- PyTorch & TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)
阿牛的药铺
算法移植部署pytorchtensorflowfpga开发
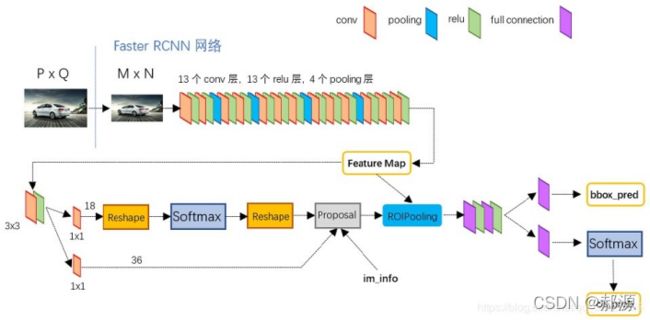
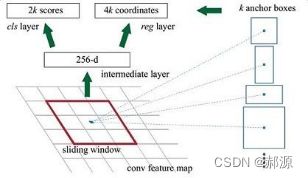
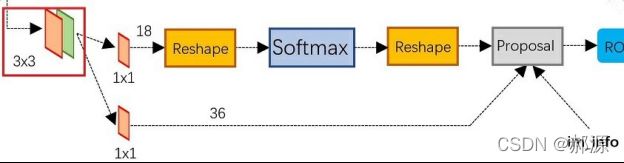
PyTorch&TensorFlow速成复习:从基础语法到模型部署实战(附FPGA移植衔接)引言:为什么算法移植工程师必须掌握框架基础?针对光学类产品算法FPGA移植岗位需求(如可见光/红外图像处理),深度学习框架是算法落地的"桥梁"——既要用PyTorch/TensorFlow验证算法可行性,又要将训练好的模型(如CNN、目标检测)转换为FPGA可部署的格式(ONNX、TFLite)。本文采用"
- 霍夫变换(Hough Transform)算法原来详解和纯C++代码实现以及OpenCV中的使用示例
点云SLAM
算法图形图像处理算法opencv图像处理与计算机视觉算法直线提取检测目标检测霍夫变换算法
霍夫变换(HoughTransform)是一种经典的图像处理与计算机视觉算法,广泛用于检测图像中的几何形状,例如直线、圆、椭圆等。其核心思想是将图像空间中的“点”映射到参数空间中的“曲线”,从而将形状检测问题转化为参数空间中的峰值检测问题。一、霍夫变换基本思想输入:边缘图像(如经过Canny边缘检测)输出:一组满足几何模型的形状(如直线、圆)关键思想:图像空间中的一个点→参数空间中的一个曲线参数空
- 【目标检测】机场内部目标检测数据集4106张YOLO+VOC格式
数据集格式:VOC格式+YOLO格式压缩包内含:3个文件夹,分别存储图片、xml、txt文件JPEGImages文件夹中jpg图片总计:4106Annotations文件夹中xml文件总计:4106labels文件夹中txt文件总计:4106标签种类数:7标签名称:["Ground_vehicles","Horizontal_sign","Runaway_limit","Taxiway","Ver
- 传统检测响应慢?陌讯多模态引擎提速90+FPS实战
2501_92473147
算法计算机视觉目标检测
开篇痛点:实时目标检测在安防监控中的核心挑战在安防监控领域,实时目标检测是保障公共安全的关键技术。然而,传统算法如YOLOv5或开源框架MMDetection常面临两大痛点:误报率高(复杂光照或遮挡场景下检测不稳定)和响应延迟(高分辨率视频流处理FPS低于30)。实测数据显示,城市交通监控系统误报率达15%,导致安保资源浪费;客户反馈表明,延迟超100ms时,目标跟踪可能失效。这些问题源于算法泛化
- 深度学习模型表征提取全解析
ZhangJiQun&MXP
教学2024大模型以及算力2021AIpython深度学习人工智能pythonembedding语言模型
模型内部进行表征提取的方法在自然语言处理(NLP)中,“表征(Representation)”指将文本(词、短语、句子、文档等)转化为计算机可理解的数值形式(如向量、矩阵),核心目标是捕捉语言的语义、语法、上下文依赖等信息。自然语言表征技术可按“静态/动态”“有无上下文”“是否融入知识”等维度划分一、传统静态表征(无上下文,词级为主)这类方法为每个词分配固定向量,不考虑其在具体语境中的含义(无法解
- 【Qualcomm】高通SNPE框架简介、下载与使用
Jackilina_Stone
人工智能QualcommSNPE
目录一高通SNPE框架1SNPE简介2QNN与SNPE3Capabilities4工作流程二SNPE的安装与使用1下载2Setup3SNPE的使用概述一高通SNPE框架1SNPE简介SNPE(SnapdragonNeuralProcessingEngine),是高通公司推出的面向移动端和物联网设备的深度学习推理框架。SNPE提供了一套完整的深度学习推理框架,能够支持多种深度学习模型,包括Pytor
- 目标检测(object detection)
加油吧zkf
目标检测目标检测人工智能计算机视觉
