moses(mosesdecoder)数据预处理&BPE分词&moses用法总结
mosesdecoder&BPE数据预处理
-
- moses数据预处理
- BPE分词
- moses用法总结
moses数据预处理
源码链接:
https://github.com/moses-smt/mosesdecoder
做机器翻译的小伙伴应该会moses很熟悉,这是一个很强大的数据预处理工具,虽然已经用了很多年了,但现在依然非常流行。
很多人做数据预处理都会用到BPE算法,bpe算法太强大,30000个子词几乎可以表示词典中所有的单词。但是如果我们要用词级别的翻译,那词典太大了,在机器翻译中词典受限的情况下,很多词就会变为未登录词。为了让词典尽可能的能囊括更多的单词,必须对双语语料进行预处理操作。
中文的预处理好做很多,除了分词,可做的就不多了,相比之下,英文的预处理就变得繁琐了很多,比如在bpe的子词词典中,我们可以看到American’s 和american’s同时存在于词典,并且英文的标点符号和单词之间是没空格分隔的,所以如果直接对英文按照空格进行分词,cat和cat.就可能占据词典中两个词的位置,这些都是不合理的,会浪费词典的位置。所以对英文的处理是及其有必要的。
mosesdecoder作为统计机器翻译工具,常用的预处理方法如下:
normalize:对标点符号进行规范化。
perl dir_name/mosesdecoder/scripts/tokenizer/normalize-punctuation.perl -l en < data/train.en > data/train.norm.en
其中-l en是选择语言,de类似
tokenisation:分词
perl dir_name/mosesdecoder/scripts/tokenizer/tokenizer.perl -a -l en < data/train.norm.en > data/train.norm.tok.en
de类似
cleaning:长句和空语句可引起训练过程中的问题,因此将其删除,同时删除明显不对齐的句子。–将句子长度控制在1-80。
perl path/to/mosesdecoder/scripts/training/clean-corpus-n.perl data/train.norm.tok en de data/train.norm.tok.clean 1 80
这样会同时将双语语料进行操作,生成两个处理后的文件train.norm.tok.clean.en和train.norm.tok.clean.de。
truecasing:Truecase不同于lowercase,lowercase相当于把数据中所有的字母小写,而truecase则会学习训练数据,判断句子中的名字、地点等需要大写的内容并将其保留,其余则小写,提升翻译时候的准确性,这有助于减少数据稀疏性问题。
- 需要训练一个truecase模型。注意:只能使用训练集训练truecase模型。
perl path/to/mosesdecoder/scripts/recaser/train-truecaser.perl -corpus data/train.norm.tok.clean.en -model path/to/truecase-model.en
- 应用apply:将训练得到的英语truecase模型应用到训练集、校验集和测试集的英文上。
perl dir_name/mosesdecoder/scripts/recaser/truecase.perl -model path/to/truecase-model.en < data/train.norm.tok.clean.en > data/train.norm.tok.clean.tc.en
同样德语也需要训练一个truecase模型。
BPE分词
如果想按子词来分词,则要用到BPE算法,在使用BPE算法之前最好先使用moses做数据预处理,然后将moses处理好的数据输入到BPE算法中。
项目链接:
https://github.com/glample/fastBPE
BPE分词一般有以下四个步骤:
learnbpe nCodes input1 [input2] 从1到2个文件中学习 BPE codes
applybpe output input codes [vocab] 应用 BPE codes 对输入文件做分词
getvocab input1 [input2] 从1到2个文件中抽取词汇
applybpe_stream codes [vocab] apply BPE codes to stdin and outputs to stdout
- Learn codes
./fast learnbpe 40000 train.de train.en > codes
从train.de 、train.en两个文件中学习BPE codes并输出到codes文件中,40000为BPE codes的个数(取排名前40000的子词)。
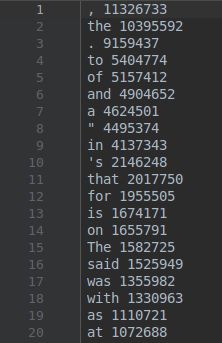
对于使用子词作为基本单位进行训练的神经机器翻译模型,训练的第一步就是根据语料生成bpe的codes资源,以英文为例,该资源会将训练语料以字符为单位进行拆分,按照字符对进行组合,并对所有组合的结果根据出现的频率进行排序,出现频次越高的排名越靠前,排在第一位的是出现频率最高的子词。如图所示:a n为出现频率最高的子词,出现了22968671次,e s< /w>出现了21090192次,其中 < /w> 表示这个s是作为单词结尾的字符。训练过程结束,会生成codes文件。BPE codes的个数为40000,所以codes文件中总共有40000行。codes文件内容如下:

