伯克利开源工具库RLib现已支持大规模多智能体强化学习
AI前线导读:近日,UC伯克利的研究团队RISELab在其Github的项目Ray Rlib 0.6.0中添加了面向多智能体强化学习(multi-agent Reinforcement Learning)的支持。本文由团队成员Eric Liang首发于RISELab团队主页,AI前线翻译整理。本文主要是关于多智能体强化学习的简明教程,以及在RLib中的设计思路。
为什么要使用多智能体强化学习?
研究人员发现,在实际的强化学习设置中,很多问题都讨论到使用多智能体学习是否有意义。在特定的环境中,与训练单一策略的方案相比,多智能体方案能提供以下优点:
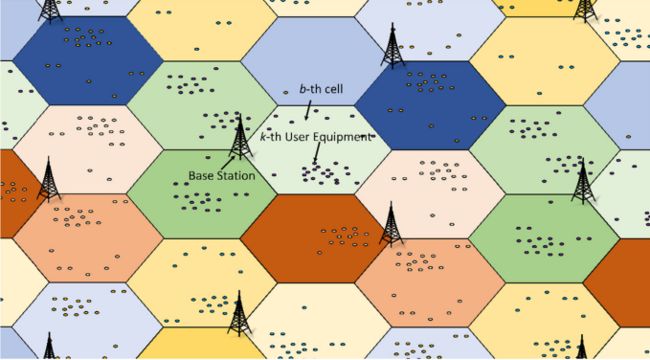
- 对问题的分解更具有可解释性。举个例子,假设现在需要在城市环境中训练蜂窝天线仰角控制的策略。一种方案是训练一个“超级智能体”在城市中控制所有的蜂窝天线,另一种方案是将每个天线建模成分离的智能体,后者显然更加合理。因为只有相邻的天线和用户观测到的天线需要彼此互联,而其他个体之间则不需要复杂的响应机制。
- 对于可扩展性的潜力:首先,将一个庞大的、复杂的单一智能体分解为多个简单的智能体不仅可以减少输入和输出的维度,同时也可以有效的增加每次迭代过程中训练数据的输入数量。其次,对每个智能体的操作和观测空间进行分区,可以起到与时域抽象方法类似的作用,该方法成功地在单智能体策略中提高了学习效率。相对地,类似的分级方法可以显式地实现为多智能体系统。最后,好的分解策略可以对环境变化具有更好的鲁棒性,例如,单一的超智能体很容易对某个特定环境产生过拟合。
一些多智能体应用的例子:
减少交通拥堵:事实证明,智能化控制少数自动驾驶车辆的速度,我们可以大幅增加交通流量。多智能体是这种自动化策略的基础,因为在混合自动化系统中,将交通信号灯和车辆建模为单个智能体是不现实的,因为这需要在一个广泛区域内的所有智能体之间同步所有的观测值和行为。
天线仰角控制:可以根据本地环境的用户分布和拓扑结构来优化蜂窝基站的联合配置。每个基站可以被建模为覆盖城市的多个智能体之一。
OpenAI Five:Dota 2 AI智能体经过训练,可以相互协调并与人类对抗。五个AI玩家中的每一个都作为单独的神经网络策略实施,并与大规模PPO一起训练。
介绍RLib中的多智能体支持
本文主要针对RLib中的通用多智能体支持进行介绍,包括与Rlib中的大多数分布式算法(A2C/A3C、PPO、IMPALA、DQN、DDPG和Ape-X)的兼容性介绍。本文还讨论了多智能体强化学习面临的挑战,并展示了如何使用现有算法训练多智能体策略,同时还提供了针对非平稳环境和环境变化较多情况下的特定算法的实现。
由于当前可供使用的多智能体强化学习库几乎没有,这就增加了基于多智能体方法的实验成本。在科研和应用两个领域中,RLib希望减少从单智能体模式转为多智能体模式的矛盾并简化转变过程。
为什么支持多智能体很困难
为类似强化学习这种快速发展的领域开发软件是极具挑战性的,多智能体强化学习更甚之。这一工作的难点主要是针对处理多智能体学习中出现的核心问题的技术。
举个例子:非平稳环境。在下图中,红色智能体的目标是学习如何调节整个交通流的速度。蓝色智能体则只学习如何最小化它自己的行进时间。红色智能体可以通过简单地以所需速度驾驶来实现其目标。然而,在多智能体环境中,其他智能体将会学习如何达到其目标——例如蓝色智能体通过绕行以缩短其时间。这是有问题的,因为从单智能体的视角来看(例如图中红色智能体),蓝色智能体也是“环境的一部分”。事实上,从单智能体视角来看,环境的动态变化违反了马尔可夫假设,而在Q-learning算法例如DQN中,这是整个算法设计的前提。

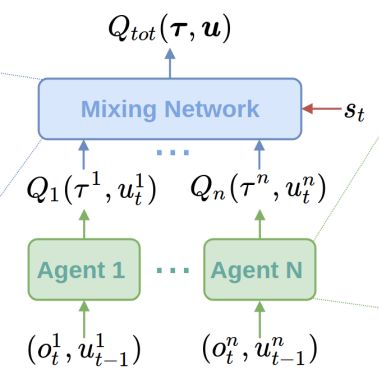
