YOLOv7与MediaPipe在人体姿态估计上的对比
前期文章的分享,我们介绍了YOLOv7人体姿态估计的文章以及MediaPipe人体姿态估计方面的文章。由于YOLOv7与MediaPipe都可以进行人体姿态估计,我们本期就对比一下2个算法的不同点。
利用机器学习,进行人体33个2D姿态检测与评估
人工智能领域也卷了吗——YOLO系列又被刷新了,YOLOv7横空出世
基于深度学习的人体姿态估计
自2014年Google首次发布DeepPose以来,基于深度学习的姿态估计算法已经取得了较大的进步。这些算法通常分两个阶段工作。
人员检测
关键点定位根据设备[CPU/GPU/TPU]的不同,不同框架的性能有所不同。有许多两阶段姿态估计模型在基准测试中表现良好,例如:Alpha Pose、OpenPose、Deep Pose等等。然而,由于两阶模型相对复杂,获得的实时性能非常昂贵。这些模型在GPU上运行得很快,但在CPU上运行的较慢。就效率和准确性而言,MediaPipe是一个很好的姿态估计框架。它在CPU上生成实时检测,且速度很快。
YOLOv7
与传统的姿态估计算法不同,YOLOv7姿态是一个单级多人关键点检测器。它具有自顶向下和自底向上两种方法中的优点。YOLOv7姿态是在COCO数据集上训练的,前期的文章我们也分享过YOLOv7人体姿态检测的代码。

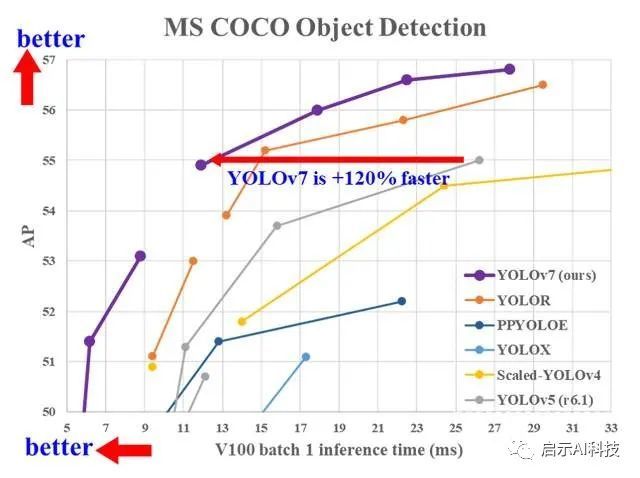
YOLOv7 是 YOLO 系列中最先进的新型物体检测器。根据论文,它是迄今为止最快、最准确的实时物体检测算法。根据 YOLOv7 论文,最好的模型获得了 56.8% 的平均精度(AP),这是所有已知对象检测算法中最高的。各种模型的速度范围为 5-160 FPS。与基础模型相比,YOLOv7 将参数数量减少到40%,计算量减少 50%。
MediaPipe人体姿态检测
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。在谷歌,一系列重要产品,如 、Google Lens、ARCore、Google Home 以及 ,都已深度整合了 MediaPipe。
MediaPipe 的核心框架由 C++ 实现,并提供 Java 以及 Objective C 等语言的支持。MediaPipe 的主要概念包括数据包(Packet)、数据流(Stream)、计算单元(Calculator)、图(Graph)以及子图(Subgraph)。
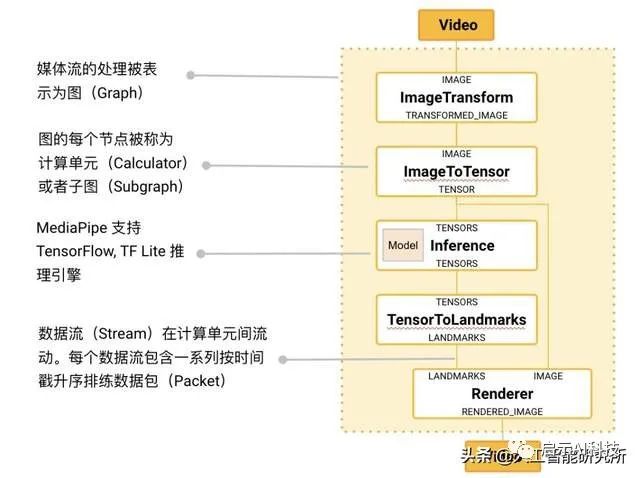
MediaPipe Pose是用于高保真人体姿势跟踪的ML解决方案,利用BlazePose研究成果,还从ML Kit Pose Detection API中获得了RGB视频帧的整个33个2D标志(或25个上身标志)。当前最先进的方法主要依靠强大的桌面环境进行推理,而MediaPipe Pose的方法可在大多数现代手机,甚至是Web上实现实时性能。
MediaPipe中有三个模型用于姿势估计。
BlazePose GHUM Heavy
BlazePose GHUM Full
BlazePose GHUM Lite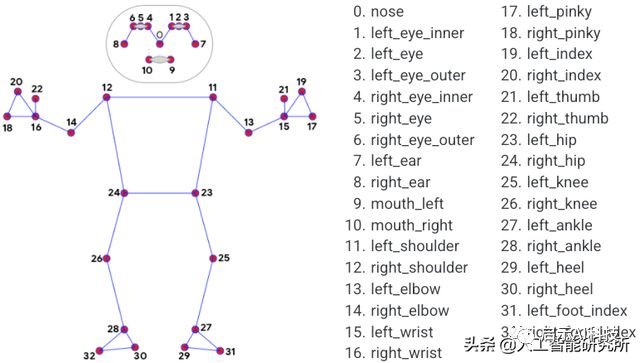
YOLOv7 vs MediaPipe特征对比
| YOLOv7 |
MediaPipe |
|
| Topology |
17 Keypoints COCO |
33 Keypoints COCO + Blaze Palm + Blaze Face |
| Workflow |
Detection runs for all frames |
Detection runs once followed by tracker until occlusion occurs |
| GPU support |
CPU and GPU |
CPU |
| Segmentation |
Segmentation not integrated to pose directly |
Segmentation integrated |
| Number of persons |
Multi-person |
Single person |
YOLOv7是一个多人检测框架。MediaPipe是一个单人检测框架(主要原因是只用于CPU,速度较快),因此在我们实现人体姿态检测时,需要关注是否只检测多人,或者单人,当然对自己的硬件配置也有较高的要求。
MediaPipe 代码实现人体姿态检测
cap = cv2.VideoCapture(0)
time.sleep(2)
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = pose.process(image)
