卷积序列到序列模型的学习(Convolutional Sequence to Sequence Learning)
文章目录
-
- Introduction
- 数据预处理
- 搭建模型
-
- Encoder
- Convolutional Blocks
- Encoder的实现
- Decoder
- Decoder Convolutional Blocks
- Decoder的实现
- Seq2Seq
- 训练模型
- 推断
- BELU
- 完整代码
在本笔记本中,我们将实现论文Convolutional Sequence to Sequence Learning模型。
Introduction
这个模型与之前笔记中使用的先前模型有很大的不同。根本没有使用任何循环的组件。相反,它使用通常用于图像处理的卷积层。
简而言之,卷积层使用了过滤器。这些过滤器有一个宽度(在图像中也有一个高度,但通常不是文本)。如果一个过滤器的宽度为3,那么它可以看到3个连续的标记。每个卷积层都有许多这样的过滤器(本教程中是1024个)。每个过滤器将从开始到结束滑过序列,一次查看所有3个连续的标记。其思想是,这1024个过滤器中的每一个都将学习从文本中提取不同的特征。这个特征提取的结果将被模型使用——可能作为另一个卷积层的输入。然后,这些都可以用来从源句子中提取特征,将其翻译成目标语言。
数据预处理
首先,让我们导入所有必需的模块,并为可重复性设置随机种子。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
接下来,我们将加载spaCy模块,并为源语言和目标语言定义标记器。
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
接下来,我们将设置决定如何处理数据的字段。默认情况下,PyTorch中的RNN模型要求序列是一个[src_len,批batch_size]形状的张量,因此TorchText将默认返回一批相同形状的张量。然而,在本笔记中,我们使用的CNN期望batch_size是第一个。通过设置batch_first = True,我们告诉TorchText将batch设置为[batch_size,src_len]。
我们还附加了序列标记的开始和结束,并对所有文本进行小写。
SRC = Field(tokenize = tokenize_de,
init_token = '' ,
eos_token = '' ,
lower = True,
batch_first = True)
TRG = Field(tokenize = tokenize_en,
init_token = '' ,
eos_token = '' ,
lower = True,
batch_first = True)
然后,我们加载数据集。
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'),
fields=(SRC, TRG))
我们像以前一样构建词汇表,将出现次数少于2次的任何标记转换为《unk》标记。
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
最后一点数据准备是定义device,然后构建迭代器。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
搭建模型
接下来是构建模型。与之前一样,该模型由编码器和解码器组成。编码器用源语言将输入句子编码成上下文向量。解码器对上下文向量进行解码,以生成目标语言的输出句子。
Encoder
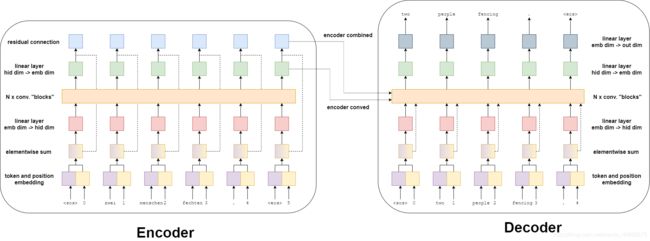
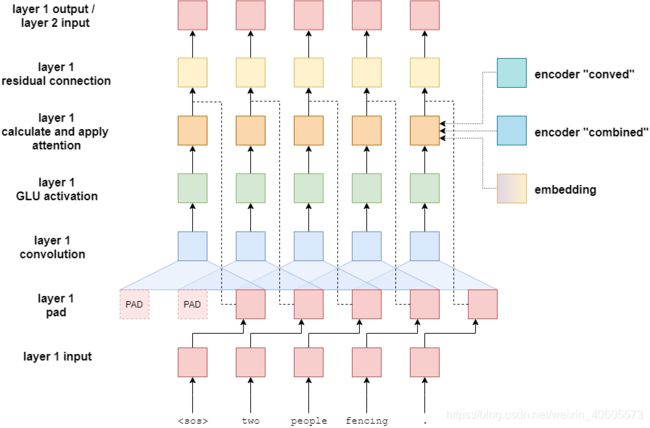
这些教程中以前的模型有一个编码器,它可以将整个输入句子压缩到单个上下文向量 z z z中。卷积序列到序列模型有一点不同——它为输入句子中的每个标记获得两个上下文向量。因此,如果我们的输入句子有6个标记,我们将得到12个上下文向量,每个标记两个有两个上下文向量。
每个标记的两个上下文向量是一个卷积向量(conved vector)和一个组合向量(combined vector)。conved向量是每个标记通过几个层传递的结果——我们稍后将对此进行解释。combined向量来自于卷积向量和该标记的embedding的和。这两个都由编码器返回,由解码器使用。
