MYSQL窗口函数
文章目录
- 一、为何使用窗口函数
- 二、什么是窗口函数
- 三、窗口函数如何使用
-
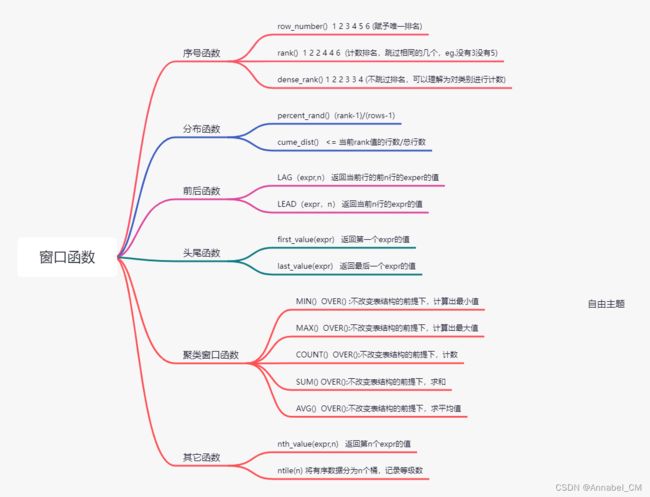
- 3.1 序号函数
- 3.2 分布函数
- 3.3 前后函数
- 3.4 头尾函数
- 3.5 其他函数
- 3.6 聚类窗口函数
一、为何使用窗口函数
在日常工作中经常会遇到类似这样的需求:
怎么样得到各部门工资排名前N名的员工列表?
查找各部门每人工资占部门总工资的百分比?
对于这样的需求,使用传统的SQL实现起来比较困难,这类需求都有一个共同的特点,需要在单表中满足某些条件的记录集内部做一些函数操作。不使用窗口函数的话可能要进行多次的表连接操作,可读性差的同时还会影响性能。
窗口函数适用场景: 对分组统计结果中的每一条记录进行计算的场景下, 使用窗口函数更好, 注意, 是每一条;因为MySQL的普通聚合函数的结果(如 group by)是每一组只有一条记录。
二、什么是窗口函数
-
窗口函数也称为OLAP(Online Anallytical Processing)函数,意思是对数据库数据进行实时分析处理。窗口函数就是为了实现OLAP而添加的标准SQL功能。
-
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数,有的函数,随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
-
窗口函数和普通聚合函数也很容易混淆,二者区别如下:
- 聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,查询结果并不会改变记录条数,有几条记录执行完还是几条。
- 普通聚合函数也可以用于窗口函数中,赋予它窗口函数的功能。
原因就在于窗口函数的执行顺序(逻辑上的)是在FROM,JOIN,WHERE,GROUP BY,HAVING之后,在ORDER BY,LIMIT,SELECT DISTINCT之前。它执行时GROUP BY的聚合过程已经完成了,所以不会再产生数据聚合。
窗口函数的简单语法如下:
<窗口函数> OVER (partition by <用于分组的列名>
order by <用于排序的列名>)
三、窗口函数如何使用
数据表:
drop table if exists examination_info,user_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE user_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int UNIQUE NOT NULL COMMENT '用户ID',
`nick_name` varchar(64) COMMENT '昵称',
achievement int COMMENT '成就值',
level int COMMENT '用户等级',
job varchar(32) COMMENT '职业方向',
register_time datetime COMMENT '注册时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO user_info(uid,`nick_name`,achievement,`level`,job,register_time) VALUES
(1001, '牛客1', 3200, 7, '算法', '2020-01-01 10:00:00'),
(1002, '牛客2号', 2500, 6, '算法', '2020-01-01 10:00:00'),
(1003, '牛客3号♂', 2200, 5, '算法', '2020-01-01 10:00:00');
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, 'SQL', 'hard', 60, '2020-01-01 10:00:00'),
(9002, 'SQL', 'hard', 80, '2020-01-01 10:00:00'),
(9003, '算法', 'hard', 80, '2020-01-01 10:00:00'),
(9004, 'PYTHON', 'medium', 70, '2020-01-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2020-01-01 09:01:01', '2020-01-01 09:21:59', 90),
(1002, 9001, '2020-01-20 10:01:01', null, null),
(1002, 9001, '2020-02-01 12:11:01', null, null),
(1003, 9001, '2020-03-01 19:01:01', null, null),
(1001, 9001, '2020-03-01 12:01:01', null, null),
(1002, 9001, '2020-03-01 12:01:01', '2020-03-01 12:41:01', 90),
(1002, 9001, '2020-05-02 19:01:01', '2020-05-02 19:32:00', 90),
(1001, 9002, '2020-01-02 19:01:01', '2020-01-02 19:59:01', 69),
(1001, 9002, '2020-02-02 12:01:01', '2020-02-02 12:20:01', 99),
(1002, 9002, '2020-02-02 12:01:01', null, null),
(1002, 9002, '2020-02-02 12:01:01', '2020-02-02 12:43:01', 81),
(1002, 9002, '2020-03-02 12:11:01', null, null),
(1001, 9001, '2020-01-02 10:01:01', '2020-01-02 10:31:01', 89),
(1001, 9002, '2020-01-01 12:11:01', null, null),
(1002, 9001, '2020-01-01 18:01:01', '2020-01-01 18:59:02', 90),
(1002, 9003, '2020-05-06 12:01:01', null, null),
(1001, 9002, '2020-05-05 18:01:01', null, null);
3.1 序号函数
- ROW_NUMBER():顺序排序——1、2、3
- RANK():并列排序,跳过重复序号——1、1、3
- DENSE_RANK():并列排序,不跳过重复序号——1、1、2
select nick_name,ei.exam_id,score,
row_number() over(partition by nick_name order by score desc) row_ranking,
rank() over(partition by nick_name order by score desc) ranking,
dense_rank() over(partition by nick_name order by score desc) dense_ranking
from user_info ui
join exam_record er on ui.uid = er.uid
join examination_info ei on er.exam_id = ei.exam_id
where score is not null
结果:

