阿里推荐算法:BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transform
这篇是阿里猜你喜欢的一篇transformer paper,含金量很高。
注意:
1.bert用在推荐系统中,将用户的历史序列看做是词序列。
2.测试时,将序列的最后一个item进行masked
Abstract:
根据用户历史的行为信息,对用户动态的偏好衍变进行建模,是对推荐系统产生的巨大挑战。现有算法使用序列神经网络,只能从左向右,利用单向信息进行建模。尽管这些放大得到了很好的效果,但是他们设定的严格顺序是不实际的。因此,本文提出针对推荐系统的transformer的双向编码器表示。由于利用深度双向信息会造成信息的泄露,为了解决这个问题,本文使用Cloze task训练模型,利用上下文信息预测masked item。相比于预测next item,Cloze task可以产生多个训练样本。实验证明,本文提出的方法在多个数据集上效果明显
Introduction
精确地捕捉用户的兴趣,是推荐系统的核心问题。在实际生活中,用户的兴趣是根据历史偏好进行动态变化的。为了捕捉用户的偏好的动态变化,提出了许多根据用户历史交互信息的序列推荐算法,最早使用马尔科夫对用户序列进行建模,其中一些方法的强假设破坏了推荐系统的准确性。近期,一些序列神经网络在序列推荐问题中取得了不俗的效果。最基本的思想就是将用户的历史序列自左向右编码成一个embedding,然后基于这个embedding进行推荐。
本文认为自左向右的序列推荐算法限制了用户历史信息的发挥。无论是RNN还是MCs,都具有一定的顺序性。而这种顺序性的假设,对于实际生活中的用户行为并不适用。例如下图,三个口红的点击顺序对于用户的推荐并没有什么差别。因此,本文认为双向模型对于序列推荐问题更有效。
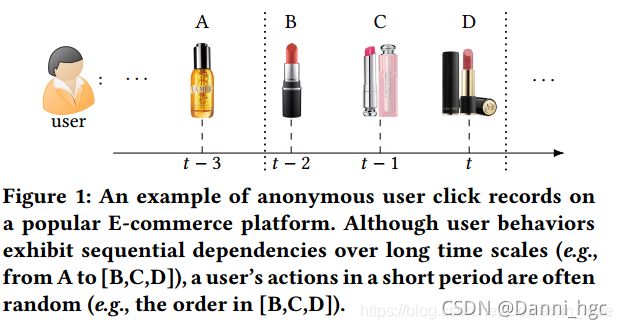
由于用户的行为序列很像是文本序列,而Bert是目前最好的自然语言处理模型。但是Bert不能直接用到序列推荐问题。如图,同时利用双向信息会造成信息的泄露,为了解决这个问题,采用了Cloze task,将输入序列进行随机的mask,然后利用上下文信息,预测mask item。利用cloze task任务还可以产生大量的训练样本。因为训练过程和最终的任务(预测序列的下一项)不匹配,所以在预测过程,我们将mask 加入到输入序列的最后,然后利用mask的embeeding进行推荐。
创新点:
1:提出了一种基于双向self-attention的cloze take用户行为序列建模方法。据我们所知,这是第一个将双向self-attention的cloze take用户行为序列建模引入推荐系统的算法。
2:我们将我们的模型与最先进的方法进行了比较,并通过对四个基准数据集的定量分析,证明了本文算法的有效性。
3:我们进行了一项消融分析,分析了模型中关键部件的影响
BERT4REC
一:问题定义:定义U={u1,…,un}为用户序列,V={v1,…,vn},Su={u1u,…,un u }为用户u和商品的交互数据。目标就是预测用户下一次点击的商品,即
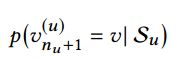
二:模型结构:如图b,是L层的Transformer,每一层利用前一层所有的信息。相比于图d的基于RNN的推荐模型,self-attention可以捕获任意位置的信息。相比于基于cnn的推荐模型,可以捕获整个field的信息。相比于图2c和图2d的模型(都是l2r的单向模型),本文提出的双向模型可以解决现有模型的问题
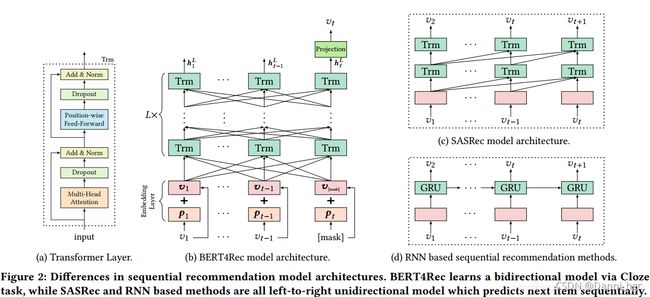
1:Transformer层