下图显示了输入句子zwei menschen fechten的结果。-通过编码器传递。
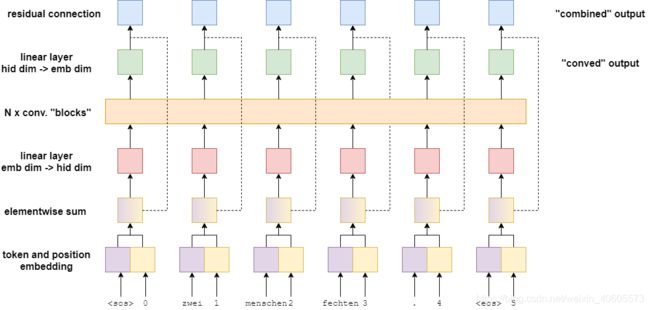
首先,token通过标记嵌入层传递——这是自然语言处理中的神经网络的标准。然而,由于该模型中没有循环的连接,因此不知道序列中标记的顺序。为了纠正这一点,我们有第二个嵌入层,位置嵌入层。这是一个标准的嵌入层,其中的输入不是标记本身,而是标记在序列中的位置——从第一个标记《sos》(序列开始)标记开始,位置为0。
接下来,将标记和位置嵌入元素相加得到一个向量,该向量包含关于标记及其在序列中的位置的信息——我们简单地称之为嵌入向量。随后是一个线性层,它将嵌入向量转换成具有所需隐藏维度大小的向量。
下一步是将这个隐藏向量传递到 N N N卷积块中。这就是这个模型中发生“魔法”的地方,我们稍后将详细介绍卷积块的内容。经过卷积块后,向量传入另一个线性层,将其从隐藏维数大小转换回嵌入维数大小。这是我们的卷积向量(conved vector)------在输入序列中每个标记卷积后都会有一个。
最后,通过残差连接将卷积向量(conved vector)与嵌入向量(embedding vector)进行元素相加,得到每个标记的组合向量(combined vector)。同样,输入序列中的每个标记都有一个组合向量(combined vector)。
Convolutional Blocks
那么,这些卷积块是如何工作的呢?下图显示了两个卷积块,其中一个过滤器(蓝色)在序列中的标记上滑动。在实际的实现中,我们将有10个卷积块,每个块中有1024个过滤器。
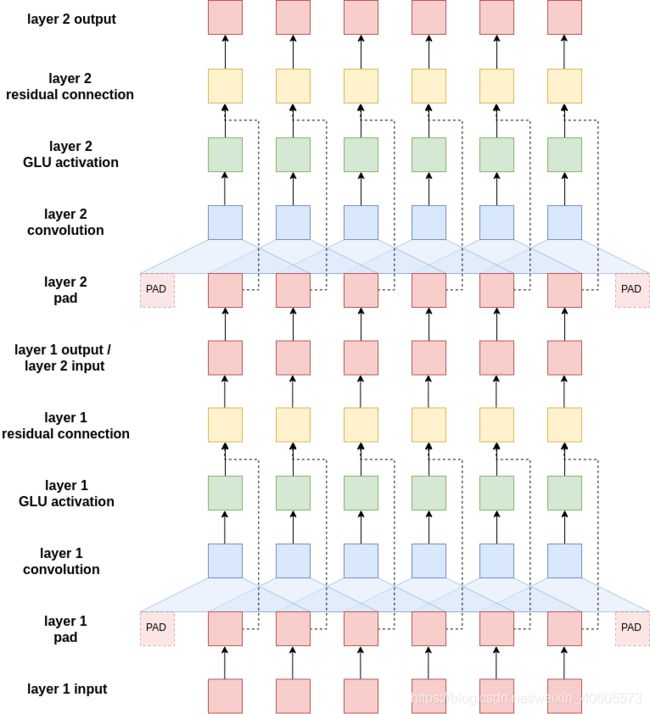
首先,填充输入句子。这是因为卷积层将减少输入句子的长度,我们希望进入卷积块的句子的长度等于从卷积块中出来的句子的长度。如果没有填充,从卷积层出来的序列的长度将比进入卷积层的序列短filter_size - 1。例如,如果我们的过滤器大小为3,那么序列将短2个元素。因此,我们在句子的每一侧都填充一个padding元素。对于奇数大小的过滤器,我们可以通过简单的操作(filter_size - 1)/2来计算两边的填充量,在本教程中我们将不涉及偶数大小的过滤器。
这些过滤器的设计使其输出隐藏维数是输入隐藏维数的两倍。在计算机视觉术语中,这些隐藏的维度被称为通道——但我们将坚持称它们为隐藏的维度。为什么我们要把隐藏维度的大小增加一倍来离开卷积滤波器?这是因为我们使用了一种特殊的激活函数,叫做门控线性单元(GLU)。GLUs有门控机制(类似于LSTMs和GRUs),包含在激活函数中,实际上是隐藏维度大小的一半——而激活函数通常保持隐藏维度的大小相同。
经过GLU激活后,每个标记的隐藏维度大小与进入卷积块时相同。在经过卷积层之前,它现在与自己的向量进行元素级求和。
这就得到了一个单独的卷积块。后续块获取前一个块的输出并执行相同的步骤。每个块都有自己的参数,它们不会在块之间共享。最后一个块的输出返回到主编码器——在那里它通过线性层被馈入以得到卷积(conved)输出,然后与标记的嵌入(embedding)元素累加以得到组合(combined)输出。
Encoder的实现
为了使实现简单,我们只允许奇数大小的卷积核。这允许将填充相等地添加到源序列的两边。
研究人员使用这个尺度(scale)变量来“确保整个网络的方差不会发生显著变化”。如果不使用不同的种子,模型的性能似乎会有很大的不同。
位置嵌入被初始化为100的“词汇表”。这意味着它可以处理长度为100个元素的序列,索引范围从0到99。如果在具有更长的序列的数据集上使用,这个值可以增加。
class Encoder(nn.Module):
def __init__(self,
input_dim,
emb_dim,
hid_dim,
n_layers,
kernel_size,
dropout,
device,
max_length = 100):
super().__init__()
assert kernel_size % 2 == 1, "Kernel size must be odd!"
