python实现淘宝用户行为分析
数据分析实战项目之python用户消费行为分析
- 项目背景和前言
-
- 分析大纲
- **分析流程**
-
- 1.提出问题
- 2 .数据清洗
- 3. 数据分析
- 用户分析
- 商品分析
-
- 帕累托分析
- 总结
前言: 博主是一个正在学习数据分析的21届普通大学学生,在看到许多厉害的大学博主,自己也想尝试一下记录自己的成长,主要以交流学习为主有错误望指出,会虚心学习
项目背景和前言
背景: 现在电商行业发展越来越好,而竞争也越来越大。要想在营销运营上快竞争对手一步,利用现有数据分析用户行为进行精准营销,用户画像以及营销活动变得越来越重要。
数据来源:天池淘宝数据
数据介绍:数据截取了淘宝双12那一个月的用户行为数据,(行为包含点击、购买、加购、喜欢),行为时间戳,产品ID和产品类别ID。
用户ID:整数类型,序列化后的用户ID;
商品ID:整数类型,序列化后的商品ID;
商品类目ID:整数类型,序列化后的商品所属类目ID
行为类型:字符串,包括(“pv”:相当于点击,“buy”:商品购买,“cart”:将商品加入购物车,“fav”:收藏商品)
时间戳:行为发生的时间戳
工具:python3.8 pandas numpy等
分析大纲

分析流程: 提出问题–>数据清洗–>数据分析–>得出总结和建议
分析流程
1.提出问题
- 用户的活跃的时间段
- 用户行为转化率情况
- 用户复购率如何
- 用户的具体分类,如何把用户分类为有价值用户
- 商品销售符不符合二八定律(帕累托分析)
2 .数据清洗
# 导入数据 处理数据(处理时间戳,缺失值处理,删除geo列)
df = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')
df = df.dropna()
#把数据自带的字符时间转换成datetime对象,可以更好的拿出需要的时间段
time = pd.to_datetime(df['time'])
df['day'] = time.dt.time
df['week'] = time.dt.weekday
df['date'] = time.dt.date
#删除无用数据列
del df['time'],df['user_geohash']
# 把用户行为对应成相对应的pv collect buy
behavior = {1:'pv',2:'collect',3:'cart',4:'buy'}
df['behavior_type'] = df['behavior_type'].replace([1,2,3,4],['pv','collect','cart','buy'])
df.head()

3. 数据分析
3.1 流量分析 --->> 3.1.1总体流量分析
#总体流量,收藏,加购,下单
total_liu = df.groupby(['behavior_type']).size()
#总UV
# total_uv = df['user_id'].drop_duplicates().count()
total_uv = len(df['user_id'].unique())
print("总体流量为:\n",total_liu)
print(" ")
print("总体UV为: \n",total_uv)
总体流量为:
behavior_type
buy 3221
cart 8690
collect 6239
pv 302279
dtype: int64
总体UV为:
6425
3.1.2每日流量分析
#每日流量
#每日PV,收藏,加购,下单
day_liu = df.groupby(['date','behavior_type']).size().unstack()
#每日UV
daily_uv = df.groupby('date')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
daily_uv.plot(figsize = (12,3))
#由于购买,收藏,加入购物车无法看清,所以还要进行单独plot
for i in day_liu.columns:
plt.figure()
ax = day_liu[i].plot(figsize = (12,3))
ax.set_title(i+" "+"day of analysis")


1.从图标可以得出,UV PV 收藏 加购各项指标在双十二活动的影响下都呈稳步上升趋势 而由于14年双12并没有预结尾款的活动,这也导致了整个活动积攒的购买量都堆积到了双12当年
2.收藏数 加购数在双12前一星期上升最快,说明用户在活动前一星期是最容易产生购买决策的时候,应该加大推送力度
3.1.3 每时流量分析
#每时PV,收藏,加购,下单
hour_liu = df.groupby(['day','behavior_type']).size().unstack()
#每时UV
hour_uv = df.groupby('day')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
hour_uv.plot(figsize = (12,3))
#由于购买,收藏,加入购物车无法看清,所以还要进行单独plot
