2021刷新COCO和Cityscapes | Polarized Self-Attention:极化自注意力机制(keras实现)

Polarized Self-Attention: Towards High-quality Pixel-wise Regression
paper:https://arxiv.org/pdf/2107.00782.pdf
code:https://github.com/DeLightCMU/PSA
摘要
像素级回归是细粒度计算机视觉任务中最常见的问题,如估计关键点热图和分割掩模。这些回归问题非常具有挑战性,特别是因为它们需要在低计算开销下,建模对高分辨率输入/输出的长期依赖关系来估计高度非线性的像素语义。虽然深度卷积神经网络(DCNNs)中的注意机制已经因增强长期依赖而流行,但元素特定的注意,如非局部块,学习高度复杂和噪声敏感,大多数简化的注意力混合试图在多种类型的任务中达到最佳的折衷。在本文中,提出了极化自注意(PSA)块,它包含了两个高质量像素回归:
(1)极化滤波:在通道和空间注意计算中保持高内部分辨率,同时沿其对应维度完全折叠输入张量。
(2)增强:组成非线性,直接适合典型的细粒度回归的输出分布,如二维高斯分布(关键点热图),或二维二项分布(二进制分割掩模)。
PSA似乎已经耗尽了其仅通道和仅空间分支内的表示能力,因此其串行和并行布局之间只有边际度量差异。
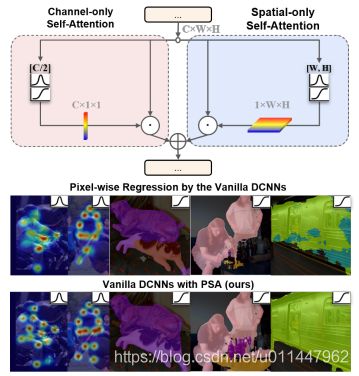
论文背景
注意机制广泛应用于图像分类、目标检测、实例分割。具体来说,注意方法有两种类型,分别是通道注意和空间注意。通道注意力机制如SE、ECANett等,仅通过通道不同权重,但对不同的空间位置施加相同的权重。因此分类任务由于其空间信息最终通过池化而崩溃。随着空间和通道注意力机制的提出,很自然的,结合空间和通道两个维度的双重注意力机制也被提出如DANet、CBAM。该论文提出了一种更加精细的双重注意力机制——极化自注意力(Polarized Self-Attention)。在通道和空间维度保持比较高的resolution(在通道上保持C/2的维度,在空间上保持[H,W]的维度 ),这一步能够减少降维度造成的信息损失,并且采用细粒度回归输出分布的非线性函数。作为一个即插即用的模块,在人体姿态估计和语义分割任务上,作者将它用在了以前的SOTA模型上,并达到了新的SOTA性能。
论文主要思想

提出极化自注意力(PSA),分为两个之路,一个分支做通道维度的自注意力机制,另一个分支做空间维度的自注意力机制,最后将这两个的分支的结果进行融合,得到极化自注意力结构的输出。极化注意力机制有两种模式一种是串联型(mode='s'),另一种是并联型(mode='p')。
通道维度注意力机制
先用了1x1的卷积将输入的特征X转换成了q和v,其中q的通道被完全压缩,而v的通道维度依旧保持在一个比较高的水平(C/2)。因为q的通道维度被压缩,就需要通过HDR进行信息的增强,因此作者用Softmax对q的信息进行了增强。然后将q和k进行矩阵乘法,并在后面接上1x1卷积、LN将通道上C/2的维度升为C(原始代码还加了一个1x1卷积)。最后用Sigmoid函数使得所有的参数都保持在0-1之间。
空间维度注意力机制
作者先用了1x1的卷积将输入的特征转换为了q和v,其中,对于q特征,作者还用了GlobalPooling对空间维度压缩,转换成了1x1的大小;而v特征的空间维度则保持在一个比较大的水平(HxW)。由于q的空间维度被压缩了,所以作者就用了Softmax对q的信息进行增强。然后将q和K进行矩阵乘法,然后接上reshape和Sigmoid使得所有的参数都保持在0-1之间。
Keras实现
以下是根据论文和pytorch源码实现的keras版本(支持Tensorflow1.x)。
注:安装LayerNormlization模块 pip install keras-layer-normalization
PSA模块
def _PSA(x, mode='p'):
context_channel = spatial_pool(x, mode)
if mode == 'p':
context_spatial = channel_pool(x)
out = Add()([context_spatial, context_channel])
elif mode == 's':
out = channel_pool(context_channel)
else:
out = x
return out通道注意力机制
def spatial_pool(x, mode, ratio=4):
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
if channel_axis == -1:
batch, height, width, channels = K.int_shape(x)
assert channels % 2 == 0
channel = channels//2
input_x = Conv2D(channel, kernel_size=1, strides=1, padding='same', use_bias=False, kernel_initializer='he_normal')(x)
input_x = Reshape((width*height, channel))(input_x)
context_mask = Conv2D(1, kernel_size=1, strides=1, padding='same', use_bias=False, kernel_initializer='he_normal')(x)
context_mask = Reshape((width*height, 1))(context_mask)
context_mask = Softmax(axis=1)(context_mask)
context = Lambda(lambda x: tf.matmul(x[0], x[1], transpose_a=True))([input_x, context_mask])
