使用Pytorch框架自己制作做数据集进行图像分类(三)
第三章: Pytorch框架构建DenseNet神经网络
第一章: Pytorch框架制作自己的数据集实现图像分类
第二章: Pytorch框架构建残差神经网络(ResNet)
第三章: Pytorch框架构建DenseNet神经网络
文章目录
- 第三章: Pytorch框架构建DenseNet神经网络
- 前言
- 一、DenseNet网络简介
-
- 1. 背景介绍
- 2. DesNet网络结构特点及核心技术
- 二、DenseNet网络对图像进行分类(代码实现)
-
- 1.数据集介绍
- 2.导入相关数据包
- 3.读入图片数据文件并制作相应标签
- 4.定义图像处理和BirdsDataset类
- 4.提取每个图片的图片特征并创建FeatureDataset类
- 5.读入特征集定义分类模型
- 6.定义优化函数、损失函数、训练函数
- 7.进行50轮训练,并展示每轮训练结果
- 总结
- 附件 本篇文章所用全部代码
前言
作为CVPR2017年的Best Paper, DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing问题的产生.结合信息流和特征复用的设,DenseNet当之无愧成为2017年计算机视觉顶会的年度最佳论文。
研究表明,如果卷积网络在接近输入和接近输出地层之间包含较短地连接,那么,该网络可以显著地加深,变得更精确并且能够更有效地训练。该论文基于这个观察提出了以前馈地方式将每个层与其它层连接地密集卷积网络(DenseNet)
如上所述,所提出的网络架构中,两个层之间都有直接的连接,因此该网络的直接连接个数为L(L+1)2。对于每一层,使用前面所有层的特征映射作为输入,并且使用其自身的特征映射作为所有后续层的输入
先列下DenseNet的几个优点,感受下它的强大:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上较少了参数数量
本篇文章首先介绍DenseNet的原理以及网路架构,然后讲解DenseNet在Pytorch上的实现,调用DenseNet121网络架构实现图像分类。
提示:文章末尾附本文全部代码,更改数据集文件夹路径可跑通
一、DenseNet网络简介
1. 背景介绍
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如最近的GoogLenet,VGG-19,Incepetion等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。今天我们要介绍的是DenseNet模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。
这篇文章是CVPR2017的oral,文章提出的DenseNet(Dense Convolutional Network)主要还是和ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效!众所周知,最近一两年卷积神经网络提高效果的方向,要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception),而作者则是从feature入手,通过对feature的极致利用达到更好的效果和更少的参数。
2. DesNet网络结构特点及核心技术
请见《MXNet深度学习实战----计算机视觉算法实现》
论文:Densely Connected Convolutional Networks
论文代码的GitHub链接:请点击此处
MXNet版本代码(有ImageNet预训练模型): 请点击此处
二、DenseNet网络对图像进行分类(代码实现)
1.数据集介绍
加利福尼亚理工学院鸟类数据集(Caltech-UCSD Birds-200):
数据集包含 200 种鸟类(主要为北美洲鸟类)照片的图像数据集。
可用于进行细粒度图像识别分类。
分类数量:200种
图片数量: 11788张
文件大小:1.07G
提示:此为所用数据集下载链接,读者可自行下载
下载数据集
链接:https://pan.baidu.com/s/1_3tjPBnPGBIr1TG2V-jaeQ
提取码:dnet
2.导入相关数据包
代码如下:
import glob
import torch
import torchvision.models
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torch.nn as nn
3.读入图片数据文件并制作相应标签
代码如下:
#使用DenseNet121进行分类,对鸟类图片进行分类
#思路
#卷积部分可认为是特征提取网络,一个图的特征提取出来后是Tensor
#我们后面进行分类,是对图像特征进行分类
torchvision.models.densenet121()
imgs_path = glob.glob(r'F:\birds\*\*.jpg')
#获取前五图片
print(imgs_path[:5])
#在路径当中提取出类别名称
img_p = imgs_path[100] #随便取,这里取第100张
# print(img_p)
a = img_p.split('\\')[2].split('.')[1] #对图片路径进行分割得到类名
#列表推导式,提取出所有图片的类别
all_labels_name = [img_p.split('\\')[2].split('.')[1] for img_p in imgs_path]
# print(all_labels_name)
unique_label = np.unique(all_labels_name)
# print(len(unique_label))
label_to_index = dict((v, k) for k, v in enumerate(unique_label))
index_to_label = dict((v, k) for k, v in label_to_index.items())
# print(label_to_index)
# print(index_to_label)
#将图片类别完全转换成编码的形式
all_labels_name = [label_to_index.get(name) for name in all_labels_name]
print(all_labels_name)
print(len(all_labels_name))#显示所有图片总数量
#划分训练数据和测试数据
np.random.seed(2022)
random_index = np.random.permutation(len(imgs_path))
imgs_path = np.array(imgs_path)[random_index] #图片数据乱序
all_labels_name = np.array(all_labels_name)[random_index] #标签乱序,保证两者乱序一致性
i = int(len(imgs_path)*0.8)
train_path = imgs_path[:i]
train_labels = all_labels_name[:i]
test_path = imgs_path[i:]
test_labels = all_labels_name[i:]
4.定义图像处理和BirdsDataset类
代码如下:
#创建输入
