机器学习入门
目录
- 1 机器学习概述
- 2 机器学习过程
-
- 2.1 机器学习与人类学习
- 3 机器学习的分类
-
- 3.1 无监督学习
- 3.2 监督学习
- 3.3 深度学习
- 3.4 强化学习
- 4 机器学习应用
1 机器学习概述
参考文献:黄佳《零基础学机器学习》

这里可能会有些乱机器学习和人工智能的关系是什么样的
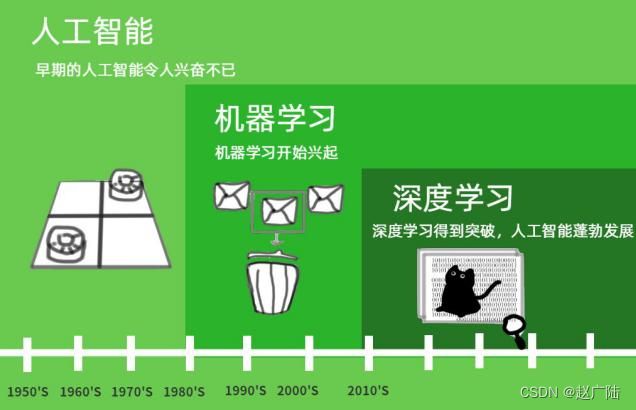
这种热点的形成有多方面的原因。
首先,是数据。在大数据时代,我们终于拥有了算法所需要的海量数据。如果把机器学习比作工业革命时的蒸汽机,那么数据就是燃
料。有了燃料,机器才能够运转。
其次,在硬件方面,随着存储能力、计算能力的增强,以及云服务、GPU(专为执行复杂的数学和几何计算而设计的处理器)等的出现,我们几乎能够随意构建任何深度模型(model)。
最重要的是,两种技术都有特别良好的可达性,几乎能够触达任何一个特定行业的具体场景。简单地说就是实用、“接地气”,大大拓展了AI的应用领域。小到为客户推荐商品、识别语音图像,大到预测天气,甚至探索宇宙星系,只要你有数据,AI几乎可以在任何行业落地。这种可达性和实用性,才是机器学习和深度学习的真正价值所在。
2 机器学习过程
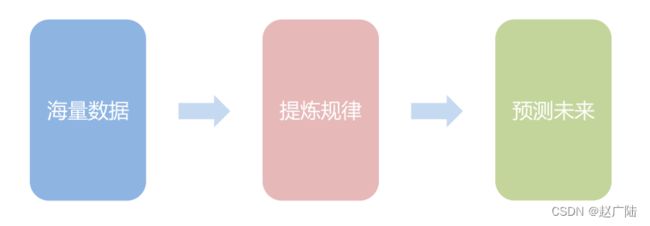
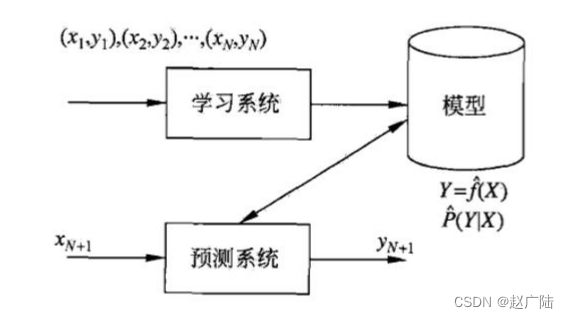
机器学习的关键内涵之一在于利用计算机的运算能力从大量的数据中发现一个“函数”或“模型”,并通过它来模拟现实世界事物间的关系,从而实现预测或判断的功能。这个过程的关键是建立一个正确的模型,因此这个建模的过程就是机器的“学习”。
可能上面的图片有点抽象那么举个具体例子
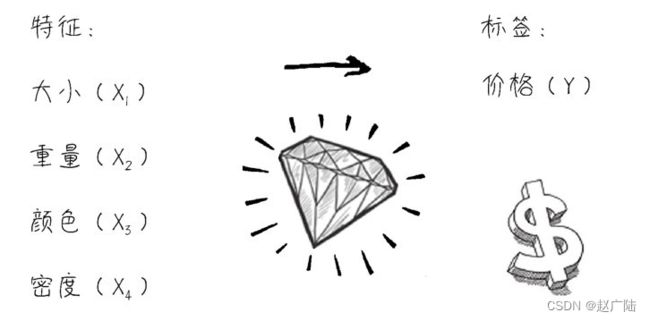

机器学习最核心的就是——从特征到标签
2.1 机器学习与人类学习
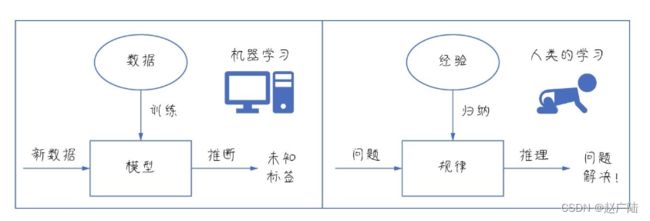
婴儿,他总想吞掉他能够拿到的任何东西,包括硬币和纽扣,但是真的吃到嘴里,会发生不好的结果。慢慢地,他就从这些错误经验中学习到什么能吃,什么不能吃。这是通过试错来积累经验。机器学习的训练、建模的过程和人类的这个试错式学习过程有些相似。机器找到一个函数去拟合(fit)它要解决的问题,如果错误比较严重,它就放弃,再找到一个函数,如果错误还是比较严重,就再找,一直到找到相对最为合适的函数为止,此时犯错误的概率最小。这个寻找的过程,绝大多数情况不是在人类的“指导”下进行的,而是机器通过机器学习算法自己摸索出来的。
