ElasticSearch+kibana的安装
目录
1.什么是Elasticsearch:
2.Elasticsearch 的基本概念:
3.安装Elasticsearch
4.安装kibana
1.什么是Elasticsearch:
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值全文检索是指对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当查询时,根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
2.Elasticsearch 的基本概念:
(1)index 索引:索引类似于mysql 中的数据库,Elasticesearch 中的索引是存在数据的地方,包含了一堆有相似结构的文档数据。
(2)type 类型:类型是用来定义数据结构,可以认为是 mysql 中的一张表,type 是 index 中的一个逻辑数据分类。
(3)document 文档:类似于 MySQL 中的一行,不同之处在于 ES 中的每个文档可以有不同的字段,但是对于通用字段应该具有相同的数据类型,文档是es中的最小数据单元,可以认为一个文档就是一条记录。
(4)Field 字段:Field是Elasticsearch的最小单位,一个document里面有多个field
(5)shard 分片:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。
(6)replica 副本:任何服务器随时可能故障或宕机,此时 shard 可能会丢失,通过创建 replica 副本,可以在 shard 故障时提供备用服务,保证数据不丢失,另外 replica 还可以提升搜索操作的吞吐量。
shard 分片数量在建立索引时设置,设置后不能修改,默认5个;replica 副本数量默认1个,可随时修改数量。
3.安装Elasticsearch
一、安装jdk1.8
配置环境变量
使用vim /etc/profile编辑profile文件
在/etc/profile底部加入如下内容
#java environment
export JAVA_HOME=/usr/java/jdk1.8.0_11
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
其中/prog/java是jdk存放路径
最后使用source /etc/profile让profile文件立即生效。
使用java -version 测试是否安装成功
二、安装es不能用root用户,需要新建用户
--创建用户和组
groupadd esgroup
useradd -g esgroup esuser
三、修改系统配置:
(a)设置内核参数
vim /etc/sysctl.conf
添加如下内容:
fs.file-max=65536
vm.max_map_count=262144
sysctl -p 刷新下配置,sysctl -a查看是否生效 如果不成功的(启动es还是失败,不是所有人都碰得到,好像是在7.6碰到了):
rm -f /sbin/modprobe
ln -s /bin/true /sbin/modprobe
rm -f /sbin/sysctl
ln -s /bin/true /sbin/sysctl
b)设置资源参数
vi /etc/security/limits.conf
# 添加一下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
c)修改进程数
vi /etc/security/limits.d/20-nproc.conf
* soft nproc 4096
配置完成后 要关掉链接窗口,重新打开一个防火墙关闭
firewall-cmd --reload firewall-cmd --list-port firewall-cmd --zone=public --add-port=15601/tcp --permanent firewall-cmd --list-port
修改es配置文件:vim /opt/elasticsearch-7.13.0/config/elasticsearch.yml
# 配置es的集群名称, es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: bi-cluster
# 节点名称
node.name: node-master
# 存储数据的目录
path.data: /home/elasticsearch/data
# 存储日志的目录
path.logs: /home/elasticsearch/logs
# 设置绑定的ip地址还有其它节点和该节点交互的ip地址
network.host: 0.0.0.0
# 指定http端口,你使用head、kopf等相关插件使用的端口
http.port: 9200
# 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9300
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
discovery.zen.ping.unicast.hosts: ["10.108.4.203:9300", "10.108.4.204:9300", "10.108.4.205:9300"]
#如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 - 分裂的大脑 - 这将导致数据丢失
discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true #es5.x版本以上需要,head访问
http.cors.allow-origin: "*"
bootstrap.memory_lock: false #某些系统需要 是因为centos6.x操作系统不支持SecComp,而elasticsearch 5.5.2默认 bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
bootstrap.system_call_filter: false
elasticsearch.yml 例子
注意,要放开某些注释:
discovery.seed_hosts: ["host1"]
cluster.initial_master_nodes: ["node-1"]
cluster.name: my-es
node.name: node-1
network.host: 0.0.0.0
http.port: 19200
transport.tcp.port: 19300
#discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"]
#discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.memory_lock: false
bootstrap.system_call_filter: false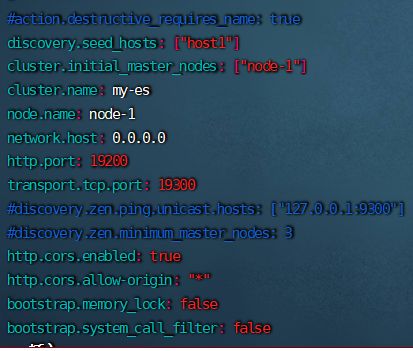
jvm.options
修改:
-Xms1g
-Xmx1g
目录授权:
chown -R esuser elasticsearch-7.13.0
切换用户:
su esuser
启动es:./bin/elasticsearch
打开浏览器访问 http://你的ip:19200/查看是否能够正常访问,看到以下界面表示启动ok

4.安装kibana
修改kibana.yml
vim kibana.yml
server.port: 15601 server.host: "0.0.0.0" elasticsearch.hosts: ["http://localhost:19200"]
给esuser附kibana-7.13.0-linux-x86_64权限
chown -R esuser kibana-7.13.0-linux-x86_64
切换到esuser
su esuser
启动kibana
./bin/kibana
访问ip:15601出现下面图片启动成功