【论文阅读】Computational Personality: A Survey 计算性格学综述
文章目录
- 摘要
- 1. 引言
- 2. 计算性格学研究框架
-
- 2.1 性格学理论基础
-
- 2.1.1 性格分类模型
- 2.1.2 性格计算(测量)方法
- 2.2 计算性格学研究框架
- 3. 计算性格学研究
-
- 3.1 性格预测
-
- 3.1.1 基于大五模型的性格预测
- 3.1.2 基于MBTI性格量表的性格预测
- 3.1.3 小结
- 3.2 抑郁检测
-
- 3.2.1 基于线下问卷的抑郁检测
- 3.2.2 基于社交媒体的抑郁检测
- 3.2.3 总结
- 3.3 自杀检测
-
- 3.3.1 基于问卷的自杀风险检测
- 3.3.2 基于官方统计数据的自杀风险检测
- 3.3.3 基于社交媒体的自杀风险检测
- 3.3.4 小结
- 3.4幸福感评估
-
- 3.4.1 以量表为主的早期研究
- 3.4.2 以文本为主的近期研究
- 3.4.3 小结
- 4. 技术评测及其资源
-
- 4.1性格预测的相关技术评测及其资源
- 4.2 抑郁检测的相关技术评测及其资源
- 4.3 自杀检测的相关评测及其资源
- 4.4 幸福感评估的相关评测及其资源
- 5. 可解释性与道德问题
- 6. 结论
- 参考文献
- TODO List
大连理工大学信息检索研究室杨亮,李树群,林鸿飞等。
原文来自:《Computational Personality: A Survey》Soft Computing (2022).
原文链接: paper
参考:深度阅读 | 计算性格学综述
摘要
Personality is a set of stable and tendentious behaviors, thoughts and emotions. How to measure personality more conveniently and accurately has always been a problem for scholars in related fields. With the rapid development of computer technology and the widespread popularity of social media in recent years, the research of computational personality has attracted wide attention of researchers in Computational Linguistics and psychology. Various methods, from statistical methods in psychology to machine learning and then to deep learning, have been proposed to deal with different areas of computational personality. In this paper, we first summarize the research framework of computational personality, and then review the current research progress of computational personality from the aspects of personality prediction, depression detection, suicide detection and happiness assessment, and provide the corresponding research resources for reference. Finally, we provide some possible research directions.
性格是一组稳定的、有倾向性的行为、思想和情绪。如何更方便准确地测量性格一直是相关领域学者面临的难题。近年来,随着计算机技术的飞速发展和社交媒体的广泛普及,计算性格学的研究引起了计算语言学和心理学研究人员的广泛关注。从心理学中的统计方法到机器学习再到深度学习,计算性格学研究方法也得到了进一步发展。本文首先总结了计算性格学的研究框架,然后从性格预测、抑郁检测、自杀检测和幸福感评估等方面回顾了当前计算性格学的研究进展,并提供相应的研究资源以供参考。最后,思考了一些可能的研究方向。
1. 引言
性格是人类个体特征的高度概括,对人们的日常行为和主观认知起到关键的指导作用,每个个体独特的性格特征会对其日常生活产生深远的影响,因此,对于性格的研究一直以来都是心理学等领域的重要研究课题。在心理学上不同学者对于性格的含义有着不同的诠释,Funder[1]将性格定义为个体的思维、情感和行为特征模式,以及隐藏在这些背后的心理机制,De Young等[2]认为性格是一个描述人类对各种类型的环境刺激的持续行为反应的处理系统,而心理学界一种普遍的观点认为性格是一个人所具有的相对一致的心理结构、行为特征的集合。由此可见,个体性格会决定一个人的行为模式,对于个体行为、群体行为甚至社会发展均会产生一定影响,性格分析方面的研究在心理学、认知学和计算机科学等多个领域具有广泛的应用前景,相关应用包括抑郁症的检测、自杀的早期监测、犯罪嫌疑人的识别、婚姻状态的改善、求职信息的匹配等,因此,性格分析研究有着重大的学术意义和应用价值。
传统心理学对于性格的研究一般采用问卷法和测验法,通过制定心理学量表,采集个体的性格数据开展性格分析,由于该过程需要大量人工参与,采集的样本数量十分有限,性格分析研究有待进一步深入。随着互联网的广泛普及,特别是社交媒体的盛行,给人们的社会交往方式带来了全新的变革,也为性格分析研究提供了充足的数据储备。人们的日常网络社交行为可以很大程度上反映人们的个体性格,这种社交模式既平行于现实社会,又与现实社会紧密相连,由于社交媒体中的个体行为和状态更容易被记录和获取,因此基于互联网数据的用户性格分析成为相关领域的重要研究内容,该研究领域被称为计算性格学。
计算性格学旨在将计算方法应用于性格分析研究,通过数据采集、特征抽取及机器学习算法等手段,挖掘用户的个体行为特征和社会交往模式,进而对互联网用户性格进行建模,挖掘出用户的个人属性,用于更为精准有效的心理学分析。计算性格学将性格理论和社交媒体分析有机结合,基于深度学习等人工智能关键技术对社交媒体用户的性格进行分析和预测,并将用户性格信息应用于个性化推荐、用户心理预警和不良言论检测等领域,对心理学和社交媒体计算等领域有着十分重要的研究价值,(locate a gap) 由于该领域是多学科交叉的新兴领域,相关研究存在诸如数据筛选和隐私保护等诸多难题和挑战,相关研究亟待深入开展。
本文旨在全面介绍计算性格及其最新进展。首先概述计算性格学的研究框架,总结从资源到下游应用的完整研究过程。然后,重点关注计算性格学的四个方向:性格预测、抑郁检测、自杀检测和幸福感评估。这些方向是计算性格学的发展趋势,受到了广泛关注。从以上四个方向梳理了计算性格的相关研究,介绍了计算性格学的研究进展、主要挑战和未来的可行性研究。之后,回顾计算性格学研究和相关竞赛中常用的数据资源。由于计算性格学是一门涉及多个交叉学科的新兴研究,在数据筛选、隐私保护等方面仍存在困难和挑战,因此简要讨论了道德问题和模型的可解释性。
本文的其余部分安排如下。第 2 节介绍计算性格学研究的总体框架。第 3 节详细梳理和比较计算性格学四个子领域的现有工作。第 4 节回顾计算性格学研究中常用的数据资源。第 5 节讨论计算性格学研究的伦理问题和可解释性。第 6 节是本文的结论。
2. 计算性格学研究框架
2.1 性格学理论基础
2.1.1 性格分类模型
心理学对个体差异的研究诞生了很多理论,常见的性格分类模型主要有大五性格模型(Big Five Model)和MBTI(Myers-Briggs Type Indicator)等。
大五性格模型是最受计算性格分析研究者们欢迎的模型,它是现在心理学中描述最高级组织层次的五个方面的性格特征,这五大性格特征构成了人的主要性格。总体上可以分为五大性格特征:开放型(Openness to Experience)、外倾型(Extraversion)、神经型(Neuroticism)、严谨型(Conscientiousness)、随和型(Agreeableness)。具体各个性格维度的特征如下表所示。大五模型的产生不仅使传统心理学对个体差异的研究更精确化,也为性格分析与计算机领域的结合提供了重要的理论基础。一方面,它反映了性格模型在性格心理学中的主宰地位,另一方面,该模型用数值计算性格类型,这便于通过计算机进行数据处理[3]。 