3.2 分布函数
- percent_rank()
- 用途:和之前的RANK()函数相关,每行按照如下公式进行计算: (rank - 1) / (rows - 1)
其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
- cume_dist()
- 用途:分组内大于等于当前rank值的行数/分组内总行数,这个函数比percen_rank使用场景更多。
应用场景:班级中比当前同学成绩高的学生比例是多少
select nick_name,ei.exam_id,score,
PERCENT_RANK() OVER (PARTITION BY nick_name
ORDER BY score DESC) as percent,
CUME_DIST() OVER (PARTITION BY nick_name
ORDER BY score DESC) as cumdist
from user_info ui
join exam_record er on ui.uid = er.uid
join examination_info ei on er.exam_id = ei.exam_id
where score is not null
结果:

3.3 前后函数
- lead(n) / lag(n)
- 用途:分组中位于当前行后n行(lead)/ 前n行(lag)的记录值。
- 应用场景:求每个用户相邻两次浏览的时间差
select nick_name,ei.exam_id,score,
lead(score,1) OVER (PARTITION BY nick_name
ORDER BY score DESC) as leadVal,
lag(score,1) OVER (PARTITION BY nick_name
ORDER BY score DESC) as lagVal
from user_info ui
join exam_record er on ui.uid = er.uid
join examination_info ei on er.exam_id = ei.exam_id
where score is not null
结果:

3.4 头尾函数
- first_val(expr) / last_val(expr)
- 用途:得到分区中的第一个/最后一个指定参数的值
select nick_name,ei.exam_id,score,
FIRST_VALUE(score) OVER (PARTITION BY nick_name
ORDER BY score DESC) as firstVal,
LAST_VALUE(score) OVER (PARTITION BY nick_name
ORDER BY score DESC) as lastVal
from user_info ui
join exam_record er on ui.uid = er.uid
join examination_info ei on er.exam_id = ei.exam_id
where score is not null
结果:
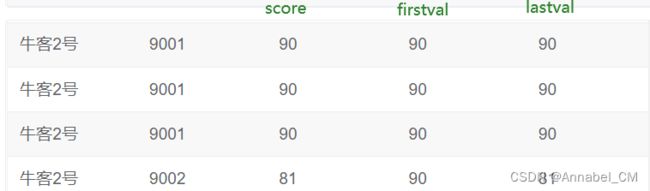
截止到第二行,第一个记录为90分,最后一个记录为90分;
截止到第四行,第一个记录为90分,最后一个记录为81分.
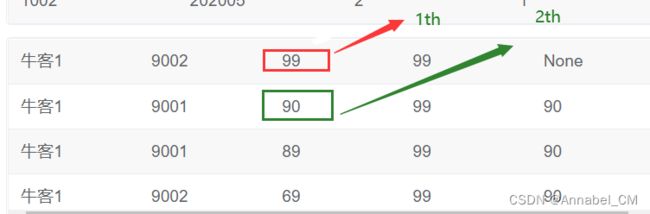
3.5 其他函数
- nth_value(expr, n)
- 用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名
select nick_name,ei.exam_id,score,
nth_value(score,1) OVER (PARTITION BY nick_name
ORDER BY score DESC) as 1th,
nth_value(score,2) OVER (PARTITION BY nick_name
ORDER BY score DESC) as 2th
from user_info ui
join exam_record er on ui.uid = er.uid
join examination_info ei on er.exam_id = ei.exam_id
where score is not null
- 结果:
2. nfile()
- 用途:将分区中的有序数据分为n个桶,记录桶号。
- 此函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到N个并行的进程分别计算,此时就可以用NFILE(N)对数据进行分组,由于记录数不一定被N整除,所以数据不一定完全平均,多出来的部分则依次加给第一组、第二组···直到分配完。
3.6 聚类窗口函数
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
select *,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表
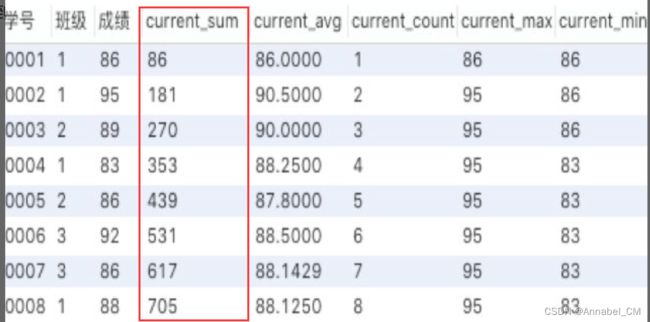
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
参考链接:狗哥数据分析
数据来源:牛客网