python数据预处理
总览 (Overview)
A large amount of football play by play data was published by Wyscout in May 2019 on figshare.
Wyscout于2019年5月在figshare上发布了大量按比赛数据播放的足球比赛。
These data are JSON format and it is complicated to process, so I tried to preprocess these data to DataFrame format with Python for later analysis. I’m going to use FIFA World Cup 2018 data. Use Google Colab, so you don’t need to build any dev environment on your laptop.
这些数据是JSON格式,处理起来很复杂,因此我尝试使用Python将这些数据预处理为DataFrame格式,以便以后进行分析。 我将使用FIFA World Cup 2018数据。 使用Google Colab,因此您无需在笔记本电脑上构建任何开发环境。
This is not sports analytics article but TIPS for preprocessing with pandas.
这不是体育分析文章,而是有关熊猫预处理的TIPS。
After this process, I visualized passing data. Please see also that article.
完成此过程后,我将传递的数据可视化。 另请参阅该文章。
1.读取Json文件 (1. Read Json files)
I’m going to use these files as follow:
我将按以下方式使用这些文件:
- matches_World_Cup.json matches_World_Cup.json
- events_World_Cup.json events_World_Cup.json
- players.json players.json
- teams.json team.json
Read these files using “pandas.read_json”.
使用“ pandas.read_json”读取这些文件。
import pandas as pd
pd.set_option("max_columns", 100) #This allows us to see a bunch of columnsmatch_origin = pd.read_json("matches_World_Cup.json”.replace(“‘“, ‘“‘))event_origin = pd.read_json(“events_World_Cup.json”.replace(“‘“, ‘“‘))player_origin = pd.read_json(“players.json”.replace(“‘“, ‘“‘))team_origin = pd.read_json(“teams.json”.replace(“‘“, ‘“‘))See inside of dataframe.
参见数据框内部。

Looks good… No, “teamsData” column is nested text data as json format. We need to process this.
看起来不错…不,“ teamsData”列是嵌套文本数据,为json格式。 我们需要对此进行处理。
Get “teamsData” of each row using loop, you can treat as dict type.
使用循环获取每一行的“ teamsData”,您可以将其视为dict类型。
for team_data in match_origin["teamsData"].head():
print(team_data)
2.将嵌套的json转换为dataframe (2. Convert nested json into dataframe)
We cannot use “teamsData” for analysis as it is, so we have to convert “teamsData” into dataframe. We create the two dataframe, one stores match info and another stores match members from “teamsData”.
我们不能按原样使用“ teamsData”进行分析,因此我们必须将“ teamsData”转换为数据框。 我们创建两个数据框,一个存储匹配信息,另一个存储匹配“ teamsData”中的成员。
matchesInfo = pd.DataFrame(
columns=[
“matchId”
,”gameweek”
,"homeAway"
,”homeTeamId”
,”homeScore”
,”homeScoreP”
,”awayTeamId”
,”awayScore”
,”awayScoreP”
]
)matchesMember = pd.DataFrame(
columns=[
“matchId”
,”teamId”
,”homeAway”
,”playerId”
,”startingF”
,”goals”
,”ownGoals”
,”yellowCards”
,”redCards”
]
)We get the value from “teamsData” as dict type using loop.
我们使用循环从“ teamsData”中获取值作为字典类型。
for matchId, gameweek, teams in zip(match_origin[“wyId”], match_origin[“gameweek”], match_origin[“teamsData”]): for team, info in teams.items():
if str(info[“side”]) == “home”:
homeAway = 1
else:
homeAway = 2 matchesInfo = matchesInfo.append(
pd.Series(
[
matchId
,gameweek
,homeAway
,team
,info["score"]
,info["scoreP"]
]
,index=matchesInfo.columns
)
,ignore_index=True
) for startingM in info[“formation”][“lineup”]:
matchesMember = matchesMember.append(
pd.Series(
[
matchId
,team
,homeAway
,startingM[“playerId”]
,1
,startingM[“goals”].replace(“null”,”0")
,startingM[“ownGoals”]
,startingM[“yellowCards”]
,startingM[“redCards”]
]
,index=matchesMember.columns
)
,ignore_index=True
) for benchM in info[“formation”][“bench”]:
matchesMember = matchesMember.append(
pd.Series(
[
matchId
,team
,homeAway
,benchM[“playerId”]
,0
,benchM[“goals”].replace(“null”,”0")
,benchM[“ownGoals”]
,benchM[“yellowCards”]
,benchM[“redCards”]
]
,index=matchesMember.columns
),ignore_index=True
)Let’s see inside.
让我们看看里面。
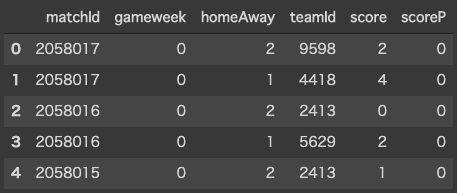

3.将json(字典)转换为数据框 (3. Convert json (dictionary) into dataframe)
Move on to player and team. Both dataset also have json format in area, role and so on, but these are not nested, just dictionary type.
转到球员和团队。 这两个数据集在区域,角色等方面也具有json格式,但它们不是嵌套的,而只是字典类型的。
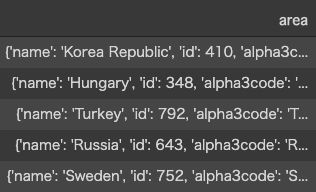