2. Apply codes to train
./fast applybpe train.de.40000 train.de codes
./fast applybpe train.en.40000 train.en codes
通过生成的codes文件,对train.de、train.en分词,生成train.de.40000、 train.en.40000文件。
train.en.40000文件内容如下:

3. Get train vocabulary
./fast getvocab train.de.40000 > vocab.de.40000
./fast getvocab train.en.40000 > vocab.en.40000
./fast getvocab train.de.40000 train.en.40000 > vocab.de-en.40000
从train.de.40000中抽取词汇并保存到vocab.de.40000中。
从train.en.40000中抽取词汇并保存到vocab.en.40000中。
从train.de.40000、train.en.40000中共同抽取词汇并保存到 vocab.de-en.40000中。
vocab.en.40000文件内容如下:
除了上面的方法,还有另外一个开源框架也可以做BPE处理,链接如下:
https://blog.csdn.net/Elenore1997/article/details/89483681
moses用法总结
官网链接:
http://www.statmt.org/moses/?n=Development.GetStarted
- Tokenisation 分词工具:
-
~/mosesdecoder-master/scripts/tokenizer/tokenizer.perl -
命令: -
perl ./tokenizer.perl -no-escape -l zh <./test.zh >. /test.seq.zh -
说明:zh表示中文 -
输入文件:./test.zh -
输出文件:. /test.seq.zh
2.Truecasing 格式转换
-
~/mosesdecoder-master/scripts/recaser/train-truecaser.perl -
命令: -
./ train-truecaser.perl –model ./truecase_model.SRC –corpus . /test.seq.zh -
模型保存文件: ./truecase_model.SRC -
分词后的文本的路径: . /test.seq.zh -
使用上一步生成的模型和分词的文本进行格式转换 -
~/mosesdecoder-master/scripts/recaser/truecase.perl -
./truecase.perl --model ./truecase_model.SRC < . /test.seq.zh > . /test.seq.mx.zh -
说明:./truecase_model.SRC 以上训练的模型路径 -
说明:. /test.seq.zh 以上分词后的文本 -
说明:. /test.seq.mx.zh以上转换后的输出文本
3.Cleaning 处理语句长度+该命令可以一次性处理完双向的两个文件(1-100)
-
~/mosesdecoder-master/scripts/training/clean-corpus-n.perl -
命令: -
./clean-corpus-n.perl . /test.seq.mx zh en . /test.seq.mx.clean 1 100 -
说明: -
以上格式化的文本(源端+目标)的文件名(去除扩展名):. /test.seq.mx -
文件的扩展名(源端+目标):zh en -
输出端的文件(源端+目标)名称: . /test.seq.mx.clean -
句子的长度范围:1 100
4.语言模型训练
-
mkdir ~/lm -
cd ~/lm
5.使用KenLM的构建N-gram的语言模型
-
评估并生成模型 -
~/mosesdecoder/bin/lmplz -
命令: -
./lmplz –o 3 <. /test.seq.mx.clean > . /test.seq.mx.clean.arpa -
处理后的输出文本:. /test.seq.mx.clean -
语言模型生成的文件: . /test.seq.mx.clean.arpa
6.二进制化语言模型文件
-
~/mosesdecoder/bin/build_binary -
命令: -
./ build_binary . /test.seq.mx.clean.arpa . /test.seq.mx.clean. blm -
说明: -
上一步生成的语言模型:. /test.seq.mx.clean.arpa -
转化为二进制的模型文件: . /test.seq.mx.clean. blm
7.查询测试
-
~ /mosesdecoder/bin/query -
命令: -
echo “is this an DeST sentence?” | ./query . /test.seq.mx.clean. blm -
