SLAM 05.视觉里程计-2-特征法
相机模型是理解视觉里程计之前的基础。本文主要是对高翔博士的《SLAM十四讲》的总结。
我们希望测量一个运动物体的轨迹,这可以通过许多不同的手段来实现。例如,我们在汽车轮胎上安装轮式计数码盘,就可以得到轮胎转动的距离,从而得到汽车运动距离的估计。或者,也可以使用IMU来测量汽车的速度、加速度,通过时间积分来计算它的位移。完成这种运动估计的装置(包括硬件和算法)叫做里程计(Odometry)。里程计一个很重要的特性,是它只关心局部时间上的运动,多数时候是指两个时刻间的运动。当我们以某种间隔对时间进行采样时,就可估计运动物体在各时间间隔之内的运动。由于这个估计受噪声影响,先前时刻的估计误差,会累加到后面时间的运动之上,这种现象称为漂移(Drift)。
如果一个里程计主要依靠视觉传感器,比如单目、双目相机,我们就叫它视觉里程计。视觉里程计最主要的问题是如何从几个相邻图像中,估计相机的运动。在SLAM前端的实现主要是视觉里程计,通过多个图片之间的特征值匹配,进行地图重建,同时得到相机机身的定位。视觉里程计(VIO)主要分为特征法和直接法。
如果说特征点法关注的是像素的位置差,那么,直接法关注的则是像素的颜色差。特征点法通常会把图像抽象成特征点的集合,然后去缩小特征点之间的重投影误差;而直接法则通过warp function直接计算像素点在另一张图像上的颜色差,这样就省去了特征提取的步骤。

基于特征的方法是当前视觉里程计的主流方式,特征方法认为,对于两张图像,应该首先选取一些具有代表性的点,称为特征点。之后,仅针对这些特征点估计相机的运动,同时估计特征点的空间位置。图像里其他非特征点的信息,则被丢弃了。
特征法主要解决如下连个问题:
- 我们如何获取图像特征点?如何匹配它们?
- 如何根据已知特征点,计算相机的运动?
人们设计了很多特征点提取方法,包括图像中的角点、色块等。特征法要解决一个重要问题是:在图像发生一定的改变后,特征点提取算法仍能提取出相同的点,并能判别它们之间的相关性。常用的提取和匹配特征点有Harris角点、SIFT、SURF、ORB等。其中ORB是经典的ORB方法。

1、ORB
特征值法首先要找到特征点然后进行匹配。
先了解什么是 特征向量(Feature Vectors)
1.1、地标
一般而言,地标需要满足下面的条件:
- 地标应该可以从不同的位置和角度观察得到;
- 地标应该是独一无二的,从而可以很容易的将底边从其他物体中分辨出来
- 地标不应该过少,从而导致机器人需要花费额外的代价寻找地标;
- 地标应该是静止的,因而,我们最好不要使用一个人作为地标
举例来说,室内环境中的地标,我们可以选择为墙壁与地面之间的连线,以及墙角等。
1.2、特征点
特征点作为路标:可区别性、稳定性、重复性。
1.3、寻找特征点

1、通过FAST找到特征点。周围16个点,比较和中心点的阈值,连续n个超过,则认为是一个特征点;
2、方向不变性:几何中心和质心的连线为方向;
3、尺度不变性:不同分辨率下,使用金字塔方法重新通过FAST获取。
1.4、特征子
对于每一个特征点,为了说明它与其他点的区别,人们还使用“描述子”(Descriptor)对它们加以描述。描述子通常是一个向量,含有特征点和周围区域的信息。如果两个特征点的描述子相似,我们就可以认为它们是同一个点。根据特征点和描述子的信息,我们可以计算出两张图像中的匹配点。
特征子:
通常128个bit,每个bit分别为1,0。
两个点,如果a>b,则为1,否则为0.
两个点为随机获取。
每个特征点对应一个描述子。