for i in hour_liu.columns:
plt.figure()
ax = hour_liu[i].plot(figsize = (12,3))
ax.set_title(i+" "+"hour of analysis")

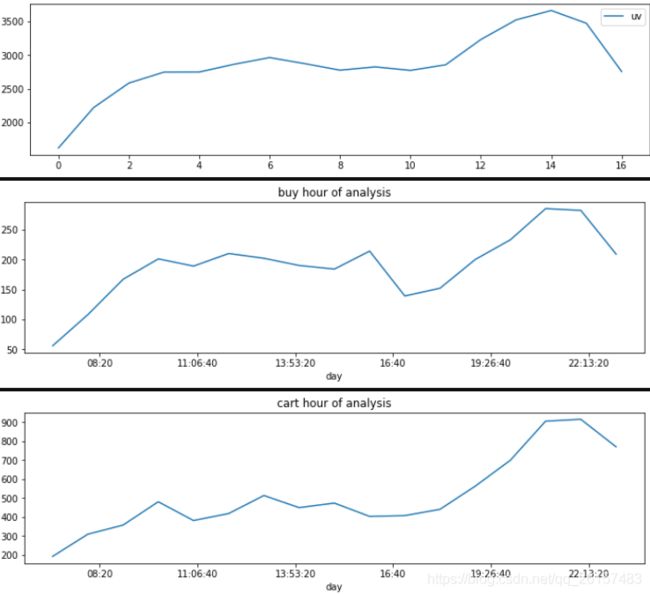
1.从图标知,用户一天时间内集中活跃在早上6-10时,下午5点到晚上10点,
这也符合人们的日常作息时间,所以在这段时间内要做好用户喜好产品的推送
2. 用户的buy与PV 收藏 加购相比,上升幅度并不明显,说明用户有想要购买的产品,但是碍于各种原因并没有下单,
推测应该是想等更优惠或者资金充裕的时候购买,所以建议推送相关优惠卷以及推出相关用户花呗免息活动来促使用户消费
3.2 流量漏斗转化
pv_to_car_collect = (total_liu.cart+total_liu.collect)/total_liu.pv *100
car_collect_to_buy = total_liu.buy/(total_liu.cart+total_liu.collect) *100
pv_to_buy = (total_liu.buy/total_liu.pv)*100
print("浏览到收藏加入购物车的转化率为: ",pv_to_car_collect)
print("购物车收藏到购买的转化率为 : ",car_collect_to_buy)
print("浏览到购买转化率: ", pv_to_buy)
浏览到收藏加入购物车的转化率为: 4.938814803542423
购物车收藏到购买的转化率为 : 21.57545716390917
浏览到购买转化率: 1.0655718723431002
*1.可以看出,在收藏和加购之后,的购买转化率远远大于其他的转化率,所以应该出活动鼓励用户多收藏或加购:例如加购减少额资金
2. 总的购买转化率超过了14年整个电商转化率的均值,说明淘宝的推送目标群体准确度还是很高的*
3.3复购率
cos_rebuy = df[df.behavior_type=='buy'].groupby('user_id')['date'].apply(lambda x:len(x.unique())).rename('rebuy_count')
print('复购率为 :',round(cos_rebuy[cos_rebuy>=2].count()/cos_rebuy.count(),4))
复购率为 : 0.3147
1.复购率远远高于其他电商平台,淘宝用户的忠诚度以及淘宝对用户的粘性在整个电商行业都属于佼佼者
3.4 跳失率 (用只产生pv行为的用户/总用户)
groupby_userid = df.groupby(by='user_id')
user_type = groupby_userid.behavior_type.value_counts().unstack().fillna(0)
#计算跳出率
# sum(axis=1)对DataFrame进行横向相加,如果一个userid的pv值==横向相加的和,那就表明他只有点击行为
only_pv_users = user_type[user_type['pv']==user_type.sum(axis=1)]
# only_pv_users.shape[0] 这个只有PV的总人数
bounce_rate = only_pv_users.shape[0]/total_uv
print("跳失率:{:.2f}%".format(bounce_rate*100))
跳失率:39.69%
分析: 跳失率达到了百分之40,一定程度上反应了商品的受欢迎程度。影响跳失率的原因一般有,界面UI不够吸引人,加载问题等要结合实际分析
用户分析
用户RFM价值分析
2.1用户RFM价值分析
最近一次消费(Recency)
消费频率(Frequency)
消费金额(Monetary)
由于此数据集中并没有消费金额数据,故只计算机消费频率和最近一次消费
#计算R:
df_rfm_group = df[df["behavior_type"]=='buy'].groupby('user_id')
#创建一个空的RF
RF = pd.DataFrame(index =df_rfm_group.groups.keys(),columns = ['R','F'] )
#这个月用户的消费次数
RF['F'] = df_rfm_group.count()
last_buy_time = df_rfm_group.date.max()
# pd.to_datetime(last_buy_time)
# 数据最新日期减去用户最后一次消费日期
RF['R'] = (pd.to_datetime(df.date.max())-pd.to_datetime(last_buy_time)).dt.days
RF.describe()
R F
count 1808.000000 1808.000000
mean 10.861726 1.781527
std 8.584597 1.838936
min 0.000000 1.000000
25% 4.000000 1.000000
50% 8.000000 1.000000