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(input_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_length, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim,
out_channels = 2 * hid_dim,
kernel_size = kernel_size,
padding = (kernel_size - 1) // 2)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [batch size, src len]
batch_size = src.shape[0]
src_len = src.shape[1]
#create position tensor
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [0, 1, 2, 3, ..., src len - 1]
#pos = [batch size, src len]
#embed tokens and positions
tok_embedded = self.tok_embedding(src)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = pos_embedded = [batch size, src len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, src len, emb dim]
#pass embedded through linear layer to convert from emb dim to hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, src len, hid dim]
#permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, src len]
#begin convolutional blocks...
for i, conv in enumerate(self.convs):
#pass through convolutional layer
conved = conv(self.dropout(conv_input))
#conved = [batch size, 2 * hid dim, src len]
#pass through GLU activation function
conved = F.glu(conved, dim = 1)
#conved = [batch size, hid dim, src len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, src len]
#set conv_input to conved for next loop iteration
conv_input = conved
#...end convolutional blocks
#permute and convert back to emb dim
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, src len, emb dim]
#elementwise sum output (conved) and input (embedded) to be used for attention
combined = (conved + embedded) * self.scale
#combined = [batch size, src len, emb dim]
return conved, combined
Decoder
解码器接收实际的目标句子并试图预测它。这个模型不同于前面在这些教程中详细介绍的循环神经网络模型,因为它可以并行地预测目标句子中的所有标记。没有顺序处理,也就是说没有解码循环。这将在后面的教程中进一步详细说明。
解码器与编码器类似,只是对主要模型和模型内的卷积块做了一些修改。
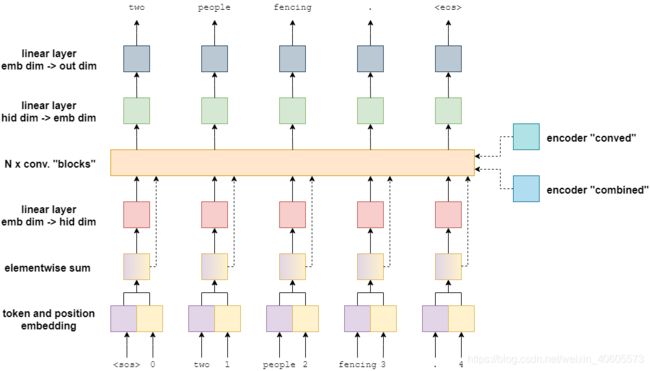
首先,在卷积块和变换之后,嵌入没有进行残差连接。相反,嵌入被送入卷积块中,在那里进行剩差连接使用。
其次,为了往编码器输入解码器信息,在卷积块内使用编码器的卷积输出(conved)和组合(combined)输出。
最后,解码器的输出是一个从嵌入维度变换到输出维度的线性层。这是用来预测翻译中的下一个单词应该是什么。
Decoder Convolutional Blocks
同样,这些与编码器中的卷积块相似,只是做了一些修改。
首先,进行的是填充。为了确保句子的长度始终一致,我们只在句子的开头填充,而不是在每一侧均匀填充。由于我们并行而不是顺序地同时处理所有目标标记,所以我们需要一种方法,只允许过滤器将token i i i转换为只查看单词 i i i之前的token。如果允许它们查看token i + 1 i+1 i+1(它们应该输出的token),模型将通过直接复制它来学习输出序列中的下一个单词,而不需要实际学习如何翻译。
让我们看看如果我们不正确地在每一边等量填充会发生什么,就像我们在编码器中做的那样。
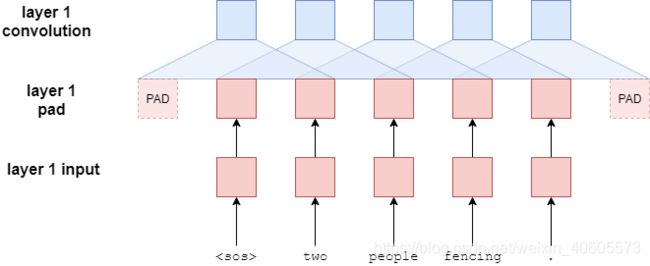
第一个位置的过滤器尝试使用序列中的第一个单词《sos》来预测第二个单词two,现在可以直接看到单词two。这对于每个位置都是一样的,模型试图预测的单词是过滤器覆盖的第二个元素。因此,过滤器可以学习简单地复制每个位置上的第二个单词,从而实现完美的翻译,而不必真正学习如何翻译。
第二,在GLU激活后,在残差连接之前,该区块计算并应用注意力-使用编码表示和嵌入当前单词。注意:我们只显示到最右边标记的连接,但它们实际上连接到所有标记——这样做是为了清楚。每个标记输入都使用自己的,且仅使用自己的,嵌入自己的注意力计算。
注意力计算首先使用一个线性层改变Decoder传入的conved的隐藏维数为相同的嵌入维数。然后,再与嵌入(embedded)通过一个残差连接求和。然后,通过发现它与编码的卷积(conved)有多少“匹配”,然后再通过对编码的组合(combined)进行加权和,这样应用标准注意力计算。然后将其投影回隐藏的维度大小,并应用与注意力层初始输入(conved)的残差连接。
为什么他们首先用编码的卷积(conved)来计算注意力然后用它来通过编码的组合(combined)计算加权和?论文认为,编码后的卷积(conved)有助于在编码序列上获得更大的上下文,而编码后的组合(combined)具有更多关于特定标记的信息,因此更有助于进行预测。
Decoder的实现
由于我们只在一边填充,解码器允许使用奇数和偶数大小的填充。再一次,scale被用来减小整个模型的方差,位置嵌入被初始化为100的“词汇表”。
该模型在其forward方法中接受编码器的表示(encoder_conved和encoder_combined),并将两者传递给calculate_attention方法,该方法计算和应用注意力。它还返回实际的注意力值,但我们目前没有使用它们。
class Decoder(nn.Module):
def __init__(self,
output_dim,
emb_dim,
hid_dim,
n_layers,
kernel_size,
dropout,
trg_pad_idx,
device,
max_length = 100):
super().__init__()
self.kernel_size = kernel_size
self.trg_pad_idx = trg_pad_idx
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(output_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_length, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_emb2hid = nn.Linear(emb_dim, hid_dim)
self.fc_out = nn.Linear(emb_dim, output_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim,
out_channels = 2 * hid_dim,
kernel_size = kernel_size)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def calculate_attention(self, embedded, conved, encoder_conved, encoder_combined):
#embedded = [batch size, trg len, emb dim]
#conved = [batch size, hid dim, trg len]
#encoder_conved = encoder_combined = [batch size, src len, emb dim]
#permute and convert back to emb dim
conved_emb = self.attn_hid2emb(conved.permute(0, 2, 1))
#conved_emb = [batch size, trg len, emb dim]
combined = (conved_emb + embedded) * self.scale