目标检测作为计算机视觉的核心技术,在自动驾驶、安防监控、医疗影像等领域发挥着不可替代的作用。本文将系统讲解目标检测的概念、原理、主流模型、常见数据集及应用场景,帮助读者构建对这一技术的完整认知。一、目标检测的核心概念目标检测(ObjectDetection)是指在图像或视频中自动定位并识别出所有感兴趣的目标的技术。它需要解决两个核心问题:分类(Classification):确定图像中每个目标的类
- 深度学习篇---昇腾NPU&CANN 工具包
Atticus-Orion
上位机知识篇图像处理篇深度学习篇深度学习人工智能NPU昇腾CANN
介绍昇腾NPU是华为推出的神经网络处理器,具有强大的AI计算能力,而CANN工具包则是面向AI场景的异构计算架构,用于发挥昇腾NPU的性能优势。以下是详细介绍:昇腾NPU架构设计:采用达芬奇架构,是一个片上系统,主要由特制的计算单元、大容量的存储单元和相应的控制单元组成。集成了多个CPU核心,包括控制CPU和AICPU,前者用于控制处理器整体运行,后者承担非矩阵类复杂计算。此外,还拥有AICore
- 深度学习图像分类数据集—桃子识别分类
AI街潜水的八角
深度学习图像数据集深度学习分类人工智能
该数据集为图像分类数据集,适用于ResNet、VGG等卷积神经网络,SENet、CBAM等注意力机制相关算法,VisionTransformer等Transformer相关算法。数据集信息介绍:桃子识别分类:['B1','M2','R0','S3']训练数据集总共有6637张图片,每个文件夹单独放一种数据各子文件夹图片统计:·B1:1601张图片·M2:1800张图片·R0:1601张图片·S3:
- 微算法科技的前沿探索:量子机器学习算法在视觉任务中的革新应用
MicroTech2025
量子计算算法
在信息技术飞速发展的今天,计算机视觉作为人工智能领域的重要分支,正逐步渗透到我们生活的方方面面。从自动驾驶到人脸识别,从医疗影像分析到安防监控,计算机视觉技术展现了巨大的应用潜力。然而,随着视觉任务复杂度的不断提升,传统机器学习算法在处理大规模、高维度数据时遇到了计算瓶颈。在此背景下,量子计算作为一种颠覆性的计算模式,以其独特的并行处理能力和指数级增长的计算空间,为解决这一难题提供了新的思路。微算
- 目标检测中的NMS算法详解
好的,我们来详细解释一下目标检测中非极大值抑制(Non-MaximumSuppression,NMS)的相关概念和计算过程。1.为什么需要NMS?问题:目标检测模型(如FasterR-CNN,YOLO,SSD等)在推理时,对于同一个目标物体,通常会预测出多个重叠的、不同置信度(confidencescore)的候选边界框(BoundingBoxes)。直接输出所有这些框会导致:结果冗余:同一个物体
- NumPy-@运算符详解
GG不是gg
numpynumpy
NumPy-@运算符详解一、@运算符的起源与设计目标1.从数学到代码:符号的统一2.设计目标二、@运算符的核心语法与运算规则1.基础用法:二维矩阵乘法2.一维向量的矩阵语义3.高维数组:批次矩阵运算4.广播机制:灵活的形状匹配三、@运算符与其他乘法方式的核心区别1.对比`np.dot()`2.对比元素级乘法`*`3.对比`np.matrix`的`*`运算符四、典型应用场景:从基础到高阶1.深度学习
- NLP_知识图谱_大模型——个人学习记录
macken9999
自然语言处理知识图谱大模型自然语言处理知识图谱学习
1.自然语言处理、知识图谱、对话系统三大技术研究与应用https://github.com/lihanghang/NLP-Knowledge-Graph深度学习-自然语言处理(NLP)-知识图谱:知识图谱构建流程【本体构建、知识抽取(实体抽取、关系抽取、属性抽取)、知识表示、知识融合、知识存储】-元気森林-博客园https://www.cnblogs.com/-402/p/16529422.htm
- 解决 Python 包安装失败问题:以 accelerate 为例
在使用Python开发项目时,我们经常会遇到依赖包安装失败的问题。今天,我们就以accelerate包为例,详细探讨一下可能的原因以及解决方法。通过这篇文章,你将了解到Python包安装失败的常见原因、如何切换镜像源、如何手动安装包,以及一些实用的注意事项。一、问题背景在开发一个深度学习项目时,我需要安装accelerate包来优化模型的训练过程。然而,当我运行以下命令时:bash复制pipins