75% 17.000000 2.000000
max 30.000000 41.000000
# R我们划分4个区域 0-1,2-3,4-6,7-9,分别得分4,3,2,1
# F划分4个区域 1,2,3,4+,分别得分1,2,3,4
def get_R_score(x):
if 0 <= x <= 1:
return 4
elif 2 <= x <= 3:
return 3
elif 4 <= x <= 6:
return 2
elif 7 <= x <= 9:
return 1
else:
return 0
def get_F_score(x):
if x == 1:
return 1
elif x == 2:
return 2
elif x == 3:
return 3
elif x >= 4:
return 4
else:
return 0
#根据RF计算出他们的得分
RF['R_score'] = RF.R.map(get_R_score)
RF['F_score'] = RF.F.map(get_F_score)
RF.head()
R F R_score F_score
7591 12 4 0 4
12645 4 3 2 3
88930 6 5 2 4
113251 27 1 0 1
113960 15 2 0 2
# 判断各自的RF分数有没有大于对应的平均值
RF['R>mean?'] = (RF['R_score']>RF['R_score'].mean())*1#把True False 结果转换成可以计算的 1或者0
RF['F>mean?'] = (RF['F_score']>RF['F_score'].mean())*1
RF.head()
def user_classfication(tuple):
R_score, F_score = tuple
if R_score == 0 and F_score == 1:
return "重要保持客户"
elif R_score == 1 and F_score == 0:
return "重要发展客户"
elif R_score == 1 and F_score == 1:
return "重要价值客户"
elif R_score == 0 and F_score == 0:
return "重要挽留客户"
else:
return None
RF['user_classification'] = RF[['R>mean?','F>mean?']].apply(user_classfication, axis = 1)
R F R_score F_score R>mean? F>mean? user_classification
7591 12 4 0 4 0 1 重要保持客户
12645 4 3 2 3 1 1 重要价值客户
88930 6 5 2 4 1 1 重要价值客户
113251 27 1 0 1 0 0 重要挽留客户
113960 15 2 0 2 0 1 重要保持客户
RF.user_classification.value_counts()
重要挽留客户 661
重要发展客户 438
重要价值客户 395
重要保持客户 314
Name: user_classification, dtype: int64
#占比情况
RF.user_classification.value_counts(1).plot.bar()
RF.user_classification.value_counts(1)
重要挽留客户 0.365597
重要发展客户 0.242257
重要价值客户 0.218473
重要保持客户 0.173673
淘宝客户占比最高的是重要挽留客户其次是重要发展用户,说明对淘宝来说,还有很大的上升空间,可以对这一部分客户推送优惠卷,花呗免息等活动促进消费增加这部分群体客户的粘性和忠诚性
而对于重要价值客户,需要维持住这一部分群体,尽可能推送一些优质符合他们需求的商品,提高这部分用户的留存率和活跃率。同时,需要提高社群管理的效率,将重要保持客户和重要发展客户转变为重要价值客户,可采取定期发送文案、赠送优惠券等方式。要抓住用户渴望被认同、提升优越感、爱占便宜等心理进行考虑。
商品分析
对销量前10的商品种类 销量前10的商品进行分析
对于排好出来的商品最好从点击 和购买率进行分析
# 分析销量前十的具体商品
#获得商品ID和用户行为的Dataframe
item_10 = df.groupby('item_id').behavior_type.value_counts().unstack().fillna(0).sort_values('buy', ascending = False)
item_10['pv2_buy'] = item_10['buy']/ item_10['pv']
item_10.replace(np.inf, 0,inplace=True)
item_10.head(10)
#第二种方法