说明: -
对应的脚本: ./query -
以上生成的二进制语言模型. /test.seq.mx.clean. blm
8.翻译系统训练
-
~/mosesdecoder-master/scripts/training/ -
运行的脚本:train-model.perl -
完成九个步骤
9.脚本的参数设置
-
可以选择使用mgiza++替换giza++来加速训练速度 -
mkdir ~/working -
cd ~/working -
命令: nohup nice~/mosesdecoder/scripts/training/train-model.perl \ -root-dir train \ #指明生成目录 -corpus~/corpus/news-commentary-v8.fr-en.clean \ #指明clean语料库文件名(但不包括语言的extension) -f fr -e en \ #指明SRC和 DEST 语言,即语料库文件对应的后缀。 Fr->en的情况下。 -alignment grow-diag-final-and \ #指明单词对齐的启发方法 -reorderingmsd-bidirectional-fe \ #指明specifies which reordering models totrain using a comma-separated list of config-strings -lm0:3:$HOME/lm/news-commentary-v8.fr-en.blm.en:8 \ #语言模型, factory:order:filename -external-bin-dir~/mosesdecoder/tools \ #指明word alignment tools的可执行文件路径 -mgiza \ #从默认的giza++切换成mgiza++ -cores N \ #指明训练过程可以使用的多核数量。加快训练过程。 >& training.out & #log输出 经过训练之后,moses.ini会在 ~/working/train/models下面生成。
10.Tuning :模型调整
-
生成的moses.ini通过有以下两个问题 -
加载速度比较慢, 可以用二进制化来解决 -
moses采用的权值不是最优的 -
因此需要对模型进行调整,这也是整个过程中最慢的一步。tuning需要一些跟训练数据无关的并行数据
11.准备tuning数据
-
下载相应的数据 -
命令: -
cd ~/corpus -
wget http:www.statmt.org/wmt12/dev.tgz -
tar xvzf dev.tgz -
根据SRC&DEST 选择相应的数据包,然后对数据进行分词和格式统一化,例如选择de->en, 找到并选择对应的文件newtest2011.de &newtest2011.en
12.执行tokenize-----(目标语和源语言都要进行)-----分词
-
~/mosesdecoder-master/scripts/tokenizer/ tokenizer.perl -
命令: -
./tokenizer.perl -l zh <. /3.sq.zh > ./3.dv.zh -
说明: -
为刚才以上下载的数据通过分词、格式统一化后的文本: . /3.sq.zh -
输出的文本: ./3.dv.zh
13.执行格式化统一(源端与目标端)
-
truecase.perl -
命令: -
./truecase.perl --model ./truecase_model.SRC <./3.dv.zh >./3.dv._zh -
说明: -
第二步生成的语言模型: ./truecase_model.SRC -
上一步分词后的文本文件: ./3.dv.zh -
格式化后的文本文件: ./3.dv._zh
14.进行调整(源端与目标端)
-
进入目录:cd ~/working -
脚本: mert-moses.pl -
~/mosesdecoder-master/scripts/training/ mert-moses.pl -
命令: nohup nice ./mert-moses.pl \ ./ 3.dv._zh ./3.dv._en \ ~/mosesdecoder/bin/mosestrain/model/moses.ini --mertdir ~/mosesdecoder/bin/ \ &> mert.out & -
说明: -
分别为第13步格式化后的文本文件: ./ 3.dv._zh ./3.dv._en
15.二进制化加速(源端与目标端)
-
对phrase-tableand lexicalised reordering models进行二进制化,加速模型文件的加载 -
脚本: processPhraseTableMin -
路径: ~/mosesdecoder/processPhraseTableMin -
创建文件夹: mkdir~/working/binarised-model -
进入文件中:cd ~/working -
~/mosesdecoder/bin/processPhraseTableMin \ -in train/model/phrase-table.gz -nscores 4 \ -out binarised-model/phrase-table -
说明: -
第九步中第四个时生成的训练文件:train/model/phrase-table.gz -nscores 4 -