#combined = [batch size, trg len, emb dim]
energy = torch.matmul(combined, encoder_conved.permute(0, 2, 1))
#energy = [batch size, trg len, src len]
attention = F.softmax(energy, dim=2)
#attention = [batch size, trg len, src len]
attended_encoding = torch.matmul(attention, encoder_combined)
#attended_encoding = [batch size, trg len, emd dim]
#convert from emb dim -> hid dim
attended_encoding = self.attn_emb2hid(attended_encoding)
#attended_encoding = [batch size, trg len, hid dim]
#apply residual connection
attended_combined = (conved + attended_encoding.permute(0, 2, 1)) * self.scale
#attended_combined = [batch size, hid dim, trg len]
return attention, attended_combined
def forward(self, trg, encoder_conved, encoder_combined):
#trg = [batch size, trg len]
#encoder_conved = encoder_combined = [batch size, src len, emb dim]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
#create position tensor
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, trg len]
#embed tokens and positions
tok_embedded = self.tok_embedding(trg)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = [batch size, trg len, emb dim]
#pos_embedded = [batch size, trg len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, trg len, emb dim]
#pass embedded through linear layer to go through emb dim -> hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, trg len, hid dim]
#permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, trg len]
batch_size = conv_input.shape[0]
hid_dim = conv_input.shape[1]
for i, conv in enumerate(self.convs):
#apply dropout
conv_input = self.dropout(conv_input)
#need to pad so decoder can't "cheat"
padding = torch.zeros(batch_size,
hid_dim,
self.kernel_size - 1).fill_(self.trg_pad_idx).to(self.device)
padded_conv_input = torch.cat((padding, conv_input), dim = 2)
#padded_conv_input = [batch size, hid dim, trg len + kernel size - 1]
#pass through convolutional layer
conved = conv(padded_conv_input)
#conved = [batch size, 2 * hid dim, trg len]
#pass through GLU activation function
conved = F.glu(conved, dim = 1)
#conved = [batch size, hid dim, trg len]
#calculate attention
attention, conved = self.calculate_attention(embedded,
conved,
encoder_conved,
encoder_combined)
#attention = [batch size, trg len, src len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, trg len]
#set conv_input to conved for next loop iteration
conv_input = conved
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, trg len, emb dim]
output = self.fc_out(self.dropout(conved))
#output = [batch size, trg len, output dim]
return output, attention
Seq2Seq
封装的Seq2Seq模块与以前的笔记中使用的循环神经网络方法有很大的不同,特别是在解码方面。
我们的trg将《eos》元素从序列末尾切掉。这是因为我们没有在解码器中输入《eos》标记。
编码类似,插入源序列并接收“上下文向量”。但是,在源序列中,每个单词都有两个上下文向量,encoder_conved和encoder_combined。
由于解码是并行完成的,我们不需要一个解码循环。所有的目标序列都一次性输入到解码器中,并且填充用于确保解码器中的每个卷积过滤器在序列滑过句子时只能看到序列中的当前和之前的标记。
然而,这也意味着我们不能使用这个模型来做teacher forcing。我们没有一个循环,在这个循环中,我们可以选择是在序列中输入预测的标记还是实际的标记,因为所有事情都是并行预测的。
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg):
#src = [batch size, src len]
#trg = [batch size, trg len - 1] ( token sliced off the end)
#calculate z^u (encoder_conved) and (z^u + e) (encoder_combined)
#encoder_conved is output from final encoder conv. block
#encoder_combined is encoder_conved plus (elementwise) src embedding plus
# positional embeddings
encoder_conved, encoder_combined = self.encoder(src)
#encoder_conved = [batch size, src len, emb dim]
#encoder_combined = [batch size, src len, emb dim]
#calculate predictions of next words
#output is a batch of predictions for each word in the trg sentence
#attention a batch of attention scores across the src sentence for
# each word in the trg sentence
output, attention = self.decoder(trg, encoder_conved, encoder_combined)
#output = [batch size, trg len - 1, output dim]
#attention = [batch size, trg len - 1, src len]
return output, attention
训练模型
本教程的其余部分类似于前面的所有内容。我们定义所有的超参数,初始化编码器和解码器,并初始化整个模型——如果我们有GPU,就把它放到GPU上。
在这篇论文中,他们发现使用小的过滤器(核大小为3)和高的层数(5+)更有益。
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
EMB_DIM = 256
HID_DIM = 512 # each conv. layer has 2 * hid_dim filters
ENC_LAYERS = 10 # number of conv. blocks in encoder
DEC_LAYERS = 10 # number of conv. blocks in decoder
ENC_KERNEL_SIZE = 3 # must be odd!
