图像中的目标检测学习笔记(一)
1.目标检测
本文包含以下内容:
目标检测算法概述
用于检测的后处理方法
新的度量标准:平均精度中值(mAP)
TensorFlow目标检测API
训练和监测神经网络的提示和技巧


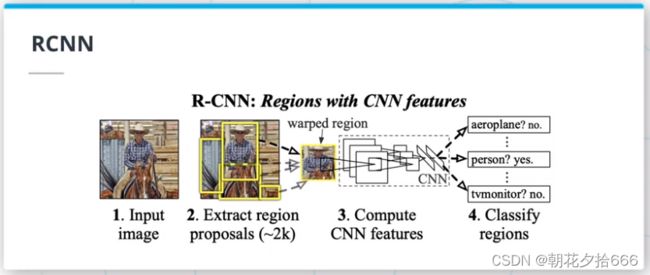
2.基于区域CNNs (RCNNs) I
选择性搜索
目标检测算法的第一次迭代依赖于选择性搜索,一种在图像中分割区域的迭代算法(http://www.huppelen.nl/publications/selectiveSearchDraft.pdf)。
RCNN (Region-Based CNN)家族的第一篇论文使用选择性搜索创建的区域作为卷积神经网络的输入。这篇2014年的论文(https://arxiv.org/pdf/1311.2524.pdf)中,通过选择性搜索创建的区域,在输入到CNN之前将其调整到固定大小的分辨率。
尽管在性能方面取得了突破,但这种架构仍有一些缺点:
需要将每个区域的大小调整为固定大小的输入
需要重新计算每个区域的CNN特征
它的速度很慢,因为它依赖于选择性搜索

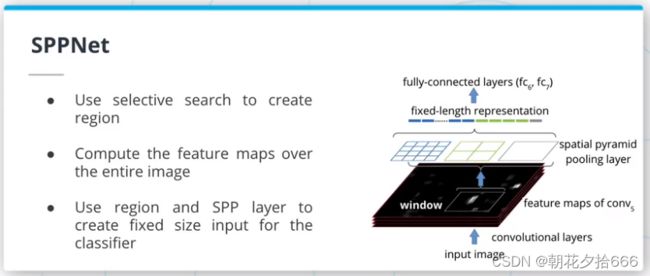
SPPNet
SPPNet(https://arxiv.org/abs/1406.4729)引入了一种新的层来弥补RCNN体系结构的一些问题:空间金字塔池化(SPP)层。这一层接受可变大小的输入,并创建固定大小的输入。
考虑一个具有1x1, 2x2, 2x3和4x4分割的4级SPP层的例子,给这个层提供一个2D数组。这个数组将使用这些拆分中的每一个进行池化,创建一个维度为1x1 + 2x2 + 2x3 + 4x4 = 27的向量。无论输入图像的分辨率是多少,输出矢量都是27x1矢量。
SPPNet也采用了与RCNN不同的方法,它重用了CNN的特征。事实上,不是输入裁剪后的输入图像,而是将整个图像输入CNN,并使用选择性搜索区域来裁剪最终的特征图。然后将这些区域送入SPP层。通过这样做,SPPNet获得了与RCNN相似的性能,同时将推断时间提高了近100倍。

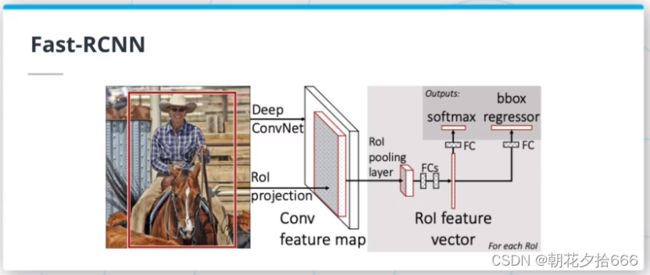
3.基于区域CNNs (RCNNs)II
Fast-RCNN
Fast RCNN(https://arxiv.org/pdf/1504.08083.pdf)在RCNN和SPPNet的基础上进行了改进,采用了多任务损失和端到端训练的方法,即对目标的分类和边界框的回归都使用单个损失函数。因此,可以将模型训练作为单个实体,而不必分别训练不同的模块。该模型还使用了感兴趣区域(ROI)池化,一个1级SPP层。