- 从RNN循环神经网络到Transformer注意力机制:解析神经网络架构的华丽蜕变
熊猫钓鱼>_>
神经网络rnntransformer
1.引言在自然语言处理和序列建模领域,神经网络架构经历了显著的演变。从早期的循环神经网络(RNN)到现代的Transformer架构,这一演变代表了深度学习方法在处理序列数据方面的重大进步。本文将深入比较这两种架构,分析它们的工作原理、优缺点,并通过实验结果展示它们在实际应用中的性能差异。2.循环神经网络(RNN)2.1基本原理循环神经网络是专门为处理序列数据而设计的神经网络架构。RNN的核心思想
- 如何使用Python实现交通工具识别
如何使用Python实现交通工具识别文章目录技术架构功能流程识别逻辑用户界面增强特性依赖项主要类别内容展示该系统是一个基于深度学习的交通工具识别工具,具备以下核心功能与特点:技术架构使用预训练的ResNet50卷积神经网络模型(来自ImageNet数据集)集成图像增强预处理技术(随机裁剪、旋转、翻转等)采用多数投票机制提升预测稳定性基于置信度评分的结果筛选策略功能流程用户通过GUI界面选择待识别图
- YOLOv11 技术详解:架构优化与性能提升
代码老y
YOLO架构目标跟踪
YOLOv11是目标检测领域中一个备受瞩目的新版本,它在保持实时性的同时,显著提升了检测的准确性和效率。本文将深入探讨YOLOv11的架构改进、性能优化以及它在不同应用场景中的表现。一、架构改进(一)C3K2块YOLOv11引入了C3K2块,这是对之前版本中CSP(CrossStagePartial)块的增强。C3K2块使用不同的核大小(例如3x3或5x5)和通道分离策略来优化更复杂特征的提取。这
- OpenCV图片操作100例:从入门到精通指南(1)
总有刁民想爱朕ha
opencv计算机视觉人工智能
OpenCV图片操作100例:从入门到精通指南本文整理了100个OpenCV实用技巧,涵盖图像处理各个领域,助你轻松掌握计算机视觉核心技能!一、入门必备:基础操作1.图像读写与显示importcv2#读取图像(BGR格式)img=cv2.imread('image.jpg')#显示图像cv2.imshow('示例图片',img)cv2.waitKey(0)#按任意键退出cv2.destroyAll
- OpenCV图片操作100例:从入门到精通指南(3)
总有刁民想爱朕ha
opencv人工智能计算机视觉
高效学习路径:1️⃣分阶段学习:入门:1-20例(基础操作)进阶:21-50例(图像处理)高级:51-100例(计算机视觉)2️⃣项目驱动学习:证件照背景替换(1-15例)停车场车位检测(30-45例)视频运动追踪(70-85例)3️⃣性能优化技巧:#使用UMat加速图像处理umat_img=cv2.UMat(img)processed=cv2.GaussianBlur(umat_img,(5,5
- YOLO11 目标检测从安装到实战
前言YOLO(YouOnlyLookOnce)系列是目标检测领域的经典算法,凭借速度快、精度高的特点被广泛应用。最新的YOLO11在模型结构和性能上进一步优化,本文将从环境搭建到实战应用,详细讲解YOLO11的使用方法,适合新手快速上手。一、环境准备1.系统要求操作系统:Windows10/11、Ubuntu20.04+、欧拉系统等硬件:CPU可运行,GPU(NVIDIA)可加速(推荐,需支持CU
- Python OpenCV教程从入门到精通的全面指南【文末送书】
一键难忘
pythonopencv开发语言
文章目录PythonOpenCV从入门到精通1.安装OpenCV2.基本操作2.1读取和显示图像2.2图像基本操作3.图像处理3.1图像转换3.2图像阈值处理3.3图像平滑4.边缘检测和轮廓4.1Canny边缘检测4.2轮廓检测5.高级操作5.1特征检测5.2目标跟踪5.3深度学习与OpenCVPythonOpenCV从入门到精通【文末送书】PythonOpenCV从入门到精通OpenCV(Ope
- OpenCV入门到精通:AI视觉处理的完整指南
AI云原生与云计算技术学院
人工智能opencv计算机视觉ai