Myers-Briggs Type Indicator,简称MBTI,是另一种常见的有代表性的模型,它是基于量表的性格测评模型,其理论原型是分析心理学的创始者Carl G Jung的性格类型说[4]。该模型将人的性格分为四个维度,外向和内向(E/I)、感觉和直觉(N/S)、理性和感性(T/F)、主观和客观(J/P)。四个维度如同四把标尺,每个人的性格都会落在标尺的某个点上。取每个维度上的偏好字母,组成了16种不同的性格。目前有很多 性格测试网站可以支持使用MBTI测量人的性格。心理学界认为MBTI理论过于理想化,存在缺陷,测量结果不可靠,而且同一个人不同时刻的测量结果也不同。相比之下,大五模型是更好的性格测量工具。

2.1.2 性格计算(测量)方法
对应不同的性格理论,产生了不同测量性格的方法,传统的性格测量方法包括自陈量表(self-report inventory),如明尼苏达多相性格测试(MMPI)、卡特尔16种性格因素测验(16PF),艾森克性格问卷(EPQ)、爱德华个性偏好量表(EPPS)加州心理问卷(CPI)等。
但传统的性格测量方法需要测量人员的辅助以及被测量者的高度配合,测量结果的准确性并不能完全保证。随着社交媒体的流行,研究者们看到根据用户在社交媒体中的行为来计算其性格特征的可行性,将诸如自然语言处理等技术与心理学相结合,利用统计学,机器学习如支持向量机、线性回归等,以及基于深度学习的相关方法对文本进行分析,衍生了性格预测、自杀检测、抑郁检测、幸福感评估等研究方向。
常用的分析数据多为文本数据,但近来不少研究者们开始利用多模态数据及处理技术,将声音信息、视频信息等与文本信息相结合,来提高性格计算的有效性。
2.2 计算性格学研究框架
本文以心理学领域的性格理论为基础,对计算性格学研究展开综述,计算性格学的整体研究框架如图1所示。在资源层,计算机性格学以互联网中的社交媒体为数据来源,同时借鉴自然语言处理中的多种语义资源,针对用户性格构建计算模型(情感词典、文本语料库);在理论层,计算性格学以心理学中的大五性格和相关性格理论为指导,将性格理论融入计算模型的构建环节,实现面向心理学的计算性格分析与挖掘;在算法层,计算性格学采用统计机器学习和深度学习方法,基于社交媒体数据构建性格分析与预测模型;在应用层,将相关计算性格分析模型应用于更多细粒度的性格分析研究方向,如抑郁检测、自杀检测和幸福感评估等,以深入探索计算性格学在相关任务中的应用模式;在平台层,通过构建计算性格学分析平台,对互联网用户性格展开深入的分析和应用,实现精准有效的用户建模(精神疾病诊断、个性化推荐、用户画像)。
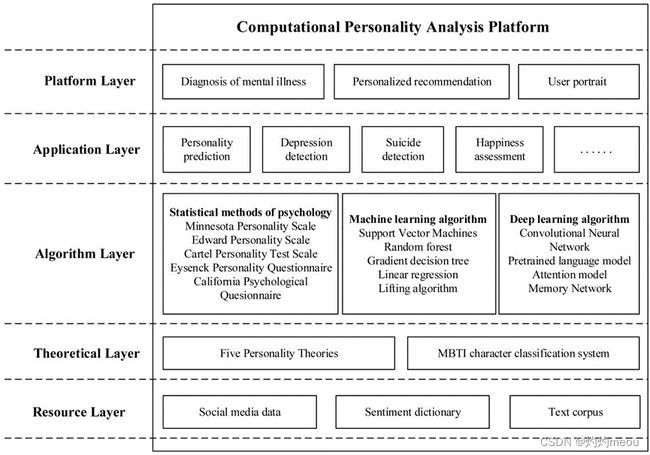
3. 计算性格学研究
随着物质需求的增长,生活压力的增大,人们的心理健康,越来越受到重视,但由于目前民众仍对心理疾病等存在歧视和误解,初期患有精神疾病的患者,羞于寻医,而导致病情发展到不可收是的地步,因而造成不幸。计算性格学研究的产生就是为了更好地了解人们的心理健康状态,以达到早发现,早治疗的目的。在计算性格学研究中,以性格预测、抑郁检测、自杀检测和幸福感评估四个方面对人们的心理健康状态进行了深入研究,以下为这四方面分别的阐述。
3.1 性格预测
性格预测有很多应用方向。一个人的性格不同,所喜爱浏览的内容也不尽相同,因此可以用来辅助构建推荐系统,如对于目前红火的电商业务,可以通过分析一个人的性格给他推荐适合的商品;性格不同会导致不同的行为,例如“神经型”的性格特征往往与“恐惧”、“悲伤”、“愤怒”等存在显著相关性,因此这种性格类型的人可能存在较大概率的抑郁倾向,甚至会导致自杀行为的产生。
近年来,随着移动设备的普及,社交媒体已经成为一种流行的信息交流和社会互动的手段。社交媒体用户的个性信息可以用于分析人群行为和构建推荐系统,这使得性格预测研究者们常常从用户量大的社交软件入手,如Facebook、Twitter等社交平台。这些社交媒体用户量庞大,用户信息丰富,吸引了大量研究者的注意。常用的性格标准如大五模型等,因此性格预测问题也就转化为一个分类问题。
3.1.1 基于大五模型的性格预测
早期的基于大五模型进行性格预测的代表性工作有Argamon[5](2005)等人使用支持向量机(SVM)算法,并加入了词汇特征,对大五模型中“神经型”和“外倾型”的性格进行预测。数据集采用得克萨斯大学奥斯汀分校的学生在1997年至2003年间所写的文章,实现对这些学生的五因素性格测量。实验结果证明了词汇特征对性格分析(神经型性格)具有一定的适用性,但对外倾型性格的预测结果准确性并不乐观。
除收集学生文章文本来构建数据集外,也可采用社交媒体的开源数据进行性格预测,如Zheng[6](2016)等人采用myPersonality2(该数据集所在网站现已停止分享数据)进行实验,提出了一种结合信息增益与语义特征的性格预测方法对文本提取了情感词、词性、时态等特征,对其进行特征选择和加权,同时将文本内容映射为本体概念并计算语义相关度,最后基于词的特征和语义特征,运用支持向量机(SVM)、K最近邻(KNN)、朴素贝叶斯(NB)等机器学习算法进行性格预测,相比于一般基于LIWC构造特征方法具有更好的预测效果。Liu[7](2017)等人在大五模型理论的基础上,针对微博社交媒体,提出一种基于用户行为信息来预测性格的方法,基于线性回归的方法构建了用户性格预测模型,实验的正确率达到了78.5%。
上述研究均采用文本信息作为实验数据,另有研究者认为社交媒体上的互动行为(如转发、点赞等)也可以作为性格预测的数据分析基础。如Michal等人[8](2013)认为像Facebook中Likes之类的数字记录可以表征一个人的个人属性,如性取向、种族、宗教、政治观点、个性特征、智力、幸福感等。这项分析基于58000多名志愿者提供的其在Facebook上的Likes数据、详细个人资料以及一些心理测试的结果,模型采用降维的方式对数据进行预处理,然后输入logistic回归/线性回归,预测Likes的个体性格特征。该模型正确区分了数据集中88%的同性恋和异性恋男性,95%的非裔美国人和美国白人,85%的民主党人和民主党人。对于“开放性”性格特征,预测准确度接近标准性格测验的准确度。
Jennifer等人[9](2011)通过分析用户在Facebook上的公开信息来准确预测用户的个性,如姓名、教育水平、婚姻状况、社交网络的密度(即与友人之间的亲密程度)、形容最喜爱活动的用词数量、加入群组的数量以及政治倾向等。实验结果显示高斯算法和M5算法预测用户的RMSE性格分数值低于0.13,可以准确预测用户性格。

有研究者用图像来分析预测性格,比如用户的头像等信息。如 Fabio[10](2014)等人对Facebook用户的头像进行分析,他们认为性格与个人交互风格有关,头像图片传达了大量有关与用户的信息。最后,使用了不同的机器学习算法来测试图像特征在预测性格和交互风格特征方面的有效性,经过有效训练的机器学习算法能比人类更准确的识别头像所属用户的性格特征。
多模态技术在性格预测上的研究也越来越广泛,如Marcin等人[11](2016)认为在许多个性化检索和推荐系统中,用户的个性特征是非常重要的。因此,他们集成了文本、图像等特征并对两个不同的SNS(Twitter和Instagram网络)同时进行分析,使得每种性格特质的预测误差得到一致的降低。
Onno等人[12](2018)利用多模态融合的技术,基于大五性格模型利用语音、文本,以及视频(主要是脸部特征)对性格进行预测。对于语音数据,使用了声学(acoustic)和韵律(prosodic)信息,将原始声波输入至卷积神经网络(CNN)中;对于视频数据,从每个视频中随机抽取一帧,只通过外观特征识别性格,利用VGG-FACECNN模型对图像提取表示特征;对于文本信息,利用word2vec转化为词向量后输入至CNN模型。实验结果显示其多模态融合技术比单个模态的最高性能(视频特征)提升了9.4%。
Aslan[13](2019)等人提出了一种基于深度学习的多模态方法,从视频中提取说话风格、面部表情、身体动作、语言因素等与性格有关的特征,经过预训练的深度卷积网络(Resnet和VGGish)提取高层特征,并使用LSTM集合时间信息。实验结果在大五模型的五个特征的平均准确率达到了当年的最优结果。
现今越来越多的学者基于大五性格模型进行性格预测研究,信息时代使得社交媒体成为了数据获取的主要来源。常见的用于性格预测的方法如提取特征利用机器学习算法进行分类,以及利用自然语言处理技术对文本词嵌入输入至神经网络(如CNN、RNN等)实现性格预测,同时,预训练语言模型(如Bert)的火热也给这一领域带来了新的活力。除文本信息,利用多模态技术结合文本、声音、图像等数据进行性格预测的方法也成为了新的研究热点。
3.1.2 基于MBTI性格量表的性格预测