针对上述情况,很多算法被提出,例如LOLA、RIAL和Q-MIX。 从高层面讲,强化学习模型的训练过程中,这些算法会考虑其他智能体的行为。通常是在训练阶段部分集中化,在执行阶段分散化处理。在实现方面,这意味着策略网络之间是彼此依赖的,例如,Q-MIX算法中的网络混合:
类似地,基于梯度策略的算法例如A3C和PPO等,可能无法兼容多智能体配置。因为随着智能体数量的增加,置信度评价将变得越来越困难。考虑下图中这种多智能体的所处的情况。可以看出,随着智能体数量的增加,对智能体的激励与其行为的相关性将会越来越小。此时,交通速度已经降为了0,但是智能体并不能作出正确的响应以打破僵局。

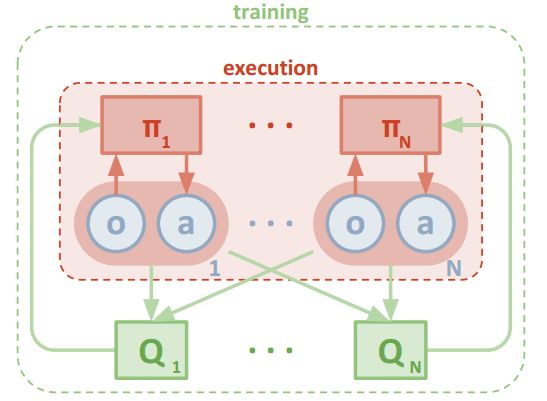
一类方法通过中心化值函数(如图8中的“Q”框)来模拟其他智能体对环境中的影响,MA-DDPG则使用了这种方法。直观地讲,通过统计其他智能体的行为,可以有效减少对每个智能体进行优势估计时的变化性。
到这里,本文已经介绍了研究多智能体强化学习所面临的两大挑战与解决策略。在很多情况下,使用单智能体强化学习算法训练多智能策略可以取得不错的结果。例如,OpenAI Five就是利用了大规模PPO和特殊化网络模型的组合。
在RLib中训练多智能体
那么,在多智能体设置中如何使用特殊化算法与单智能体强化学习?RLib为此设计了简单易行的方法。相关细则如下:
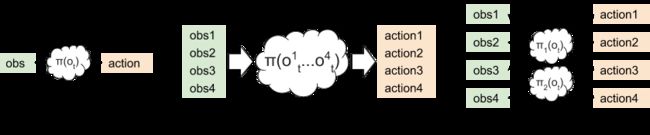
策略被表示为对象:在RLib中,所有的基于梯度的算法都会声明一个策略图对象,该对象包含一个策略模型πθ(ot)和一个轨迹后处理函数postθ(traj)以及策略损失L(θ; X)。该策略图对象为分布式框架提供了足够的内容与功能以执行环境部署(通过检索πθ)、经验整理(通过应用postθ)以及策略优化(通过减小策略损失)。
策略对象是黑箱:为了支持多智能体配置,在每个环境中,RLib仅管理多个策略图的创建与执行,并在策略优化过程中对他们的损失进行累计。在RLib中,策略图对象通常被当成黑箱,这就意味着可以用任何框架(包括TensorFlow和PyTorch)来实现它们。此外,策略图可以在内部共享变量和层以实现Q-MIX和MA-DDPG等算法,而不需要特殊的框架支持。
更了更具体的说明这些细则,接下来的几节将介绍一些RLlib中的多智能体API来执行大规模多智能体训练的代码示例。
多智能体环境模型
由于不确定标准的多智能体环境借口,因此RISELab将这个多智能体环境模型编写为Gym接口的直接扩展。在多智能体环境中,每一步会存在多种行为实体。图6所示的是一种交通控制场景,其中多个可控实体(例如,交通灯、自动驾驶车辆)一起工作以减少高速公路拥堵。
在该场景中:
- 每个智能体都可以在不同的时间尺度上作出响应(即,异步工作)。
- 智能体会随时间进出该环境。
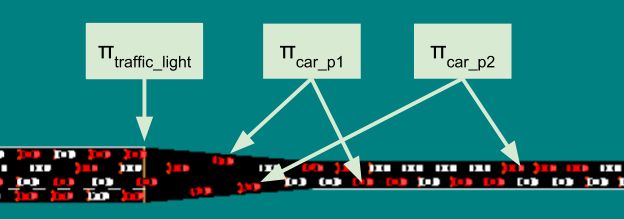
下面这段代码是使用MultiAgentEnv接口的一个示例,该接口可以从多个就绪的智能体中返回观测值和激励:
# 示例:使用多智能体环境\u0026gt; env = MultiAgentTrafficEnv(num_cars=20, num_traffic_lights=5)# 观测值是字典形式的,不是每一个智能体都需要在每个时间点被表示于字典中。\u0026gt; print(env.reset()){ \u0026quot;car_1\u0026quot;: [[...]], \u0026quot;car_2\u0026quot;: [[...]], \u0026quot;traffic_light_1\u0026quot;: [[...]],}# 每个智能体都需要定义一个行为来返回他们的观测值\u0026gt; new_obs, rewards, dones, infos = env.step(actions={\u0026quot;car_1\u0026quot;: ..., \u0026quot;car_2\u0026quot;: ...