SLAM 06.视觉里程计-3-直接法
1、特征法和直接法比较
1.1、特征法的缺点
特征点法有如下几个缺点:
- 特征点法需要提取多个特征点以及描述子,并且要进行多个特征点之间的匹配,运算量很大,难于满足实时要求。SIFT目前在CPU上是无法实时计算的,而ORB也需要近20毫秒的计算时长。如果整个SLAM以30毫秒每帧的速度运行,那么一半时间都将花在计算特征点上。
- 使用特征点时,忽略了除特征点外的所有信息。一幅图像有几十万像素,而特征点只有几百个。只使用特征点丢弃了大部分可能有用的图像信息,之后的运动估计、重建过程并未使用除特征点以外的信息。
- 弱纹理环境下容易失效。相机有时运动到特征缺失的地方,这些地方往往没有明显的纹理信息。例如,有时面对一堵白墙,或者空荡的走廊。这些场景下特征点数量会明显减少,可能找不到足够的匹配特征点来计算相机运动。

1.2、直接法的优缺点
所以就提出了直接法,直接法跳过了提取特征点的步骤。它构建一个优化问题,直接根据像素信息(通常是亮度),来估计相机的运动。这种方法省去了提特征的时间,然而代价则是,利用了所有信息之后,使得优化问题规模远远大于使用特征点的规模。因此,基于直接法的VO,多数需要GPU加速,才能做到实时化。此外,直接方法假设相机运动是连续的、缓慢的。只有在图像足够相似时才有效。而特征点方法在图像差异较大时也能工作。 因为利用了图像中所有的信息,直接法重构的地图是稠密的,这与基于稀疏特征点的VO有很大不同。在稠密地图里,你可以看到每处的细节,而不是离散的点。
直接法相对特征法的好处有:
- 速度快
- 对点特征缺失图像更鲁棒;
- 姿态稳定连续;
- 场景重建较稠密。
1.3、特征法和直接法区别
特征点法通过最小化重投影几何误差(geometric error)来计算相机位姿与地图点的位置(常用的有重投影误差(projection error)等),而直接法则最小化光度误差(photometric error,即像素之间的误差)。所谓光度误差是说,最小化的目标函数,通常由图像之间的灰度误差来决定,而非重投影之后的几何误差。直接法让单独一个点不具备识别意义,而是将大量的点组织起来,因此它的表达是一种细粒度的几何表示。直接法假设同一空间三维点在各个视角下测到的灰度值不变(因此假设所在平面是漫反射,没有遮挡,没有光照变化)。
直接法又分为光流法和直接法。
2、光流
光流就是光在不同时刻在图像之间的流动,分为稀疏光流和稠密光流。计算部分像素运动称为稀疏光流,计算所有像素的称为稠密光流。稀疏光流使用LK算法,稠密使用HS算法。在SLAM中用光流去追一些特征点,例如角点的运动。
2.1、光流法推导过程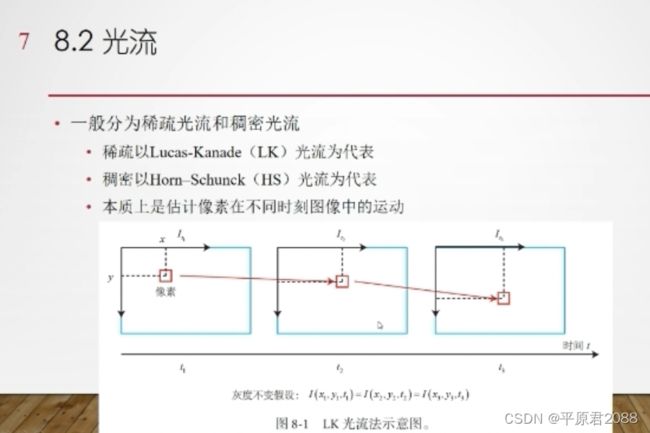
这里要引入光流的基本假设。
- 灰度不变假设:同一空间点的像素灰度值,在各个图像中是固定不变的。
- 假设某一窗口内的像素具有相同的运动,从而来计算u,v。

进行泰勒展开。

上图涉及到图像在x和y方向的灰度梯度以及速度u、v。
这是一个二元一次方程式,求解未知量u、v需要多个方程式。所以还需要加上一个约束,就是在这个光点周围的一定窗口范围内,光亮也是不变的。

