Bert入门学习过程记录
学习记录
- 0 学习情况介绍
- 1 知识点扫盲
-
- 1.1 Attention
- 1.2 Transformer
- 2 相关模型
-
- 2.1 语言模型
- 2.2 seq2seq
- 2.3 Attention seq2seq
- 2.4 Transformer
- 2.5 Bert
- 3 使用Bert预训练模型
-
- 3.1 相关资源
- 2.2 应用举例
0 学习情况介绍
本文记录的是一个新手学习bert的过程,本人只有一些基础模型和基础模型代码编写的基础,算是一个深度学习的freshman,如果你也和我类似可以参考我的学习过程,这样也许会让你学的更顺畅一点,如果不是新手的话可能对你没有什么帮助。
我的目的是简单的应用一下bert,以便在后续项目中使用bert时,可以比较快速的上手。大概过程就是,首先看了bert的论文和一些介绍bert的文章(csdn、知乎),初步了解一些bert和它的模型,开始即便看不太懂也没关系,这一步的作用是让你带着问题去搜索相关知识,比如什么是Attention,什么是Transformer;得到问题后,先从你有基础或者你觉得最简单的地方一点一点看起,将需要的基础知识补充完毕后,可以对比相关模型学习bert模型,比如语言模型、seq2seq等;经过上面两步,你大概已经了解了bert的含义及其模型架构,下面就是把理论变成应用,建议先找一些bert简单应用的文章学习,知道了调用bert预训练模型的大致过程后,结合GitHub上bert使用的介绍进行对比学习,直接看官网介绍对新手来说不太友好。
1 知识点扫盲
首先要知道bert是什么,从全称Pre-training o f Deep Bidirectional Transformers for Language Understanding可以看出bert是一个深层双向的Transformer的预训练模型。这里涉及到两个概念Transformer和预训练模型,Transformer会在后面介绍。
预训练模型就是一个已经训练好的保存下来的网络模型,你可以理解为保存了训练得到的参数矩阵weight。预训练模型一般是用较大的数据集训练好的模型(这种模型往往比较大,训练需要大量的内存资源),所以将训练好的模型保存下来可以让其他无法进行如此大规模计算的人使用,你可以用这些预训练模型用到类似的数据集上进行模型微调。bert微调应用会在后续给出。
1.1 Attention
Attention的理解推荐两个学习途径:
1.在这里找到序列模型课程,学习里面3.7和3.8节。
2.文章
途径1学习笔记:
3.7.注意力模型直观理解
当句子很长时,编码-解码型的模型效果会变小。因为神经网络不擅长记忆过长的句子。
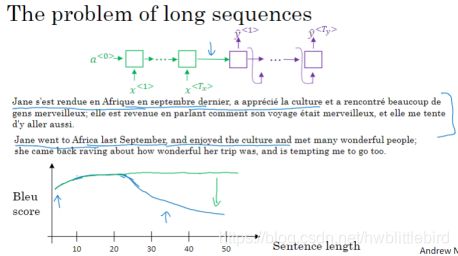
注意力模型是计算注意力权重,使翻译过程更像人工翻译。
大概过程:(用一个短句举例说明一下)
首先使用一个双向RNN计算每个输入单词的特征集,但并不是为了翻译每个单词,所以把输出y_hat先去掉。
然后用另一个RNN模型来实现英文翻译,此处为了避免混淆不在用a来表示RNN的隐藏状态。当你想要生成第一个输出,我们应该看输入是法语句子的哪个部分,用a<1,1>来表示当你生成第一个词时,你应该放多少注意力在法语的第一块信息处,然后看第二个法语在第一个英文输出的注意力权重a<1,2>,以此类推,把这些权重会作为翻译RNN每一步输入的一部分。
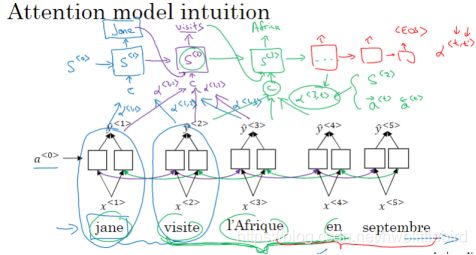
3.8.注意力模型