Myers-Briggs Type Indicator(MBTI)在非科学界非常流行,许多人采用该性格量表来分析自己的性格并在社交媒体中加以分享讨论,这使得有关MBTI的自我评估数据在诸如Twitter等社交媒体中轻松获得。
其中比较有代表性的工作,如Ben Verhoeven等人[14](2016)从Twitter中创建了一个基于MBTI的新的语料库,适用于荷兰语、德语等六种语言,他们使用了sklearn中的线性SVC以及逻辑回归等常用机器学习算法给出了一个baseline,其分析结果同样对性别的识别较有成效。
Kosuke等人[15](2019)认为人们在社交平台上的文本化信息和用户行为(如点赞和分享)对于预测社交媒体用户的性格有积极的作用,他们发现有很多社交媒体用户经常浏览他人的帖子,却很少发布自己的信息,这些用户往往通过用户行为(点赞和分享)来表达自己的观点和偏好。因此作者从Twitter中爬取数据构建数据集,基于MBTI的性格模型指标,利用BOW、SVD、DBOW、Co-occurrence等文本分析方法分析用户行为,从而对其性格进行分类。
在线教育已经成为现代教育体系的一个重要方面,而学生性格的不同会导致在线学习的效果差异明显。Mohamed等人[16](2015)基于MBTI理论使用了10种数据挖掘分类算法如朴素贝叶斯、随机森林等对从埃及开罗的德国商学院收集的数据集进行分析,以帮助学生意识到自己的性格特征,从而使他们的学习习惯变得更加有效。
MateJ等人[17](2018)利用Reddit社交媒体构建了一个带有MBTI标注的大型数据集——MBTI9k,通过特征提取以及三种机器学习算法(SVM、LR、MLP)对性格进行分类,在“感觉和直觉”(N/S)性格维度上的F1值达到了82%,但在“理性和感性”(T/F)的性格维度上只有67%,因此可能需要利用深度学习模型以提高在T/F性格维度上的性能指标。
近年来,电子商务发展迅速,因此为用户提供更为准确的推荐服务便显得尤为重要。Chen等人[18](2019)提出了一种基于消费性格本体的用户模型表示方法,按照消费性格的不同,将用户分为顺应性、保守型、自由型、怪癖型、经济型五种类型。实验选取自某电子商务网站服装类下的500个实际商品资源,分别采用了基于关键词的表示方法、传统的基于文本的表示方法和基于消费性格本体的表示方法对推荐结果进行统计分析,实验结果显示后者在准确度上高于前两者,推荐的商品与用户需求更为契合。

3.1.3 小结
在性格预测方面,现如今的性格预测研究,多是以基于社交媒体的开源数据集为主,一般基于大五人格模型和MBTI进行性格预测。研究者将性格理论与社交媒体相结合,通过性格信息可以更好的理解社交媒体用户的行为,对于个性化推荐、舆情分析、用户心理预警(如自杀检测、抑郁检测、幸福感评估等)有重大研究价值。
3.2 抑郁检测
抑郁症是影响全球人类健康的一项重要因素,预防抑郁症有助于保护人类的健康。早期抑郁症的发现对于患者至关重要,但由于人们往往对咨询心理医生感到反感,所以许多研究工作利用计算性格学的思想,对潜在用户进行抑郁检测,有助于在早期发现抑郁症,从而得到及时的治疗。
抑郁检测是计算性格学中的一项重要任务,它指的是获取UGC(用户所生成的信息),如文字、音频和图像等,使用自然语言处理等技术,检测和预测相关用户的抑郁状态;将UGC作为输入,输出为用户是否患有抑郁症的概率值。
3.2.1 基于线下问卷的抑郁检测
在心理学领域中,早在2006年,Cloninger等人[19]通过一项纵向研究,研究了性格特征在个体易患抑郁症可能性中的作用;而在社会语言学领域中,Oxman等人[20](1982)指出,语言分析可以将被分为抑郁和偏执两类。据此,抑郁检测的研究围绕着相关抑郁的书面文字而展开。
通过LIWC对书面文本的分析也揭示了有关神经病倾向和精神疾病的预测线索(Gortner和Pennebaker, 2004)[21]。Resnik等人[22](2013)以Rude等[23](2004)收集的文章为材料,该文章是由学生以“大学生活中最深刻的想法和感受”为题创作的文字材料,结合贝克抑郁测量表(Beck等人, 1961)[24]计算的BDI值,利用LR模型分别对LIWC(Pennebaker和King,1999)[25]和LDA(Blei等人,2003)[26]提取的特征,再对两者结合的特征进行训练,预测文章的作者是否患有抑郁症。该研究首次使用计算性格学的方法对文字材料进行检测,为后来以社交媒体为载体的抑郁检测研究提供了可能性。
上述的研究为检测抑郁症提供了相关思路,但是其存在显著的局限性,它在样本选取时,存在着样本数量少,样本特征相似的缺陷,这些样本不一定代表大多数抑郁症患者。此外,这些研究通常基于问卷等相关形似的调查,依赖于抑郁症患者相关情绪的回顾性自我报告和有关健康的观察结果,而这样的调查通常要持续数月,甚至数年,就需要投入大量人力、物力。总而言之,其存在资源的浪费且受限于时间粒度的弊端,无法及时有效地预测抑郁症。
3.2.2 基于社交媒体的抑郁检测
1. 结合书面文字的抑郁检测
随着社交媒体的兴起,越来越多的人喜欢在社交媒体上分享自己的生活状态。而对于抑郁症患者,由于在现实生活中有时会受到他人的歧视与侮辱,使得他们更多的倾向于在社交媒体上分享自己的抑郁状态和寻求帮助。Moreno等人[27](2011)证明,Facebook上的状态更新可以用于揭示严重抑郁症发作的症状,而Park等人[28](2012)在Twitter的平台下发现了最初的证据,郁症患者倾向在社交媒体上发布有关抑郁症甚至治疗的信息。


正因如此,可以利用社交媒体中于用户相关心理活动和社会环境活动的数据流,以一种时间细粒度的方式,检测相关用户易患抑郁症的可能性。但由于相关社交媒体数据集的缺乏,以及仅根据社交媒体的数据无法判断用户是否患有抑郁症,所以此时大多的研究所使用的数据集都是通过将社交媒体动态和面对面访谈或问卷调查相结合构建的。
Munmun等人[29](2013)探讨了在社交媒体上进行抑郁检测的潜力,通过收集Twitter用户是否患有抑郁症的数据,再结合他们在社交媒体上的行为与标准用户的行为的区别(抑郁症用户表现为社交活动减少、消极情绪增加、自我关注度高和宗教思想表达增强等),建立特征模型,但此研究同样受困于缺乏标注的数据集,利用SVM分类器仅得到准确率为74%的结果。 Park等人[30](2013)通过社交媒体(Twitter)检测用户是否患有抑郁症,对Twitter上14名活跃用户进行半结构化的面对面访谈,对其进行定性分析,以了解抑郁症用户和非抑郁症用户对社交媒体的感知和行为差异,研究得出以下结论,抑郁症用户将社交媒体视为社交意识和情感分享的工具,而非抑郁症用户则将社交媒体信息分享的平台。
上述研究工作将社交媒体动态、问卷信息、访谈信息以及实际心理活动等信息结合,可以获得不错的效果,但是由于收集访谈等信息需要投入大量的人力、物力,在一定程度上制约了其发展。
2. 基于社交媒体信息的抑郁检测
随着技术的进步,以及受到Coppersmithet等人[31]的启发,根据内容中是否严格存在“我是/我曾是/抑郁症”的语句结构,可将文章标注为抑郁指向性文章和标准文章,进而实现了直接从社交媒体中获取标注完整的数据集的目标。
在此方法提出后,大部分研究主要集中在分析公开的社交媒体文本内容,其中一些特征最常用于理解个体的心理状态,通常是使用著名的LIWC(Pennebaker等人,2001)[32]提取特征,如第一、第二、第三人称代词、感知过程相关单词或正、负情绪词(Wang等,2017)[33]。在对文本进行情感分析时,常使用诸如OpinionFinder(Wilson等,2005)[34]、SentiStrength(Thelwall等,2010)[35]和ANEW(Bradley和Lang,1999)[36]等工具用于量化文本表达中的感知和情感属性(Kang等,2016)[37]。此外,表情符号和图像也被用于检测社交媒体帖子中的积极和消极情绪(Kang等,2016)[37]。作为内容分析的一部分,为了从用户生成的内容中提取主题,集成了各种类型的主题建模,常使用的模型如LDA[26]。
在对数据集进行预测时,使用的预测模型大多是采用有监督的机器学习模型进行训练和预测。其中比较有代表性的方法包括,如Shen等人[38]根据上述的方法构建了标注齐全的抑郁和非抑郁数据集,并提取了六个与抑郁相关的特征组,涵盖临床抑郁标准和社交媒体上的在线行为。通过这些功能组,提出了一种多模态抑郁词典方法,并结合实验证明了该方法的有效性,以实现Twitter上抑郁用户的检测。Hiraga[39]探讨了书面语言中的语言特征是否可以通过使用监督的机器学习方法来帮助预测作者是否患有抑郁症,其研究以一般主题的日语博客作为数据集,通过Character n-grams和Token n-grams提取文本特征,使用scikit-learn (Pedregosa等人,2011)[40]中的Multinomia lNaiveBayes(NB)分类器, Linear Support Vector Machines(SVM)分类器和Logistic Regression(LR)分类器对博客进行分类。实验表明,在作者级别分类任务,准确率可达86.4%;而对于文本级别的分类任务,准确率最高为75.5%。但由于实验数据规模较小,无法确定是否在大规模数据集上依然可以有效。