OpenCV入门到精通:AI视觉处理的完整指南关键词:OpenCV、计算机视觉、图像预处理、目标检测、AI视觉应用摘要:本文是一份面向AI视觉爱好者的OpenCV完整学习指南。从OpenCV的核心概念讲起,结合生活案例、代码示例和项目实战,逐步拆解图像读取/显示、灰度化、边缘检测、目标检测等关键技术。无论你是想入门计算机视觉的新手,还是希望用OpenCV解决实际问题的开发者,都能通过本文掌握从理论
- CNN 猫狗识别:从理论到实战的深度解析
爱熬夜的小古
cnn深度学习人工智能
在计算机视觉领域,卷积神经网络(ConvolutionalNeuralNetwork,CNN)凭借其强大的特征提取和模式识别能力,成为图像分类任务的主流技术。猫狗识别作为经典的图像分类问题,不仅能帮助我们理解CNN的工作原理,还能为实际应用提供技术支持。本文将深入探讨CNN在猫狗识别中的应用,从理论基础到实战代码,带你全面掌握这项技术。一、CNN基础理论概述(一)CNN的核心组件卷积层:是CNN的
- OpenCV入门到精通:从基础到实战的全面指南
摘要:本文旨在为初学者和有一定经验的开发者提供OpenCV从入门到精通的全面指南。文章首先介绍了OpenCV的基本概念和安装方法,然后深入讲解了图像处理基础、特征检测与匹配、视频处理与分析等核心内容,最后通过实战案例展示了OpenCV在计算机视觉任务中的应用。关键词:OpenCV;图像处理;特征检测;视频分析;实战案例引言OpenCV(OpenSourceComputerVisionLibrary
- 第八周 tensorflow实现猫狗识别
降花绘
365天深度学习tensorflow系列tensorflow深度学习人工智能
本文为365天深度学习训练营内部限免文章(版权归K同学啊所有)**参考文章地址:[TensorFlow入门实战|365天深度学习训练营-第8周:猫狗识别(训练营内部成员可读)]**作者:K同学啊文章目录一、本周学习内容:1、自己搭建VGG16网络2、了解model.train_on_batch()3、了解tqdm,并使用tqdm实现可视化进度条二、前言三、电脑环境四、前期准备1、导入相关依赖项2、
- 深度学习实战-使用TensorFlow与Keras构建智能模型
程序员Gloria
Python超入门TensorFlowpython
深度学习实战-使用TensorFlow与Keras构建智能模型深度学习已经成为现代人工智能的重要组成部分,而Python则是实现深度学习的主要编程语言之一。本文将探讨如何使用TensorFlow和Keras构建深度学习模型,包括必要的代码实例和详细的解析。1.深度学习简介深度学习是机器学习的一个分支,使用多层神经网络来学习和表示数据中的复杂模式。其广泛应用于图像识别、自然语言处理、推荐系统等领域。
- AI在垂直领域的深度应用:医疗、金融与自动驾驶的革新之路
AI在垂直领域的深度应用:医疗、金融与自动驾驶的革新之路一、医疗领域:AI驱动的精准诊疗与效率提升1.医学影像诊断AI算法通过深度学习技术,已实现对X光、CT、MRI等影像的快速分析,辅助医生检测癌症、骨折等疾病。例如,GoogleDeepMind的AI系统在乳腺癌筛查中,误检率比人类专家低9.4%;中国的推想医疗AI系统可在20秒内完成肺部CT扫描分析,为急诊救治争取黄金时间。2.药物研发传统药
- 目前主流图像分类模型的详细对比分析
@comefly
闲聊linux运维服务器
以下是目前主流图像分类模型的详细对比分析,结合性能、架构特点及应用场景进行整理:一、主流模型架构分类与定量对比模型名称架构类型核心特点ImageNetTop-1准确率参数量(百万)计算效率典型应用场景ResNetCNN残差连接解决梯度消失,支持超深网络(如ResNet-152)76.1%25.6中等通用分类、目标检测ViTTransformer将图像分割为patches,用标准Transforme
- 专题:2025云计算与AI技术研究趋势报告|附200+份报告PDF、原数据表汇总下载
原文链接:https://tecdat.cn/?p=42935关键词:2025,云计算,AI技术,市场趋势,深度学习,公有云,研究报告云计算和AI技术正以肉眼可见的速度重塑商业世界。过去十年,全球云服务收入激增8倍,中国云计算市场规模突破6000亿元,而深度学习算法的应用量更是暴涨400倍。这些数字背后,是企业从“自建机房”到“云原生开发”的转型,是AI从“实验室”走向“产业级应用”的跨越。本报告
- 【深度学习解惑】在实践中如何发现和修正RNN训练过程中的数值不稳定?