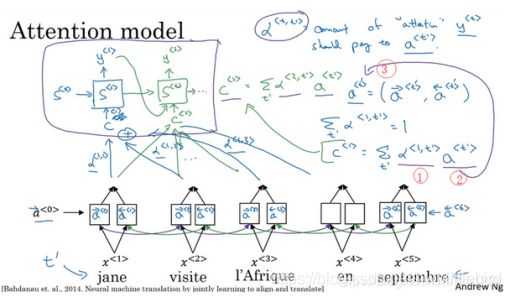
这个 a 参数告诉我们上下文有多少取决于我们得到的特征,或者我们从不同时间步中得到的激活值。所以我们定义上下文的方式实际上来源于被注意力权重加权的不同时间步中的特征值。
这里的这项(下图编号1所示)就是注意力权重,这里的这项(下图编号2)来自于这里(下图编号3),于是 a^
换句话来说,当你在 t 处生成输出词,你应该花多少注意力在第 t’ 个输入词上面,这是生成输出的其中一步。
当你在t处生成输出词时,你应该花多少注意力在第t’个输入词上,这是生成输出的其中一步,其他步骤类似。将权重与输入词特征相乘,然后将结果以一定的方式相加,这就产生了一个新的上下文,用c来表示
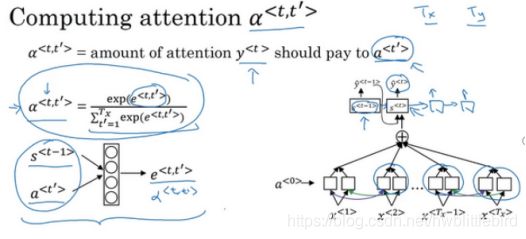
这个式子你可以用来计算 a^
a^
1.2 Transformer
Transformer模型的学习推荐:
https://blog.csdn.net/longxinchen_ml/article/details/86533005
Transformer包括encoder和decoder,encoder就是接收源句子的词向量进行类似上下文语义融合的过程,decoder就是根据encoder的输出和目标句子的词向量得到完成的目标句子。
其实质和Attention seq2seq模型的运算过程类似,知识将其中的RNN模块换成了Attention模块。上面的推荐文章可以很好的帮助你理解Transformer的encoder部分,bert模型也只用到了Transformer的encoder部分,所以上文已经足够,如果想深入理解decoder部分可以参考文章。
https://zhuanlan.zhihu.com/p/127774251
2 相关模型
这部分主要是通过相似模型之间的对比,让自己能够更加深入的理解模型,并加深记忆。其实bert的本质就是一个语言模型,都是通过对语言的学习,通过训练得到的参数记录语义,使模型可以理解句子的含义,就和人学习的过程类似。
可以通过比较模型的输入、输出、数据的传递和模型的用途,理解不同模型之间的关系。下面知识我在学习相关模型时的记录,帮助不大,可以搜索相关文章学习。
2.1 语言模型
吴恩达《深度学习》笔记:
如何建立一个语言模型:
为了使用RNN建立出这样的模型,你首先需要一个训练集,包含一个很大的英文文本语料库(corpus)或者其它的语言,你想用于构建模型的语言的语料库。语料库是自然语言处理的一个专有名词,意思就是很长的或者说数量众多的英文句子组成的文本。
第一件事就是将这个句子标记化,意思就是像之前视频中一样,建立一个字典,然后将每个单词都转换成对应的one-hot向量,也就是字典中的索引。
句子的结尾,一般的做法就是增加一个额外的标记,叫做EOS。

建立RNN模型,我们继续使用“Cats average 15 hours of sleep a day.”这个句子来作为我们的运行样例,我将会画出一个RNN结构。
RNN中的每一步都会考虑前面得到的单词,比如给它前3个单词(上图编号7所示),让它给出下个词的分布,这就是RNN如何学习从左往右地每次预测一个词。

经过训练后:
第一次输入x1=0的输出y1是一个10000维的向量,表示词汇表里10000个词出现的概率。
当确定了x2是哪个单词后,第二个输出y2就是当x^2出现的条件下,词汇表里10000个词出现的概率。
依次类推。
