随机森林算法实现--R语言:randomForest函数
一、随机模型的介绍
在随机森林方法中,创建了大量的决策树。每个观察结果都被送入每个决策树。 每个观察结果最常用作最终输出。对所有决策树进行新的观察,并对每个分类模型进行多数投票。
- 随机森林首先是一种并联的思想,同时创建多个树模型,它们之间是不会有任何影响的,使用相同参数,只是输入不同。
- 为了满足多样性的要求,需要对数据集进行随机采样,其中包括样本随机采样与特征随机采样,目的是让每一棵树都有个性。
- 将所有的树模型组合在一起。在分类任务中,求众数就是最终的分类结果;在回归任务中,直接求平均值即可。
二、随机森林模型建立
1.首先是数据采样的随机:将数据集分为训练集和测试集,均从总数据集中随机抽样。
data1<-iris#加载数据集
data2<-na.omit(data1)#删除空缺值
trainlist<-sample(nrow(data2),7/10*nrow(data2))#将数据集划分为7:3
train_data<-data2[trainlist,]
test_data<-data2[-trainlist,]2.其次是考虑特征的随机性:寻找当特征数为多少时,模型的误判率均值最小。
install.packages("randomForest")
library("randomForest")
rate<-1#设置模型误判率向量初始值
n<-ncol(train_data)
for(i in 1:(n-1))
{
set.seed(1234)
rf_train<-randomForest(as.factor(train_data$Species)~.,data=train_data,
mtry=i,importance=T,proximity=T,ntree=1000)
rate[i]<-mean(rf_train$err.rate) #计算基于OOB数据的模型误判率均值
}
plot(rate)#可知当特征选取3时,模型误判率的均值最小由结果可知,当特征数选取3时,模型误判率均值最小。
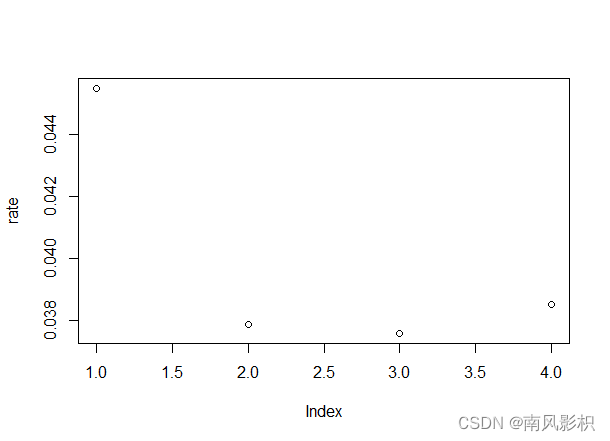
3.构建随机森林模型:将特征值定为3,树模型的个数并不是越多越好,当树模型个数达到一定数值后,整体效果趋于稳定,若建立太多树模型,会导致整体的准确率下降。
set.seed(1000)
rf_train<-randomForest(as.factor(train_data$Species)~.,data=train_data,
mtry=3,importance=T,proximity=T,ntree=500)
plot(rf_train) #绘制模型误差与决策树数量关系图
importance(rf_train,type=2)#计算平均最小基尼指数
importance(rf_train,type=1)#计算平均准确度下降指数
varImpPlot(rf_train, main = "variable importance")#使用图形的方式对指标的重要性进行可视化平均最小基尼系数表示随机森林预测准确性的降低程度,该值越大表示该变量的重要性越大。
平均准确率下降指数表示每个变量对分类树每个节点上观测值的异质性的影响,该值越大表示该变量的重要性越大。
由图可知,Petal.Width的两项指标均最大,所以Petal.Width的重要性最大;随着决策树的数量增加,模型误差趋于稳定。
