Transformer流程解析及细节思考
目录
- Transformer流程
- Attention机制
- 模块解析
-
- Embedding和Positional Encoding
-
- Embedding
- Positional Encoding
- Encoder
-
- Multi-Head Attention
- Feed Forward Network(FFN)
- Add & Norm
-
- 残差 Add
- 层归一化 Layer normalization
- Encoder总结
- Decoder
-
- 1. Decoder的输入到底是什么
- 2. Decoder到底是不是并行计算的
- 3. Encoder与Decoder之间的交互
- 总结
- 参考链接
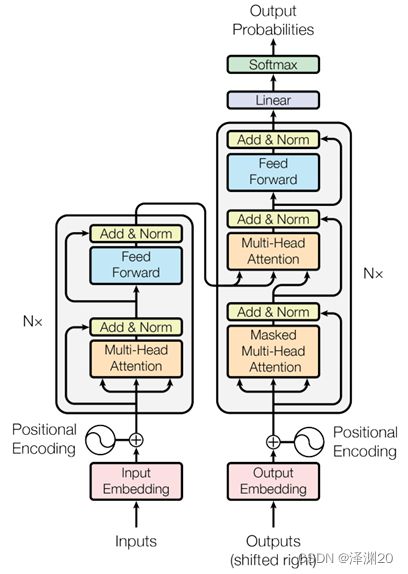
Transformer流程
Inputs表示输入的数据,在NLP中可以是一个句子,经过Input Embedding后转换为数值向量,再通过Positional Encoding向数值向量中添加位置信息,进入由N个层组成的Encoder部分,首先通过多头注意力层(Multi-Head Attention),计算自注意力,接下来的Add&Norm层代表着残差连接和归一化处理,与CNN中不同的是,此处的归一化是layer normalization,CNN中是batch normalization。之后送入Feed Forward层中,实际上这里是一个MLP。
Decoder部分和Encoder部分子层结构基本一致,有两处明显修改,一是多头注意力层增加了Mask,原因是NLP中预测时只知道一句话中的部分字词,从而预测句子后续内容,Mask用于将不应该知道的部分句子屏蔽掉。另一处修改是,Decoder中先经过一个多头自注意力层和残差、归一化层后,增加了一个交叉注意力层,该层的q来自Decoder的Masker Multi-Head Attention,k和v来自Encoder的输出。
在经过Encoder和Decoder后,经过线性层进行映射,最后softmax输出结果。下面将详细介绍Transformer中的注意力机制和各个模块的细节。
Attention机制
注意力机制借鉴了人类的注意力机制,在人类的视觉系统中,有着选择性的注意力机制。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
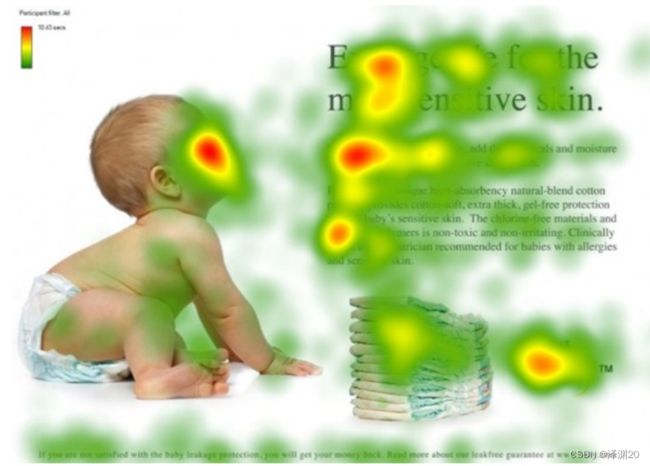
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
self-attention 最终想要的是什么?
给定当前输入样本 x i ∈ R 1 × d x_i\in\mathbb{R}^{1\times d} xi∈R1×d( 为了更好地理解,我们把输入进行拆解),产生一个输出,而这个输出是序列中所有样本的加权和。因为假设这个输出能看到所有输入的样本信息,然后根据不同权重选择自己的注意力点。
Transformer中的注意力机制有self-attention和cross-attention,其实self-attention也就是Q=K=V=X,attention(Q, K, V)=attention(X, X, X),而cross-attention则是Q != K = V, Q != K != V。
Source中的构成元素想象成是由一系列的