云博士的AI课堂
大模型技术开发与实践哈佛博后带你玩转机器学习深度学习深度学习rnn人工智能tensorflowpytorch神经网络机器学习
在实践中发现和修正RNN训练过程中的数值不稳定目录引言与背景介绍原理解释代码说明与实现应用场景与案例分析实验设计与结果分析性能分析与技术对比常见问题与解决方案创新性与差异性说明局限性与挑战未来建议和进一步研究扩展阅读与资源推荐图示与交互性内容语言风格与通俗化表达互动交流1.引言与背景介绍循环神经网络(RNN)在处理序列数据时表现出色,但训练过程中常面临梯度消失和梯度爆炸问题,导致数值不稳定。当网络
- html
周华华
html
js
1,数组的排列
var arr=[1,4,234,43,52,];
for(var x=0;x<arr.length;x++){
for(var y=x-1;y<arr.length;y++){
if(arr[x]<arr[y]){
&
- 【Struts2 四】Struts2拦截器
bit1129
struts2拦截器
Struts2框架是基于拦截器实现的,可以对某个Action进行拦截,然后某些逻辑处理,拦截器相当于AOP里面的环绕通知,即在Action方法的执行之前和之后根据需要添加相应的逻辑。事实上,即使struts.xml没有任何关于拦截器的配置,Struts2也会为我们添加一组默认的拦截器,最常见的是,请求参数自动绑定到Action对应的字段上。
Struts2中自定义拦截器的步骤是:
- make:cc 命令未找到解决方法
daizj
linux命令未知make cc
安装rz sz程序时,报下面错误:
[root@slave2 src]# make posix
cc -O -DPOSIX -DMD=2 rz.c -o rz
make: cc:命令未找到
make: *** [posix] 错误 127
系统:centos 6.6
环境:虚拟机
错误原因:系统未安装gcc,这个是由于在安
- Oracle之Job应用
周凡杨
oracle job
最近写服务,服务上线后,需要写一个定时执行的SQL脚本,清理并更新数据库表里的数据,应用到了Oracle 的 Job的相关知识。在此总结一下。
一:查看相关job信息
1、相关视图
dba_jobs
all_jobs
user_jobs
dba_jobs_running 包含正在运行
- 多线程机制
朱辉辉33
多线程
转至http://blog.csdn.net/lj70024/archive/2010/04/06/5455790.aspx
程序、进程和线程:
程序是一段静态的代码,它是应用程序执行的蓝本。进程是程序的一次动态执行过程,它对应了从代码加载、执行至执行完毕的一个完整过程,这个过程也是进程本身从产生、发展至消亡的过程。线程是比进程更小的单位,一个进程执行过程中可以产生多个线程,每个线程有自身的
- web报表工具FineReport使用中遇到的常见报错及解决办法(一)
老A不折腾
web报表finereportjava报表报表工具
FineReport使用中遇到的常见报错及解决办法(一)
这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己。
出现问题先搜一下文档上有没有,再看看度娘有没有,再看看论坛有没有。有报错要看日志。下面简单罗列下常见的问题,大多文档上都有提到的。
1、address pool is full:
含义:地址池满,连接数超过并发数上
- mysql rpm安装后没有my.cnf
林鹤霄
没有my.cnf
Linux下用rpm包安装的MySQL是不会安装/etc/my.cnf文件的,
至于为什么没有这个文件而MySQL却也能正常启动和作用,在这儿有两个说法,
第一种说法,my.cnf只是MySQL启动时的一个参数文件,可以没有它,这时MySQL会用内置的默认参数启动,
第二种说法,MySQL在启动时自动使用/usr/share/mysql目录下的my-medium.cnf文件,这种说法仅限于r
- Kindle Fire HDX root并安装谷歌服务框架之后仍无法登陆谷歌账号的问题
aigo
root
原文:http://kindlefireforkid.com/how-to-setup-a-google-account-on-amazon-fire-tablet/
Step 4: Run ADB command from your PC