如果你用很大的训练集来训练这个RNN,你就可以通过开头一系列单词像是Cars average 15或者Cars average 15 hours of来预测之后单词的概率。现在有一个新句子,为了简单起见,它只包含3个词(如下图所示),现在要计算出整个句子中各个单词的概率,方法就是第一个softmax层会告诉你 y^<1> 的概率(下图编号1所示),这也是第一个输出,然后第二个softmax层会告诉你在考虑 y^<1> 的情况下 y^<2> 的概率(下图编号2所示),然后第三个softmax层告诉你在考虑 y^<1> 和 y^<2> 的情况下 y^<3> 的概率(下图编号3所示),把这三个概率相乘,最后得到这个含3个词的整个句子的概率。
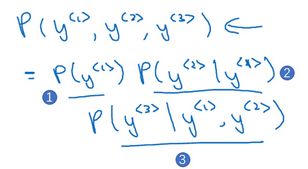
2.2 seq2seq
seq2seq实际上就是一个encoder-decoder模型,通过encoder过程得到的源句子语义,计算出目标句子。
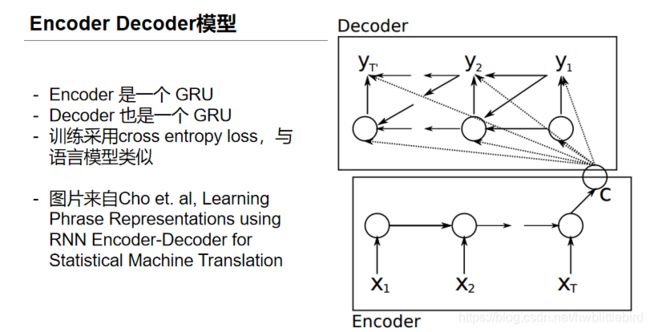
seq2seq模型:翻译模型由编码网络和解码网络组成。
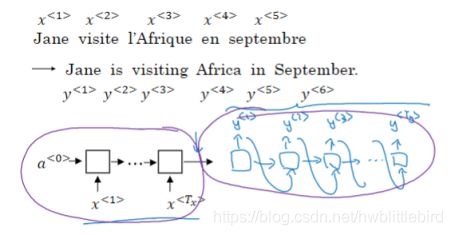
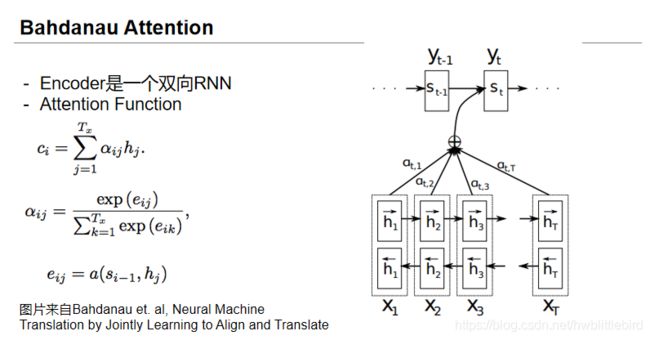
2.3 Attention seq2seq
Attention seq2seq就是在encoder和decoder之间加了一层Attention,目的是使decoder不仅仅关注encoder的最终输出,而是关注encoder的每一个hidden state,使目标词可以对用到与之关联的输入词上。
2.4 Transformer
Transformer是在论文《Attention is all you need》中提出的,重点理解其中的self-Attention,学习材料已在上文推荐。
2.5 Bert
给出学习材料:
1.论文:BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
2.论文翻译:https://blog.csdn.net/muumian123/article/details/84031163
3.bert github官网:https://github.com/google-research/bert
4.一文读懂bert:https://blog.csdn.net/jiaowoshouzi/article/details/89073944
5.bert模型图解:https://cloud.tencent.com/developer/article/1389555
3 使用Bert预训练模型
3.1 相关资源
1.bert封装库:https://www.zhihu.com/question/385026292/answer/1130498448
2.transformers库:(支持pytorch和tf2.0)https://github.com/huggingface/transformers
3.中文模型下载:https://github.com/ymcui/Chinese-BERT-wwm
2.2 应用举例
1.使用bert进行文本分类的简单应用:https://zhuanlan.zhihu.com/p/112655246
该文中模型下载部分需要注意,必须是转换成pytorch版本的模型才能够在该代码中使用,如果下载的模型没有进行pytorch转换会提示没有pytorch_model.bin文件的错误。如果出现该错误只需要选择一个有该文件的pytorch版本的模型即可。