关于深度学习中的注意力机制,详细了解可以点击这篇博客文章。
模块解析
Embedding和Positional Encoding
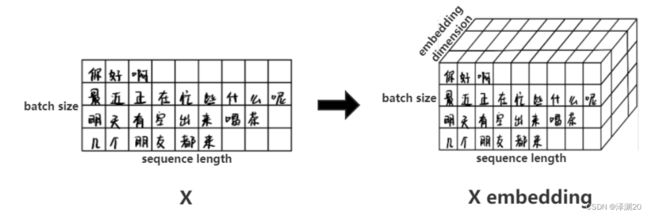
Embedding
简单来说,embedding就是用一个数值向量“表示”一个对象,这里的对象可以是一个词,或是一个商品,或是一个电影等等。这个embedding向量的性质是能使距离相近的向量对应的对象有相近的含义。如果对Embedding表征对象的相近原理有疑问,可以参考这里。
Embedding能够用低维向量对物体进行编码还能保留其含义的特点非常适合深度学习。首先,Embedding 是处理稀疏特征的利器。在传统机器学习模型构建过程中,我们经常使用one hot encoding对离散特征,特别是id类特征进行编码, 因为推荐场景中的类别、ID 型特 征非常多,大量使用 One-hot 编码会导致样本特征向量极度稀疏,而深度学习的结构特点又不利于稀疏特征向量 的处理,因此几乎所有深度学习推荐模型都会由 Embedding 层负责将稀疏高维特征向量转换成稠密低维特征向 量。所以说各类 Embedding 技术是构建深度学习推荐模型的基础性操作。其次,Embedding 可以融合大量有价值信息,本身就是极其重要的特征向量 。 相比由原始信息直接处理得来的特 征向量,Embedding 的表达能力更强,特别是 Graph Embedding 技术被提出后,Embedding 几乎可以引入任何 信息进行编码,使其本身就包含大量有价值的信息,所以通过预训练得到的 Embedding 向量本身就是极其重要的 特征向量。
Positional Encoding
自然语言处理中,同样的字组成的句子,在不同的顺序下表达的意思可能截然不同,文本是时序型数据,词与词之间的顺序关系往往影响整个句子的含义。例如“我爱你”和“你爱我”,组成的字是一样的,但表达的意思完全不同。Transfomer的效果非常好并且可以对语句进行并行计算,也就是同时把一句话中的所有词都输入进去同时计算,大大加快了计算效率。但是问题来了,并行计算好是好,但是我们怎么让模型知道一句话中每个字的顺序信息呢?这就要引出我们的Positional Encoding(位置编码)了。
位置编码的目的是将位置信息内嵌到输入向量中,保证在计算中位置信息不丢失。对于transformer模型的positional encoding有两种主流方式:绝对位置编码和相对位置编码。
绝对位置编码是指直接对不同的位置随机初始化一个postion embedding,加到word embedding上输入模型,作为参数进行训练。对模型来说,输入序列的每个元素都打上了一个“位置标签”标明其绝对位置。

绝对位置编码考虑到了不同位置使用不同的编码,但位置之间的相互关系确没有显式地体现出来。相对位置编码能够显式地体现不同位置之间的相互关系,告知模型两两元素之间的距离。
初始版本Transformer中使用的是绝对位置编码,用三角函数实现。
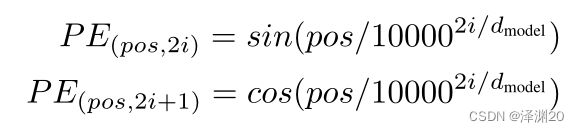
绝对位置编码有很多种方式,最简单的有直接使用计数来编码,给定一个长为T的文本,使用0, 1, 2,…, T-1作为文本中每个字的位置编码。这种编码有两个缺点:1. 如果一个句子的字数较多,则后面的字比第一个字的Positional Encoding大太多,和word embedding合并以后难免会出现特征在数值上的倾斜;2. 这种位置编码的数值比一般的word embedding的数值要大,对模型可能有一定的干扰。
为了避免上述问题,可以考虑对其进行归一化,使得所有编码落入[0, 1]之间,但问题也很明显,不同长度文本的位置编码步长是不同的,在较短的文本中紧紧相邻的两个字的位置编码差异,会和长文本中相邻数个字的两个字的位置编码差异一致,如下图所示。