区别于传统的机器学习方法,Yates等人[41]使用神经网络模型进行抑郁检测并描述了自残与抑郁症的紧密关系,根据Reddit自我报告的抑郁症诊断(RSDD)构建了用于识别用户的数据集,与之前的提取特定性的特征和使用有监督的机器学习模型不同,研究从文本内容出发,提出改善后的神经网络CNN(Kalchbrenner等人,2014)[42]模型,在F1上获得优秀的表现。但由于Reddit平台用户的匿名特性,无法确定数据是否具有真实性;另外,该研究忽略了未进行自我报告的抑郁症用户,而那些抑郁症用户的隐藏式推文依然还需进一步研究。
(gap)在大量工作的投入后,在社交媒体上进行抑郁检测的研究也陷入了瓶颈,急需在方法上取得进展。基本研究方法大多是在小时间窗口中进行收集数据和模型预测的,忽略了对离散的基本情绪的利用。Chen等人[43]第一次以情绪特征和时间序列对社交媒体上的用户进行抑郁检测,其以Twitter的帖子作为数据集,根据八种基础情绪提取情绪特征,再利用时间序列测量方法对情绪测量结果进行分析,得出一组时间特征,分别以情绪特征和情绪特征与时间特征结合的方法,进行抑郁检测。经实验得出,仅使用情绪特征提取的预测结果的准确率为87.27%高于先前研究的结果,另外结合时间序列特征的研究结果,随着时间的推移,准确率可达到89.77%。实验证明,情绪特征可以揭示个人的心理状态,而随着时间的推移,情绪的变化会带来更多的信息,其有助于检测抑郁症。虽然对于情绪数据的判断需要专业培训和与抑郁心理深度相关的数据,但此方法为抑郁检测带来了新的思考角度。
(多模态) 不同于先前单一文本材料作为输入的研究,Samareh等人[44]提出通过多模态特征工程与融合的方法预测抑郁症的严重程度,在AVEC 2017(Ringeval等人.2017)[45]数据集上,证明了该方法具有良好的性能。AVEC 2017数据集是由音频、视频和文本信息组成,通过分别提取音频、视频和文本信息的特征,利用随机森林分类模型得到每个特征的分数,再基于置信度的决策机融合特征得到最终的预测结果。相似的,Gui等人[46]选择了从文本信息和视觉方面的信息进行研究,利用强化学习的方法来筛选相关推文,并有效地融合了文本和视觉的特征,实验证明此方法在实际情况中性能强大且稳定。
(gap:跨语言)另外,尽管抑郁检测已经在Twitter和Facebook等平台上被证明了有效性,但是由于文化的差异,无法直接将一些研究方法应用于其他语言的社交媒体,比如使用中文作为基本语言的微博,其可能由于缺少已标注的数据集而效果不佳。Hen等人[47]提出了一种具有特征自适应变换的跨域深层神经网络模型,以大量的Twitter数据作为源域,研究了以特定目标域(如微博)的抑郁检测,经过实验得出,该方法有效可以较好的在跨领域语言中检测抑郁。虽然在部分数据集上可以取得不错的结果,但是仍缺乏与线下的实际情况结合,无法直接应用于临床诊断。
发展至今,基于社交媒体信息的抑郁检测取得了相当大的成果,随着模型准确率的不断提高,则会更加准确的预测用户是否患有抑郁症,并能够早发现、早治疗,从而有助于全人类的健康。
3.2.3 总结
社交媒体上对抑郁症的检测取得了长足进步,随着准确率的提高,其可以用来预测抑郁症,使患者可以得到早期治疗。以下提出相关的几个未来研究方向:为更好的检测社交媒体的抑郁用户,可寻找用户所创作的文字信息、图片和声音等之间的逻辑关系,为抑郁检测提供多维度的依据,以在实际情况中更具实用性;随着抑郁检测的准确性的不断提高,如何将抑郁检测应用于临床检测也成为了未来的一个重大研究课题,比如通过用户创造的信息,结合抑郁症临床症状,以判断抑郁症的严重等级,并进行及时干预。
3.3 自杀检测
根据美国疾病控制与预防中心(CDC)的最新数据,自杀是10-34岁之间的第二大死亡原因和35-64岁之间的第四大死亡原因,且自杀率呈上升趋势。据统计,中国每年有28.7万人死于自杀,200万人自杀未遂,因此造成的直接和间接经济、社会、心理损失不可估量,成为了一个严重的公共卫生问题。传统的自杀风险评估研究主要采用心理测验、问卷等分析方法,但实际使用时,以上方法仍然具有一定的局限性。随着近年来越来越多的社交网络平台让人们有更多机会在虚拟社区中吐露自己的感受和观点,那么通过社交网络也就能主动寻找有潜在自杀倾向的个体,并对他们进行分析和预警。目前基于社交媒体的自杀风险评估研究常采用四标签(无风险,低风险,中度风险和高风险)分类方案对自杀用户进行分类,通过用户在社交媒体上的表达和行为信息预测其自杀风险。下面进行详细介绍。
3.3.1 基于问卷的自杀风险检测
传统的心理学研究人员已经开发了一些获取自杀风险的心理学测量方法,如Bagge等[48]的自杀概率量表、Fu等[49]的成人自杀意念问卷、Harris等[50]的自杀影响行为认知量表等,各个量表也有各自的适用群体范围。这些心理学量表是专业和有效的,在实际使用过程中也展现出了较好的效果,有一定的参考价值。Sueki等[51]做了关于自杀相关Twitter和自杀行为之间的相关性研究,参与者回答了一份自我管理的在线问卷,其中包含关于Twitter使用、自杀行为、抑郁焦虑等问题,调查结果显示,Twitter文本有助于识别有自杀倾向的青年网民。
但基于问卷的自杀风险检测具有一定的局限性,即量表的研制可能只是针对某些影响自杀的因素或是某些特定群体,而且要求受访者填写评估表或是参加面谈,这样对那些很少寻求专业帮助的潜在自杀者不能起到很好的识别作用。同时耗费时间、人力较大,难以胜任大规模的实时自杀检测任务。综上所述,心理学量表法固然有其专业、理论性好的优势,但仍需要更进一步的研究以提高自杀检测的准确率与效率,即引入计算机技术,通过更大规模的数据及计算量实现更为普适、实用的检测方法。
3.3.2 基于官方统计数据的自杀风险检测
本小节中的官方统计数据指的是官方机构统计记录并发布的数据,但与心理学问卷不同的是,这里的统计数据一般数据量较大,数据维度较多,同时也包括很多与自杀无关的维度,所以在数据处理方面较为依赖计算机技术,也更为贴合大数据的概念。Walsh等[52](2017)人在进行自杀意念检测研究时,使用了匿名电子健康档案(EHR)数据集,其数据集大小大于50万,并采用了随机森林(RF)方法进行自杀风险的二分类,最终F1分数达到86%,召回率达到95%。Bhat等[53](2017)在一项关于预测青少年自杀的研究中,应用深度神经网络来预测自杀想法,同样使用匿名电子健康档案(EHR)数据集,最终模型获得了70%的真阳性和98.2%的真阴性。Amini等[54](2016)采用来自伊朗的自杀数据集,利用支持向量机(SVM)、逻辑回归(LR)、人工神经网络(ANN)等传统机器学习方法来评估自杀风险,并发现性别、年龄、工作等是影响自杀意念的重要因素。
基于官方统计数据的自杀风险预测可以探究更多影响自杀信念的因素,然而其数据集构建较为困难,且难以实际应用于在线自杀检测任务。而随着社交媒体的广泛使用,其包含的大量无监督语料、社交网络特征等进一步提供了更为全面的信息以及更为便捷的数据获取方式,给自杀检测研究指出了一个新的方向。
3.3.3 基于社交媒体的自杀风险检测
近年来基于社交媒体研究的数据集主要来源于Reddit、Facebook、微博等社区平台,而相关的研究则主要集中在识别自杀信息的真实性以及识别社交媒体中的自杀信息等方面。前者主要研究在给定一些自杀相关的数据集后,如何判定其真实性,如Reddit的自杀子社区中的发言;后者主要研究在用户发布的日常推文(即日常发布的文本)中识别高自杀风险的文本及用户。下面逐一进行介绍。
1. 识别自杀信息的真实性
此处的自杀信息多指用户发布的自杀文本。识别自杀信息任务的文本数据集一般较小,具有一定的分类难度。Pestian等[55]利用机器学习技术创建了一个自杀文本分类器,在区分虚假的在线自杀文本和真实的自杀文本方面,它比人类心理学家表现得更好。Jones等[56]的工作重点在于区分真实的和伪造的自杀文本,使用了有监督分类模型和一组语言特征来进行区分,并达到了82%的准确率。Burnap等[57]进行了自杀检测分类,用于区分自杀相关主题,比如是真实的自杀事件还是仅是提及了自杀。
2. 识别社交媒体中的自杀信息