1.5、特征点匹配
对于两个特征点之间的距离采用汉明距离,代表他们相似度。汉明距离越短表示越相似。汉明距离就是两个特征子异或后出现1的个数,也就是表示特征值不同的个数,越大则距离越远。
寻找不通点之间的特征点匹配,最简单的就是暴力搜索方法:从第一张图的一个点开始在第二张图上找到所有的点进行匹配,然后遍历第一张图的所有点。 
简单代码如下,通过opencv来实现,最好用opencv3
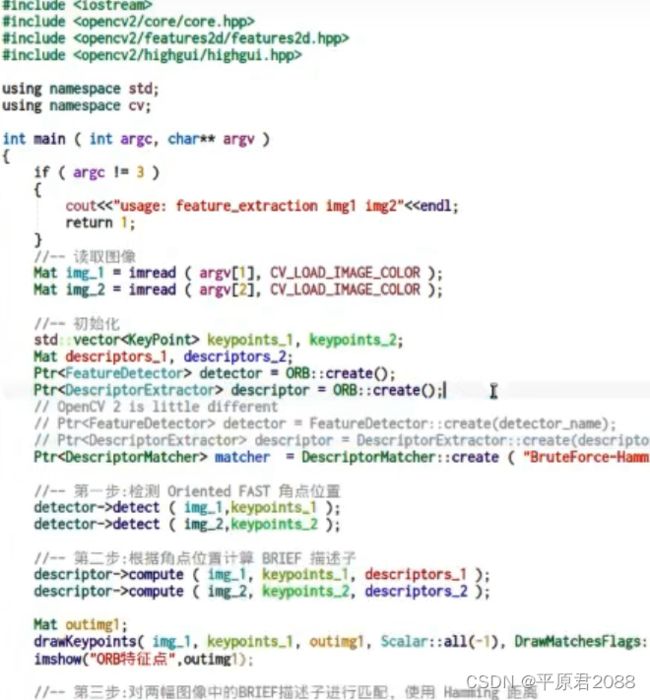
总结起来:
1、先使用ORB生成特征点;
2、针对特征点计算其特征子;
3、匹配两组特征子(使用汉明距离);
4、进行一步自己的筛选,例如先找出最小距离,如果小于最小距离的两倍,则认为是可以的,其他都丢弃掉。
2、定位和构图
知道了特征点以及他们之间的匹配后,就相当于在两张图中知道了同一个点。然后根据这个点来反推两张图之间的旋转和平移。就是根据两组匹配好的点集,计算相机是如何运动的(运动估计),同时根据视觉定位出机器人的位置。
基础知识,下面这篇文章讲得很清楚:
对极几何
本质矩阵E、基本矩阵F和八点法
在普通的单目成像中,我们只知道这两组点的像素坐标。而在双目和RGBD相机中,我们还知道该特征点离相机的距离。因此,该问题就出现了多种形式:
- 2D-2D形式:通过两个2D图像的像素位置来估计相机的运动。
- 3D-2D形式:假设已知其中一组点的3D坐标,以及另一组点的2D坐标,求相机运动。
- 3D-3D形式:两组点的3D坐标均已知,估计相机的运动。