这里有一个名词拟合继续应用以前的例子

3 机器学习的分类
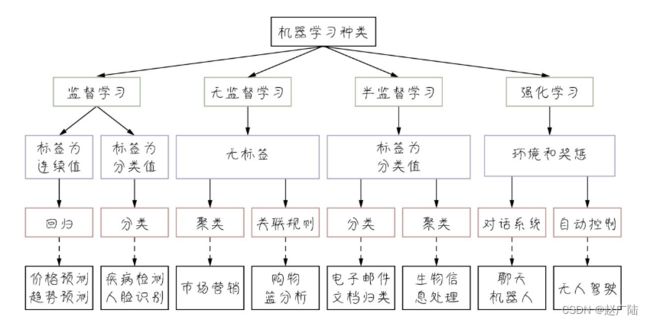
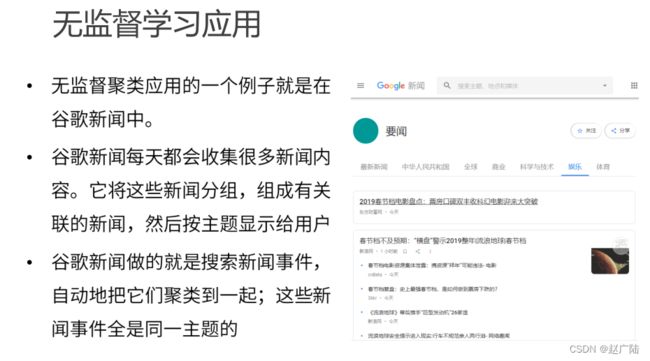
机器学习的类别多,分类方法也多。最常见的分类为监督学习(supervised learning)、 无监督学习(unsupervised learning)和半监督学习(semi-supervised learning)。监督学习的训练需要标签数据,而无监督学习不需要标签数据,半监督学习介于两者之间。使用一部分有标签数据,如下图所示。
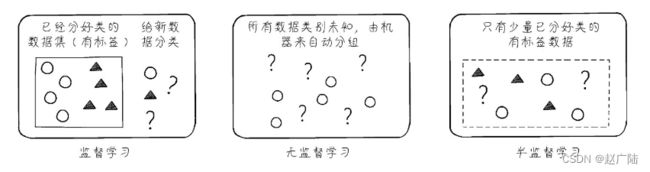
以分类问题展示监督、无监督和半监督学习的区别
比较容易理解的说法,如果训练集数据包含大量的图片,同时告诉计算机哪些是猫,哪些不是猫(这就是在给图片贴标签),根据这些已知信息,计算机继续判断新图片是不是猫。这就是一个监督学习的示例。如果训练集数据只是包含大量的图片,没有指出哪些是猫,哪些是狗,但是计算机经过判断,它能够把像猫的图片归为一组,像狗的图片归为一组(当然它无法理解什么是什么,仅能根据图片特征进行归类而已)。这就是一个无监督学习的示例。
3.1 无监督学习
无监督学习 (Unsupervised Learning) 算法采用一组仅包含输入的数据,通过寻找数据中的内在结构来进行样本点的分组或聚类。
• 算法从没有被标记或分类的测试数据中学习。
• 无监督学习算法不是响应反馈,而是要识别数据中的共性特征;对于一个新数据,可以通过判断其中是否存在这种特征,来做出相应的反馈。 无监督学习的核心应用是统计学中的密度估计和聚类分析。
3.2 监督学习
监督学习 (Supervised Learning) 算法构建了包含输入和所需输出的一组数据的数学模型。这些数据称为训练数据,由一组训练样本组成。
监督学习主要包括分类和回归。
当输出被限制为有限的一组值(离散数值)时使用分类算法;当输出可以具有范围内的任何数值(连续数值)时使用回归算法。
相似度学习是和回归和分类都密切相关的一类监督机器学习,它的目标是使用相似性函数从样本中学习,这个函数可以度量两个对象之间的相似度或关联度。它在排名、推荐系统、视觉识别跟踪、人脸识别等方面有很好的应用场景。
3.3 深度学习
