Python数据分析案例—淘宝用户行为分析
赛题与数据
一、项目背景
本数据报告以淘宝app平台为数据集,通过行业的指标对淘宝用户行为进行分析,从而探索淘宝用户的行为模式,具体指标包括:日PV和日UV分析,付费率分析,复购行为分析,漏斗流失分析和用户价值RFM分析。
主要内容如下:
- 用户行为分析:日访问量分析、小时访问量分析、不同行为类型用户pv分析
- 用户消费行为分析:用户购买次数情况分析、日ARPPU、日ARPU、付费率、同一时间段用户消费次数分布
- 复购情况分析:所有复购时间间隔消费次数分布、不同用户平均复购时间分析
- 漏斗流失分析
- 用户行为与商品种类关系分析:不同用户行为类别的转化率、不同用户行为类别的感兴趣率
- 二八理论分析
- 用户价值度RFM模型分析
二、具体要解决的问题
1.日PV有多少
2.日UV有多少
3.付费率情况如何
4.复购率是多少
5漏斗流失情况如何
6.用户价值情况
三、了解数据
tianchi_mobile_recommend_train_user表。共有104万条左右数据,数据为淘宝APP2014年11月18日至2014年12月18日的用户行为数据,共计6列字段,列字段分别是:
user_id:用户身份,脱敏、
item_id:商品ID,脱敏、
behavior_type:用户行为类型(包含点击、收藏、加购物车、支付四种行为,分别用数字1、2、3、4表示)、
user_geohash:地理位置、
item_category:品类ID(商品所属的品类)、
time:用户行为发生的时间
四、数据清洗
数据导入-- 数据查看 – 缺失值处理
import pandas as pd
import numpy as py
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
dfu = pd.read_csv('E:/kaggle数据/淘宝用户行为分析数据/tianchi_mobile_recommend_train_user.csv') #数据读入
#缺失值处理
missingTotal = dfu.isnull().sum() #统计每列的缺失量
missingExist = missingTotal[missingTotal>0] #筛选出有缺失值的列,即缺失值为0的列不显示
missingExist = missingExist.sort_values(ascending=False) #排序,降序显示
print(missingExist)
#输出:user_geohash 8334824
分析:存在缺失值的是User_geohash列,有8334824条,不能删除缺失值,因为地理信息在数据集收集过程中做过加密转换,因此对数据集不做处理。

数据格式要调整成合理的:日期列拆分+日期类数据类型
dfu.head() #查看数据格式
#日期列需要拆分成年月日 与小时
import re
dfu['date'] = dfu['time'].map(lambda s:re.compile(' ').split(s)[0])
dfu['hour'] = dfu['time'].map(lambda s:re.compile(' ').split(s)[1])
dfu.head()
dfu.dtypes #查看每列类型
#time列与date列应该是日期类数据类型,hour是字符串
dfu['time'] = pd.to_datetime(dfu['date'])
dfu['date'] = pd.to_datetime(dfu['date'])
dfu['hour'] = dfu['hour'].astype('int64')
dfu.dtypes #再看
dfu = dfu.sort_values(by = 'time',ascending = True)
dfu = dfu.reset_index(drop = True) #reset_index()重置索引或其level
dfu.describe() #先按时间升序,再给出每列的四分位数,总数,平均值,方差等
reset_index()
重置索引或其level
reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=‘’)
drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False
inplace: 是否在原DataFrame上改动,默认为False
level: 如果索引(index)有多个列,仅从索引中删除level指定的列,默认删除所有列
col_level: 如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级
col_fill: 如果列名(columns)有多个级别,决定其他级别如何命名
例子:
df = pd.DataFrame([('bird', 389.0), ('bird', 24.0), ('mammal', 80.5), ('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'], columns=('class', 'max_speed'))
print(df)
print('\n')
df1 = df.reset_index()
print(df1)
print('\n')
df2 = df.reset_index(drop=True)
print(df2)
五、用户行为分析
(1)pv 和uv
PV:Page View 页面浏览量,即页面被多少人看过。指某段时间内访问网站或某一页面的用户的总数量,通常用来衡量一篇文章或一次活动带来的流量效果。PV可重复累计,用户每刷新一次即重新计算一次。
UV:Unique Visitor 唯一访问量,即页面被多少人访问过。同一用户不同时段访问网站只算作一个独立访客,不会重复累计
1)日访问量分析
计算每日的pv与uv,并做日期与其的图形
#pv_daily记录每天用户操作次数,uv_daily记录每天不同的上线用户数量
pv_daily = dfu.groupby('date')['user_id'].count().reset_index().rename(columns = {'user_id':'pv'})
#按date分组后计算user_id的计数,reset_index()加索引,rename改列名
uv_daily = dfu.groupby('date')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns = {'user_id':'uv'})
#drop_duplicates()去重
fig,axes=plt.subplots(2,1,sharex=True) #画板框架
pv_daily.plot(x='date',y='pv',ax=axes[0])
uv_daily.plot(x='date',y='uv',ax=axes[1])
axes[0].set_title('pv_daily') #加标题