那么问题就来了:是否需要为这三种情况设计不同的计算方法呢?答案是:既可以单独做,也可以统一到一个大框架里去做。
单独做的时候,2D-2D使用对极几何的方法,3D-2D使用PnP求解算法,而3D-3D则称为ICP方法(准确地说,ICP不需要各点的配对关系)。
统一的框架,就是指把所有未知变量均作为优化变量,而几何关系则是优化变量之间的约束。由于噪声的存在,几何约束通常无法完美满足。于是,我们把与约束不一致的地方写进误差函数。通过最小化误差函数,来求得各个变量的估计值。这种思路也称为Bundle Adjustment(BA,中文亦称捆集优化或光束法平差)。
代数方法简洁优美,但是它们对于噪声的容忍性较差。存在误匹配,或者像素坐标存在较大误差时,它给出的解会不可靠。而在优化方法中,我们先猜测一个初始值,然后根据梯度方向进行迭代,使误差下降。Bundle Adjustment非常通用,适用于任意可以建模的模型。但是,由于优化问题本身非凸、非线性,使得迭代方法往往只能求出局部最优解,而无法获得全局最优解。也就是说,只有在初始值足够好的情况下,我们才能希望得到一个满意的解。在实际的VO中,我们会结合这两种方法的优点。先使用代数方法估计一个粗略的运动,然后再用Bundle Adjustment进行优化,求得可精确的值。
2.1、 对极几何(2D-2D)
对极几何处理两张2d图片之间的关系,通产用在SLAM初始化阶段。
我们用两个摄像头可以同时观测到一个特征点,利用匹配的特征点,我们将可以建立对极约束,当匹配的特征点足够多时,我们将可以求解本质矩阵,比如使用常用的八点法,当求解完成后,我们就可以从本质矩阵中分解得到两个相机位置相对的位移和旋转。值得注意的是本质矩阵的自由度是5,因为在位移上,我们丢失了一个自由度的尺度信息。
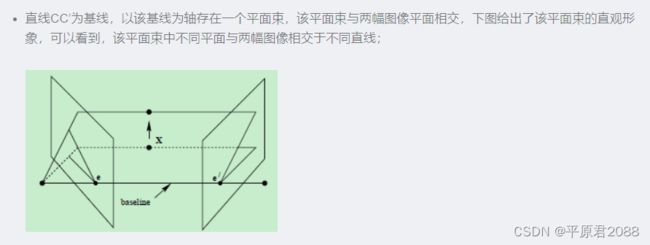
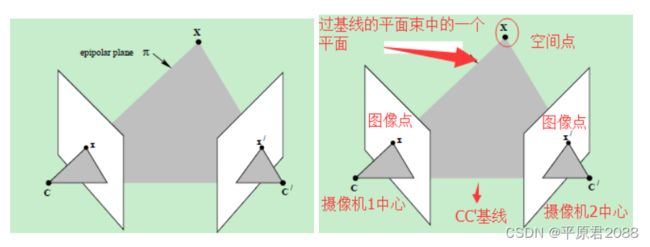
上图中的灰色平面π,只是过基线的平面束中的一个平面(当然,该平面才是平面束中最重要的、也是我们要研究的平面)。
仍以上面贴出的图像为例,此处重复贴出,空间点X在两幅图像中的像分别为x和x’,这两个投影点之间存在什么关系呢?观察下图

上图a中两个摄像机的光心分别是C与C’,而X为一个三维空间点,它在两个摄像机的成像平面上的投影点分别是x与x’。我们常称:
基线:两个摄像机光心的连线CC′。
对极点:上图b中的e与e’,它们分别是一幅视图中另一个摄像机中心的像。二维表示为基线CC′与两个成像平面的交点。
对极平面:是一张包含基线的平面,存在着对极平面的一个集合(以基线为轴转动),上图中的一个例子就是CXC′。
对极线:对极平面与图像平面的交线。上图中的例子是xe与x′e′,一个成像平面上的所有的对极线相交于对极点。
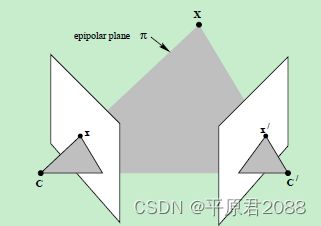
点x、x’与摄像机中心C和C’是共面的,并且与空间点X也是空面的,这5个点共面于平面π!这是一个最本质的约束,即5个点决定了一个平面π。
对极几何相关的一个重要约束·5点共面约束。






推荐算法之SVD算法
什么是特征向量?特征值?
八点法就是在这种前提下产生的,只要获得了8个匹配点,那么就能根据八点法的套路求出基本矩阵 [公式] 。如下所示:

初始化阶段通常用对极几何,所以对极几何主要用于单目SLAM的初始化。等建立图之后,就有了3D的信息了,则可以用3d-2d的PNP方法来解了。

通过opencv可以计算基础矩阵和本质矩阵。

2.2、PNP(3D-2D)
对极几何主要用于单目SLAM的初始化。等建立图之后,就有了3D的信息了,则可以用3d-2d的PNP方法来解了。也就是把2d的图像如何增加到3D地图之中。
PnP (Perspective-n-Point)是已知一组3D点和一组2D点求解相机位姿变化的方法。有P3P、EPnP、DLT直接线性法、 优化方法等。DLT(直接线性变换)是其中的一种求解方法。
详见 《SLAM原理深度解析(8):3D-2D位姿求解》