上面说的监督学习与无监督学习,主要是通过数据集有没有标签来对机器学习进行分类。本课程中的一个重点内容深度学习(deep learning),则是根据机器学习的模型或者训练机器时所采用的算法进行分类。
也可以说,监督学习或无监督学习,着眼点在于数据即问题的本身;是传统机器学习还是深度学习,着眼点在于解决问题的方法。
那么深度学习所采用的机器学习模型有何不同呢?答案是4个字:神经网络。当然这种神经网络不是我们平时所说的人脑中的神经网络,而是人工神经网络(Artificial Neural Network, ANN),是数据结构和算法形成的机器学习模型,由大量的所谓人工神经元相互联结而成,这些神经元都具有可以调整的参数,可以实现监督学习或者无监督学习。
大家千万不要被什么人工神经元、神经网络之类的专业名词吓住,觉得这些东西离自己太过于遥远,其实这些数学模型的结构简单得令人吃惊。
初期的神经网络模型比较简单,后来人们发现网络层数越多,效果越好,就把层数较多、结构比较复杂的神经网络的机器学习技术叫作深度学习,如下图所示。这其实是一种品牌重塑,因为神经网络在AI业界曾不受重视,起了一个更高大上的名字之后果然“火了起来”。当然,火起来是大数据时代到来后的必然结果,换不换名字其实倒无所谓。
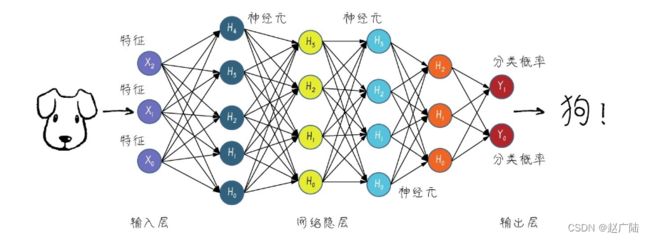
深度学习中的神经网络是神经元组合而成的机器学习模型
神经网络本质上与其他机器学习方法一样,也是统计学方法的一种应用,只是它的结构更深、参数更多。
各种深度学习模型,如卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network,RNN),在计算机视觉、自然语言处理(Natural Language Processing,NLP)、音频识别等应用中都得到了极好的效果。这些问题大多很难被传统基于规则的编程方法所解决,直到深度学习出现,“难”问题才开始变简单了。
而且深度学习的另一大好处是对数据特征的要求降低,自动地实现非结构化数据的结构化,无须手工获取特征,减少特征工程(feature engineering)。特征工程是指对数据特征的整理和优化工作,让它们更易于被机器所学习。在深度学习出现之前,对图像、视频、音频等数据做特征工程是非常烦琐的任务。
什么是自动地实现非结构化数据的结构化,听着像绕口令,你还是再解释一下。
有些数据人很容易理解,但是计算机很难识别。比如说,下图中一个32px×32px的图片,我们一看到就知道写的是8。然而计算机可不知道这图片8背后的逻辑,计算机比较容易读入Excel表格里面的数字8,因为它是存储在计算机文件系统或者数据库中的结构化数据。但是一张图片,在计算机里面存储的形式是数字矩阵,它很难把这个32px×32px的矩阵和数字8联系起来。