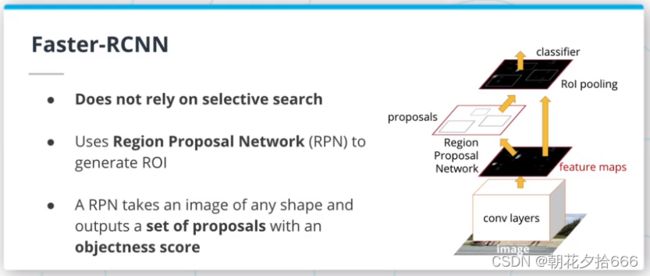
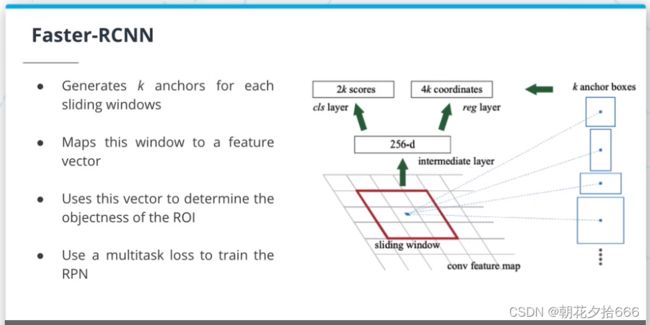
Faster-RCNN
Faster RCNN架构(https://arxiv.org/pdf/1506.01497.pdf)是RCNN家族的最新迭代。
它比RCNN和FastRCNN更好,不再依赖于选择性搜索。相反,它使用区域提议网络(Region Proposal Network, RPN)来生成ROIs。RPN使用最后一个卷积层的特征映射来生成ROIs。RPN在特征图上使用一个滑动窗口,对于该窗口的每个位置,生成k个锚框。这些锚框用于确定该区域是否包含目标。
由于采用了多任务损失函数,FasterRCNN的所有组件都是同时训练的。
4.单段式目标检测
You Only Look Once (YOLO)采取了与FasterRCNN非常不同的方法。这篇2016年论文(https://arxiv.org/pdf/1506.02640.pdf)的作者没有依赖于区域提议步骤,而是直接将输入图像分割成网格。对于网格的每个元素,网络预测B个边界框和目标得分。
通过摆脱区域提议步骤,YOLO提供了比FasterRCNN更快的推理时间。
作者又发布了两个版本的YOLO。这里描述了最新的YOLOv3(https://pjreddie.com/media/files/papers/YOLOv3.pdf)。此外,其他研究人员还发布了YOLOv4(https://arxiv.org/pdf/2004.10934.pdf)和YOLOv5(GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite)。YOLO仍然是最流行的目标检测架构之一。


5.单段式与二段式(One vs Two Stages )
二段式的目标检测模型,如FasterRCNN,需要一个区域提议步骤来提出ROIs,然后对该区域进行分类。而一段式的目标检测算法不需要区域提议步骤,直接对输入图像工作。虽然最初意味着一段式的目标检测更快但不太准确,但最近的YOLO迭代显示出了比FasterRCNN更好的性能。
然而, FasterRCNN仍然是最受欢迎的目标检测算法之一,可能是因为它在各种库中的广泛可用性,以及采用更新架构的行业的惯性。

更多探索
以下是其他一些流行的目标检测算法:
- SSD: Single Shot MultiBox Detector
- CenterNet: Keypoint Triplets for Object Detection
- Focal Loss for Dense Object Detection
6.Non-Max抑制
非最大抑制(Non max suppression, NMS)是一种去除冗余检测的后处理方法。FasterRCNN的区域提议网络(Region Proposal Network ,RPN)中,对于滑动窗口的每个位置,网络生成k个锚框。正因为如此,目标检测算法往往会输出大量的边界框;通过使用每个预测的置信度得分,可以去除高重叠/低置信度的预测来清理这些预测。