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor()
])
class BirdsDataset(data.Dataset):
def __init__(self, imgs_path, labels):
self.imgs = imgs_path
self.labels = labels
def __getitem__(self, index):
img = self.imgs[index]
label = self.labels[index]
#注意对黑白照片,要处理为channel为3的形式
pil_img = Image.open(img) #H, W, ? Channel = 3
#对黑白图像进行处理
np_img = np.asarray(pil_img, dtype=np.uint8)
if len(np_img.shape)==2:
img_data = np.repeat(np_img[:, :, np.newaxis], 3, axis=2)
pil_img = Image.fromarray(img_data)
img_tensor = transform(pil_img)
return img_tensor, label
def __len__(self):
return len(self.imgs)
train_ds = BirdsDataset(train_path, train_labels)
test_ds = BirdsDataset(test_path, test_labels)
BATCH_SIZE = 32
train_dl = data.DataLoader(
train_ds,
batch_size=BATCH_SIZE,
)
test_dl = data.DataLoader(
test_ds,
batch_size=BATCH_SIZE,
)
img_batch, label_batch = next(iter(train_dl))
print(img_batch.shape)
plt.figure(figsize=(12,8))
for i, (img, label) in enumerate(zip(img_batch[:6],label_batch[:6])):
img = img.permute(1, 2, 0).numpy()
plt.subplot(2, 3, i+1)
plt.title(index_to_label.get(label.item()))
plt.imshow(img)
plt.show()
运行结果如下:

4.提取每个图片的图片特征并创建FeatureDataset类
代码如下:
#调用DenseNet提取特征
my_densenet = torchvision.models.densenet121(pretrained=True).features
#GPU
if torch.cuda.is_available():
my_densenet = my_densenet.cuda()
#设置不可训练
for p in my_densenet.parameters():
p.requires_grad = False
train_features = []
train_feat_labels = []
for im, la in train_dl:
out = my_densenet(im.cuda()) #一个批次一个批次的返回特征
#将四维数据扁平成二维
out = out.view(out.size(0), -1)
train_features.extend(out.cpu().data)
train_feat_labels.extend(la)
test_features = []
test_feat_labels = []
for im, la in test_dl:
out = my_densenet(im.cuda()) #一个批次一个批次的返回特征
#将四维数据扁平成二维
out = out.view(out.size(0), -1)
test_features.extend(out.cpu().data)
test_feat_labels.extend(la)
print(len(train_features)) #9430
#创建特征Dataset和分类模型
class FeatureDataset(data.Dataset):
def __init__(self, feat_list, label_list):
self.feat_list = feat_list
self.label_list = label_list
def __getitem__(self, index):
return self.feat_list[index], self.label_list[index]
def __len__(self):
return len(self.feat_list)
5.读入特征集定义分类模型
代码如下:
#使用提取之后的特征创建了两个DataSet
train_feat_ds = FeatureDataset(train_features, train_feat_labels)
test_feat_ds = FeatureDataset(test_features, test_feat_labels)
train_feat_dl = data.DataLoader(train_feat_ds,
batch_size=BATCH_SIZE,
shuffle=True
)
test_feat_dl = data.DataLoader(test_feat_ds,
batch_size=BATCH_SIZE
)
in_feat_size = train_features[0].shape[0]
class FCModel(torch.nn.Module):
def __init__(self, in_size, out_size):
super().__init__()
self.lin = torch.nn.Linear(in_size, out_size) #可一个linear层,也可以多个
def forward(self, input):
return self.lin(input)
6.定义优化函数、损失函数、训练函数
代码如下:
#将FCModel实例化
net = FCModel(in_feat_size, 200) #要分类200个种类
print(net)
#定义优化函数和损失函数
if torch.cuda.is_available():
net.to('cuda')
loss_fn = torch.nn.CrossEntropyLoss()
optim = torch.optim.Adam(net.parameters(), lr=0.00001)
#训练函数
def fit(epoch, model, trainloader, testloader):
corret = 0
total = 0
running_loss = 0
model.train()
for x, y in trainloader:
if torch.cuda.is_available():
y = torch.tensor(y, dtype=torch.long)
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred,y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