# product_buy=df.loc[df['behavior_type']=='buy',['user_id','item_id']]
# product_buy_count=product_buy.groupby('item_id')['user_id'].count().rename('销售次数')
# #转换为数据框,按列排序
# product_buy_count=pd.DataFrame(product_buy_count)
# #按照销售次数降序排序
# product_buy_count=product_buy_count.sort_values(by='销售次数',axis=0,ascending = False)
# #购买产品类目前10名
# product_buy_count=product_buy_count.iloc[:10,:]
# product_buy_count
#清楚异常值
item_10[(item_10.pv2_buy>0) & (item_10.pv2_buy<1)].head(10)

1.转化率极高(0.6,1),该商品也许是特定群体非常需要的,他们搜索和点击的目标比较明确。电商平台可以收集用户信息,分析用户画像,结合商品特点,核实是否如此。如果是某类特征明显的用户群体购买更多,可以集中向该类用户多推送。如果没有明显的群体需求,建议对这类商品多做推广,因为原有的购买量比较高,若是能够提高点击量,可能购买量也会再上一个台阶。
2.转化率一般(0.15,0.6),电商平台应该重点推送该商品,因为该商品有市场,并且可以多做活动,吸引更多的潜在客户变成购买客户。
3.转化率极低(0,0.15),该商品应该首先从商品本身进行分析,部分转化率极低而销量却排在靠前的商品可能通过广告赚取了一定的点击量,但是购买量相对点击量极低可能是因为用户因为广告推广点击了但是这类商品本身不是用户需要的,又或者是价格过高?社会热点造成了炒作营销导致用户好奇的点击?更深的原因需要结合更多的信息进行进一步分析。
商品种类分析
category_10 = df.groupby('item_category').behavior_type.value_counts().unstack().fillna(0).sort_values('buy', ascending = False)
category_10['cate_pv2_buy'] = (category_10['buy']/ category_10['pv'])
sns.distplot(category_10[(category_10['cate_pv2_buy']<=1)&(category_10['cate_pv2_buy']>0)]['cate_pv2_buy'],
kde=True)
plt.show()
category_10[(category_10.cate_pv2_buy>0) & (category_10.cate_pv2_buy<=1)].head(10)
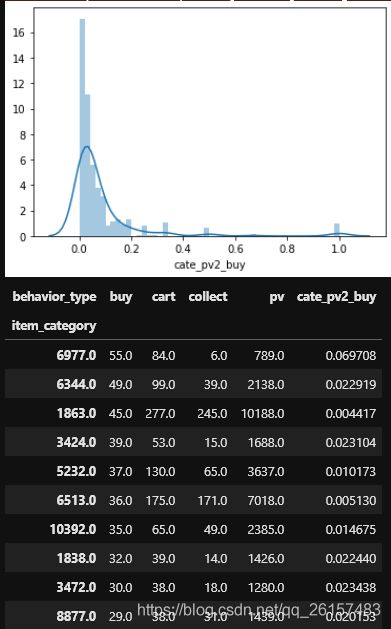
结论: 1,无论从总体还是前10种类的转化率来看,转化率都大部分在{0,0.015},少部分优秀的能到0.02
说明这类商品转化率低可能因为同一类商品包含很多种商品,用户存在“货比三家”的心理,
用户对于需要的该类商品可能不会购买多种商品,而是在该类商品中购买具体的一个商品。
建议: 提高这类商品的转化率,推荐精确与否是关键,可以考虑这类商品的精准定位,预测用户感兴趣的物品,
然后从用户可能感兴趣的商品类目中推荐有比较性的具体商品,这样可以减少用户比较多个商品来回跳转的点击量,
能在更短的时间做出比较并选择需要购买的商品。
帕累托分析
category_10['cumsum'] = category_10['buy'].cumsum()
key = category_10['buy'].sum()*0.8
category_10['class'] = category_10['cumsum'].map(lambda x: '80%' if x<=key else '20%' )
category_10['class'].value_counts(1)
20% 0.913589
80% 0.086411
Name: class, dtype: float64
总结:前80%销量有8%左右的商品品类提供,后20%的销量由92%左右的商品品类提供,接近二八定律所表示的由少数商品品类掌控了大部分的销量
总结
整体终结与建议:
1.总体用户活跃具有规律性,在活动前一周加购和收藏数上升,在每天的早上7-10 下午17:00-20:00用户访问会增加,而在工作日用户会比休息日要活跃
建议在这断时间加大推送以及直播带货等
2. 在收藏加购后的购买率能达到百分之20
推出加购收藏优惠活动,提高加购收藏率
3. 通过RFM分析,得出重要挽留部分占36.55%,重要发展占24.22%,重要价值客户占21.8%,重要保持客户17%
重要价值用户:推出更个性化服务,推荐更贴近这类客户需求的商品
重要发展:想办法提高消费频率,推送购物车收藏里面的优惠卷,花呗免息等
重要挽留:分析哪出了问题,推送感兴趣的商品,并促进消费
重要保持:主动联系他们,例如活动推送,其他网站广告引流等
4.商品分析: 整体的类别转化率过低
推出更精确的推送,例如买别的网站数据等,在销量前十的商品中,有的转化率很高可以模仿一下。
由于使用的数据集是2014年的淘宝数据,这也导致有的结论看上去有点奇怪。
参考博客:
博客1
博客2
博客3