DEC_KERNEL_SIZE = 3 # can be even or odd
ENC_DROPOUT = 0.25
DEC_DROPOUT = 0.25
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
enc = Encoder(INPUT_DIM, EMB_DIM, HID_DIM, ENC_LAYERS, ENC_KERNEL_SIZE, ENC_DROPOUT, device)
dec = Decoder(OUTPUT_DIM, EMB_DIM, HID_DIM, DEC_LAYERS, DEC_KERNEL_SIZE, DEC_DROPOUT, TRG_PAD_IDX, device)
model = Seq2Seq(enc, dec).to(device)
我们还可以看到,该模型的参数几乎是基于注意力的模型的两倍(20m到37m)。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 37,351,685 trainable parameters
接下来,我们定义优化器和损失函数(criterion)。与前面一样,我们忽略目标序列是填充标记时的损失。
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
然后,我们为模型定义训练循环。
我们处理序列的方式与之前的教程略有不同。对于所有的模型,我们从不把《eos》放入解码器。这是处理在RNN模型有解码器循环不达到有《eos》作为输入解码器。在这个模型中,我们简单地将《eos》标记从序列末尾切掉。因此:

x i x_i xi表示实际目标序列元素。然后,我们将其输入到模型中,以获得一个有望预测《eos》标记的预期序列:

y i y_i yi表示预测的目标序列元素。然后,我们使用原始trg张量计算我们的损失,将《sos》标记切掉,留下《eos》标记:

然后我们计算我们的损失并按照标准更新我们的参数。
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg len - 1, output dim]
#trg = [batch size, trg len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg len - 1, output dim]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
评估循环与训练循环相同,只是没有梯度计算和参数更新。
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg len - 1, output dim]
#trg = [batch size, trg len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg len - 1, output dim]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
同样,我们有一个函数告诉我们每个epoch需要多长时间。
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
最后,我们训练我们的模型。注意,为了更可靠地训练这个模型,我们将 CLIP值从1减少到0.1。随着较高的 CLIP值,梯度偶尔爆炸。
尽管我们的参数几乎是基于注意力的RNN模型的两倍,但它实际上只需要标准版本的一半时间,并且与填充序列版本的时间差不多。这是由于所有的计算都是使用卷积过滤器并行完成的,而不是按顺序使用RNN。
注意:该模型的teacher forcing比率始终为1,即它将始终使用目标序列中的ground truth next token。这意味着,当使用不为1的teacher forcing比率时,我们不能将perplexity值与之前的模型进行比较。在teacher forcing比率为1时,基于注意力的RNN的结果见这里。
N_EPOCHS = 10
CLIP = 0.1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut5-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
Epoch: 01 | Time: 0m 30s
Train Loss: 4.240 | Train PPL: 69.408
Val. Loss: 2.994 | Val. PPL: 19.961
Epoch: 02 | Time: 0m 30s
Train Loss: 3.043 | Train PPL: 20.971
Val. Loss: 2.379 | Val. PPL: 10.798
Epoch: 03 | Time: 0m 30s
Train Loss: 2.604 | Train PPL: 13.521
Val. Loss: 2.124 | Val. PPL: 8.361
Epoch: 04 | Time: 0m 30s
Train Loss: 2.369 | Train PPL: 10.685
Val. Loss: 1.991 | Val. PPL: 7.323
Epoch: 05 | Time: 0m 30s
Train Loss: 2.209 | Train PPL: 9.107
Val. Loss: 1.908 | Val. PPL: 6.737
Epoch: 06 | Time: 0m 30s
Train Loss: 2.097 | Train PPL: 8.139
Val. Loss: 1.864 | Val. PPL: 6.448
Epoch: 07 | Time: 0m 30s
Train Loss: 2.009 | Train PPL: 7.456
Val. Loss: 1.810 | Val. PPL: 6.110
Epoch: 08 | Time: 0m 31s
Train Loss: 1.932 | Train PPL: 6.904
Val. Loss: 1.779 | Val. PPL: 5.922
Epoch: 09 | Time: 0m 30s
Train Loss: 1.868 | Train PPL: 6.474
Val. Loss: 1.762 | Val. PPL: 5.825
Epoch: 10 | Time: 0m 30s
Train Loss: 1.817 | Train PPL: 6.156
Val. Loss: 1.736 | Val. PPL: 5.674
然后我们加载获得最低验证损失的参数,并计算测试集上的损失。
model.load_state_dict(torch.load('tut5-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
| Test Loss: 1.795 | Test PPL: 6.022 |
推断
现在我们可以使用下面的translate_sentence函数对模型进行翻译。
所采取的步骤是:
- 如果源语句没有被标记(是字符串),则标记源语句
- 附加《sos》和《eos》标记
- 将源语句数字化
- 把它转换成张量,然后加上batch维数
- 将源语句输入编码器
- 创建一个列表来保存输出语句,初始化时使用《sos》令牌
- 当我们还没有达到最大长度时
- 将当前输出句子的预测转换为具有批维度的张量
- 将当前输出和两个编码器输出放入解码器
- 从解码器获取下一个输出标记预测
- 添加预测到当前输出句子预测
- 如果预测是《eos》标记,则中断
- 将输出语句从索引转换为标记
- 返回输出语句(删除《sos》标记)和最后一层的注意力
def translate_sentence(sentence, src_field, trg_field, model, device, max_len = 50):
model.eval()
if isinstance(sentence, str):
nlp = spacy.load('de')
tokens = [token.text.lower() for token in nlp(sentence)]
else:
tokens = [token.lower() for token in sentence]
tokens = [src_field.init_token] + tokens + [src_field.eos_token]
src_indexes = [src_field.vocab.stoi[token] for token in tokens]
src_tensor = torch.LongTensor(src_indexes).unsqueeze(0).to(device)
with torch.no_grad():
encoder_conved, encoder_combined = model.encoder(src_tensor)
trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]]
for i in range(max_len):
trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0).to(device)
with torch.no_grad():
output, attention = model.decoder(trg_tensor, encoder_conved, encoder_combined)
pred_token = output.argmax(2)[:,-1].item()
trg_indexes.append(pred_token)
if pred_token == trg_field.vocab.stoi[trg_field.eos_token]:
break
trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes]
return trg_tokens[1:], attention
接下来,我们有一个函数,它将显示在解码的每个步骤中模型对每个输入标记的关注程度。
def display_attention(sentence, translation, attention):
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(111)
attention = attention.squeeze(0).cpu().detach().numpy()
cax = ax.matshow(attention, cmap='bone')
ax.tick_params(labelsize=15)
ax.set_xticklabels(['']+['' ]+[t.lower() for t in sentence]+['' ],
rotation=45)
ax.set_yticklabels(['']+translation)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
plt.close()
然后我们开始翻译一些句子。注:这些句子都是精心挑选的。
首先,我们将从训练集获得一个示例:
example_idx = 2
src = vars(train_data.examples[example_idx])['src']
trg = vars(train_data.examples[example_idx])['trg']
print(f'src = {src}')
print(f'trg = {trg}')
src = ['ein', 'kleines', 'mädchen', 'klettert', 'in', 'ein', 'spielhaus', 'aus', 'holz', '.']