You can use “json_normalize” to convert json (dictionary) into dataframe.
您可以使用“ json_normalize”将json(字典)转换为数据框。
from pandas.io.json import json_normalizeteams = pd.DataFrame(
data={
"teamId": team_origin["wyId"]
,"name": team_origin["name"]
,"officialName": team_origin["officialName"]
}
).join(
pd.DataFrame(
data={
"areaCode": json_normalize(team_origin["area"])["alpha3code"]
,"areaName": json_normalize(team_origin["area"])["name"]
}
)
)players = pd.DataFrame(
data={
"playerId": player_origin["wyId"]
,"clubTeamId": player_origin["currentTeamId"]
,"nationalTeamTd":player_origin["currentNationalTeamId"].replace("null","0")
,"playerName": player_origin["shortName"]
,"firstName": player_origin["firstName"]
,"middleName": player_origin["middleName"]
,"lastName": player_origin["lastName"]
}
).join(
pd.DataFrame(
data={
"positionCode": json_normalize(player_origin["role"])["code2"]
,"positionName": json_normalize(player_origin["role"])["name"]
}
)
)See inside of dataframe.
参见数据框内部。

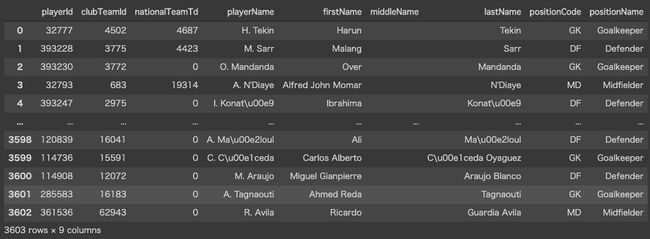
4.按播放数据获取播放 (4. Get play by play data)
In the end, get play by play data which is the most important.
最后,最重要的是逐次播放数据。
Let’s see inside of event data.
让我们看看事件数据的内部。

What is “tags”? You can see api document in this link:
什么是“标签”? 您可以在以下链接中查看api文档:
1801 is accurate pass and 701 is lost. You definitely need to process this column.
1801是准确通过,而701则丢失。 您肯定需要处理此列。
Firstly, we need to define dataframe.
首先,我们需要定义数据框。
events = pd.DataFrame(
columns=[
“eventId”
,”matchId”
,”matchPeriod”
,”teamId”
,”playerId”
,”beforeEventSec”
,”eventSec”
,”eventId”
,”subEventId”
,”goalF”
,”assistF”
,”keyPass”
,”accurateF”
,”fromX”
,”fromY”
,”toX”
,”toY”
]
)Insert data into dataframe using loop in event data. (This takes a long, long time…) I chose Goal, Assist, KeyPass and Accurate Pass in tags, but you can choose whatever you want.
使用事件数据中的循环将数据插入数据框。 (这需要很长时间……)我在标签中选择了目标,辅助,关键密码和准确密码,但是您可以选择任何内容。
beforeSec = 0for index_event,event in event_origin.iterrows():
#initialize variable
fromX = -1
fromY = -1
toX = -1
toY = -1
goal_f = 0
assist_f = 0
keypass_f = 0
accurate_f = 0 for pos in event[‘positions’]:
if (fromX == -1 or fromY == -1):
fromX = pos[“x”]
fromY = pos[“y”]
else:
toX = pos[“x”]
toY = pos[“y”]
for tag in event[‘tags’]:
if int(tag[“id”]) == 101:
goal_f = 1
elif int(tag[“id”]) == 301:
assist_f = 1
elif int(tag[“id”]) == 302:
keypass_f = 1
elif int(tag[“id”]) == 1801:
accurate_f = 1
events = events.append(
pd.Series(
[
event[“id”]
,event[“matchId”]
,event[“matchPeriod”]
,event[“teamId”]
,event[“playerId”]
,beforeSec
,event[“eventSec”]
,event[“eventId”]
,event[“subEventId”]
,goal_f
,assist_f
,keypass_f
,accurate_f
,fromX
,fromY
,toX
,toY
]
,index=events.columns
)
,ignore_index=True
)
beforeSec = event[“eventSec”]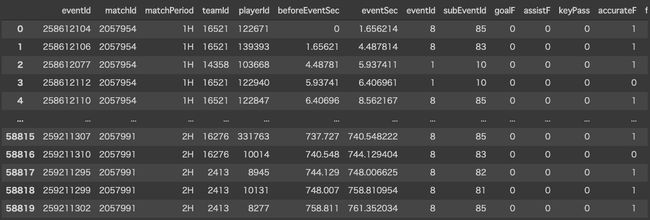
There are no event id and sub event id master as json file, so we need to create.
没有作为json文件的事件ID和子事件ID主文件,因此我们需要创建。
eventKinds = event_origin[[“eventId”,”eventName”]][~event_origin[[“eventId”,”eventName”]].duplicated()]subEventKinds = event_origin[["subEventId","subEventName"]][~event_origin[["subEventId","subEventName"]].duplicated()]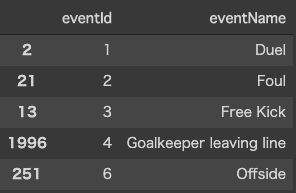

In the end, save dataframe to csv.
最后,将数据帧保存到csv。
matchesInfo.to_csv(“csv/matches.csv”,index=False)
matchesEntry.to_csv(“csv/matches_member.csv”,index=False)
events.to_csv(“csv/events.csv”, index=False)
eventKinds.to_csv(“csv/eventKinds.csv”,index=False)
subEventKinds.to_csv(“csv/subEventKinds.csv”,index=False)
players.to_csv(“csv/players.csv”,index=False)
teams.to_csv(“csv/teams.csv”,index=False)I’m going to visualize data using these csv next time.
下次,我将使用这些csv可视化数据。
Thank you for reading and see you soon!
感谢您阅读并很快见到您!
翻译自: https://medium.com/the-sports-scientist/preprocess-fifa-world-cup-data-with-python-810a9e25e6ec
python数据预处理