例如4*4=16个点,就有k=16个方程式,用来求解两个未知变量u、v。

2.2、光流法总结
光流法可以看做最小化像素误差的非线性优化,但是这种适合于比较连续性的帧之间。但是如果运动速度太快,或者说相机采样频率比较低的时候,图像之间不连续,相差太大,则这种非线性优化可能出现问题。这个时候就采用金字塔的方式,例如降低图像的分辨力,例如除以2,这样两个图像之间的灰度差异距离就接近了,然后去做非线性优化。一般是采用四层金字塔,先从粗再到密,每层上做非线性优化。
光流可以追出特征点,例如先从第一张图像上找到几个关键特征点(但是没必要找出描述子),然后使用光流去追踪出下一幅图像中的特征点。然后使用前面的构图方法,计算2d-3d之间的运动关系,这样就可用于跟踪图像中稀疏关键点之间的轨迹。
我个人的想法:能否在不同图片之间,去除掉差异部分,相同部分就是所跟踪的物体(前提是一辆汽车在运行中形状不会改变),分割出来出目标后,再使用一定的方法进行相似度匹配。
2.3、光流法代码实践
具体的代码实现流程:
1、先用fast检测出第一帧的特征点;
2、使用opencv的光流方法追踪特征点;
3、找到匹配的特征点后,然后用PnP或ICP、对极几何等方法来估计相机运动以及进行位置重构。
所以光流法只是解决了如何找到不同图像之间匹配点的方法,也就是运动跟踪,后续还需要进行位置重构。
3、 直接法
3.1、直接法原理
光流法存在下面的问题:

光流法没有考虑相机本身的内参影响;光流法只是考虑了像素之间的平移,没考虑相机的旋转和图像的缩放,所以就提出了直接法。直接法实际是最小二乘法,就是预估计一个旋转和偏移,然后假设灰度不变,最后用观测到的(也就是第二张图)中像素点去进行非线性最小化误差。
回忆特征点法中,由于我们通过匹配描述子,知道了像素位置,所以可以计算重投影的位置。但在直接法中,由于没有特征匹配,我们无从知道哪一个与对应着同一个点。直接法思路就是估计两张图像之间存在旋转和平移的情况下,同一空间三维点在各个视角下测到的灰度值不变(因此假设所在平面是漫反射,没有遮挡,没有光照变化),那么会存在一个偏差,让这个偏差最小化。因为存在很多个点,所以就能能通过最小化灰度误差得到旋转矩阵R和平移t,可以用高斯牛顿法来求解。
此时最小化的不是重投影误差,而是光度误差(Photometric Error),也就是P的两个像的亮度误差:
能够做这种优化的理由,是基于灰度不变假设。在直接法中,我们假设一个空间点在各个视角下,成像的灰度是不变的。我们有许多个(比如N个)空间点,那么,整个相机位姿估计问题变为: 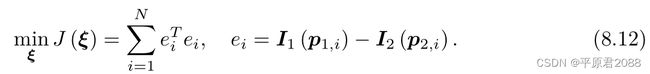
3.2、直接法推导
根据前面的相机模型,得到如下:

I分别为pi在图像对应点的灰度值。随后用非线性优化求解最小测量误差J,得到目标函数:
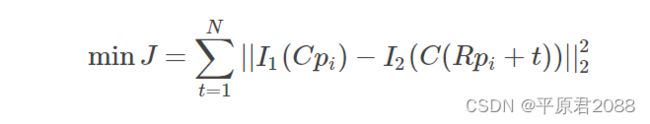
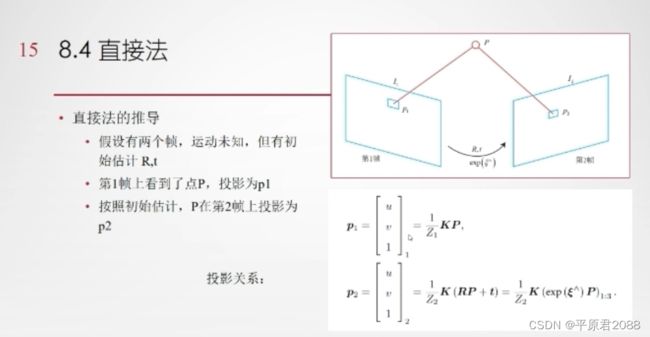
其中Z为深度(距离),K是相机内参,P为真实世界坐标。(u、v、1)为齐次坐标,R为旋转矩阵,t为平移,然后用李代数表示。

对于p1和p2各自对应一个光度,计算两点之间的光度误差。存在很多个点(1到N),则最小化光度误差。最小化一般方法就是求导,但是非线性求导很难,所以就用非线性优化的方法。待估计的量为相机运动,我们关心光度误差相对于相机运动的导数。
利用李代数扰动模型,然后泰勒展开,保留一阶项。
三个导数分别代表(从左往右)图像对像素的导数,像素对空间点的导数,空间点对位姿的李代数的导数。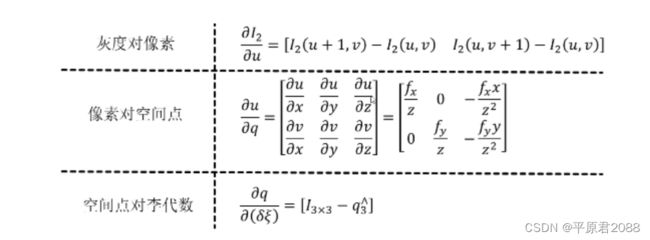
- 第一个是图像对像素的求导,相邻灰度值求导;
- 第二个可以根据u=Cq中的