On the PC, you need install Amazon Fire ADB driver and instal
- javascript 中var提升的典型实例
alxw4616
JavaScript
// 刚刚在书上看到的一个小问题,很有意思.大家一起思考下吧
myname = 'global';
var fn = function () {
console.log(myname); // undefined
var myname = 'local';
console.log(myname); // local
};
fn()
// 上述代码实际上等同于以下代码
m
- 定时器和获取时间的使用
百合不是茶
时间的转换定时器
定时器:定时创建任务在游戏设计的时候用的比较多
Timer();定时器
TImerTask();Timer的子类 由 Timer 安排为一次执行或重复执行的任务。
定时器类Timer在java.util包中。使用时,先实例化,然后使用实例的schedule(TimerTask task, long delay)方法,设定
- JDK1.5 Queue
bijian1013
javathreadjava多线程Queue
JDK1.5 Queue
LinkedList:
LinkedList不是同步的。如果多个线程同时访问列表,而其中至少一个线程从结构上修改了该列表,则它必须 保持外部同步。(结构修改指添加或删除一个或多个元素的任何操作;仅设置元素的值不是结构修改。)这一般通过对自然封装该列表的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedList 方
- http认证原理和https
bijian1013
httphttps
一.基础介绍
在URL前加https://前缀表明是用SSL加密的。 你的电脑与服务器之间收发的信息传输将更加安全。
Web服务器启用SSL需要获得一个服务器证书并将该证书与要使用SSL的服务器绑定。
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后
- 【Java范型五】范型继承
bit1129
java
定义如下一个抽象的范型类,其中定义了两个范型参数,T1,T2
package com.tom.lang.generics;
public abstract class SuperGenerics<T1, T2> {
private T1 t1;
private T2 t2;
public abstract void doIt(T
- 【Nginx六】nginx.conf常用指令(Directive)
bit1129
Directive
1. worker_processes 8;
表示Nginx将启动8个工作者进程,通过ps -ef|grep nginx,会发现有8个Nginx Worker Process在运行
nobody 53879 118449 0 Apr22 ? 00:26:15 nginx: worker process
- lua 遍历Header头部
ronin47
lua header 遍历
local headers = ngx.req.get_headers()
ngx.say("headers begin", "<br/>")
ngx.say("Host : ", he
- java-32.通过交换a,b中的元素,使[序列a元素的和]与[序列b元素的和]之间的差最小(两数组的差最小)。
bylijinnan
java
import java.util.Arrays;
public class MinSumASumB {
/**
* Q32.有两个序列a,b,大小都为n,序列元素的值任意整数,无序.
*
* 要求:通过交换a,b中的元素,使[序列a元素的和]与[序列b元素的和]之间的差最小。
* 例如:
* int[] a = {100,99,98,1,2,3
- redis
开窍的石头
redis
在redis的redis.conf配置文件中找到# requirepass foobared
把它替换成requirepass 12356789 后边的12356789就是你的密码
打开redis客户端输入config get requirepass
返回
redis 127.0.0.1:6379> config get requirepass
1) "require
- [JAVA图像与图形]现有的GPU架构支持JAVA语言吗?