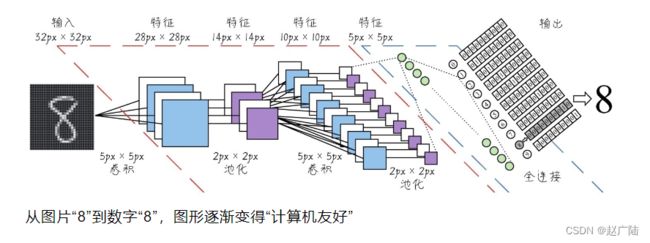
然而,通过深度学习就能够完成图片上这种从非结构化到结构化的转换,你们可以研究一下上图中的这个从图片“8”到数字“8”的过程。通过卷积神经网络的处理,图片‘8’变成了[0000000010]的编码,虽然这样的编码未必让人觉得舒服,但是对于计算机来说这可比32px×32px数字的矩阵好辨认多了。因此,数据结构化的目标也就是:使数据变得计算机友好
看一看下图所示的这个图片识别问题的机器学习流程。使用传统算法,图片识别之前需要手工做特征工程,如果识别数字,可能需要告诉机器数字8有两个圈,通常上下左右都对称;如果辨别猫狗,可能需要预定义猫的特征、狗的特征,等等,然后通过机器学习模型进行分类(可麻烦了)。而深度学习通过神经网络把特征提取和分类任务一并解决了(省了好多事儿)
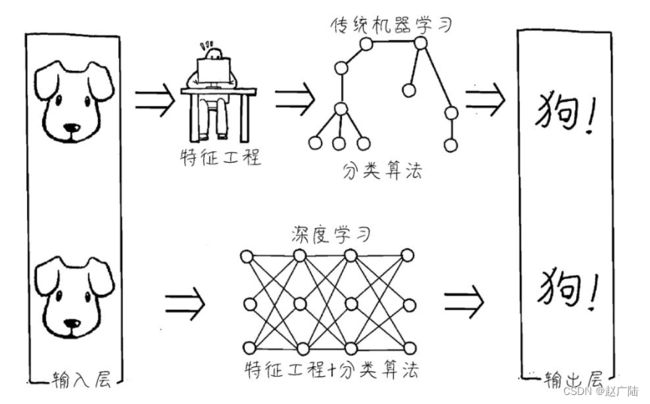
深度学习的优势—减少手工进行的特征工程任务
因此,深度学习的过程,其实也就是一个数据提纯的过程!在大数据时代,深度学习能自动搞定这个提纯过程,可是很了不起的事儿。
3.4 强化学习
4 机器学习应用
机器学习都能做些什么呢?
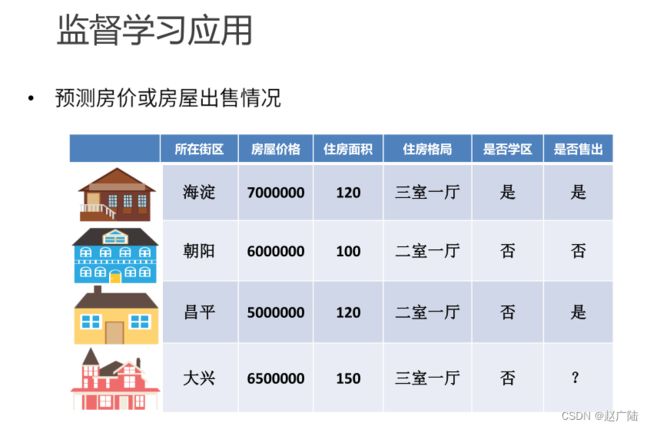
回归和分类
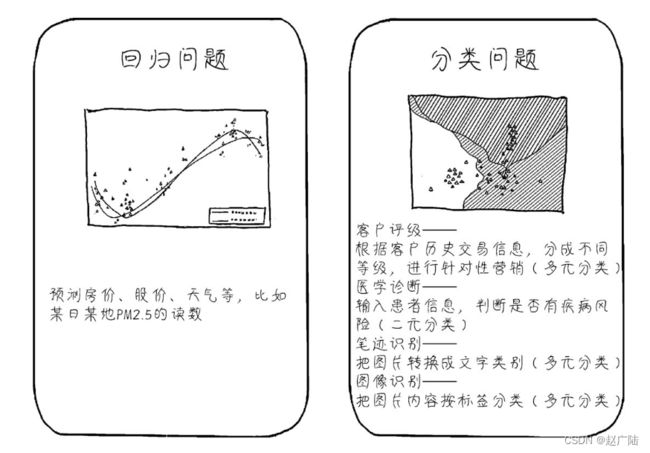
•监督学习问题主要可以划分为两类,即分类问题和回归问题
-分类问题预测数据属于哪一类别。一一离散
-回归问题根据数据预测一个数值。一一连续
回归问题通常用来预测一个值,其标签的值是连续的。例如,预测房价、未来的天气等任何连续性的走势、数值。比较常见的回归算法是线性回归(linear regression)算法以及深度学习中的神经网络等。
通俗地讲,分类问题就是预测数据属于哪一种类型,就像上面的房屋出售预测,通过大量数据训练模型,然后去预测某个给定房屋能不能出售出去,属于能够出售类型还是不能出售类型。
总体来说,机器学习的诀窍在于要了解自己的问题,并针对自己的问题选择最佳的机器学习方法(算法),也就是找到哪一种技术最有可能适合这种情况。如果能把场景或任务和适宜的技术连接起来,就可以在遇到问题时心中有数,迅速定位一个解决方向。下图将一些常见的机器学习应用场景和机器学习模型进行了连接。