第十次周报
第十次周报
- 摘要
- RNN
-
- 公式推导
- 为什么使用tanh激活函数
- 为什么会出现梯度消失或梯度爆炸
- 代码实现
- LSTM
-
- 公式推导
- 文献阅读
- 总结
摘要
This week, I read a review paper on text recognition and detection, and I analyzed the mathematical formulas of recurrent neural networks. The biggest highlight of this review paper is to summarize the problems in the field, and I thought about the questions posed by the author.
本周我阅读了一篇关于文本识别和检测的综述型论文,并且我分析了循环神经网络的数学公式。这篇综述论文最大的亮点是总结了该领域存在的问题,我对作者提出的问题进行了思考。
RNN
上个周对模型结构进行了分析,这个周主要学习对RNN模型的推导、用数学解释一些上周遇到的相关问题和代码实现
公式推导

为什么使用tanh激活函数
没有tanh激活函数的情况:

由图可以看到,RNN层数越深,越可能出现状态h的值变得非常高或非常低
tanh激活函数的作用就是对h进行规范化处理,将数值恢复到(-1,1)范围内
为什么会出现梯度消失或梯度爆炸

代码实现
用RNN在IMDB数据集上实现情感分析
max_features = 10000 # 保留前10000个高词频的词 (词典里有10000个词汇)
embedding_dim = 32 # 词向量x的维度是32
maxlen = 500 # 序列长度 (每个电影评论有500个单词)
state_dim = 32 # 状态向量h的维度是32
(train_data,train_label),(test_data,test_label) = imdb.load_data(num_words=max_features)# 保留训练数据中前 10000 个最常出现的单词,舍弃低频词
train_data = sequence.pad_sequences(train_data,maxlen=maxlen) # 规定序列长度为500,大于截断,小于补0
test_data = sequence.pad_sequences(test_data,maxlen=maxlen)
models = tf.keras.Sequential([
tf.keras.layers.Embedding(max_features,embedding_dim,input_length=maxlen), # 把输入的词映射到 自定义维度的词向量x
#Embedding 的维度要由交叉验证来确定
tf.keras.layers.SimpleRNN(state_dim,return_sequences=False),#输入词向量x,输入状态h,h的维度由自己确定
tf.keras.layers.Dense(1,activation='sigmoid')
models.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='binary_crossentropy',metrics=['acc'])
history = models.fit(train_data,train_label,epochs=3,batch_size=128,validation_data=(test_data,test_label))
# epochs=3 是因为出现了过拟合,3个轮次后,验证集的准确率会变差,所以让算法提前停止
])
效果:
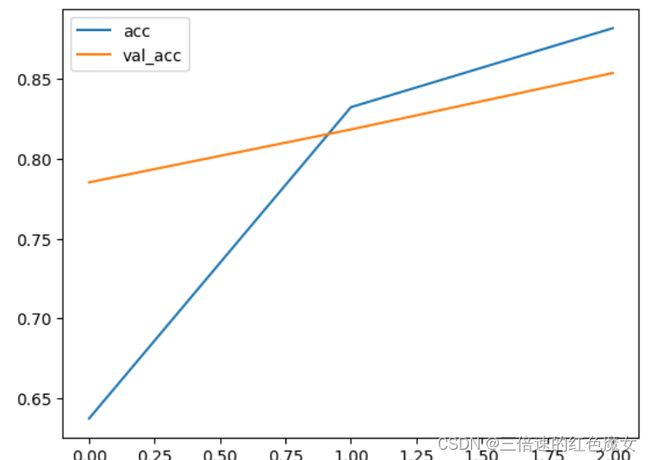
总结:RNN擅长解决 短期依赖问题(short-term dependence),不擅长解决 长期依赖问题(long-term dependence)会产生遗忘。
LSTM
公式推导

文献阅读
《Text Detection and Recognition in Imagery: A Survey》
作者:Qixiang Ye and David Doermann
摘要:这篇文章分析了文本检测和文本识别技术应用于彩色图像的研究中,存在的挑战、方法以及表现。它不仅总结了这些问题,还列举了在解决这些问题时应考虑的因素,并比较了最具代表性的方法的性能。它还对该领域的剩余问题进行了基本的比较和分析。
总结:这是一篇大而全的文章,逻辑清晰且结构完整,既包含了文本检测和文本识别过去十年到现在的背景起源,基础理论和发展,又涵盖了作者对于该领域目前存在问题以及前景的展望,通读下来,我作为普通科研水平的读者,也能对其有个大致详细的了解,从中不仅学习了作者的写作手法,对如何评价综述性论文又有了更深的了解,下面主要摘取一部分阅读论文的思考作为汇报内容
多语言内容(Multilingual Content)
人们提出了各种特定语言的方法来检测和识别文本。现有的方法只存在验证多语言检测能力,但其中很少涉及多语言识别能力。检测中的模式差异来自于字体大小和笔画分布,这与字符结构、形状和类数有关。谷歌的研究人员表明,Tesseract OCR模块所使用的分类器可以适应于各种语言。在最近的端到端PhotoOCR系统中,他们通过集成多种检测方法和采用基于深度学习的识别,将多语言能力扩展到29种语言。
处理多语言文本(Processing multilingual text)
来自不同语言的文本表现出不同的特征,处理多语言文本被认为是一个极其困难的问题。使用带有固定参数的单一方法来识别所有语言中的文本仍然难以实现。一种可能的解决方案是使用一种通用的可训练的方法来为每种语言指定一个模型,并使用一种可配置的方法来管理这些模型。
思考:
目前处理多语言文本的模型已层出不穷,绝大部分的思想是收集更多高质量的语料库结合优秀的算力不断的训练更深的神经网络模型,看上去好像解决了作者在这篇综述中提出的问题,但处理多语言文本在处理方言、小语种方面的任务时还并不理想,最根本原因就是缺乏高质量语料库。
人类的语言是会自然分裂的,比如:德语与英语属于近亲,二者都是以日耳曼语为主体发展演变而来的。那么在一个国家不同的语言之间,是否存在一些共同的特征(比如:语法)?机器通过已学习到的语言,能否总结出共同的特征,创造出一个中间语言?使得通过中间语言,从而让机器自己学会这些小语种和方言,或者将语音融合进处理多语言文本的技术中,是否在处理多语言文本中表现会更好?
总结
本周推导了RNN数学公式以及代码实现,下周研究将任意波函数写成RNN结构。