2.2.1、DLT

需要6对点,才能计算出来。

详见:
PnP问题的DLT解法
2.2.2 P3P


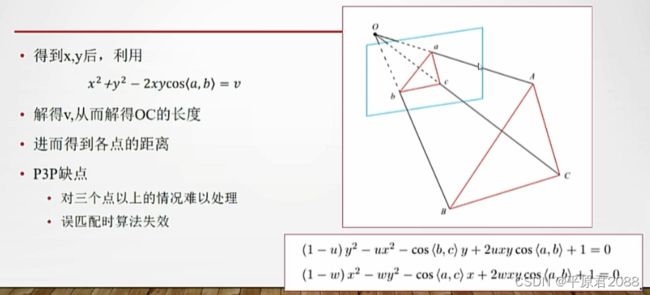
这个能够在三个点下就能处理。
2.2.3 优化解法(Bundle Adjustment)

上图把旋转矩阵用李代数表示。
2.3、ICP(3D-3D)
ICP用来处理3D-3d,三维空间的两个点之间的相对位姿。
详见:
点云配准1-ICP算法 原理代码实现
三维点云配准 – ICP 算法原理及推导
推荐算法之SVD算法
《SLAM前端之ICP算法详解》
[《LIDAR-SLAM] Iterative Closest Point (ICP)简单实现》

把误差平均到每个点上。


让左边项最小化,取某个t让右边项为零。

2.4、小结

3、视觉里程计存在问题
以下再说说视觉里程计存在的问题和困难。
3.1、单目SLAM存在的问题
单目的优点是成本低,最大的局限性是测不到空间物体的距离,只有一个图像。没有距离信息,我们不知道一个东西的远近——所以也不知道它的大小。它可能是一个近处但很小的东西,也可能是一个远处但很大的东西。只有一张图像时,你没法知道物体的实际大小——我们称之为尺度(Scale)。

单目的局限性主要在于我们没法确定尺度,而在双目视觉、RGBD相机中,距离是可以被测量到的(当然测量也有一定的量程和精度限制)。双目视觉和人眼类似,通过左右眼图像的差异来计算距离——也就是所谓的立体视觉(Stereo)。RGBD则是把(通常是红外)光投射到物体表面,再测量反射的信息来计算距离的。
单目SLAM刚开始时,只有2D图像间的信息,没有三维空间的信息,所以要通过图像的运动来解决。初始化问题是一个2D-2D求运动和结构的问题,比3D-2D的PnP要难(信息更少,更不确定)。运动是通过对极几何来求解的,结构是由三角测量得到的。
3.1.1、尺度不确定问题
对极几何最终会分解一个本质矩阵(Essential Matrix)(或基本矩阵(Fundametal Matrix))来得到相机运动。但分解的结果中,**你会发现对平移量乘以任意非零常数,仍满足对极约束。直观地说,把运动和场景同时放大任意倍数,单目相机仍会观察到同样的图像!**这种做法在电影里很常见。例用用相机近距离拍摄建筑模型,影片看起来就像在真实的高楼大厦一样。这个事实称为单目的尺度不确定性(Scale Ambiguity)。所以,我们会把初始化的平移当作单位1,而之后的运动和场景,都将以初始化时的平移为单位。然而这个单位具体是多少,我们不知道(摊手)。并且,在初始化分解本质矩阵时,平移和旋转是乘在一起的。如果初始化时只有旋转而没有平移,初始化就失败了——所以业界有种说法,叫做“看着一个人端相机的方式,就知道这个人有没有研究过SLAM”。有经验的人会尽量带平移,没经验的都是原地打转……所以,从应用上来说,单目需要一个带平移的初始化过程,且存在尺度不确定问题,这是它理论上的障碍。
3.1.2、结构问题
由于单目没有距离信息,所有特征点在第一次出现时都只有一个2d投影,实际的位置可能出现在光心与投影连线的任意一处。只有在相机运动起来以后,才可能通过三角测量,估计特征点的距离。
在单目情形下,你必须移动相机之后,才可能去估计空间点的3D位置。换句话说,如果相机摆在那儿不动——就没有三角了。这导致单目在机器人避障中应用存在困难,不过既然在谈AR我们就先不说机器人吧。
3.1.3、尺度漂移
用单目估计出来的位移,与真实世界相差一个比例,叫做尺度。这个比例在初始化时确定,但单纯靠视觉无法确定这个比例到底有多大。进而,由于SLAM过程中噪声的影响,这个比♂例还不是固定不变的。当你用单目SLAM,会发现,咦怎么跑着跑着地图越来越小了……?