context = Permute((2, 1))(context)
context = Reshape((1, 1, channel))(context)
else:
batch, channels, height, width = K.int_shape(x)
assert channels % 2 == 0
channel = channels // 2
input_x = Conv2D(channel, kernel_size=1, strides=1, padding='same', use_bias=False,
kernel_initializer='he_normal')(x)
input_x = Reshape((channel, width * height))(input_x)
context_mask = Conv2D(1, kernel_size=1, strides=1, padding='same', use_bias=False,
kernel_initializer='he_normal')(x)
context_mask = Reshape((width * height, 1))(context_mask)
context_mask = Softmax(axis=1)(context_mask)
context = Lambda(lambda x: tf.matmul(x[0], x[1]))([input_x, context_mask])
context = Reshape((channel, 1, 1))(context)
if mode == 'p':
context = Conv2D(channels, kernel_size=1, strides=1, padding='same')(context)
else:
context = Conv2D(channel // ratio, kernel_size=1, strides=1, padding='same')(context)
context = LayerNormalization()(context) # pip install keras-layer-normalization
context = Conv2D(channels, kernel_size=1, strides=1, padding='same')(context)
mask_ch = Activation('sigmoid')(context)
return Multiply()([x, mask_ch])
空间注意力机制
def channel_pool(x):
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
if channel_axis == -1:
batch, height, width, channels = K.int_shape(x)
assert channels % 2 == 0
channel = channels//2
g_x = Conv2D(channel, kernel_size=1, strides=1, padding='same', use_bias=False, kernel_initializer='he_normal')(x)
avg_x = GlobalAvgPool2D()(g_x)
avg_x = Softmax()(avg_x)
avg_x = Reshape((channel, 1))(avg_x)
theta_x = Conv2D(channel, kernel_size=1, strides=1, padding='same', use_bias=False, kernel_initializer='he_normal')(x)
theta_x = Reshape((height*width, channel))(theta_x)
context = Lambda(lambda x: tf.matmul(x[0], x[1]))([theta_x, avg_x])
context = Reshape((height*width,))(context)
mask_sp = Activation('sigmoid')(context)
mask_sp = Reshape((height, width, 1))(mask_sp)
else:
batch, channels, height, width = K.int_shape(x)
assert channels % 2 == 0
channel = channels//2
g_x = Conv2D(channel, kernel_size=1, strides=1, padding='same', use_bias=False, kernel_initializer='he_normal')(x)
avg_x = GlobalAvgPool2D()(g_x)
avg_x = Softmax()(avg_x)
avg_x = Reshape((1, channel))(avg_x)
theta_x = Conv2D(channel, kernel_size=1, strides=1, padding='same', use_bias=False, kernel_initializer='he_normal')(x)
theta_x = Reshape((channel, height*width))(theta_x)
context = Lambda(lambda x: tf.matmul(x[0], x[1]))([avg_x, theta_x])
context = Reshape((height*width,))(context)
mask_sp = Activation('sigmoid')(context)
mask_sp = Reshape((1, height, width))(mask_sp)
return Multiply()([x, mask_sp])声明:本内容来源网络,版权属于原作者,图片来源原论文。如有侵权,联系删除。
创作不易,欢迎大家点赞评论收藏关注!(想看更多最新的注意力机制文献欢迎关注浏览我的博客)