corret = corret +(y_pred == y).sum().item()
total = total + y.size(0)
running_loss = running_loss + loss.item()
epoch_loss = running_loss/len(trainloader.dataset) #!!!!小心变量名错误
epoch_acc = corret/total
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for x, y in testloader:
y = torch.tensor(y, dtype=torch.long)
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred =torch.argmax(y_pred, dim=1)
test_correct = test_correct + (y_pred == y).sum().item()
test_total = test_total + y.size(0)
test_running_loss = test_running_loss + loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset) # !!!!小心变量名错误
epoch_test_acc = test_correct / test_total
print('epoch:', epoch,
'loss:', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'test_loss', round(epoch_test_loss, 3),
'test_accuracy', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
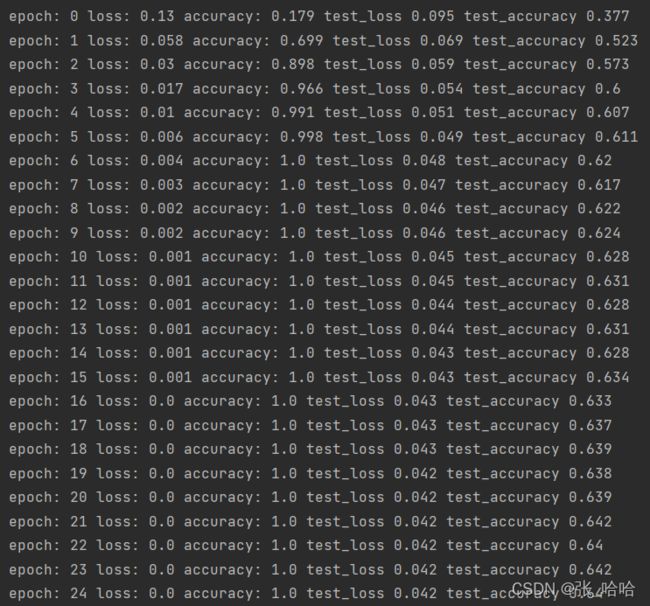
7.进行50轮训练,并展示每轮训练结果
代码如下:
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, net, train_feat_dl, test_feat_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
运行结果如下:

总结
提示:这里对文章进行总结:
附件 本篇文章所用全部代码
import glob
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision.models
from PIL import Image
from torch.utils import data
from torchvision import transforms
# 使用DenseNet121进行分类,对鸟类图片进行分类
# 思路
# 卷积部分可认为是特征提取网络,一个图的特征提取出来后是Tensor
# 我们后面进行分类,是对图像特征进行分类
torchvision.models.densenet121()
imgs_path = glob.glob(r'F:\birds\*\*.jpg')
# 获取前五图片
print(imgs_path[:5])
# 在路径当中提取出类别名称
img_p = imgs_path[100] # 随便取,这里取第100张
# print(img_p)
a = img_p.split('\\')[2].split('.')[1] # 对图片路径进行分割得到类名
# 列表推导式,提取出所有图片的类别
all_labels_name = [img_p.split('\\')[2].split('.')[1] for img_p in imgs_path]
# print(all_labels_name)
unique_label = np.unique(all_labels_name)
# print(len(unique_label))
label_to_index = dict((v, k) for k, v in enumerate(unique_label))
index_to_label = dict((v, k) for k, v in label_to_index.items())
# print(label_to_index)
# print(index_to_label)
# 将图片类别完全转换成编码的形式
all_labels_name = [label_to_index.get(name) for name in all_labels_name]
print(all_labels_name)
print(len(all_labels_name)) # 显示所有图片总数量
# 划分训练数据和测试数据
np.random.seed(2022)
random_index = np.random.permutation(len(imgs_path))
imgs_path = np.array(imgs_path)[random_index] # 图片数据乱序
all_labels_name = np.array(all_labels_name)[random_index] # 标签乱序,保证两者乱序一致性
i = int(len(imgs_path) * 0.8)
train_path = imgs_path[:i]
train_labels = all_labels_name[:i]
test_path = imgs_path[i:]
test_labels = all_labels_name[i:]
# 创建输入
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
class BirdsDataset(data.Dataset):
def __init__(self, imgs_path, labels):
self.imgs = imgs_path
self.labels = labels
def __getitem__(self, index):
img = self.imgs[index]
label = self.labels[index]
# 注意对黑白照片,要处理为channel为3的形式
pil_img = Image.open(img) # H, W, ? Channel = 3
# 对黑白图像进行处理
np_img = np.asarray(pil_img, dtype=np.uint8)
if len(np_img.shape) == 2:
img_data = np.repeat(np_img[:, :, np.newaxis], 3, axis=2)
pil_img = Image.fromarray(img_data)
img_tensor = transform(pil_img)
return img_tensor, label
def __len__(self):
return len(self.imgs)
train_ds = BirdsDataset(train_path, train_labels)
test_ds = BirdsDataset(test_path, test_labels)
BATCH_SIZE = 32
train_dl = data.DataLoader(
train_ds,
batch_size=BATCH_SIZE,
