DW组队学习task4--MIND
NOTE:本文附录的代码引用自Datawhale推荐系统论文组队学习task4中的代码实现
一、论文的背景
会话推荐的之前的很多工作通常从用户的行为序列中给出一个整体嵌入。但是,一个统一的用户嵌入并不能体现用户在一个时期内的多重兴趣。作者在本文提出了一种新的可控多兴趣框架,称为ComiRec。
二、模块的流程
从用户行为序列中捕获多种兴趣,这可以用于从大规模项目库中检索候选项目。然后,这些项目被输入一个汇总模块,然后就会得到一个推荐。其中的聚集模块利用可控因素来平衡推荐准确性和多样性。
三、主要的技术要点
3.1 注意力机制
注意机制的起源可以追溯到几十年前的计算机视觉领域。然而,它在机器学习的各个领域的普及只是近几年的事情。它首先由被引入机器翻译,后来成为一种突破性的方法,如tensor2tensor模型
3.2 胶囊网络
“胶囊”自从提出动态路由方法以来已经变得众所周知。本模型MIND将胶囊引入推荐领域,并基于动态路由机制使用胶囊网络来捕获电子商务用户的多个兴趣,这适用于对过去的行为进行聚类并提取多样化的兴趣。CARP这一模块首先从用户和项目评论文档中提取视点和方面,并基于其组成视点和方面导出每个逻辑单元的表示,用于评级预测
四、模型概括
4.1 Multi-Interest Framework
下图是模型的主要框架
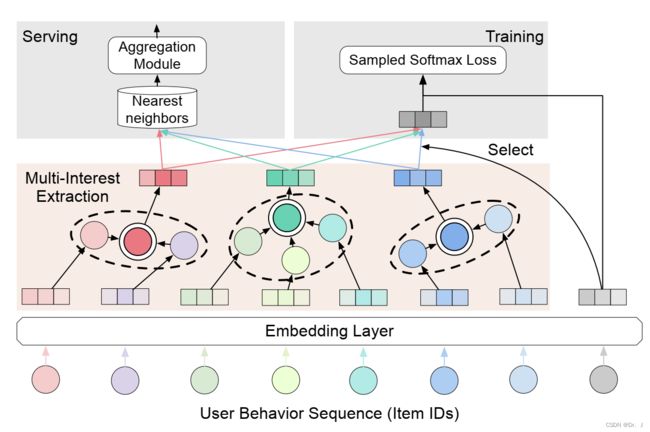
4.2 动态路由
本文使用动态路由方法作为兴趣的提取模块,用户序列的项目嵌入可以被视为初级胶囊,而多个用户兴趣可以被视为兴趣胶囊。
首先计算预测向量如下:
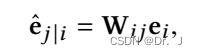
然后计算胶囊的总输入
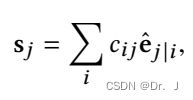
然后计算上式中的cij,基于注意力机制:
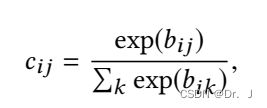
最后得到胶囊的向量表示:
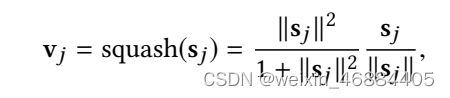
4.3 聚合模块
聚合模块的主要作用就是在多兴趣模块提取完成之后获取了用户的一个embedding,然后每个embedding会基于内部产生邻近性独立的检索前N个item,聚合模块的作用就是根据不同的兴趣来聚合这些item的影响,具体实现见附录的代码部分
五、总结
本文提出了一个新的可控的多兴趣框架用于顺序推荐。由一个多兴趣提取模块和一个聚合模块组成。多兴趣模块的作用是来产生多个用户兴趣,聚合模块的作用是来获取前N个感兴趣的item。本文首次将胶囊网络引入到推荐领域,是一个很大的突破,为之后的模型带来了很多启发
附录
class MIND(nn.Layer):
def __init__(self, config):
super(MIND, self).__init__()
self.config = config
self.embedding_dim = self.config['embedding_dim']
self.max_length = self.config['max_length']
self.n_items = self.config['n_items']
self.item_emb = nn.Embedding(self.n_items, self.embedding_dim, padding_idx=0)
self.capsule = CapsuleNetwork(self.embedding_dim, self.max_length, bilinear_type=0,
interest_num=self.config['K'])
self.loss_fun = nn.CrossEntropyLoss()
self.reset_parameters()
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def forward(self, item_seq, mask, item, train=True):
if train:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
item_e = self.item_emb(item).squeeze(1)
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
cos_res = paddle.bmm(multi_interest_emb, item_e.squeeze(1).unsqueeze(-1))
k_index = paddle.argmax(cos_res, axis=1)
best_interest_emb = paddle.rand((multi_interest_emb.shape[0], multi_interest_emb.shape[2]))
for k in range(multi_interest_emb.shape[0]):
best_interest_emb[k, :] = multi_interest_emb[k, k_index[k], :]
loss = self.calculate_loss(best_interest_emb,item)
output_dict = {
'user_emb': multi_interest_emb,
'loss': loss,
}
else:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
output_dict = {
'user_emb': multi_interest_emb,
}
return output_dict