从源码看Java中Object类中hashCode方法的实现
hashcode方法会影响jvm性能?听上去天方夜谭,实际上蕴藏着一些微小的原理,接下来让我们走进hashcode方法,一探native方法源头(hashcode方法java源码中有native关键字,大致含义就是此方法由c或c++语言来实现,并不是java)。
默认实现
调用hashCode方法默认返回的值被称为identity hash code(标识哈希码),接下来我们会用标识哈希码来区分重写hashCode方法。如果一个类重写了hashCode方法,那么通过调用System.identityHashCode(Object o)方法获得标识哈希码,也就是说并不是我们重写了hashCode方法就再也得不到默认的hashcode了,同样可以通过System.identityHashCode(Object o)方法来获得默认的hahscode。
在hashcode方法的注释中,这样写道:hashcode方法通常是通过转换内部对象的地址转换成整数,但是这个实现不是必需的,大致意思就是说通常和对象的内存地址有关,但具体的实现由jvm决定,jvm不同,实现就可能不同。
但是了解jvm的同学肯定知道,不管是标记复制算法还是标记整理算法,都会改变对象的内存地址。鉴于jvm重定位对象地址,但该hashCode又不能变化,那么该值一定是被保存在对象的某个地方了。
我们推测,很有可能是在第一次调用hashCode方法时获取当前内存地址,并将其保存在对象的某个地方,当下次调用时,只用从对象的某个地方获取值即可。但这样实际是有问题的,你想想,如果对象被归集到别的内存上了,那在对象以前的内存上创建的新对象其hashCode方法返回的值岂不是和旧对象的一样了?这倒没关系,java规范允许这样做。
至此,我们的推测hashcode方法返回值和内存地址有关,是否正确呢,我们先跑一下程序验证一下(JDK8环境)。
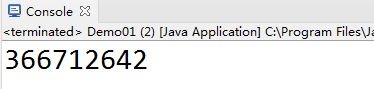
第一次
public static void main(String[] args) {
Object object=new Object();
System.out.println(object.hashCode());
}
第二次
public static void main(String[] args) {
Object object1=new Object();
Object object2=new Object();
Object object3=new Object();
Object object=new Object();
System.out.println(object.hashCode());
}
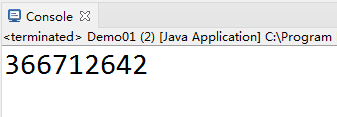
我们可以发现,这两次运行的结果一样,这说明hashcode方法返回值确实和内存地址无关。我们在第二次运行时,新建了三个无关的Object对象使得内存分布和第一次不同,即便这样,程序第二次运行得到的hahscode方法返回值依然和第一次相同。
真正的hashCode方法
hashCode方法的实现依赖于jvm,不同的jvm有不同的实现,我们目前能看到jvm源码就是OpenJDK的源码,OpenJDK的源码大部分和Oracle的JVM源码一致。
OpenJDK定义hashCode的方法在src/share/vm/prims/jvm.h和src/share/vm/prims/jvm.cpp
jvm.cpp:
508 JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
509 JVMWrapper("JVM_IHashCode");
510 // as implemented in the classic virtual machine; return 0 if object is NULL
511 return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
512 JVM_END
ObjectSynchronizer :: FastHashCode() 也是通过调用identity_hash_value_for方法返回值的,System.identityHashCode()调用的也是这个方法。
708 intptr_t ObjectSynchronizer::identity_hash_value_for(Handle obj) {
709 return FastHashCode (Thread::current(), obj()) ;
710 }
我们可能会认为 ObjectSynchronizer :: FastHashCode() 会判断当前的hash值是否为0,如果是0则生成一个新的hash值。实际上没那么简单,来看看其中的代码。
685 mark = monitor->header();
...
687 hash = mark->hash();
688 if (hash == 0) {
689 hash = get_next_hash(Self, obj);
...
701 }
...