刚创建的文件夹用来存储二进制化后的文件:binarised-model/phrase-table -
~/mosesdecoder/bin/processLexicalTableMin \ -intrain/model/reordering-table.wbe-msd-bidirectional-fe.gz \ -out binarised-model/reordering-table -
说明:跟以上一样的
16.然后将mert-work/moses.ini 文件拷贝到binarised-model 文件夹,并phrase & reordering tables 修改指向二进制的文件::
-
Change PhraseDictionaryMemory to PhraseDictionaryCompact -
Set the path of the PhraseDictionary feature to point to $HOME/working/binarised-model/phrase-table.minphr -
Set the path of the LexicalReordering feature to point to $HOME/working/binarised-model/reordering-table
17.https://blog.csdn.net/chrissata/article/details/65632744
18.使用GIZA++进行词对齐
-
下载: git clone https://github.com/moses-smt/giza-pp.git -
进入文件中:cd giza-pp -
编辑:make -
编译完会在GIZA++-v2/和mkcls-v2/目录下生成以下可执行文件: -
plain2snt.out、snt2cooc.out、GIZA++、mkcls -
将这四个程序移动到工作目录workspace(自己创建的工作文件夹中)下: -
文本单词编号: -
命令: ./plain2snt.out zh.txt en.txt -
说明:zh.txt和en.txt分别为分词后的标准的平行语料、必须放在workspace目录下 -
得到en.vcb、zh.vcb、en_zh.snt、zh_en.snt四个文件 -
说明: -
en.vcb / zh.vcb:字典文件,id : token : count -
格式为: 2 海洋 1 3 是 6 4 一个 2 5 非常 2 6 复杂 4 7 的 12 8 事物 1 9 。 7 10 人类 1 ... -
en_zh.snt / zh_en.snt:编号表示句对,第一行表示句对出现次数 1 2 3 4 5 6 7 8 9 2 3 4 5 6 7 8 9 10 11 12 13 1 10 7 11 12 3 13 14 5 6 7 15 9 14 15 4 5 6 7 8 9 10 16 17 18 19 13 说明:第一行表示句对出现的次数 第二行为源端/目标端词语的id 第三行为目标端/源端词语的id
19.生成共现文件
-
命令:(中文-à英文为例) -
./snt2cooc.out zh.vcb en.vcb zh_en.snt > zh_en.cooc -
说明: zh.vcb 和en.vcb分别为以上生成的字典 -
说明:zh_en.snt为以上生成的中文编号 -
说明:zh_en.cooc为生成的英文编号 -
zh_en.cooc / en_zh.cooc 0 33 0 34 0 35 0 36 0 37 0 38 0 39 0 40
20.生成词类
-
命令: -
./mkcls –pzh.txt –Vzh.vcb.classes opt -
./mkcls -pen.txt -Ven.vcb.classes opt -
说明: zh.txt和en.txt为中英文平行语料 zh.vcb.classes和en.vcb.classes分别为中英文输出 注意:文件的名称跟前面的参数连接在一起不能有空 ***** 1 runs. (algorithm:TA)***** ;KategProblem:cats: 100 words: 68 start-costs: MEAN: 262.907 (262.907-262.907) SIGMA:0 end-costs: MEAN: 190.591 (190.591-190.591) SIGMA:0 start-pp: MEAN: 3.52623 (3.52623-3.52623) SIGMA:0 end-pp: MEAN: 1.95873 (1.95873-1.95873) SIGMA:0 iterations: MEAN: 50117 (50117-50117) SIGMA:0 time: MEAN: 1.468 (1.468-1.468) SIGMA:0 -
参数说明: -c 词类数目 -n 优化次数,默认是1,越大越好 -p 输入文件 -V 输出文件 opt 优化输出 -
en.vcb.classes / zh.vcb.classes:单词所属类别编号 , 26 . 28 : 64 And 29 I 13 If 52 It 49 a 34 about 22 ... -
en.vcb.classes.cats / zh.vcb.classes.cats:类别所拥有的一组单词 0:$, 1: 2:science, 3:seem, 4:things, 5:some, 6:start, 7:task, ...