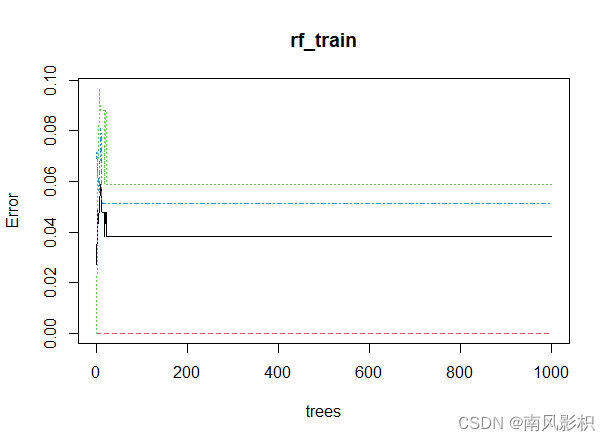
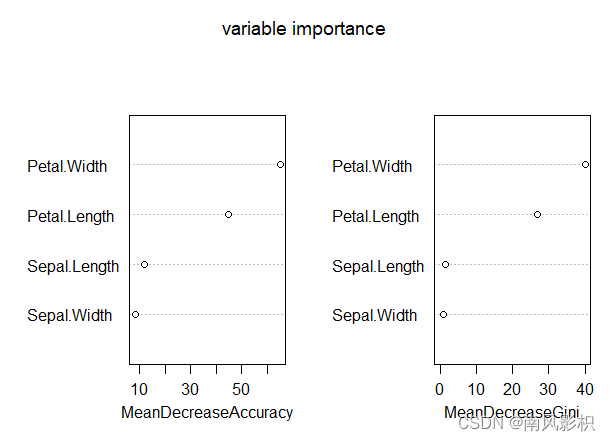
print(rf_train)#展示随机森林模型简要信息
hist(treesize(rf_train))#展示随机森林模型中每棵决策树的节点数
MDSplot(rf_train,train_data$Species,palette=rep(1,3),pch=as.numeric(train_data$Species),
main="二维情况下各类别的具体分类情况")#展示数据集在二维情况下各类别的具体分布情况
barplot(rf_train$importance[,1],main="输入变量重要性测度指标柱形图")
box()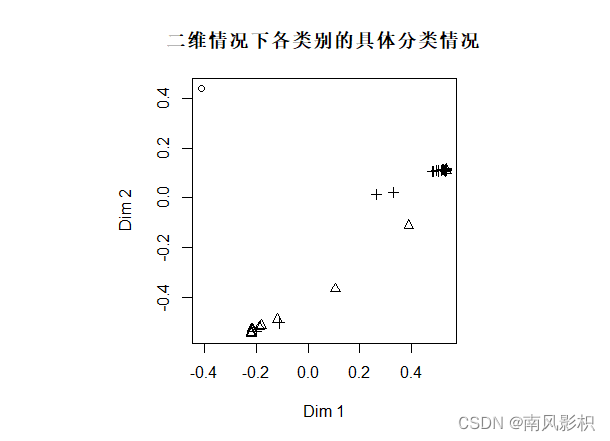

4. 利用测试集进行预测,并计算预测的准确率。可知预测准确率为93.33%,可认为预测效果较好。
pred<-predict(rf_train,newdata=test_data)#利用训练集进行预测
pred_out_1<-predict(object=rf_train,newdata=test_data,type="prob")#输出概率
table <- table(pred,test_data$Species,dnn=c("预测值","真实值"))#输出混淆矩阵
sum(diag(table))/sum(table)#计算预测准确率
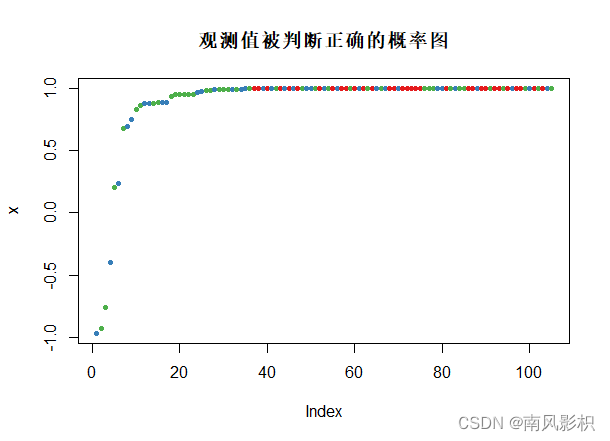
plot(margin(rf_train,test_data$Species),main="观测值被判断正确的概率图")
5.利用pROC安装包来绘制ROC曲线,ROC曲线与横坐标轴所围成面积越大,说明模型的判错率越小。由于ROC曲线仅能用于二分类结果,而iris数据集的Species中有三个水平( setosa、virginica、versicolor),因此需要先处理数据,再绘制ROC曲线。
h<-test_data
h$label[h$Species=='setosa']<-1
h$label[h$Species=='virginica']<-0
h<-h[-which(h$Species == 'versicolor')]#剔除类型为versicolor的数据
h$Species<-NULL#去除Species列
head(h,10)#显示前10个数据
pred<-as.numeric(pred)
pred[pred==2]<-1
ran_roc<-roc(h$label,pred)
plot(ran_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),
grid.col=c("green", "red"),max.auc.polygon=TRUE,auc.polygon.col="skyblue",
print.thres=TRUE,main='随机森林模型ROC曲线')#绘制ROC曲线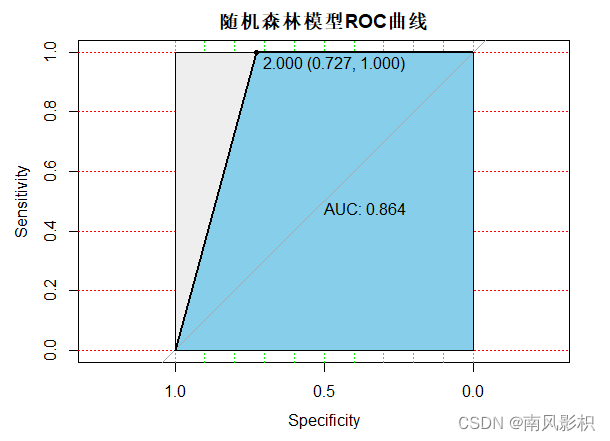
以上就是本文的全部内容,欢迎读者批评指正。
随机森林定义摘自:http://t.csdn.cn/kHjtQ
ROC曲线参考:http://t.csdn.cn/51re0