trg = ['a', 'little', 'girl', 'climbing', 'into', 'a', 'wooden', 'playhouse', '.']
然后我们将它传递给translate_sentence函数,该函数会给我们预测的翻译标记和注意力。
我们可以看到,它没有给出完全相同的翻译,但它捕捉了与原文相同的意思。它实际上是一个更字面的翻译,就像aus holz字面上翻译的of wood,所以wooden playhouse和 playhouse made of wood是一样的。
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}')
predicted trg = ['a', 'little', 'girl', 'is', 'climbing', 'into', 'a', 'playhouse', 'made', 'of', 'wood', '.', '' ]
我们可以查看模型的注意力,确保它给出合理的外观结果。
我们可以看到它在翻译make和of时对aus的正确重视。
display_attention(src, translation, attention)

让我们看看它如何翻译一个不属于训练集的例子。
example_idx = 2
src = vars(valid_data.examples[example_idx])['src']
trg = vars(valid_data.examples[example_idx])['trg']
print(f'src = {src}')
print(f'trg = {trg}')
src = ['ein', 'junge', 'mit', 'kopfhörern', 'sitzt', 'auf', 'den', 'schultern', 'einer', 'frau', '.']
trg = ['a', 'boy', 'wearing', 'headphones', 'sits', 'on', 'a', 'woman', "'s", 'shoulders', '.']
模型在这一方面做得很好,除了把wearing换成了in。
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}')
predicted trg = ['a', 'boy', 'in', 'headphones', 'sits', 'on', 'the', 'shoulders', 'of', 'a', 'woman', '.', '' ]
再一次,我们可以看到注意力被应用到有意义的词上,如junge for boy,等等。
display_attention(src, translation, attention)

最后,让我们检查测试集中的一个示例。
example_idx = 9
src = vars(test_data.examples[example_idx])['src']
trg = vars(test_data.examples[example_idx])['trg']
print(f'src = {src}')
print(f'trg = {trg}')
src = ['ein', 'mann', 'in', 'einer', 'weste', 'sitzt', 'auf', 'einem', 'stuhl', 'und', 'hält', 'magazine', '.']
trg = ['a', 'man', 'in', 'a', 'vest', 'is', 'sitting', 'in', 'a', 'chair', 'and', 'holding', 'magazines', '.']
我们在这里得到了一个大致正确的翻译,尽管模型改变了 in a chair到on a chair,并移除了and。
“magazines ”这个词不在我们的词汇表中,因此它是作为一个未知的符号输出的。
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}')
predicted trg = ['a', 'man', 'in', 'a', 'vest', 'is', 'sitting', 'on', 'a', 'chair', 'holding', '' , '.', '' ]
这种关注似乎是正确的。没有注意力应用到und,因为它从来没有输出并且单词magazine正确的注意到,即使它不是输出词汇。
display_attention(src, translation, attention)

BELU
最后,我们计算模型的BLEU分数。
from torchtext.data.metrics import bleu_score
def calculate_bleu(data, src_field, trg_field, model, device, max_len = 50):
trgs = []
pred_trgs = []
for datum in data:
src = vars(datum)['src']
trg = vars(datum)['trg']
pred_trg, _ = translate_sentence(src, src_field, trg_field, model, device, max_len)
#cut off token
pred_trg = pred_trg[:-1]
pred_trgs.append(pred_trg)
trgs.append([trg])
return bleu_score(pred_trgs, trgs)
我们得到了约等于33的BLEU分数,相比之下,基于注意力的RNN模型给出了约等于28的分数。这使BLEU分数提高了17%。
bleu_score = calculate_bleu(test_data, SRC, TRG, model, device)
print(f'BLEU score = {bleu_score*100:.2f}')
BLEU score = 33.29
我们现在已经介绍了第一个不是使用RNN单元的模型!下一个是 Transformer模型,它甚至不使用卷积层-它只有线性层和大量的注意力机制。
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
SRC = Field(tokenize = tokenize_de,
init_token = '' ,
eos_token = '' ,
lower = True,
batch_first = True)
TRG = Field(tokenize = tokenize_en,
init_token = '' ,
eos_token = '' ,
lower = True,
batch_first = True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'),
fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, kernel_size, dropout, devoce, max_length = 100):
super(Encoder, self).__init__()
assert kernel_size % 2 == 1, "Kernel size must be odd!"