)
test_dl = data.DataLoader(
test_ds,
batch_size=BATCH_SIZE,
)
img_batch, label_batch = next(iter(train_dl))
print(img_batch.shape)
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(img_batch[:6], label_batch[:6])):
img = img.permute(1, 2, 0).numpy()
plt.subplot(2, 3, i + 1)
plt.title(index_to_label.get(label.item()))
plt.imshow(img)
plt.show()
# 调用DenseNet提取特征
my_densenet = torchvision.models.densenet121(pretrained=True).features
# GPU
if torch.cuda.is_available():
my_densenet = my_densenet.cuda()
# 设置不可训练
for p in my_densenet.parameters():
p.requires_grad = False
train_features = []
train_feat_labels = []
for im, la in train_dl:
out = my_densenet(im.cuda()) # 一个批次一个批次的返回特征
# 将四维数据扁平成二维
out = out.view(out.size(0), -1)
train_features.extend(out.cpu().data)
train_feat_labels.extend(la)
test_features = []
test_feat_labels = []
for im, la in test_dl:
out = my_densenet(im.cuda()) # 一个批次一个批次的返回特征
# 将四维数据扁平成二维
out = out.view(out.size(0), -1)
test_features.extend(out.cpu().data)
test_feat_labels.extend(la)
print(len(train_features)) # 9430
# 创建特征Dataset和分类模型
class FeatureDataset(data.Dataset):
def __init__(self, feat_list, label_list):
self.feat_list = feat_list
self.label_list = label_list
def __getitem__(self, index):
return self.feat_list[index], self.label_list[index]
def __len__(self):
return len(self.feat_list)
# 使用提取之后的特征创建了两个DataSet
train_feat_ds = FeatureDataset(train_features, train_feat_labels)
test_feat_ds = FeatureDataset(test_features, test_feat_labels)
train_feat_dl = data.DataLoader(train_feat_ds,
batch_size=BATCH_SIZE,
shuffle=True
)
test_feat_dl = data.DataLoader(test_feat_ds,
batch_size=BATCH_SIZE
)
in_feat_size = train_features[0].shape[0]
class FCModel(torch.nn.Module):
def __init__(self, in_size, out_size):
super().__init__()
self.lin = torch.nn.Linear(in_size, out_size) # 可一个linear层,也可以多个
def forward(self, input):
return self.lin(input)
# 将FCModel实例化
net = FCModel(in_feat_size, 200) # 要分类200个种类
print(net)
# 定义优化函数和损失函数
if torch.cuda.is_available():
net.to('cuda')
loss_fn = torch.nn.CrossEntropyLoss()
optim = torch.optim.Adam(net.parameters(), lr=0.00001)
# 训练函数
def fit(epoch, model, trainloader, testloader):
corret = 0
total = 0
running_loss = 0
model.train()
for x, y in trainloader:
if torch.cuda.is_available():
y = torch.tensor(y, dtype=torch.long)
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
corret = corret + (y_pred == y).sum().item()
total = total + y.size(0)
running_loss = running_loss + loss.item()
epoch_loss = running_loss / len(trainloader.dataset) # !!!!小心变量名错误
epoch_acc = corret / total
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for x, y in testloader:
y = torch.tensor(y, dtype=torch.long)
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct = test_correct + (y_pred == y).sum().item()
test_total = test_total + y.size(0)
test_running_loss = test_running_loss + loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset) # !!!!小心变量名错误
epoch_test_acc = test_correct / test_total
print('epoch:', epoch,
'loss:', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'test_loss', round(epoch_test_loss, 3),
'test_accuracy', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, net, train_feat_dl, test_feat_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)