这种现象在当前state-of-the-art的单目开源方案出亦会出现,修正方法是通过回环检测。但是有没有出现回环,则要看实际的运动方式。
3.2、视觉SLAM的困难
双目相机和RGBD相机能够测量深度数据,于是就不存在初始化和尺度上的问题了。但是,整个视觉SLAM的应用中,存在一些共同的困难,主要包括以下几条:
- 相机运动太快
- 相机视野不够
- 计算量太大
- 遮挡
- 特征缺失
- 动态物体或光源干扰
- 作者:半闲居士
链接:https://www.zhihu.com/question/50385799/answer/120902345
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3.2.1、运动太快
运动太快可能导致相机图像出现运动模糊,成像质量下降。传统卷帘快门式的相机,在运动较快时将产生明显的模糊现象。不过现在我们有全局快门的相机了,即使动起来也不会模糊的相机,只是价格贵一些。
图片来自TUM数据集)

(全局快门相机在拍摄高速运动的物体仍是清晰的,图片来自网络)运动过快的另一个结果就是两个图像的重叠区(Overlap)不够,导致没法匹配上特征。所以视觉SLAM中都会选用广角、鱼眼、全景相机,或者干脆多放几个相机。
3.2.2、相机视野不够
如前所述,视野不够可能导致算法易丢失。毕竟特征匹配的前提是图像间真的存在共有的特征。
3.2.3、计算量太大
基于特征点的SLAM大部分时间会花在特征提取和匹配上,所以把这部分代码写得非常高效是很有帮助的。这里就有很多奇技淫巧可以用了,比如选择一些容易计算的特征/并行化/利用指令集/放到硬件上计算等等,当然最直接的就是减少特征点啦。这部分很需要工程上的测试和经验。总而言之特征点的计算仍然是主要瓶颈所在。要是哪天相机直接输出特征点就更好了。
3.2.4、遮挡
相机可能运动到一个墙角,还存在一些邪恶的开发者刻意地用手去挡住你的相机。他们认为你的视觉SLAM即使不靠图像也能顺利地工作。这些观念是毫无道理的,所以直接无视他们即可。
3.2.5、特征缺失、动态光源和人物的干扰
老实说SLAM应用还没有走到这一步,这些多数是研究论文关心的话题(比如直接法)。现在AR能够稳定地在室内运行就已经很了不起了。
3.2.6、可能的解决思路
既然视觉解决不了,那就靠别的来解决吧。毕竟一台设备上又不是只有一块单目相机。更常见的方案是,用视觉+IMU的方式做SLAM。当前广角单目+IMU被认为是一种很好的解决方案。它价格比较低廉,IMU能在以下几点很好地帮助视觉SLAM:IMU能帮单目确定尺度IMU能测量快速的运动IMU在相机被遮挡时亦能提供短时间的位姿估计所以不管在理论还是应用上,都出现了一些单目+IMU的方案[2,3,4]。众所周知的Tango和Hololens亦是IMU+单目/多目的定位方式。
参考
《单目SLAM在移动端应用的实现难点有哪些?》
《SLAM最终话:视觉里程计》
《开源3D激光SLAM总结大全》