分析:在12号左右,pv和uv访问量达到峰值,并且可以发现,uv和pv两个访问量数值差距比较大。
drop_duplicate
参数:
subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
df.drop_duplicates() #根据所有列删除重复的行
keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
df.drop_duplicates(subset=[‘brand’, ‘style’], keep=‘last’) #删除重复项并保留最后一次出现
inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
小时访问量分析
pv_hour记录每小时用户操作次数,uv_hour记录每小时不同的上线用户数量
pv_hour = dfu.groupby('hour')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_hour = dfu.groupby('hour')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
fig,axes = plt.subplots(2,1,sharex=True)
pv_hour.plot(x='hour',y='pv',ax=axes[0])
uv_hour.plot(x='hour',y='uv',ax=axes[1])
axes[0].set_title('pv_hour')
axes[1].set_title('uv_hour')
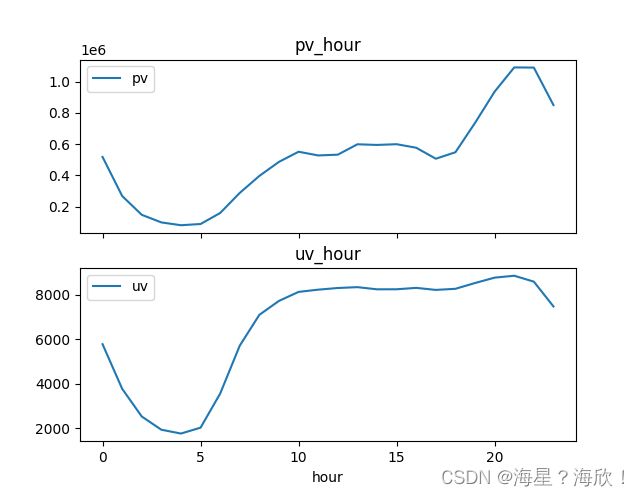
分析:0-5点pv和uv都较小,且趋势类似。在18点以后,uv有显著提升,且uv与pv都在18点以后逐渐达到峰值,因此晚上18:00以后是淘宝用户访问app的活跃时间段。
不同行为类型用户pv分析
pv_detail = dfu.groupby(['behavior_type','hour'])['user_id'].count().reset_index().rename(columns={'user_id':'total_pv']) #同上,只是分组分的更细,按行为类型与小时一起分类
fig,axes=plt.subplots(2,1,sharex=True)
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail,ax=axes[0]) #seaborn包有点问题
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail[pv_detail.behavior_type!=1],ax=axes[1]) #输出不含类型1的其他类型的图形,因为图一中由于类型1远超其他类型,导致其他类型的趋势不明显
axes[0].set_title('pv_different_behavior_type')
axes[1].set_title('pv_different_behavior_type_except1')

