dtype=float32),
array([
10.,
20.,
30.], dtype=float32)]
-
global_step
is
2
-
W
and ema.average: [
array([
10.199972,
20.199972,
30.199972], dtype=float32),
array([
10.081819,
20.081818,
30.081818], dtype=float32)]
-
global_step
is
3
-
W
and ema.average: [
array([
10.299898,
20.299898,
30.299898], dtype=float32),
array([
10.170434,
20.170433,
30.170433], dtype=float32)]
-
global_step
is
4
-
W
and ema.average: [
array([
10.399759,
20.39976 ,
30.39976 ], dtype=float32),
array([
10.260063,
20.260063,
30.260063], dtype=float32)]
-
global_step
is
5
-
W
and ema.average: [
array([
10.4995365,
20.499537 ,
30.499537 ], dtype=float32),
array([
10.349868,
20.349869,
30.349869], dtype=float32)]
-
Save
to path: my_net/save_net_3.ckpt
错误的模型读取方式
-
#如果不指定var_list,普通的W还是按普通的W去提取。
-
#存[array([ 10.49953651, 20.49953651, 30.49953651], dtype=float32), array([ 10.34986782, 20.34986877, 30.34986877]
-
#取[ 10.49953651 20.49953651 30.49953651]
-
import tensorflow
as tf
-
import numpy
as np
-
-
MOVING_AVERAGE_DECAY =
0.6
#0.99
-
global_step = tf.Variable(
0, trainable=
False,name=
'global_step')
-
-
with tf.variable_scope(
"my_scope"):
-
W2 = tf.Variable([
0,
0,
0], dtype=tf.float32,name=
'weights')
-
-
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY)
-
ema_restore = ema.variables_to_restore()
##w和w的ema,还有global,只能算指定了ema的绑定关系,不是只有ema,其实不影响变量自身的读取
-
-
# loader = tf.train.Saver(ema_restore)
-
loader = tf.train.Saver()
-
load_path =
"my_net/save_net_3.ckpt"
-
with tf.Session()
as sess:
-
tf.global_variables_initializer().run()
-
-
loader.restore(sess, load_path)
-
-
print(
"W2:",sess.run(W2))
-
# print("W2:",sess.run([W2,ema.average(W2)]))
-
# print('ema W is :',sess.run(ema_val))
-
print(sess.run(ema_restore[
'my_scope/weights/ExponentialMovingAverage']))
-
print(
'after run restore')
-
print(tf.global_variables())
-
使用了原始变量而非ema变量,ema等于白做了。
-
INFO:tensorflow:Restoring parameters from my_net/save_net_3.ckpt
-
W2: [10.4995365 20.499537 30.499537 ]
-
[10.4995365 20.499537 30.499537 ]
-
after run restore
-
[
<tf.Variable 'global_step:0' shape=() dtype=int32_ref>,
<tf.Variable 'my_scope/weights:0' shape=(3,) dtype=float32_ref>]
正确的模型读取方式
这里有人没看懂,注意那句ema_restore = ema.variables_to_restore()
这是生成一个dict,让ema替代原生weights变量,下边的手写映射的例子可以解释
-
<class 'dict'>: {
-
'my_scope/weights/ExponentialMovingAverage':
<tf.Variable 'my_scope/weights:0' shape=(3,) dtype=float32_ref>,
-
'global_step':
<tf.Variable 'global_step:0' shape=() dtype=int32_ref>}
-
#如果指定var_list,普通的W按ema去提取并完成替换。。
-
#存[array([ 10.49953651, 20.49953651, 30.49953651], dtype=float32), array([ 10.34986782, 20.34986877, 30.34986877]
-
#取[ 10.34986782 20.34986877 30.34986877]
-
import tensorflow
as tf
-
import numpy
as np
-
-
MOVING_AVERAGE_DECAY =
0.6
#0.99
-
global_step = tf.Variable(
0, trainable=
False,name=
'global_step')
-
-
with tf.variable_scope(
"my_scope"):
-
W2 = tf.Variable([
0,
0,
0], dtype=tf.float32,name=
'weights')
-
-
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY)
-
ema_restore = ema.variables_to_restore()
##w和w的ema,还有global,只能算指定了ema的绑定关系,不是只有ema,其实不影响变量自身的读取
-
-
print(
'ema_restore:',ema_restore)
#这是一个映射,让EMA对应普通变量
-
-
loader = tf.train.Saver(ema_restore)
-
load_path =
"my_net/save_net_3.ckpt"
-
with tf.Session()
as sess:
-
tf.global_variables_initializer().run()
-
-
loader.restore(sess, load_path)
-
-
print(
"W2:",sess.run(W2))
-
# print("W2:",sess.run([W2,ema.average(W2)]))
-
# print('ema W is :',sess.run(ema_val))
-
print(sess.run(ema_restore[
'my_scope/weights/ExponentialMovingAverage']))
-
print(
'after run restore')
-
print(tf.global_variables())
-
正确的使用了EMA维护的变量
-
ema_restore: {'my_scope/weights/ExponentialMovingAverage':
<tf.Variable 'my_scope/weights:0' shape=(3,) dtype=float32_ref>, 'global_step':
<tf.Variable 'global_step:0' shape=() dtype=int32_ref>}
-
INFO:tensorflow:Restoring parameters from my_net/save_net_3.ckpt
-
W2: [10.349868 20.349869 30.349869]
-
[10.349868 20.349869 30.349869]
-
after run restore
-
[
<tf.Variable 'global_step:0' shape=() dtype=int32_ref>,
<tf.Variable 'my_scope/weights:0' shape=(3,) dtype=float32_ref>]
补一发手写的映射通用写法
{'var_name':tensor}
通过手动指定,颠倒两个变量的读取和赋值
tf.train.Saver的var_list其实支持两种写法,list和dict,dict中的key是文件中的变量名
-
import tensorflow
as tf
-
import numpy
as np
-
-
with tf.variable_scope(
"my_scope"):
-
W2 = tf.Variable([
1,
2,
3], dtype=tf.float32,name=
'weights')
-
b2 = tf.Variable([
2,
3,
4], dtype=tf.float32,name=
'biases')
-
-
saver = tf.train.Saver()
-
load_path =
"my_net/save_net_4.ckpt"
-
with tf.Session()
as sess:
-
tf.global_variables_initializer().run()
-
saver.save(sess, load_path)
-
print(
"W2:",sess.run(W2))
-
print(
"b2:",sess.run(b2))
这里根据上边代码,手动写了一个dict映射
-
import tensorflow
as tf
-
import numpy
as np
-
-
with tf.variable_scope(
"my_scope"):
#颠倒一下
-
b2 = tf.Variable([
0,
0,
0], dtype=tf.float32,name=
'biases')
#看name,这里本来也是b2和biases对应的
-
W2 = tf.Variable([
0,
0,
0], dtype=tf.float32,name=
'weightss')
#不同名也无所谓
-
W3 = tf.Variable([
0,
0,
0], dtype=tf.float32,name=
'weightsss')
-
-
#另外,也不能够一个变量恢复到两个tensor,dict中key冲突覆盖了
-
restore_map = {
'my_scope/weights':b2,
'my_scope/biases':W2
#,'my_scope/biases':W3
-
}
-
loader = tf.train.Saver(restore_map)
-
load_path =
"my_net/save_net_4.ckpt"
-
with tf.Session()
as sess:
-
tf.global_variables_initializer().run()
-
-
loader.restore(sess, load_path)
-
print(
"W2:",sess.run(W2))
-
print(
"b2:",sess.run(b2))
-
print(
"W3:",sess.run(W3))