使用三角函数的优点则是1、可以使PE分布在[0,1]区间。2、不同语句相同位置的字符PE值一样(如:当pos=0时,PE=0)。
考虑到三角函数具有周期性,可能出现pos值不同但是PE值相同的情况,把PE的长度加长到和word embedding一样长,再交替使用sin/cos来计算PE的值以进一步增加PE,于是就得到了论文中的计算公式。
为什么是将positional encoding与输入向量相加而非拼接呢?这是因为 Transformer 通常会对原始输入做一个嵌入(embedding),从而映射到需要的维度,可采用一个变换矩阵做矩阵乘积的方式来实现,上述代码中的输入 x 其实就是已经变换后的表示,而非原输入。
事实上,在原输入上 concat 一个代表位置信息的向量在经过线性变换后 等同于 将原输入经线性变换后直接加上位置编码信息。 我们尝试使用 concat 的方式在原始输入中加入位置编码:

Encoder
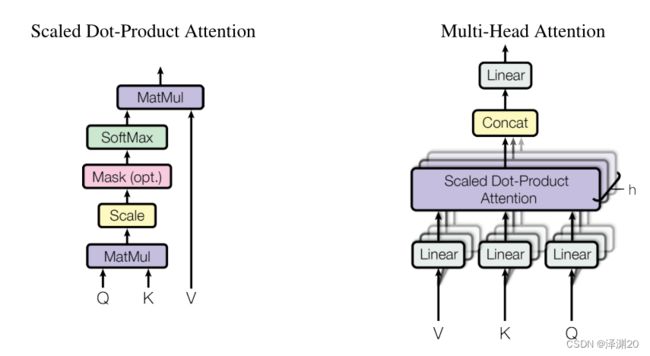
Multi-Head Attention
在 Encoder 的第1层里,多头自注意力层的输入是特征向量矩阵(比如多个词向量组成的矩阵 ),而在后面的其它层,输入则是前一层的输出。多头自注意力层由多个自注意力层组成,其输出由其中的每个自注意力层的输出拼接而成。
先来看看单个自注意力层的操作。当自注意力层获得输入后,会对其做不同的线性变换分别生成 Q(Query)、K(Key)、V(Value) 三个矩阵。权重矩阵 W Q W_Q WQ、 W K W_K WK、 W V W_V WV是可学习的权重参数。

然后按照如下公式计算输出:

