【推荐算法 学习与复现】-- 深度学习系列 -- Deep&Cross

DeepCross模型整体内容思想是和WideDeep保持一致的, 尤其是Deep部分基本一致, 但是将原先单线性回归的Wide部分替换为Cross网络,增加特征之间的交互力度. 模型结构如上图所示, DCN(论文中的叫法)模型从Embedding和Stacking层开始,然后是并行的Cross网络和Deep网络,最后是将两个网络的输出组合在一起的Stacking层和输出层。图示很清楚的表明了模型结构, 配合原论文 第二章一起食用更佳~~~ Embedding、Stacking、Deep、以及输出在其它网络中已经很常见了。
争对 Cross Network部分 , 论文中给出的单层计算过程如下, 可以看出主要有 首先是个 叉乘操作,叉乘的对象是 x_0 和 当前 x 的转置, 其次有一个类似 线性层的计算,最后再加上当前 x。 直观上可以看到 首先叉乘操作类似做了一个相关性的计算,相较于 WideDeep 仅仅是一个线性回归层,这里使用相关性计算( 是不是可以理解为注意力机制?),做了特征交叉,能够一定程度上更好的利用特征;但是仔细看又能发现每一层的参数个数仅仅只有 2 * feature_nums,单次计算的输入输出维度相同,可以支持多层叠加运算(论文中implementation details 也说到 Cross 层 取1 to 6),线性回归的参数量比这个可大得多的多了,参数量少也就限制了模型的表达能力,所以作者由加了另一个 Deep 部分获得更高的非线性相互作用。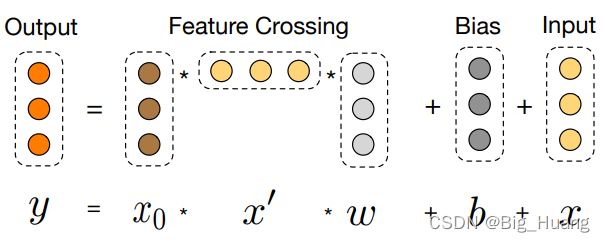
论文复现:
由于结构很好理解,加上与WideDeep相似,自己很容易就复现出下面的代码,在circto 数据上简单训练也是能很快收敛,但是基本上也是一开始就过拟合........
按照上面的橙色文字的理解,复现的代码如下,但是网上其它帖子复现的代码大多 使用 nn.Parameter 新建各部分的参数变量,然后构建图示中的计算公式,但是 nn.Linear 本身也是有参数初始化过程的,源码如下
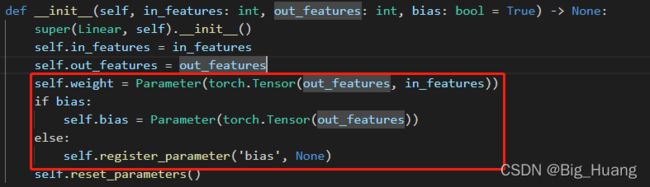
关于详细的计算过程已经在备注里面了,感觉没啥问题~~~ 主要是 自己的circto数据集量级很小, 太容易过拟合了,不好验证模型效果。完成各部分模型学习后,去天池找个比赛把各个模型的结果贴出来 ~~~ 这样才好评判结果~·~
个人理解水平有限,如果哪里写错了欢迎大佬指正~~~
class Cross(nn.Module):
def __init__(self, in_features, layer_nums):
super().__init__()
self.layers = nn.ModuleList([
nn.Linear(in_features, 1, bias=True) for _ in range(layer_nums)
])
def forward(self, x):
x_0 = x.clone()
for fc in self.layers:
# x : [batch_size, fea_nums]
# x.unsqueeze(2) : [batch_size, fea_nums, 1]
# x.unsqueeze(1) : [batch_size, 1, fea_nums]
# torch.matmul(x.unsqueeze(2), x.unsqueeze(1)) : [batch_size, fea_nums, fea_nums]
# fc 为 x*(w.T)+b : w => [1, fea_nums] b => [fea_nums, 1]
# fc(torch.matmul(x.unsqueeze(2), x.unsqueeze(1))) : [batch_size, fea_nums, 1]
# fc(torch.matmul(x.unsqueeze(2), x.unsqueeze(1))).squeeze() : [batch_size, fea_nums]
# 最终求和计算结果 : [batch_size, fea_nums]
x = fc(torch.matmul(x_0.unsqueeze(2), x.unsqueeze(1))).squeeze() + x
return x
class Deep(nn.Module):
def __init__(self, hidden_units):
super().__init__()
self.layers = nn.ModuleList([
nn.Linear(in_features, out_features, bias=True) for in_features, out_features in zip(hidden_units[:-1], hidden_units[1:])
])
def forward(self, x):
for layer in self.layers:
x = F.relu(layer(x))
return x
class DeepCross(nn.Module):
def __init__(self, features_info, hidden_units, cross_layer_nums, embedding_dim):
super().__init__()
# 解析特征信息
self.dense_features, self.sparse_features, self.sparse_features_nunique = features_info
# 解析拿到所有 数值型 和 稀疏型特征信息
self.__dense_features_nums = len(self.dense_features)
self.__sparse_features_nums = len(self.sparse_features)
# 构建Embedding层
self.embedding_layers = nn.ModuleDict({
"embed_" + key : nn.Embedding(fea_nums, embedding_dim)
for key, fea_nums in self.sparse_features_nunique.items()
})
# Deep的首层参数维度需要 stacking层 维度
stack_dim = self.__dense_features_nums + embedding_dim * self.__sparse_features_nums
hidden_units.insert(0, stack_dim)
# Deep Network
self.deep = Deep(hidden_units)
# Cross Network
self.cross = Cross(stack_dim, cross_layer_nums)
# 输出层
stack_dim = stack_dim + hidden_units[-1] # Cross 部分 + Deep 部分
self.outLayer = nn.Linear(stack_dim, 1, bias=True)
def forward(self, x):
# 从输入x中单独拿出 sparse_input 和 dense_input
dense_inputs, sparse_inputs = x[:, :self.__dense_features_nums], x[:, self.__dense_features_nums:]
sparse_inputs = sparse_inputs.long()
# embedding 编码
embedding_feas = [self.embedding_layers["embed_" + key](sparse_inputs[:, idx]) for idx, key in enumerate(self.sparse_features)]
embedding_feas = torch.cat(embedding_feas, axis=-1)
# 连接层
input_feas = torch.cat([dense_inputs, embedding_feas], axis=-1)
# Cross 和 Deep 部分
cross = self.cross(input_feas)
deep = self.deep(input_feas)
# 合并输出层
out = torch.cat([cross, deep], axis=-1)
out = F.sigmoid(self.outLayer(out))
return out参考:
1. 《深度学习推荐系统》
2. https://datawhalechina.github.io/fun-rec/