数字1、2、3、4分别表示点击、收藏、加购物车、支付四种行为
分析:点击这一用户行为相比较于其他三类用户行为,pv访问量较高,同时四种用户行为的波动情况基本一致,因此晚上这一时间段不管哪一种用户行为,pv访问量都是最高的。从图2可以看出,加入购物车这一用户行为的pv总量高于收藏的总量,因此在后续漏斗流失分析中,用户类型3应该在2之前分析。
六、用户消费行为分析
(1)用户购买次数情况分析
data_user_buy = dfu[dfu.behavior_type == 4].groupby('user_id')['behavior_type'].count()
sns.distplot(data_user_buy,kde = False)
plt.title('daily_user_buy')

分析:淘宝用户消费次数普遍在10次以内,因此购买次数在10次以上的消费者用户群体需要重点关注。
(2)日ARPPU
ARPPU(average revenue per paying user)是指从每位付费用户身上获得的收入,它反映的是每个付费用户的平均付费额度。
ARPPU=总收入/活跃用户付费数量
因为本数据集中没有消费金额,因此在计算过程中用消费次数代替消费金额
人均消费次数=消费总次数/消费人数
data_use_buy1 = dfu[dfu.behavior_type == 4].groupby(['date','user_id'])['behavior_type'].count().reset_index().rename(columns={'behavior_type':'total'}) #按日期和用户id后记数,记behavior_type的数
data_use_buy1.groupby('date').apply(lambda x:x.total.sum()/x.total.count()).plot() #按日期作图
plt.title('daily_ARPPU')

分析:平均每天消费次数在1-2次之间波动,双十二期间消费次数达到最高值。
(3)日ARPU
ARPU(Average Revenue Per User) :平均每用户收入,可通过 总收入/AU 计算出来。它可以衡量产品的盈利能力和发展活力。
活跃用户数平均消费次数=消费总次数/活跃用户人数(每天有操作行为的为活跃)
dfu['operation']=1
data_use_buy2 = dfu.groupby(['date','user_id','behavior_type'])['operation'].count().reset_index().rename(columns = {'operation':'total'})
data_use_buy2.groupby('date').apply(lambda x:x[x.behavior_type==4].total.sum()/len(x.user_id.unique())).plot()
plt.title('daily_ARPU')

(4)付费率
付费率 = 消费人数/活跃用户人数
data_use_buy2.groupby('date').apply(lambda x:x[x.behavior_type == 4].total.count()/len(x.user_id.unique())).plot()
plt.title('daily_afford_rate')

(5)同一时间段用户消费次数分布
data_use_buy3 = dfu[dfu.behavior_type == 4].groupby(['user_id','date','hour'])['operation'].sum().rename('buy_count')
sns.distplot(data_use_buy3)
print('大多数用户消费:{}次'.format(data_user_buy3.mode()[0]))

分析:大多数用户消费次数,1次
七、复购情况分析
复购情况:两天以上有购买行为,一天多次购买算一次
复购率=有复购行为的用户数/有购买行为的用户总数
date_rebuy = dfu[data_user.behavior_type==4].groupby('user_id')['date'].apply(lambda x:len(x.unique())).rename('rebuy_count')
print('复购率:',round(date_rebuy[date_rebuy>=2].count()/date_rebuy.count(),4))
复购率为0.8717
#所有复购时间间隔消费次数分布
data_day_buy=dfu[dfu.behavior_type==4].groupby(['user_id','date']).operation.count().reset_index()
data_user_buy4=data_day_buy.groupby('user_id').date.apply(lambda x:x.sort_values().diff(1).dropna())
data_user_buy4=data_user_buy4.map(lambda x:x.days)
data_user_buy4.value_counts().plot(kind='bar')
plt.title('time_gap')
plt.xlabel('gap_day')
plt.ylabel('gap_count')

分析:
八、漏斗流失分析
data_user_count=dfu.groupby(['behavior_type']).count()
data_user_count.head()
pv_all=dfu['user_id'].count()
print(pv_all)
输出:12256906
九、用户行为与商品种类关系分析
不同用户行为类别的转化率
data_category=dfu[dfu.behavior_type!=2].groupby(['item_category','behavior_type']).operation.count().unstack(1).rename(columns={1:'点击量',3:'加入购物车量',4:'购买量'}).fillna(0)
data_category.head()
data_category.head()