d k d_k dk是 Q , V Q,V Q,V矩阵的列数,即向量维度。
这个计算过程的操作也称为 Scaled Dot-Product Attention 。
至此,我们已经得到单个自注意力的输出。而多头自注意力就是“多个头的自注意力”,通常“头数”(通俗理解为个数)设为8,这样就有8个自注意力的输出,最后将它们拼接起来再经过一个线性变换即可。
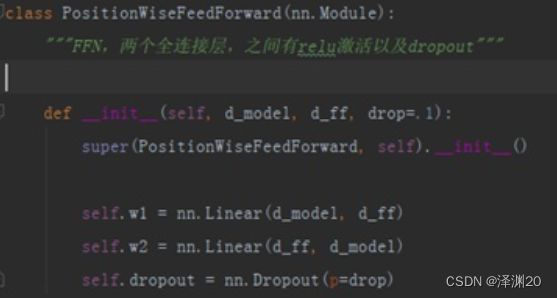
Feed Forward Network(FFN)
FFN的实质是两个全连接层,其中一个带ReLU层,两层中间有Dropout。等同于MLP。
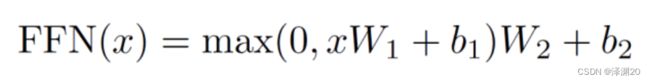
Add & Norm
该层包含两个操作,残差add和层归一化layer normalization。
残差 Add
设经过某个sublayer之前的输入是x,在经过sublayer后进行残差连接的计算,则对应的残差计算可以表示为
y = x + S u b l a y e r ( x ) y=x + Sublayer(x) y=x+Sublayer(x)
其中 y y y表示经过残差模块的结果, S u b l a y e r ( x ) Sublayer(x) Sublayer(x)表示经过某个子层后的结果。
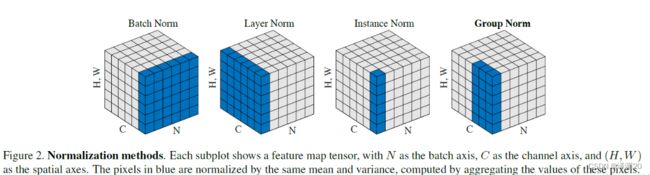
层归一化 Layer normalization
Layer Normalization的思想与Batch Normalization非常类似,只是Batch Normalization是在每个神经元对一个mini batch大小的样本进行规范化,而Layer Normalization则是在每一层对单个样本的所有神经元节点进行规范化。
Encoder总结
Encoder内的子层以及attention机制在上文都进行了相对详细的描述,整个Encoder是以N个如下结构的级联呈现的,初代transformer代码的N=6。

Decoder
解码器部分和编码器部分结构基本相同,主要的变化在于多头注意力层增加了掩码mask,以及在Encoder的feed forward层之前加了一个多头注意力,其输入和之前的多头注意力有所不同。
掩码的作用是在NLP中,输出预测的时候应该只知道真值句子中的一部分,剩余部分是需要预测的,但transformer并行处理整个句子的所有内容,为了和推理的过程匹配,得到正确的模型,引入掩码,将不应该知道的部分隐去。
新加的多头注意力层,其输入k和v来自encoder的最终输出,q来自decoder上一层的输出。根据q和k的相似度,对v进行加权。

1. Decoder的输入到底是什么
在train模式下和在test模式下Decoder的输入是不同的,在train模式下Decoder的输入是Ground Truth,也就是不管输出是什么,会将正确答案当做输入,这种模式叫做teacher-forcing。但是在test模式下根本没有Ground Truth去teach,那只能将已经出现的词的输出(注意这里的输出是走完整个Decoder计算得到预测结果而不是走完一层Decoder的输出)当做下一次Decoder计算的输入,我想这也是论文中shifted right的意思,一直往右移。
2. Decoder到底是不是并行计算的
在Transformer中,最被人津津乐道,也是他相较于RNN类型模型最大的优点之一就是他可以并行计算,但是这个并行计算仅限于在Encoder中,在Encoder中是将所有的词一起输入一起计算,但是在Decoder中不是的,在Decoder中依然是像RNN一样一个一个词输入,将已经出现的词计算得到的Q与Encoder计算得到的K,V进行计算,经过了全部Decoder层再经过FC+Softmax得到结果之后再把结果当做Decoder的输入再走一遍整个流程直到得到END标签。
3. Encoder与Decoder之间的交互
Encoder与Decoder之间的交互不是每一层一一对应的,而是Encoder 6层全部计算完得到K和V之后再将K和V传给Decoder的每一层与其计算得到的Q进行计算。此外,Encoder和Decoder之间的连接方式还有各种可能的方法。
总结
Transformer通过encoder获取特征,在训练时,Decoder的输入是ground truth和encoder的编码,这样所有的gt可以同时送进decoder进行训练,在推断时,decoder的输入是上次层decoder的输出和encoder的编码,需要一个个一次送入。
参考链接
深度学习中的注意力机制(2017版)
所有人都在谈的Embedding到底是什么?
什么是embedding?
Positional Encoding的原理和计算
Transformer 修炼之道(一)、Input Embedding
Transformer 修炼之道(二)、Encoder
层标准化详解(Layer Normalization)
Transformer Decoder详解