comsci
java语言
无论是opengl还是cuda,都是建立在C语言体系架构基础上的,在未来,图像图形处理业务快速发展,相关领域市场不断扩大的情况下,我们JAVA语言系统怎么从这么庞大,且还在不断扩大的市场上分到一块蛋糕,是值得每个JAVAER认真思考和行动的事情
- 安装ubuntu14.04登录后花屏了怎么办
cuiyadll
ubuntu
这个情况,一般属于显卡驱动问题。
可以先尝试安装显卡的官方闭源驱动。
按键盘三个键:CTRL + ALT + F1
进入终端,输入用户名和密码登录终端:
安装amd的显卡驱动
sudo
apt-get
install
fglrx
安装nvidia显卡驱动
sudo
ap
- SSL 与 数字证书 的基本概念和工作原理
darrenzhu
加密ssl证书密钥签名
SSL 与 数字证书 的基本概念和工作原理
http://www.linuxde.net/2012/03/8301.html
SSL握手协议的目的是或最终结果是让客户端和服务器拥有一个共同的密钥,握手协议本身是基于非对称加密机制的,之后就使用共同的密钥基于对称加密机制进行信息交换。
http://www.ibm.com/developerworks/cn/webspher
- Ubuntu设置ip的步骤
dcj3sjt126com
ubuntu
在单位的一台机器完全装了Ubuntu Server,但回家只能在XP上VM一个,装的时候网卡是DHCP的,用ifconfig查了一下ip是192.168.92.128,可以ping通。
转载不是错:
Ubuntu命令行修改网络配置方法
/etc/network/interfaces打开后里面可设置DHCP或手动设置静态ip。前面auto eth0,让网卡开机自动挂载.
1. 以D
- php包管理工具推荐
dcj3sjt126com
PHPComposer
http://www.phpcomposer.com/
Composer是 PHP 用来管理依赖(dependency)关系的工具。你可以在自己的项目中声明所依赖的外部工具库(libraries),Composer 会帮你安装这些依赖的库文件。
中文文档
入门指南
下载
安装包列表
Composer 中国镜像
- Gson使用四(TypeAdapter)
eksliang
jsongsonGson自定义转换器gsonTypeAdapter
转载请出自出处:http://eksliang.iteye.com/blog/2175595 一.概述
Gson的TypeAapter可以理解成自定义序列化和返序列化 二、应用场景举例
例如我们通常去注册时(那些外国网站),会让我们输入firstName,lastName,但是转到我们都
- JQM控件之Navbar和Tabs
gundumw100
htmlxmlcss
在JQM中使用导航栏Navbar是简单的。
只需要将data-role="navbar"赋给div即可:
<div data-role="navbar">
<ul>
<li><a href="#" class="ui-btn-active&qu
- 利用归并排序算法对大文件进行排序
iwindyforest
java归并排序大文件分治法Merge sort
归并排序算法介绍,请参照Wikipeida
zh.wikipedia.org/wiki/%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F
基本思想:
大文件分割成行数相等的两个子文件,递归(归并排序)两个子文件,直到递归到分割成的子文件低于限制行数
低于限制行数的子文件直接排序
两个排序好的子文件归并到父文件
直到最后所有排序好的父文件归并到输入
- iOS UIWebView URL拦截
啸笑天
UIWebView
本文译者:candeladiao,原文:URL filtering for UIWebView on the iPhone说明:译者在做app开发时,因为页面的javascript文件比较大导致加载速度很慢,所以想把javascript文件打包在app里,当UIWebView需要加载该脚本时就从app本地读取,但UIWebView并不支持加载本地资源。最后从下文中找到了解决方法,第一次翻译,难免有
- 索引的碎片整理SQL语句
macroli
sql
SET NOCOUNT ON
DECLARE @tablename VARCHAR (128)
DECLARE @execstr VARCHAR (255)
DECLARE @objectid INT
DECLARE @indexid INT
DECLARE @frag DECIMAL
DECLARE @maxfrag DECIMAL
--设置最大允许的碎片数量,超过则对索引进行碎片
- Angularjs同步操作http请求with $promise
qiaolevip
每天进步一点点学习永无止境AngularJS纵观千象
// Define a factory
app.factory('profilePromise', ['$q', 'AccountService', function($q, AccountService) {
var deferred = $q.defer();
AccountService.getProfile().then(function(res) {
- hibernate联合查询问题
sxj19881213
sqlHibernateHQL联合查询
最近在用hibernate做项目,遇到了联合查询的问题,以及联合查询中的N+1问题。
针对无外键关联的联合查询,我做了HQL和SQL的实验,希望能帮助到大家。(我使用的版本是hibernate3.3.2)
1 几个常识:
(1)hql中的几种join查询,只有在外键关联、并且作了相应配置时才能使用。
(2)hql的默认查询策略,在进行联合查询时,会产
- struts2.xml
wuai
struts
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.3//EN"
"http://struts.apache