也容易求得; - 第三个比较难,基本做法是对其做一个左微扰,具体操作是先左乘一个 exp(δξ^),再减去本身,最后除以 δξ
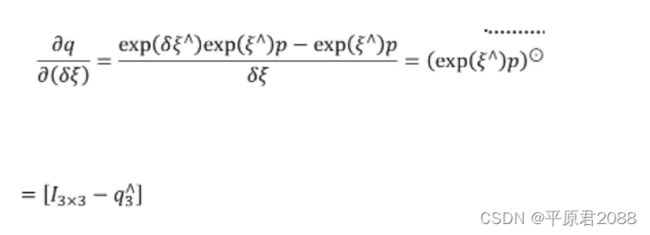
这里存在一个图像梯度因子,当图像梯度不明显的时候,则对相机运动估计的贡献很小。例如平面的地方,或者一片空白的地方,所以一般只处理角点。
3.3、直接法实践
代码流程:
- 用fast提取出特征点;
- 然后用直接法进行非线性最小化的优化。
- 最后也是使用前面的构图方法构建出地图。
见 实践:LK
具体实现技巧是先过滤一遍,把梯度明显的地方过滤出来,然后再使用直接法。直接法应用细节:
1、 只考虑梯度明显的像素点,不明显的点对目标函数贡献不大;
2、 稀疏直接法可以将像素附近patch作为整体计算loss;
3、 灰度不变假设比较严格,当不能稳定成立的时候需要光度标定;
4、 整体目标函数是极度非凸的,需要仔细的初始化。
如果使用的特征点很小,可能效果不好,因为直接法实际就是用大量的点去优化。
也是不适合处理图像之间差异太大的情况。
稠密法,就是把整个梯度比较大的点都过滤出来,然后计算。
3.4、直接法优缺点
缺点
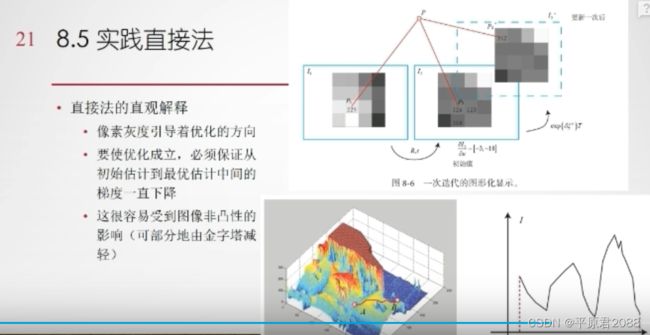

为了解决不连续问题,可以使用金字塔,先在粗糙的分辨率下做一遍,然后在到分辨力高的下再做一遍。只要是灰度渐变,存在梯度,就可以使用直接法。
4、DSO
Direct Sparse Odometry (DSO) 属于稀疏直接法的视觉里程计。它不是完整的SLAM,因为它不包含回环检测、地图复用的功能。因此,它不可避免地会出现累计误差,尽管很小,但不能消除。DSO目前开源了单目实现,双目DSO的论文已被ICCV接收,但目前未知是否开源。DSO是少数使用纯直接法(Fully direct)计算视觉里程计的系统之一。相比之下,SVO[2]属于半直接法,仅在前端的Sparse model-based Image Alignment部分使用了直接法,之后的位姿估计、bundle adjustment,则仍旧使用传统的最小化重投影误差的方式。
从后端来看,DSO使用一个由若干个关键帧组成的滑动窗口作为它的后端。这个窗口在整个VO过程中一直存在,并有一套方法来管理新数据的加入以及老数据的去除。具体来说,这个窗口通常保持5到7个关键帧。前端追踪部分,会通过一定的条件,来判断新来的帧是否可作为新的关键帧插入后端。同时,如果后端发现关键帧数已经大于窗口大小,也会通过特定的方法,选择其中一个帧进行去除。请注意被去除的帧并不一定是时间线上最旧的那个帧,而是会有一些复杂条件的。
DSO的出现将直接法推进到一个相当成熟可用的地位,许多实验已表明它的精度与鲁棒性均优于现在的ORB-SLAM2,而相比之下Large Scale Direct SLAM (LSD-SLAM) 则显然没有那么成熟。
在大部分数据集上,DSO均有较好的表现。虽然DSO要求全局曝光相机,但即使是卷帘快门的相机,只要运动不快,模糊不明显,DSO也能顺利工作。但是,如果出现明显的模糊、失真,DSO也会丢失。
参考
《【读书笔记-视觉SLAM十四讲-第8讲】视觉里程计 2:直接法》
视觉SLAM直接法与特征法及其在多传感融合中的思考
DSO详解
视觉SLAM–直接法
Slam14讲——直接法
SLAM笔记(六)直接法介绍