Soft-NMS
在2017年的这篇论文(https://arxiv.org/pdf/1704.04503.pdf)中,作者认为NMS实际上会通过去除高度遮挡物体的预测而损害目标检测算法的性能。相反,他们提出了 Soft NMS 算法。Soft NMS并没有删除高度重叠高置信度预测的预测,而是降低了它们的置信度得分。通过这样做,Soft NMS提高了密集环境下目标检测算法的性能。
7.练习1 -NMS
目标
在本练习中,实现非最大(Non-Max)抑制算法。
细节
给出一个json文件,包含一个预测列表,包括方框和分数。利用calculate_iou函数来计算这些不同预测的交集Over Union,并实现NMS算法。
为此,需要:
将每个边界框与集合中的所有其他边界框进行比较
对于每一对边框,计算IoU并比较分数
如果IoU高于阈值,则保留得分最高的那一栏
运行python nms.py来检查
提示
考虑为实现Soft NMS所做的修改。
参考代码:
import json
from utils import calculate_iou, check_results
def nms(predictions):
"""
non max suppression
args:
- predictions [dict]: predictions dict
returns:
- filtered [list]: filtered bboxes and scores
"""
data = []
for bb, sc in zip(predictions['boxes'], predictions['scores']):
data.append([bb, sc])
data_sorted = sorted(data, key = lambda k: k[1])[::-1]
filtered = []
for i, bi in enumerate(data_sorted):
discard = False
for j, bj in enumerate(data_sorted):
if i == j:
continue
iou = calculate_iou(bi[0], bj[0])
if iou > 0.5:
if bj[1] > bi[1]:
discard = True
if not discard:
filtered.append(bi)
return filtered
if __name__ == '__main__':
with open('../data/predictions_nms.json', 'r') as f:
predictions = json.load(f)
filtered = nms(predictions)
check_results(filtered)8.平均精度(mAP)
平均精度(mAP)是目标检测任务的度量指标。在文献中发现mAP指标的多种变化,COCO挑战网页(COCO - Common Objects in Context)很好地描述了不同的指标。pycocotools(cocoapi/PythonAPI/pycocotools at master · cocodataset/cocoapi · GitHub) Python库提供了一种评估目标检测结果的简单方法。
9.练习2 -平均精度(mAP)
目标
在这个练习中,实现平均精度(Mean Average Precision, mAP)指标。
细节
首先创建Precision-Recall(PR)曲线,一旦创建了这条曲线,需要创建平滑的版本;然后使用这个平滑版本来计算mAP。
创建一个可视化的PR和平滑的PR曲线。
提示
要创建PR曲线,需要根据预测的置信度分值对预测进行排序,并计算每个预测子集的精度和召回率。
可以基于PR曲线硬编码平滑的PR曲线,但应该考虑一个脚本版本。
参考代码:
import copy
import json
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
from utils import calculate_iou, check_results
if __name__ == '__main__':
# load data
with open('../data/predictions.json', 'r') as f:
preds = json.load(f)
with open('../data/ground_truths.json', 'r') as f:
gts = json.load(f)
# sort predictions by scores
boxes = preds[0]['boxes']
classes = preds[0]['classes']
scores = preds[0]['scores']
predictions = [(bb, cl, sc) for bb, cl,sc in zip(boxes, classes, scores)]
predictions = sorted(predictions, key=lambda k:k[-1])[::-1]
# create precision - recall plot
total = len(gts[0]['boxes'])
tp = 0
curve = []
for idx, pred in enumerate(predictions):
for bb in gts[0]['boxes']:
iou = calculate_iou(bb, pred[0])
# print(iou)
if iou > 0.5:
if pred[1] == 1:
tp += 1
prec = tp / (idx+1)
rec = tp / total
curve.append([prec, rec])
# smooth PR curve
curve = np.array(curve)
ct = Counter(curve[:, 1])
boundaries = sorted([k for k,v in ct.items() if v > 1])
# get max precision values
maxes = []
for i in range(len(boundaries)):
if i != len(boundaries) - 1:
loc = [p[0] for p in curve if boundaries[i+1] >= p[1] > boundaries[i]]
maxes.append(np.max(loc))
else:
loc = [p[0] for p in curve if p[1] > boundaries[i]]
maxes.append(np.max(loc))
smoothed = copy.copy(curve)
replace = -1
for i in range(smoothed.shape[0]-1):
if replace != -1:
smoothed[i, 0] = maxes[replace]
if smoothed[i, 1] == smoothed[i+1, 1]:
replace += 1
plt.plot(curve[:, 1], curve[:, 0], linewidth=4)
plt.plot(smoothed[:, 1], smoothed[:, 0], linewidth=4)
plt.xlabel('recall', fontsize=18)
plt.ylabel('precision', fontsize=18)
plt.show()
# calculate mAP
cmin = 0
mAP = 0
for i in range(smoothed.shape[0] - 1):
if smoothed[i, 1] == smoothed[i+1, 1]:
mAP += (smoothed[i, 1] - cmin) * smoothed[i, 0]
cmin = smoothed[i, 1]
mAP += (smoothed[-1, 1] - cmin) * smoothed[-1, 0]
check_results(mAP)