如图a,Transformer层有两层组成a Multi-Head Self-Attention sub-layer 和a Position-wise Feed-Forward network
1).a Multi-Head Self-Attention sub-layer:在各种任务中,注意机制已经成为序列建模的一个组成部分,允许建模表示对之间的依赖关系,而不考虑它们在序列中的距离。以前的工作表明,在不同的位置联合处理来自不同表示子空间的信息是有益的[6,29,52]。因此,我们在这项工作中采用了Multi-Head Self-Attention代替单一的attention。特别地,Multi-Head Self-Attention就是将H通过不同的线性映射函数映射到h的子空间,然后将其concatenated后再一次映射
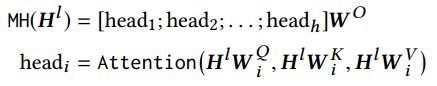
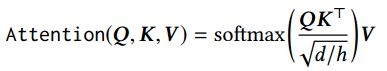
2)a Position-wise Feed-Forward Network:由于只有线性映射,为了使得模型具有非线性的性质,所以采用了a Position-wise Feed-Forward Network。使用了Gaussian Error Linear Unit,Φ(x)是高斯分布的累积分布函数,W (1) ∈ Rd×4d , W (2) ∈ R4d×d , b(1) ∈ R4d和b(2) ∈ Rd对所有位置共享,但是层与层之间不一样。
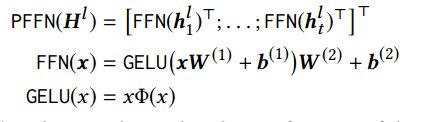
3):Stacking Transformer Layer:可以学到更多item之间的交互信息,但是模型复杂了之后就不能训练深度模型,因此两个sub-layer在normal之后加入了residual connection,并且在每一个sub-layer输出后加入了dropout,LN是normal layer,其中μ和σ分别是均值和标准差,⊙是点乘,γ是scale因子,ϵ是一个很小的因子,为了防止分母为0:
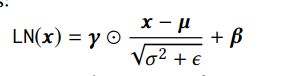
2:模型总体:
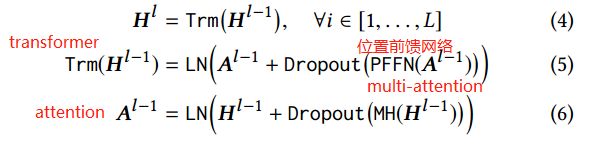
3:Embedding层:**由于没有使用cnn和rnn,所以self-attention没有关注input序列的顺序性,因此加上位置向量,本文的位置向量是学到的,不是transformer中的正弦。**位置向量矩阵可以给定任意位置的向量,但是要明确最大的长度,因此需要对input序列进行截断:
![]()
4:Output层:用最后一层的向量进行预测。接入softmax,判断这个位置的item是什么。这里使用两层带有RELU激活函数的前馈网络,其中E是item的我们倍额定,和input层一致。wP是映射举着,bp和bo是bias
![]()
三:训练过程:单向模型的训练都是通过预测输入序列下一个位置。双向模型预测时可能会造成信息泄露,所以采用cloze taske,也就是将输入序列中的p%的词进行masked,然后根据上下文信息预测masked的词
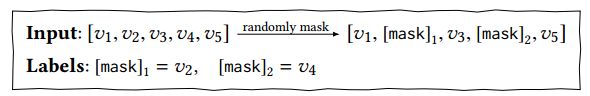
将masked最终向量输入到softmax,损失函数定义如下:
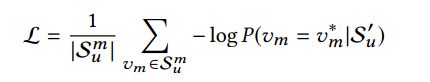
如上所述,我们在训练过程和最终的序列推荐任务之间是不匹配的。因为
cloze taske的目的是预测当前的masked,而序列推荐的目的是预测未来。为了解决这个问题,我们将masked附加到用户行为序列的末尾,然后根据该maske的最终隐藏表示来预测下一项。为了更好地匹配序列推荐任务(即,预测最后一项),我们还生成了在训练过程中只屏蔽输入序列中最后一项的样本。实验证明效果不错。