社交媒体中的自杀信息识别研究主要集中在自杀文本识别上。Li等人[58](2013)的自杀风险检测研究将文本情感分析技术应用于中文网络论坛中的用户帖子和帖子评论,以识别自杀文本。Huang等人[59](2015)基于微博数据,基于词嵌入和心理学标准,使用主题模型识别自杀信念,并构建了一个自杀信念检测的原型系统,用以实时监控自杀文本。Gamback等[60]开发了同时使用n-grams特征和word2vec的卷积神经网络,大大提高了分类性能。Lei Cao等[61]研究了树洞在微博自杀风险检测中的应用,采用两层注意力机制从个人博客流中捕捉变化点。并基于词嵌入和注意力机制,提出了一个比设计良好的基准方法更有效的自杀风险检测模型,准确率达到了91%。
文本、图等数据的特征抽取也得到了本领域研究人员的关注。Jashinsky等[62]使用支持向量机(SVM)预测了某人在一段时间内的自杀风险水平,使用每条推文的词语频率-逆文档频率(TF-IDF)、字数、唯一字数、平均字数以及每条推文的平均字符数作为输入特征。De Choudhury等[63]确定了语言,词汇和网络特征,用这些描述了患有心理健康疾病患者的特征,用于预测自杀风险,分析Reddit上自我报告帖子的内容,得到有关用户的心理健康状况,并利用倾向得分匹配测量了用户将来分享自杀想法的可能性。Xu等[64]基于中文微博数据,抽取了字典特征及语言特征,并验证了其对于基于n-gram特征的模型性能有所提高。

一些研究人员也通过引入领域知识、增加数据特征等方式在原有数据集基础上构建新的数据集。Manas Gaur等[65]结合了特定领域知识来预测个人自杀风险的严重性,使用医学知识和自杀本体论来开发自杀风险严重性词典,同时创建了一个Twitter数据集,并将现有的四标签分类方案扩充到五标签分类。Rohan Mishra等[66]利用文本特征、社交图的嵌入特征等,探讨了用户在社交媒体上的行为信息的使用。并开发了一个人工注释的Twitter中自杀检测数据集,采用上述特征进行模型训练,结果验证了所提出的SNAP-BATNET模型在自杀检测中的优势。
除了对自杀文本的分类识别之外,有研究人员也试图扩大自杀检测的研究范围,如探究自杀诱因等。Du等人[67]使用深度学习方法来检测导致自杀的精神压力源,使用卷积神经网络(CNN)构建了识别自杀推文的二分类器,一旦检测到自杀性推文,他们就会使用循环神经网络(RNN)进行命名实体识别(NER),以标记归类为自杀的推文中的精神压力源,同时实现了文本的识别及因果的推理。
综上,对社交媒体的自杀检测研究已经取得了一定成果,且由于数据获取难度低、文本分析技术较为成熟,故未来的研究前景仍然广阔。然而基于社交媒体的文本等数据筛选难度较大、图特征采集难度较大、数据标注难度大等,且理论基础不足,目前多用于辅助判断自杀风险,故仍需完善数据集及研究方法,不断提高识别准确率。
3.3.4 小结
目前的自杀检测研究主要集中在利用用户在社交媒体上发布的文字等数据对用户的自杀风险进行分类,进一步包括对自杀诱因的识别和遗书真伪的判断。方法一般是提取文本、图形等数据的特征,并用机器学习模型进行分类。随着深度学习的快速发展,各种端到端的自杀风险识别模型和一些在线自杀风险检测模型应运而生。可以预见,随着对自杀检测研究的不断深入,可以更准确地识别有自杀倾向的人,及时进行心理疏导,预防自杀行为。
此外,自杀检测的数据来源和形式也在不断多样化。社交网络数据逐渐引起研究人员的关注。自杀念头容易在社交网络中传播,因此,研究自杀念头的传播方式和过程,可以有效提高自杀检测的准确性,甚至遏制自杀念头的传播。一种常见的自杀原因和前兆是抑郁症的出现,未来可以结合抑郁症检测来研究抑郁症与自杀的关系,其有助于提高自杀检测的准确性。
3.4幸福感评估
随着社会越来越重视人们的心理健康,幸福感逐渐成为人们研究的热门方向,尤其现在像抑郁、自杀现象逐年升高,对于这类负面情绪的消除有着重要的研究价值和社会意义。因此必须要了解什么是幸福感,如何去获得幸福感。计算性格学作用于幸福感研究就是通过自然语言处理等技术挖掘出文本中与幸福感相关的信息,比如幸福感的来源,幸福感的强弱,幸福感预测等等。幸福感评估想要解决如何去衡量一个人感到幸福的程度,对幸福感这样一个抽象的概念进行量化。研究者从被测量者的相关信息中进行建模,最后给出用户幸福感的程度。
幸福感属于心理学范畴,幸福感主要是指人们对其生活质量所做的情感性和认知性的整体评价,具有主观性、稳定性和整体性三个特点[68]。幸福感的代表学者Diener[68]提出幸福感由情感维度和认知维度组成,即拥有较多的积极情感和较少的消极情感,以及对生活的满意感。国内外对幸福感的研究已经较为成熟,以Diener为代表的学者对幸福感的内涵、维度和测量方法基本达成共识。
在幸福感的研究中, 性格是预测幸福感最有力和最稳定的指标之一[69],性格从本质上表现了人的特征。在Diener提出的交互模型中,认为性格影响着人们处事的行为和态度,增加经历某种情境的可能性,不同的情境又引起幸福感增加或减少,这也是计算性格学在心理学方面的一个理论依据。
对幸福感评估的研究早期主要以量表为主,后期转向了文本,下面按照这两个阶段对幸福感评估的相关研究进行阐述:
3.4.1 以量表为主的早期研究
幸福感的研究大致从 20世纪 50年代在美国兴起。从其发展背景来看,一是源于人们生活质量的不断提高,二是积极心理学、健康心理学的崛起对人类自身生存与发展的日益关注。20世纪70年代以来,研究者将这一课题的研究从哲学层面上升到科学层面,实证性研究不断增多。在这一过程中,幸福感的解释理论直接影响了人们的研究方向[70]。从理论出发,研究重点转向测量幸福感,探讨提高人们幸福感的方法。
最早测量幸福感的工具是Bradburn在1963年编制的情感平衡量表(Affect Balance Scale,ABS)。该量表共10个题目,包含积极情感和消极情感两个维度。主试根据这两个维度的总得分推测被测者的近期情感状态,进一步推测其主观幸福感水平。有研究者提出主观幸福感是个体长期稳定而非暂时的情感状态,ABS评价的是个体暂时的情感状态,因此对以ABS 的结果来推测主观幸福感被提出质疑[71]。
在这之后出现了许多幸福感测量工具,如D-T量表(Delighted-Terrible Scale),纽芬兰纪念大学幸福感量表(the Memorial University of Newfoundland Scale of Happiness,MUNSH),生活满意度量表(the Satisfaction With Life Scale,SWLS)等。Liu等[72]在其论文《幸福感测量指标体系的评价与展望》中详细对比了现有国内外幸福感测量工具中的结构维度,结果发现仅有24%使用现有理论开发测量工具。以理论为导向的指标体系构建往往可以使测验结果更为客观、公平、准确,但未来还应加强幸福感理论构建。心理测量特性分析表明,各幸福感的测量信效度水平不一,只有不到一半的测量工具报告了注重测信度,这限制了相关工具的应用。
由于对幸福感的研究才刚刚起步,所以这一时期人们主要是采用量表的方式对幸福感测量评估,其效果与专业的心理学理论紧密相关。但是量表这种方式太过依赖于用户,收集统计工作也比较繁重。
3.4.2 以文本为主的近期研究
在如今计算机尤其人工智能飞速发展的时期,问卷调查和社交媒体因为其与用户密切相关的特性,也逐渐被用来对幸福感进行测量评估。问卷调查并不仅是直接使用上文中提到的幸福感测量工具,采集的数据多是与幸福感相关的描述。比如2018年Asai[73]等发布的公开幸福感数据集HappyDB3,它的来源就是对某一工厂的工人进行问卷调查,记录下他们在某一时间段内感到幸福的时刻,共收集到100000个幸福瞬间。社交媒体则是从如Twitter,Flickr,Blog等社交媒体平台中搜集到幸福感相关文本数据。出于社交媒体对于用户的隐私考虑,来源于社交媒体的数据集一般都是自行构建且不会公开。但也有少数公开的数据集,如Jiayin Qi[74] 等公布的搜集于中国草根博客的 Ren-CECps-SWB 2.0 中文数据集。
在方法上,研究者多会用到情感资源,通过情感词典等来辅助评估。下表总结了近几年的相关工作:

首先,从数据来源上看,所列举的文献都是从社交媒体自行构建的数据集,一方面,社交媒体是由用户实时产生数据,与用户直接相关而且数据量庞大,并且相比而言比较容易获得,有利于研究者进行分析;但另一方面,社交媒体平台都会注重用户的隐私问题,所以采集到的数据不易公开,所以需要自行构建数据集。
方法上所有列举文献都在采用情感分析作为依据。因为幸福感也是一种积极的情感,所以可以借助一些情感词典来进行情感分类,外部资源通常是一些公开的情感词典,通过情感上的积极与否来给出一个评估。或者是利用数据来源里的额外信息,比如博客中会提供给作者表达情感的标签,这些都可以作为研究者分析的重要依据。