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device) # scale = [0.4...] 取平方根
self.tok_embedding = nn.Embedding(input_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_length, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim,
out_channels = 2 * hid_dim,
kernel_size = kernel_size,
padding = (kernel_size - 1) // 2)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# src = [batch_size, seq_len]
batch_size = src.shape[0]
src_len = src.shape[1]
# create position tensor
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos = [0, 1, 2, 3, ... , src_len - 1]
# pos = [batch_size, src_len]
# embed tokens and positions
tok_embedded = self.tok_embedding(src)
pos_embedded = self.pos_embedding(pos)
# tok_embedded = pos_embedded = [batch_size, src_len, emb_dim]
# combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
# embedded = [batch_size, src_len, emb_dim]
# pass embedded through linear layer to convert from emb_dim to hid_dim
conv_input = self.emb2hid(embedded)
# conv_input = [batch_size, src_len, hid_dim]
# permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
# conv_input = [batch_size, hid_dim, src_len]
# begin convolutional blocks...
for i, conv in enumerate(self.convs):
# pass through convolutional layer
conved = conv(self.dropout(conv_input))
# conved = [batch_size, hid_dim * 2, src_len]
# pass through GLU activation function
conved = F.glu(conved, dim=1)
# conved = [batch_size, hid_dim, src_len]
# apply residual connection
conved = (conved + conv_input) * self.scale
# conved = [batch_size, hid_dim, src_len]
# set conv_input to conved for next loop iteration
conv_input = conved
# ... end convolutional blocks
# permute and convert back to emb_dim
conved = self.hid2emb(conved.permute(0, 2, 1))
# conved = [batch_size, src_len, emb_dim]
# elementwise sum output(conved) and input(embedded) to be use for attention
combined = (conved + embedded) * self.scale
# combined = [batch_size, src_len, emb_dim]
return conved, combined
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, kernel_size,dropout, trg_pad_idx, device, max_len = 100):
super(Decoder, self).__init__()
self.kernel_size = kernel_size
self.trg_pad_idx = trg_pad_idx
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(output_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_len, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emd = nn.Linear(hid_dim, emb_dim)
self.attn_hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_emb2hid = nn.Linear(emb_dim, hid_dim)
self.fc_out = nn.Linear(emb_dim, output_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels=hid_dim,
out_channels=2 * hid_dim,
kernel_size=kernel_size)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def calculate_attention(self, embedded, conved, encoder_conved, encoder_combined):
# embedded = [batch_size, src_len, emb_dim]
# conved = [batch_size, hid_dim, trg_len]
# encoder_conved = [batch_size, src_len, emb_dim]
# encoder_combined = [batch_size, src_len, emb_dim]
# permute and convert back to emb_dim
conved_emb = self.attn_hid2emd(conved.permute(0, 2, 1))
# conved_emb = [batch_size, trg_len, emb_dim]
combined = (conved_emb + embedded) * self.scale
# combined = [batch_size, trg_len, emb_dim]
energy = torch.matmul(combined, encoder_conved.permute(0, 2, 1))
# energy = [batch_size, trg_len, src_len]
attention = F.softmax(energy, dim=2)
# attention = [batch_size, trg_len, src_len]
attention_encoding = torch.matmul(attention, encoder_combined)
# attention_encoding = [batch_size, trg_len, emb_dim]
# convert from emb_dim -> hid_dim
attention_encoding = self.attn_emb2hid(attention_encoding)
# attention_encoding = [batch_size, trg_len, hid_dim]
# apply residual connection
attended_combined = (conved + attention_encoding.permute(0, 2, 1)) * self.scale
# attended_combined = [batch_size, hid_dim, trg_len]
return attention, attended_combined
def forward(self, trg, encoder_conved, encoder_combined):
# trg = [batch_size, trg_len]
# encoder_conved = encoder_combined = [batch_size, src_len, emb_dim]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
# create position tensor
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos = [batch_size, trg_len]
# embed tokens and positions
tok_embedded = self.tok_embedding(trg)
pos_embedded = self.pos_embedding(pos)
# combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
# embedded = [batch_size, trg_len, emb_dim]
# pass embedded through linear layer to go through emb_dim -> hid_dim
conv_input = self.emb2hid(embedded)
# conv_input = [batch_size, trg_len, hid_dim]
# permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
# conv_input = [batch_size, hid_dim, trg_len]
batch_size = conv_input.shape[0]
hid_dim = conv_input.shape[1]
for i, conv in enumerate(self.convs):
# apply dropout
conv_input = self.dropout(conv_input)
# need to pad so decoder can't "cheat"
padding = torch.zeros(batch_size, hid_dim, self.kernel_size - 1).fill_(self.trg_pad_idx).to(self.device)
padded_conv_input = torch.cat((padding, conv_input), dim=2)
# pass through convolutional layer
conved = conv(padded_conv_input)
# conved = [batch_size, hid_dim * 2, trg_len]
# pass through GLU activation function
conved = F.glu(conved, dim = 1)
# calculate attention
attention, conved = self.calculate_attention(embedded, conved, encoder_conved, encoder_combined)
# attention = [batch_size, trg_len, src_len]
# apply residual connection
conved = (conved + conv_input) * self.scale
# conved = [batch_size, hid_dim, trg_len]
# set conv_input to conved for next loop iteration
conv_input = conved
conved = self.hid2emd(conved.permute(0, 2, 1))
# conved = [batch_size, trg_len, emb_dim]
output = self.fc_out(self.dropout(conved))
# output = [batch_size, trg_len, output_dim]
return output, attention
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg):
# src = [batch_size, src_len]
# trg = [batch_size, trg_len - 1] ( token sliced off the end)
# calculate z~u (encoder_conved) and (z~u + e) (encoder_combined)
# encoder_conved is output from final encoder conv. block
# encoder_combined is encoder_conved plus (elementwise) src embedding plus
# positional embeddings
encoder_conved, encoder_combined = self.encoder(src)
# encoder_conved = [batch_size, src_len, emb_dim]
# encoder_combined = [batch_size, src_len, emb_dim]
# calculate predictions of next words
# output is a batch of predictions for each word in the trg sentence
# attention is a batch of attention scores across the src_sentence for each word in the trg_sentence
output, attention = self.decoder(trg, encoder_conved, encoder_combined)
# output = [batch_size, trg_len - 1, output_dim]
# attention = [batch_size, trg_len - 1, src_len]
return output, attention
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
EMB_DIM = 256
HID_DIM = 512 # each conv. layer has 2 * hid_dim filters
ENC_LAYERS = 10 # number of conv. blocks in encoder
DEC_LAYERS = 10 # number of conv. blocks in decoder
ENC_KERNEL_SIZE = 3 # must be odd!