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
cv2.imshow('MediaPipe Pose', image)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
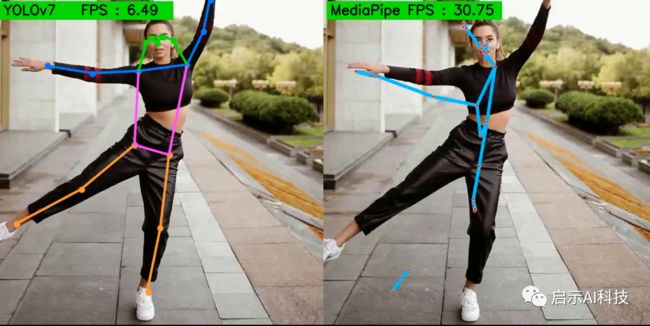
pose.close()cap.release()由于MediaPipe是一个单人检测框架,因此在视频中,MediaPipe只检测单个人的姿态,其他人体姿态则会忽略,当然,软件会检测哪个人体姿态,理论上是最前面的人体姿态,但是通过实验后,其实并不完全是这样。从上图可以看出,虽然MediaPipe仅支持使用在CPU上,但是检测速度与精度相当快,缺点是智能进行单人体姿态检测。
YOLOv7 代码实现人体姿态检测
从 YOLOv7-Tiny 模型开始,参数刚刚超过 600 万。它的验证 AP 为 35.2%,击败了具有相似参数的 YOLOv4-Tiny 模型。具有近 3700 万个参数的 YOLOv7 模型提供了 51.2% 的 AP,再次击败了具有更多参数的 YOLOv4 和 YOLOR 的变体。
YOLO7 系列中较大的模型,YOLOv7-X、YOLOv7-E6、YOLOv7-D6 和 YOLOv7-E6E。所有这些都击败了 YOLOR 模型,它们的参数数量相似,AP 分别为 52.9%、55.9%、56.3% 和 56.8%。
def pose_video(frame):
mapped_img = frame.copy()
img = letterbox(frame, input_size, stride=64, auto=True)[0]
print(img.shape)
img_ = img.copy()
img = transforms.ToTensor()(img)
img = torch.tensor(np.array([img.numpy()]))
img = img.to(device)
with torch.no_grad():
t1 = time.time()
output, _ = model(img)
t2 = time.time()
fps = 1/(t2 - t1)
output = non_max_suppression_kpt(output,
0.25, # Conf. Threshold.
0.65, # IoU Threshold.
nc=1, # Number of classes.
nkpt=17, # Number of keypoints.
kpt_label=True)
output = output_to_keypoint(output)
nimg = img[0].permute(1, 2, 0) * 255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
for idx in range(output.shape[0]):
plot_skeleton_kpts(nimg, output[idx, 7:].T, 3)
return nimg, fps由于YOLOv7是一个多人检测框架,因此在单个视频帧中,YOLOv7框架会实时检测多人体姿态。从上图可以看出,检测速度也是很快的,这是因为此例子使用的是GPU模型运行,若YOLOv7应用在CPU上面,则检测速度很慢。
MediaPipe与YOLOv7对比检测
从以上的介绍,我们知道,mediapipe是一个单人检测框架,因此检测速度特别快,同样的的一段检测对象,同样的使用CPU进行人体姿态检测,则mediapipe完全占绝对优势。
CPU人体姿态检测
但是一旦上GPU,yolov7的优势就会大大的提高,可以看到,一旦用上了GPU,yolov7的检测速度就达到了84FPS,而由于mediapipe仅仅用于CPU,就算加上GPU,也发挥不到GPU的优势。

其他文章参考
Transformer模型注意力机制的概念
利用机器学习,进行人体33个2D姿态检测与评估
利用机器学习,进行人手的21个3D手关节坐标检测
利用机器学习进行人脸468点的3D坐标检测,并生成3D模型
MediaPipe 集成人脸识别,人体姿态评估,人手检测模型
颠覆2D对象检测模型,MediaPipe 3D对象检测还原真实的对象特征
MediaPipe Face Detection可运行在移动设备上的亚毫秒级人脸检测
高大上的YOLOV3对象检测算法,使用python也可轻松实现
使用python轻松实现高大上的YOLOV4对象检测算法
基于python的YOLOV5对象检测模型实现
-
更多Transformer模型 VIT 模型 SWIN Transformer模型 参考头条号:人工智能研究所
VX搜索小程序:AI人工智能工具,体验不一样的AI工具