至于最后评估的指标,可以看到随着时间的推移,有着不小的变化。最初仅是和情感词典进行简单匹配,得到一个大致的估计,但幸福感是一种相对复杂的情感,简单的词典匹配不足以深入的描述它,需要更加科学的指标来进行评估,到后来利用一些科学指标方法,如PANAS,PWBS等,到最终构建面向该任务的评级指标,可以看出对幸福感的评估在趋于科学化,合理化。
幸福感评估的研究从量表开始,然而量表需要专业人士的设计,并且采集数据过程繁琐。随着互联网兴起,文本资源被研究者利用起来,通过自然语言处理等技术,同样能够对用户的幸福感进行评估。计算机科学正在飞速发展中,数据也在井喷式的增加,将计算机科学作用在幸福感数据上,在将来会挖掘出更多的信息,对幸福感的研究提供更多帮助。
3.4.3 小结
幸福感评价量表要求耗时的专业人员设计,数据收集过程也很繁琐,通过计算机科学可以大大提高其效率。未来,对幸福的研究会更加深入细致,数据来源将趋于多样化,不仅仅是问卷和社交媒体,还有可穿戴设备等更丰富的数据可用于从更多维度研究幸福感。同时评价指标将更倾向于与任务相结合,将比现有的心理指标更加多样化、合理化、更加准确地描述幸福程度,并为其他与幸福度量及分析相关任务提供指标。
4. 技术评测及其资源
计算机性格学研究任务中,数据集以及资源的存在是必不可少的,随着社交媒体的普及,以及收集数据工具的增多,使得构建的资源越来越多,以下提出了在性格检测、抑郁检测、自杀检测和幸福感评估中的技术评测及其资源。
4.1性格预测的相关技术评测及其资源
(1)(MBTI) Myers-Briggs Personality Type Dataset
Kaggle上一个开源的基于MBTI指标的竞赛,该项目的目标是预测一个人的MBTI性格类型。给出的数据来自用户社交媒体帖子的Personality Cafe网站论坛,包含8600多行信息,每一行都是一个人的数据,第一列为MBTI指标(4个字母),第二列为该用户最近发布的50条文本信息。格式如下图所示(仅列出前5条数据):

参赛者需要根据MBTI的四个维度,即外向和内向(E/I)、感觉和直觉(N/S)、理性和感性(T/F)、主观和客观(J/P),分别预测这四种类别(每种类别只有两个分类),最后将预测的四种类别组合在一起,即是该用户的MBTI性格类型。
(2)MyPersonality
MyPersonality是一个Facebook应用程序,允许其用户通过填写个性问卷来参与心理研究。它还为他们提供有关分数的反馈。它由David Stillwell于2007年创建。2018年4月,由于维护数据集、审查项目、响应查询等事务繁重以及遵守各种法规(涉及用户隐私问题)等问题,不再共享数据。
(3)Twisty
Ben等人[14]基于Twitter构建的一个使用MBTI量表的语料库,适用于荷兰语、德语等六种语言。它标注了性别、性格等标签,共有18168条数据。
4.2 抑郁检测的相关技术评测及其资源
(1)基于Twitter平台的抑郁检测任务数据集
不同于通过费时费力的访谈和问卷调查获取数据集,Shen等人[38]受到Coppersmithet等(2014)[31]的启发,收集了Twitter上数据,并通过相应的规则,自动地来判定文章是否为抑郁指示性文章;该数据集由抑郁数据集、非抑郁数据集和抑郁倾向性数据集组成,抑郁数据集由在一个月内收集到的相关抑郁性文章(292564条推文)和相关的1402名抑郁用户组成;非抑郁数据集是由Twitter上的标准活跃用户和其所发的推文所组成的;由于抑郁数据集太过稀少,因此在一定程度上放宽了在选择抑郁数据时的标准,若存在“沮丧”等表达,则选为倾向性抑郁数据。该数据集的具体分布如下:

该数据集可作为抑郁检测任务的原始数据集,在该数据集上的准确率能达到85%左右。
(2)基于Reddit平台的抑郁检测任务RSDD数据集
Yates等人(2017)[41]从公共可用的Reddit数据集上收集到用户自我诊断的抑郁检测(RSDD)数据集:其中,收集到的诊断报告被三个非专业人士判断是否患有抑郁症,即为了防止数据集出现“如果我是抑郁症”等假性抑郁症材料。但是由于Reddit平台的特性,RSDD数据集可能不具有代表性,其收集于那些自我诊断为抑郁症的用户,而忽略了那些未进行自我诊断的抑郁症用户,另外,由于用户的匿名,无法证实这些自我诊断为抑郁症的报告是否属实。
该数据集可用于抑郁检测任务,在该数据集上的准确率能达到59%。
4.3 自杀检测的相关评测及其资源
自杀评测CLPsych 2019 Shared Task: Predicting the Degree of Suicide Risk in Reddit Posts
简介:2019年计算语言学和临床心理学研讨会(CLPsych’19)的Shared Task是根据社交媒体发布的信息评估用户自杀风险,数据来源于Reddit帖子,三个子任务都是四分类任务,标签为无、低、中等以及高自杀风险。数据分为两部分,一部分是来源于Reddit自杀版块的帖子,另一部分则来源于非自杀版块的帖子。第一个任务只使用自杀版块的帖子,数据量少;第二个任务使用了自杀和非自杀版块的帖子;第三个任务只使用用户的日常帖子(非自杀版块)。具体数据及结果如下表。

4.4 幸福感评估的相关评测及其资源
评测任务来自于“AffCon2019: The 2nd AAAI Workshopon Affective Content Analysis”,它是AAAI2019中的一个workshop。评测任务使用的数据集是从数据集HappyDB中人工标记的10506条数据和未标记72324条数据。其中每条数据包括某人描述的一个幸福时刻的文本,以及主人公的回忆时间和相关标签。主办方人工标注了两个新的标签:agent和social。agent描述这一个幸福时刻是否作者在控制之中,social描述这一刻是否涉及作者以外的其他人,用0和1表示。评测一共包含两个任务:
任务一的题目是“幸福的要素是什么”。它是一个半监督学习任务:根据已标记和未标记的训练数据,预测测试集中快乐时刻的agent和social标记。评价结果采用了准确度和F1值,最终的评测结果,这里列举了排名前三名的队伍,并且给出了每个队伍的模型和分类结果,详细内容见下表:

任务二的题目是“我们怎样才能塑造幸福”。它是一个无监督任务,为测试集中的快乐时刻提出新的特征和见解(不限主题),例如情感、参与者和内容。任务二作为一个开放性任务,没有统一的评价标准,参赛团队都是在任务一的基础上进行了进一步的分析和可视化,比如探索agent和social标签之间的依赖性。
5. 可解释性与道德问题
随着计算性格研究开始使用社交媒体的文本和其他信息,机器学习和深度学习算法的应用越来越广泛。然而,与心理量表相比,深度学习算法的适用性虽然更好,但也存在可解释性和伦理问题。首先,作为一种黑盒算法,深度学习算法没有很好的心理学理论支持,其结果难以解释。这阻碍了相关算法的发展,也让模型难以深入理解什么是性格。然后,也使得模型的结果更加不可控,这导致很难避免一些潜在的风险(比如模型是否对不同的群体有偏见)。其次,由于深度学习算法需要大量数据,一直面临着数据隐私的问题[83]。如何保证用户在获取和使用数据中的隐私也是非常有争议的问题。
一些研究工作已经对这些问题给出了解答,如Muller 等人[84]提出了十个命令作为参考。然而,计算性格研究中的模型可解释性和伦理问题仍然亟待解决,是一个值得研究的领域。
主要的比较贴近的文献,关键性文献
6. 结论
In this paper, we review recent advances and available data resources in computational personality in four aspects: personality prediction, depression detection, suicide detection, and happiness assessment. We have also conducted an indepth discussion on related fields. In particular, we construct the overall research framework of computational personality, which provides an overview of the research from resource to application. Furthermore, we discuss the ethic issue and interpretability of the algorithms. We hope that our work will encourage further interdisciplinary research on computational personality and facilitate progress in this area.