703 return hash;
上边的片段展示了hash值是如何生成的,可以看到hash值是存放在对象头中的,如果hash值不存在,则使用get_next_hash方法生成。
真正的 identity hash code 生成
我们找到了生成hash的最终函数 get_next_hash,这个函数提供了6种生成hash值的方法。
0. A randomly generated number.
1. A function of memory address of the object.
2. A hardcoded 1 (used for sensitivity testing.)
3. A sequence.
4. The memory address of the object, cast to int.
5. Thread state combined with xorshift (https://en.wikipedia.org/wiki/Xorshift)
那么默认用哪一个呢?根据globals.hpp,OpenJDK8默认采用第五种方法。而 OpenJDK7 和 OpenJDK6 都是使用第一种方法,即 随机数生成器。
大家也看到了,JDK的注释算是欺骗了我们,明明在6,7,8版本上都是随机生成的值,为什么要引导说是内存地址映射呢?我的理解可能以前的jdk版本就是通过第4种方法实现的,具体是不是大家自己去找答案吧。
对象头格式
在上一节,我们知道了hash值是放在对象头里的,那就来了解一下对象头的结构吧。
markOop.hpp
30 // The markOop describes the header of an object.
31 //
32 // Note that the mark is not a real oop but just a word.
33 // It is placed in the oop hierarchy for historical reasons.
34 //
35 // Bit-format of an object header (most significant first, big endian layout below):
36 //
37 // 32 bits:
38 // --------
39 // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
40 // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
41 // size:32 ------------------------------------------>| (CMS free block)
42 // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
43 //
44 // 64 bits:
45 // --------
46 // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
47 // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
48 // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
49 // size:64 ----------------------------------------------------->| (CMS free block)
50 //
51 // unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
52 // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
53 // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
54 // unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
它的格式在32位和64位上略有不同,64位有两种变体,具体取决于是否启用了压缩对象指针。
对象头中偏向锁和hashcode的冲突
normal object和biased object分别存放的是hashcode和java的线程id。因此也就是说如果调用了本地方法hashCode,就会占用偏向锁对象使用的位置,偏向锁将会失效,晋升为轻量级锁。
这个过程我们可以看看这个图:
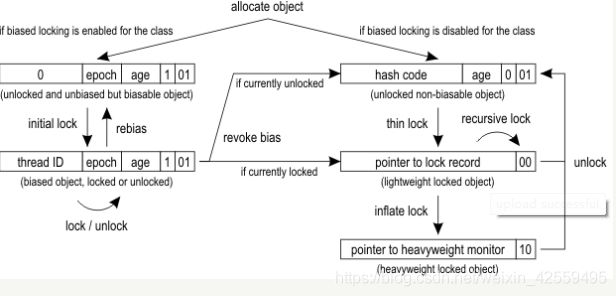
这里我来简单解读一下,首先在jvm启动时,可以使用-XX:+UseBiasedLocking=true参数开启偏向锁。
接下来,如果偏向锁可用,那分配的对象中标记字格式为可包含线程ID,当未锁定时,线程ID为0,第一次获取锁时,线程会把自己的线程ID写到ThreadID字段内,这样,下一次获取锁时直接检查标记字中的线程ID和自身ID是否一致,如果一致就认为获取了锁,因此不需要再次获取锁。
假设这时有别的线程需要竞争锁了,此时该线程会通知持有偏向锁的线程释放锁,假设持有偏向锁的线程已经销毁,则将对象头设置为无锁状态,如果线程活着,则尝试切换,如果不成功,那么锁就会升级为轻量级锁。
这时有个问题来了,如果需要获取对象的identity hash code,偏向锁就会被禁用,然后给原先设置线程ID的位置写入hash值。
如果hash有值,或者偏向锁无法撤销,则会进入轻量级锁。轻量级锁竞争时,每个线程会先将hashCode值保存到自己的栈内存中,然后通过CAS尝试将自己新建的记录空间地址写入到对象头中,谁先写成功谁就拥有了该对象。
轻量级锁竞争失败的线程会自旋尝试获取锁一段时间,一段时间过后还没获取到锁,则升级为重量级锁,没获取锁的线程会被真正阻塞。
总结
- OpenJDK默认的hashCode方法实现和对象内存地址无关,在版本6和7中,它是随机生成的数字,在版本8中,它是基于线程状态的数字。(AZUL-ZING的hashcode是基于地址的)
- 在HotSpot中,hash值会存在标记字中。(Java虚拟机有多种,从JDK1.3以后,HotSpot虚拟机成为JDK1.3及其以后所有JDK版本的默认Java虚拟机。
- hashCode方法和System.identityHashCode()会让对象不能使用偏向锁,所以如果想使用偏向锁,那就最好重写hashCode方法。
- 如果大量对象跨线程使用,可以禁用偏向锁。
- 使用-XX:hashCode=4来修改默认的hash方法实现。
本文略有修改,转载自:原文链接