21.GIZA++
-
先在当前目录新建两个输出文件夹z2e、e2z,否则下面的程序会出错,没有输出。 -
命令: -
$ ./GIZA++ -S zh.vcb -T en.vcb -C zh_en.snt -CoocurrenceFile zh_en.cooc -o z2e -OutputPath z2e -
$ ./GIZA++ -S en.vcb -T zh.vcb -C en_zh.snt -CoocurrenceFile en_zh.cooc -o e2z -OutputPath e2z -
说明: -
z2e.perp 困惑度 -
z2e.A3.final:i j l m p(i/j, l, m):i代表源语言Token位置;j代表目标语言Token位置;l代表源语言句子长度;m代表目标语言句子长度;p(i/j, l, m)代表在一对长度为l和m的句子中,位置i的源单词移动到位置j的概率. 0 2 100 8 0.0491948 0 6 100 8 0.950805 -
z2e.d3.final:类似于z2e.a3.final文件,只是交换了i 和 j 的位置 2 0 100 8 0.0491948 6 0 100 8 0.950805 -
z2e.n3.final:source_id p0 p1 p2 … pn;源语言Token的Fertility分别为0,1,…,n时的概率表,比如p0是Fertility为0时的概率。 2 1.22234e-05 0.781188 0.218799 0 0 0 0 0 0 0 3 0.723068 0.223864 0 0.053068 0 0 0 0 0 0 -
z2e.t3.final:s_id t_id p(t_id/s_id); IBM Model 3训练后的翻译表;p(t_id/s_id)表示源语言Token翻译为目标语言Token的概率 0 3 0.196945 0 7 0.74039 0 33 0.0626657 -
z2e.A3.final 单向对齐文件,数字代表Token所在句子位置(1为起点) # Sentence pair (1) source length 8 target length 11 alignment score : 8.99868e-08 It can be a very complicated thing , the ocean . NULL ({ 8 }) 海洋 ({ 1 }) 是 ({ 4 }) 一个 ({ 9 }) 非常 ({ 3 6 7 }) 复杂 ({ 2 5 }) 的 ({ }) 事物 ({ 10 }) 。 ({ 11 }) # Sentence pair (2) source length 12 target length 14 alignment score : 9.55938e-12 And it can be a very complicated thing , what human health is . NULL ({ 9 }) 人类 ({ 2 11 }) 的 ({ }) 健康 ({ 12 }) 也 ({ }) 是 ({ 5 }) 一 ({ }) 件 ({ 13 }) 非常 ({ 4 7 8 }) 复杂 ({ 3 6 }) 的 ({ }) 事情 ({ 1 10 }) 。 ({ 14 }) ... -
z2e.d4.final:IBM Model 4 翻译表 # Translation tables for Model 4 . # Table for head of cept. F: 20 E: 26 SUM: 0.125337 9 0.125337 F: 20 E: 15 SUM: 0.0387214 -2 0.0387214 F: 20 E: 24 SUM: 0.0387214 21 0.0387214 ... -
z2e.D4.final:IBM Model 4的Distortion表 26 20 9 1 15 20 -2 1 24 20 21 1 2 20 -2 1 40 20 -4 1 22 20 -3 0.0841064 22 20 9 0.915894 32 20 28 1 21 20 24 1 29 2 -3 0.472234 29 2 1 0.527766 5 2 1 0.475592 ... -
z2e.gizacfg:GIZA++配置文件,超参数 adbackoff 0 c zh_en.snt compactadtable 1 compactalignmentformat 0 -
z2e.Decoder.config:用于ISI Rewrite Decoder解码器
22.词对齐对称化
-
下载python脚本: https://github.com/Lynten/smt -
或者在working目录下: git clone https://github.com/Lynten/smt.git -
上面的得到的*.A3.final文件是单向对齐的,我们这里需要对称化,对称化方法有很多,我们这里使用最流行的“grow-diag-final-and”方法 -
命令(以下脚本在smt中)—运行在working文件夹下: -
python align_sym.py e2z.A3.final z2e.A3.final > aligned.grow-diag-final-and -
说明: -
在e2z目录下生成的文件: e2z.A3.final -
在z2e目录下生成的文件: z2e.A3.final
23.Bleu值打分
-
~/mosesdecoder-master/scripts/generic/ multi-bleu.perl -
命令: -
perl ./multi-bleu.perl -lc ./ref.en < ./mbt.en > ./mbt2.score -
./ref.en < 参考文件 -
./mbt.en > 文件预处理文件(去除等)) -
./mbt2.score具体的结果(获取)结果只有一行
24.TER值
-
~/tercom-0.7.25 -
java -jar ./tercom.7.25.jar -r referencefile -h testfile > resultfile -
Referencefile(参考文路径)(表示:原始数据 结果1) -
testfile (翻译预处理后的测试文件路径)(表示:结果2) -
resultfile (结果文件)(获取:) (倒数第4行的数据)
25.训练
-
~/mosesdecoder-master/scripts/training -
train-model.perl -
运行培训脚本: -
train-model.perl -root-dir。--corpus corpus / euro --f de - en -
在corpus目录中存在两个文件分别为:euro.de和euro.en的平行语料文件。de表示德语、en表示英语
26.小写
-
lowercase.perl
27.清理语料库
-
clean-corpus-n.perl