本文中从四个方面回顾了计算性格学的最新进展和可用的数据资源:人格预测、抑郁检测、自杀检测和幸福感评估。同时,还就相关领域进行了深入探讨,构建了计算性格学的整体研究框架,提供了从资源到应用的研究概述。此外,讨论了算法的伦理问题和可解释性。希望这一工作将推进对计算性格学的进一步研究,并促进该领域的不断进展。
参考文献
参考文献
[1] Funder D C. On the accuracy of personality judgment:a realistic approach[J]. Psychological Review,1995,102(4):652.
[2] C. G. DeYoung. 2010. Toward a theory of the big five. Psychological Inquiry 21(2010), 26–33.
[3] Funder D C. Personality[J]. Annual Review of Psychology, 2001,52(1):197-221.
[4] Pianesi F.Searching for personality [social sciences] [J]. IEEE Signal Processing Magazine, 2013,30(1):146-158.
[5] Shlomo Argamon, Sushant Dhawle , Moshe Koppel , James W. Pennebaker, Lexical predictors of personality type. In Proceedings of the 2005 Joint Annual Meeting of the Interface and the Classification Society of North America.
[6] Zheng Huizhong, Zuo Wanli. Multi-label social network user personality prediction based on information gain and semantic features. Journal of Jilin University. Vol. 54 No. 3 May, 2016.
[7] LiuPing, Cui Zongyi, Zhou Weixiang, Zhang Yangsen. Research on the characterprediction of Weibo users based on behavior information. Journal of Beijing University of Information Science and Technology. Vol. 34 No.3 Jun. 2019.
[8] Michal Kosinski, David Stillwell, and Thore Graepel. 2013. Private traits andattributes are pre- dictable from digital records of human behavior.Proceedings of the National Academy of Sciences, 110(15):5802–5805.
[9] Jennifer Golbeck, Cristina Robles, Karen Turner. Predicting personality with socialmedia. [C]//CHI’11,2011.
[10] Fabio Celli, Elia Bruni, Bruno Lepri. Automatic Personality and Interaction Style Recognition from Facebook Profile Pictures. MM '14: Proceedings of the 22nd ACM international conference on Multimedia. November 2014 Pages 1101–1104.
[11] Marcin Skowron, Marko Tkalcic, Bruce Ferwerda, Markus Schedl: Fusing Social Media Cues: Personality Prediction from Twitter and Instagram. WWW (Companion Volume)2016: 107-108.
[12] Onno Kampman, Elham J. Barezi, Dario Bertero, Pascale Fung: Investigating Audio,Video, and Text Fusion Methods for End-to-End Automatic Personality Prediction.ACL (2) 2018: 606-611.
[13] Süleyman Aslan, Uğur Güdükbay. Multimodal Video-based Apparent Personality Recognition Using Long Short-Term Memory and Convolutional Neural Networks.Computer Vision and Pattern Recognition. (cs.CV)
[14] Ben Verhoeven, Walter Daelemans, Barbara Plank. TWISTY: a Multilingual Twitter Stylometry Corpus for Gender and Personality Profiling. 2016.repository. uantwerpen.be.
[15] Kosuke Yamada, Ryohei Sasano, Koichi Takeda: Incorporating Textual Information on UserBehavior for Personality Prediction. ACL (2) 2019: 177-182.
[16] Mohamed Soliman Halawa, Mohamed Elemam Shehab, Essam M. Ramzy Hamed. Predicting Student Personality Based on a Data Driven Model from Student Behavior on LMS and Social Networks. 2015 IEEE.
[17] Matej Gjurkovic´, Jan Šnajder. Reddit: A Gold Mine for Personality Prediction. Proceedings of the Second Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media, pages 87–97.
[18] ChenXue, Huang Qi, Li Yuxuan, Zheng Shuya, Zhang Ge. Research on User Model Basedon Consumer Character Ontology. Vol. 34, No.3. Jun. 2019.
[19] Cloninger C R, Svrakic D M, Przybeck T R. Can personality assessment predict future depression? A twelve-month follow-up of 631 subjects[J]. Journal ofaffective disorders, 2006, 92(1): 35-44.
[20] Oxman TE, Rosenberg S D, Tucker G J. The language of paranoia[J]. The American journalof psychiatry, 1982.
[21] Rude S, Gortner E M, Pennebaker J. Language use of depressed and depression-vulnerable college students[J]. Cognition & Emotion, 2004, 18(8): 1121-1133.
[22] Resnik P, Garron A, Resnik R. Using topic modeling to improve prediction ofneuroticism and depression in college students[C]//Proceedings of the 2013 conference on empirical methods in natural language processing. 2013:1348-1353.
[23] Rude S,Gortner E M, Pennebaker J. Language use of depressed and depression-vulnerable college students[J]. Cognition & Emotion, 2004, 18(8): 1121-1133.
[24] Beck AT, Ward C H, Mendelson M, et al. An inventory for measuring depression[J]. Archives of general psychiatry, 1961, 4(6): 561-571.
[25] Pennebaker J W, King L A. Linguistic styles: Language use as an individual difference[J]. Journal of personality and social psychology, 1999, 77(6): 1296.
[26] Blei DM, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993-1022.
[27] Moreno M A, Jelenchick L A, Egan K G, et al. Feeling bad on Facebook: Depression disclosures by college students on a social networking site[J]. Depression andanxiety, 2011, 28(6): 447-455.
[28] Park M,Cha C, Cha M. Depressive moods of users portrayed in Twitter[C]//Proceedings of the ACM SIGKDD Workshop on healthcare informatics (HI-KDD). 2012, 2012: 1-8.
[29] De Choudhury M, Gamon M, Counts S, et al. Predicting depression via socialmedia[C]//Seventh international AAAI conference on weblogs and social media.2013.
[30] Park M, McDonald D W, Cha M. Perception differences between the depressed andnon-depressed users in twitter[C]//Seventh International AAAI Conference onWeblogs and Social Media. 2013.
[31] Malmasi S, Zampieri M, Dras M. Predicting post severity in mental health forums[C]//Proceedings of the Third Workshop on Computational Linguistics and Clinical Psychology. 2016: 133-137.
[32] Pennebaker J W, Francis M E, Booth R J. Linguistic inquiry and word count: LIWC 2001[J]. Mahway: Lawrence Erlbaum Associates, 2001, 71(2001): 2001.
[33] Wang T,Brede M, Ianni A, et al. Detecting and characterizing eating-disorder communities on social media[C]//Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. 2017: 91-100.
[34] WilsonT, Hoffmann P, Somasundaran S, et al. OpinionFinder: A system for subjectivity analysis[C]//Proceedings of HLT/EMNLP 2005 Interactive Demonstrations. 2005:34-35.
[35] Thelwall M, Buckley K, Paltoglou G, et al. Sentiment strength detection inshort informal text[J]. Journal of the American society for information scienceand technology, 2010, 61(12): 2544-2558.
[36] Bradley M M, Lang P J. Affective norms for English words (ANEW): Instruction manual andaffective ratings[R]. Technical report C-1, the center for research in psychophysiology, University of Florida, 1999.
[37] Kang K, Yoon C, Kim E Y. Identifying depressive users in Twitter using multimodal analysis[C]//2016 International Conference on Big Data and Smart Computing (BigComp).IEEE, 2016: 231-238.
[38] Shen G,Jia J, Nie L, et al. Depression Detection via Harvesting Social Media: A Multimodal Dictionary Learning Solution[C]//IJCAI. 2017: 3838-3844.
[39] Hiraga M. Predicting depression for japanese blog text[C]//Proceedings of ACL 2017,Student Research Workshop. 2017: 107-113.
[40] Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: Machine learning in Python[J]. Journal of machine learning research, 2011, 12(Oct): 2825-2830.
[41] Yates A, Cohan A, Goharian N. Depression and self-harm risk assessment in onlineforums[J]. arXiv preprint arXiv:1709.01848, 2017.
[42]Kalchbrenner N, Grefenstette E, Blunsom P. A convolutional neural network formodelling sentences[J]. arXiv preprint arXiv:1404.2188, 2014.
[43] Chen X, Sykora M D, Jackson T W, et al. What about mood swings: identifying depressionon twitter with temporal measures of emotions[C]//Companion Proceedings of the The Web Conference 2018. 2018: 1653-1660.
[44] Samareh A, Jin Y, Wang Z, et al. Predicting depression severity by multi-modal feature engineering and fusion[C]//Thirty-Second AAAI Conference on ArtificialIntelligence. 2018.
[45] Ringeval F, Schuller B, Valstar M, et al. Avec 2017: Real-life depression, andaffect recognition workshop and challenge[C]//Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge. 2017: 3-9.
[46] Gui T, Zhu L, Zhang Q, et al. Cooperative Multimodal Approach to Depression Detectionin Twitter[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 110-117.
[47] Shen T,Jia J, Shen G, et al. Cross-domain depression detection via harvesting socialmedia[C]. International Joint Conferences on Artificial Intelligence, 2018.
[48] Courtney Bagge and Augustine Osman. 1998. The suicide probability scale: Normsand factor structure. Psychological reports, 83(2):637–638.
[49] King-wa Fu, Ka Y Liu, and Paul SF Yip. 2007. Predictive validity of the chinese versionof the adult suicidal ideation questionnaire: Psychometric properties and itsshort version. Psychological Assessment, 19(4):422.
