广告行业中那些趣事系列46:一文看懂Transformer中attention的来龙去脉
导读:本文是“数据拾光者”专栏的第四十六篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇重点介绍了Transformer中attention的来龙去脉,包括self-attention的几何意义以及与Transformer中attention的区别和联系,对于希望进一步了解Transformer中attention机制的小伙伴可能有所帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇重点介绍了Transformer中attention的来龙去脉。首先回顾了Transformer中注意力机制的计算流程;然后通过图解的方式详细介绍了self-attention,剖析公式理解self-attention核心是经过注意力机制加权求和;最后对比了Transformer中attention和self-attention的区别和联系,不仅要理解注意力机制的计算流程,而且要明白注意力机制背后的意义。对于希望进一步了解Transformer中attention机制的小伙伴可能有所帮助。
下面主要按照如下思维导图进行学习分享:
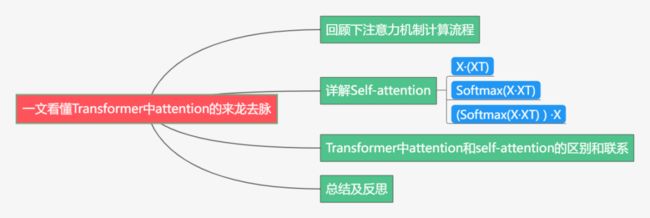
01
回顾下注意力机制计算流程
之前写过一篇关于Transformer的文章《广告行业中那些趣事系列4:详解从配角到C位出道的Transformer》,重点从宏观和微观的视角介绍Transformer,当时对注意力机制的计算流程也进行了详细的介绍,但一些细节问题总觉得还差点火候。最近重读了论文以及很多关于Transformer和self-attention的文章,对一些之前似懂非懂的问题有了更深刻的了解。
Transformer中最重要的是注意力机制self-attention,Self-attention是用于计算当前词对所有词的注意力得分。整体来看注意力机制流程输入是文本的词向量X(假如维度是512),输出的是经过注意力得分计算加权之后的向量Z,维度和X一样。下面以查看thinking对所有词的注意力得分为例,主要计算流程如下:
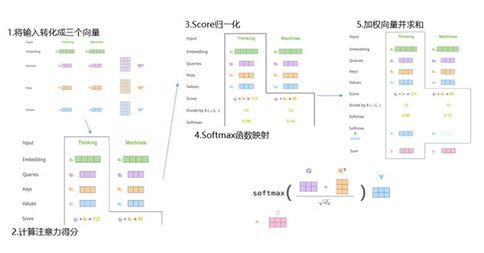
图1 self-attention计算注意力得分流程
将输入词向量X转化成Q、K、V三个向量。词向量X(1X512)和三个不同的权值矩阵WQ、WK、WV相乘得到查询向量Q(1X64)、键向量K(1X64)和值向量V(1X64)。这三个权值矩阵是模型训练得到的参数,维度都是512X64维。这里Q、K、V其实是X的线性变换,至于为什么这么做,后面会进行详细介绍;
计算当前词对所有词的注意力得分。比如我们计算"thinking"的注意力得分,将"thinking"的查询向量q1分别和所有词的ki点积相乘得到一个得分score。这个得分代表当前词对其他词的注意力。
score归一化和softmax函数映射。使用score归一化的目的是为了梯度稳定,分别将score除以键向量维度的算术平方根(论文中默认为8)。然后通过一个softmax函数将得分映射为0-1之间的实数,并且归一化保证和为1;
计算最终的注意力得分。计算softmax值和值向量v1相乘得到加权向量,然后求和得到z1为最终的自注意力向量值。目的是保持相关词的完整性,同时可以将数值极小的不相关的词删除。
上述整个流程就是通过张量计算展示自注意力层是如何计算注意力得分的。整体公式如下所示:

图2 注意力机制计算公式
整体来看:输入X,输出Z。X是一句话对应的词向量矩阵,假如“我喜欢吃苹果”,那么会得到6X512维矩阵,这里6是词的数量(以单字进行切分),512是词向量的维度(作为模型参数可设置)。Z的输出维度和X是一样的,相比于X来说Z是经过注意力加权得分计算之后的矩阵,矩阵可以反映出词与词之间的关注度,关注度越高说明越有相关性。比如“苹”和“果”的相关性比较高,那么对于“苹”来说就应该对“果”有更高的关注。
02
详解Self-attention
上面介绍了Transformer中注意力机制的计算流程,但是为什么要这么做,这就需要从self-attention最原始的公式进行理解。下面是self-attention最原始的公式:
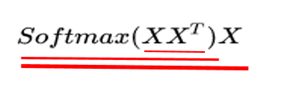
图3 self-attention最原始的公式
根据上图中红线的粗细程度层层剥离公式,原始的self-attention主要包括三步:
X·(XT)。这里需要明白矩阵X点乘的结果有什么意义。矩阵是由多个向量组成,比如下图中矩阵X包含6个向量,分别是“我喜欢吃苹果”对应的字向量。矩阵相乘其实可以理解为向量之间计算内积,比如对于字向量“我”来说,会分别和“我喜欢吃苹果”所有的字向量计算内积,而向量内积的几何意义是表征两个向量的夹角,表征向量a在另一个向量b上的投影。向量a和向量b的夹角越小,那么a在b上的投影越大,则证明两者越相似,相关度越高。极端情况下,如果向量a和b的夹角为90度,则a在b上的投影为一个点,长度为0。如果向量a和b的夹角为0度,则a在b上的投影为最大值。如下图所示向量b和向量c的夹角小于a和c的夹角,b在c上的投影也大于a在c上的投影,那么对于c来说,b比a更加相似。下面是向量内积几何意义图:

图4 向量内积几何意义图
了解了向量内积的几何意义,继续查看“我喜欢吃苹果”的例子,对于字向量“我”来说,会分别计算和所有字的内积,那么得到的内积值就代表相关度,“我”和“我”的相关度为5,“我”和“喜”的相关度为2,以此类推。值越大说明相关度越高,那么也应该给予更高的关注度,这也是为啥叫注意力。而矩阵X和XT得到的是一个方阵,方阵中的元素xij则代表第i个字对第j个字的关注度。下面是矩阵X和XT点乘展示图:
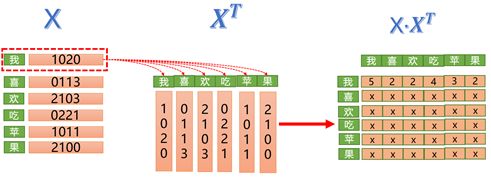
图5 矩阵X和XT点乘展示图
Softmax(X·XT)。归一化操作,将注意力值转化到0-1之间,和为1。因为Attention机制的核心就是加权求和,而这里的权重就是归一化之后的值。比如对于“我”来说分配给自己的得分为0.28,分配给“喜”字的得分为0.11。下面是添加softmax操作展示图:
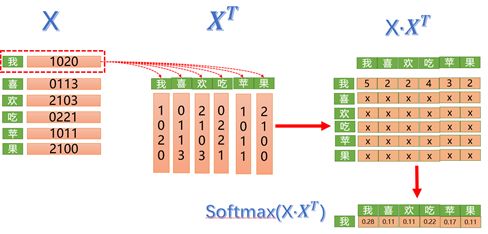
图6 添加softmax操作展示图
(Softmax(X·XT) ) ·X。如下图所示,将softmax(X·XT)和X进行点乘,以行向量“我”举例,会和矩阵X中的第一个列向量相乘,得到和行向量“我”维度相同的新向量。这个新向量是所有词向量在当前维度经过加权求和得到的,也就是词向量“我”经过注意力机制加权求和得到的向量。下面是添加点乘X操作展示图:

图7 添加点乘X操作展示图
上面通过图例完整的展示了原始的self-attention的公式,相信小伙伴们对注意力机制有了进一步的理解。下面通过可视化图更形象的展示self-attention机制的结果,下图是Transormer中第5层到第6层词“it”对所有词的注意力得分展示图,其中蓝色越深说明注意力得分越高,从最开始左边部分第五层it对animal的注意力得分很高,到第六层it对street的注意力得分很高,说明模型识别出it指代的就是street。

图8 attention机制效果展示图
03
Transformer中attention和self-attention的区别和联系

图9 Transformer中的attention和self-attention的区别和联系
上图是原始的self-attention和transformer中的attention公式对比图,可以看出transformer中的attention和self-attention非常相似(将Q、K、V设置成X,再去掉根号下dk),其实transformer中的attention就是从self-attention演变而来,本质内容是一致的。两者的区别主要有以下两点:
transformer中attention的Q、K、V。其实Q、K、V本质上是X经过线性变换得到的,transformer在训练过程中会得到WQ、WK、WV三个模型权重,主要作用是提升模型的拟合能力;
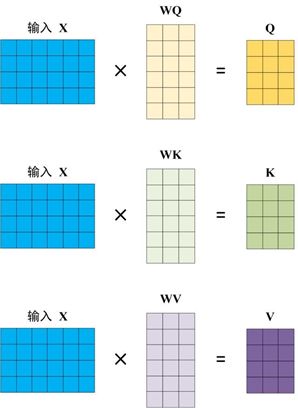
图10 Q、K、V是X的线性变换
除以根号下dk。这里主要作用是使模型训练过程中梯度值保持稳定。假设A= Q·KT,除以根号下dk的主要原因是A的分布和方差d有关,当A的分布陡峭,会使模型训练过程中梯度值不稳定,所以除以根号下dk会使训练过程梯度值保持稳定。
04
总结及反思
本篇重点介绍了Transformer中attention的来龙去脉。首先回顾了Transformer中注意力机制的计算流程;然后通过图解的方式详细介绍了self-attention,剖析公式理解self-attention核心是经过注意力机制加权求和;最后对比了Transformer中attention和self-attention的区别和联系,不仅要理解注意力机制的计算流程,而且要明白注意力机制背后的意义。对于希望进一步了解Transformer中attention机制的小伙伴可能有所帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们点赞和分享。