DEC_KERNEL_SIZE = 3 # can be even or odd
ENC_DROPOUT = 0.25
DEC_DROPOUT = 0.25
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
enc = Encoder(INPUT_DIM, EMB_DIM, HID_DIM, ENC_LAYERS, ENC_KERNEL_SIZE, ENC_DROPOUT, device)
dec = Decoder(OUTPUT_DIM, EMB_DIM, HID_DIM, DEC_LAYERS, DEC_KERNEL_SIZE, DEC_DROPOUT, TRG_PAD_IDX, device)
model = Seq2Seq(enc, dec).to(device)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output, _ = model(src, trg[:, :-1])
# output = [batch_size, trg_len - 1, output_dim]
# trg = [batch_size, trg_len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
# output = [batch_size * trg_len -1, output_dim]
# trg = [batch_size, trg_len - 1]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output, _ = model(src, trg[:, :-1])
# output = [batch size, trg len - 1, output dim]
# trg = [batch size, trg len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
# output = [batch size * trg len - 1, output dim]
# trg = [batch size * trg len - 1]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
CLIP = 0.1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut5-model.pt')
print(f'Epoch: {epoch + 1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
model.load_state_dict(torch.load('tut5-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
def translate_sentence(sentence, src_field, trg_field, model, device, max_len=50):
model.eval()
if isinstance(sentence, str):
nlp = spacy.load('de')
tokens = [token.text.lower() for token in nlp(sentence)]
else:
tokens = [token.lower() for token in sentence]
tokens = [src_field.init_token] + tokens + [src_field.eos_token]
src_indexes = [src_field.vocab.stoi[token] for token in tokens]
src_tensor = torch.LongTensor(src_indexes).unsqueeze(0).to(device)
with torch.no_grad():
encoder_conved, encoder_combined = model.encoder(src_tensor)
trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]]
for i in range(max_len):
trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0).to(device)
with torch.no_grad():
output, attention = model.decoder(trg_tensor, encoder_conved, encoder_combined)
pred_token = output.argmax(2)[:, -1].item()
trg_indexes.append(pred_token)
if pred_token == trg_field.vocab.stoi[trg_field.eos_token]:
break
trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes]
return trg_tokens[1:], attention
def display_attention(sentence, translation, attention):
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111)
attention = attention.squeeze(0).cpu().detach().numpy()
cax = ax.matshow(attention, cmap='bone')
ax.tick_params(labelsize=15)
ax.set_xticklabels([''] + ['' ] + [t.lower() for t in sentence] + ['' ],
rotation=45)
ax.set_yticklabels([''] + translation)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
plt.close()
# example_idx = 2
#
# src = vars(train_data.examples[example_idx])['src']
# trg = vars(train_data.examples[example_idx])['trg']
#
# print(f'src = {src}')
# print(f'trg = {trg}')
#
# translation, attention = translate_sentence(src, SRC, TRG, model, device)
#
# print(f'predicted trg = {translation}')
#
# display_attention(src, translation, attention)
#
# example_idx = 2
#
# src = vars(valid_data.examples[example_idx])['src']
# trg = vars(valid_data.examples[example_idx])['trg']
#
# print(f'src = {src}')
# print(f'trg = {trg}')
#
# translation, attention = translate_sentence(src, SRC, TRG, model, device)
#
# print(f'predicted trg = {translation}')
#
# display_attention(src, translation, attention)
#
# example_idx = 9
#
# src = vars(test_data.examples[example_idx])['src']
# trg = vars(test_data.examples[example_idx])['trg']
#
# print(f'src = {src}')
# print(f'trg = {trg}')
#
# translation, attention = translate_sentence(src, SRC, TRG, model, device)
#
# print(f'predicted trg = {translation}')
#
# display_attention(src, translation, attention)
#
# from torchtext.data.metrics import bleu_score
def calculate_bleu(data, src_field, trg_field, model, device, max_len=50):
trgs = []
pred_trgs = []
for datum in data:
src = vars(datum)['src']
trg = vars(datum)['trg']
pred_trg, _ = translate_sentence(src, src_field, trg_field, model, device, max_len)
# cut off token
pred_trg = pred_trg[:-1]
pred_trgs.append(pred_trg)
trgs.append([trg])
return bleu_score(pred_trgs, trgs)
bleu_score = calculate_bleu(test_data, SRC, TRG, model, device)
print(f'BLEU score = {bleu_score*100:.2f}')