[50] Keith M Harris, Jia-Jia Syu, Owen D Lello, YL EileenChew, Christopher H Willcox, and Roger HM Ho.2015. The abcs of suicide risk assessment: Applying a tripartiteapproach to individual evaluations. PLoS One, 10(6):e0127442.
[51] Hajime Sueki.2015. The association of suicide-related Twitter use with suicidal behaviour: a cross-sectional study of young internet users in Japan. Journal ofaffective disorders 170 (2015), 155–160.
[52] Colin G Walsh, Jessica D Ribeiro, and Joseph C Franklin. 2017. Predicting risk ofsuicide attempts over time through machine learning. Clinical Psychological Science 5, 3 (2017), 457–469.
[53] HarishS Bhat and Sidra J Goldman-Mellor. 2017. Predicting Adolescent Suicide Attempts with Neural Networks. arXiv preprint arXiv:1711.10057(2017).
[54] Payam Amini, Hasan Ahmadinia, Jalal Poorolajal, and Mohammad Moqaddasi Amiri. 2016. Evaluating the high risk groups for suicide: A comparison of logistic regression, support vector machine, decision tree and artificial neural network. Iranian journal of public health 45, 9 (2016), 1179.
[55] John Pestian, Henry Nasrallah, Pawel Matykiewicz, Aurora Bennett, and Antoon Leenaars. 2010. Suicide note classification using natural language processing: A content analysis. Biomedical informatics insights, 3:BII–S4706.
[56] Natalie J Jones and Craig Bennell. 2007. The development and validation of statistical prediction rules for discriminating between genuine and simulated suicidenotes. Archives of Suicide Research, 11(2):219–233.
[57] Pete Burnap, Gualtiero Colombo, Rosie Amery, Andrei Hodorog, and Jonathan Scourfield. 2017. Multi-class machine classification of suicide-related communication on twitter. Online social networks and media, 2:32–44.
[58] Tim MH Li, Ben CM Ng, Michael Chau, Paul WCWong, and Paul SF Yip. 2013. Collective intelligence for suicide surveillance in web forums. In Pacific Asia Workshopon Intelligence and Security Informatics, pages 29–37. Springer.
[59] Xiaolei Huang, Xin Li, Tianli Liu, David Chiu, Tingshao Zhu, Lei Zhang. 2015. Topic Model for Identifying Suicidal Ideation in Chinese Microblog. Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, pages 553–562.
[60] BjornGamback and Utpal Kumar Sikdar. 2017. Using convolutional neural networks toclassify hate-speech. In Proceedings of the First Workshop on Abusive LanguageOnline, pages 85–90.
[61] LeiCao, Huijun Zhang, Ling Feng, Zihan Wei, Xin Wang, Ningyun Li, Xiaohao He: Latent Suicide Risk Detection on Microblog via Suicide-Oriented Word Embeddings and Layered Attention. EMNLP/IJCNLP (1) 2019: 1718-1728
[62] Jared Jashinsky, Scott H Burton, Carl L Hanson, JoshWest, Christophe Giraud-Carrier, Michael D Barnes, and Trenton Argyle. 2014. Tracking suicide risk factors through twitter in the us. Crisis.
[63] Munmun De Choudhury, Emre Kiciman, Mark Dredze, Glen Coppersmith, and Mrinal Kumar. 2016. Dis-covering shifts to suicidal ideation from mental health content insocial media. In Proceedings of the 2016 CHI conference on human factors incomputing systems, pages 2098–2110. ACM.
[64] Xu Lipeng, Song Wenai. Suicide idea detection based on Chinese microblog language features [J]. Journal of North University of China (Natural Science Edition), 2019, 40(04): 350-357.
[65] Manas Gaur, Amanuel Alambo, Joy Prakash Sain, Ugur Kursuncu, Krishnaprasad Thirunarayan, Ramakanth Kavuluru, Amit Sheth, Randy Welton, and Jyotishman Pathak. 2019. Knowledge-aware Assessment of Severity of Suicide Risk for Early Intervention. In The World Wide Web Conference (WWW ’19). Association for Computing Machinery, New York, NY, USA, 514–525.
[66] Rohan Mishra, Pradyumna Prakhar Sinha, Ramit Sawhney, Debanjan Mahata, Puneet Mathur, Rajiv Ratn Shah: SNAP-BATNET: Cascading Author Profiling and Social Network Graphs for Suicide Ideation Detection on Social Media. NAACL-HLT (Student Research Workshop) 2019: 147-156.
[67] Jingcheng Du, Yaoyun Zhang, Jianhong Luo, Yuxi Jia, Qiang Wei, Cui Tao, and HuaXu. 2018. Extracting psychiatric stressors for suicide from social media usingdeep learning. BMC medical informatics and decision making 18, 2 (2018), 43.
[68] Diener E. SubjectiveWell-being. Psychology Bulletin.1984, 95 (2)
[69] DieNer,E., Suh, E. M., Lucas, R. E., & Smith, H. L. (1999). Subjective well-being: Three decades of progress. Psychology Bulletin, 125 , 276–302.
[70] Li Yan, Zhao Jun. Overview of research on happiness [J]. Journal of Shenyang Normal University (Social Science Edition), 2004(02): 22-26.
[71] Xu Xingyu. A summary of subjective happiness [J]. Modern Economic Information, 2017(20):363-364.
[72] Liu Lei, Sun Wujun, Jiang Yuan, Fang Ping. Evaluation and Prospect of Happiness Measurement Index System[J]. China Special Education, 2019(02): 66-73.
[73] Asai, A., Evensen, S., Golshan, B., Halevy, A., Li, V., Lopatenko, A., Stepanov, D.,Suhara, Y., Tan, W.C., Xu, Y.: Happydb: A corpus of 100,000 crowd sourced happy moments. In: Proceedings of LREC 2018. European Language Resources Association(ELRA), Miyazaki, Japan (May 2018).
[74] Jiayin Qi, Xiangling Fu, Ge Zhu. China Subjective well-being measurement based on Chinese grassroots blog text sentiment analysis, J. Qi et al. / Information& Management 52 (2015) 859–869.
[75] Sukjin You, Joel DesArmo, and Soohyung Joo. 2013. Measuring happiness of US cities bymining user-generated text in Flickr. com: a pilot analysis. In Proceedings ofthe 76th ASIS&T Annual Meeting: Beyond the Cloud: Rethinking Information Boundaries (ASIST ’13). American Society for Information Science, USA, Article167, 1–4.
[76] Hao B.,Li L., Gao R., Li A., Zhu T. (2014) Sensing Subjective Well-Being from Social Media. In: Ślȩzak D., Schaefer G., Vuong S.T., Kim YS. (eds) Active Media Technology. AMT 2014. Lecture Notes in Computer Science, vol 8610. Springer, Cham.
[77] Shrey Bagroy, Ponnurangam Kumaraguru, and Munmun De Choudhury. 2017. A Social Media Based Index of Mental Well-Being in College Campuses. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems (CHI ’17). Association for Computing Machinery, New York, NY, USA, 1634–1646. https://doi.org/10.1145/3025453.3025909
[78] Dodds,P.S., Harris, K.D., Kloumann, I.M., Bliss, C.A., Danforth, C.M.: Temporal patterns of happiness and information in a global social network: Hedonometricsand twitter. PLoS ONE 6(12), e26752 (2011)
[79] Singh,Kuldeep & Shakya, Harish & Biswas, Bhaskar. (2017). Happiness Index inSocial Network. 10.1007/978-981-10-5780-9_24.
[80] Rajendran, A., Zhang, C., Abdul-Mageed, M.: Happy together: Learning and understanding appraisal from natural language. In: Proceedings of the 2nd Workshop on Affective Content Analysis @ AAAI (AffCon2019). Honolulu, Hawaii. (January 2019)
[81] Saxon, M., Bhandari, S., Ruskin, L., Honda, G.: Word pair convolutional model for happy moment classification. In: Proceedings of the 2nd Workshop on Affective Content Analysis @ AAAI (AffCon2019). Honolulu, Hawaii. (January 2019)
[82] Syed, B., Indurthi, V., Shah, K., Gupta, M., Varma, V.: Ingredientsfor happiness: Modeling constructs via semi-supervised content driven inductivetransfer learning. In: Proceedings of the 2nd Workshop on Affective ContentAnalysis @ AAAI (AffCon2019). Honolulu, Hawaii (January 2019)
[83] Holzinger, Andreas, Peter Kieseberg, Edgar R. Weippl and A Min Tjoa. Current Advances, Trends and Challenges of Machine Learning and Knowledge Extraction: From Machine Learning to Explainable AI. CD-MAKE (2018).
[84] H. Muller, M. Mayrhofer, E. Van Veen and A. Holzinger, “The Ten Commandments of Ethical Medical AI” in Computer, vol.54, no.07,pp.119-123, 2021.
TODO List
- 论文内容整理
- 梳理思维导图