})# 同样的,新的观测值,激励,完成的,信息等也是字典形式\u0026gt; print(rewards){\u0026quot;car_1\u0026quot;: 3, \u0026quot;car_2\u0026quot;: -1, \u0026quot;traffic_light_1\u0026quot;: 0}# 独立的智能体可以早早离开; 当\u0026quot;__all__\u0026quot;设置为True时,环境配置完成。\u0026gt; print(dones){\u0026quot;car_2\u0026quot;: True, \u0026quot;__all__\u0026quot;: False}OpenAI gym中的任何离散的Box、Dict或者Tuple都可以为这些独立的智能体提供支持,每个智能体都允许接受多种类型的输入(包括智能体间的通信)。
多级的API支持
在较高的层次上,RLib模型将智能体和策略建模为在一段持续时间内可以互相绑定的对象(如图7所示)。用户可以在不同程度上使用这一抽象的对象,从仅使用一个单智能体共享策略到多策略,再到完全自定义的策略优化:
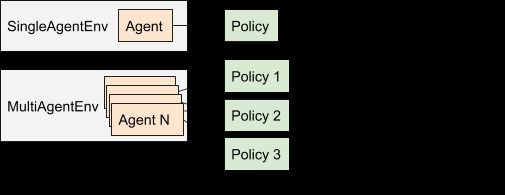
级别1:多智能体,共享策略
如果环境中的所有智能体都是同质的(例如,在交通模拟中的多个独立的车辆),则可以使用现有的单智能体算法进行训练。由于只有一个策略被训练,因此RLib只需要在策略优化之前在内部累积不同智能体的经验,用户方面的变化则很小。
单智能体的情况:
register_env(\u0026quot;your_env\u0026quot;, lambda c: YourEnv(...))trainer = PPOAgent(env=\u0026quot;your_env\u0026quot;)while True: print(trainer.train()) # distributed training step多智能体的情况:
register_env(\u0026quot;your_multi_env\u0026quot;, lambda c: YourMultiEnv(...))trainer = PPOAgent(env=\u0026quot;your_multi_env\u0026quot;)while True: print(trainer.train()) # distributed training step注意,此处的PPOAgent只是从单智能体API继承的命名约定。它更像是智能体的一个训练器而不是真正的智能体。
级别2:多智能体,多策略
这种情况下,需要定义每个智能体会被哪个策略处理。在RLib中可以通过策略映射函数处理此问题,该函数在智能体首次进入环境时将环境中的智能体分配给特定策略。下面的例子展示了一个分级控制设定,其中监督智能体将工作分配给它们监督的工作智能体。完成这一目标的所需配置是监督策略和工作策略的集合:
def policy_mapper(agent_id): if agent_id.startswith(\u0026quot;supervisor_\u0026quot;): return \u0026quot;supervisor_policy\u0026quot; else: return random.choice([\u0026quot;worker_p1\u0026quot;, \u0026quot;worker_p2\u0026quot;])在本例中,我们通常将监督智能体与一个单独的监督策略绑定,然后将其他工作智能体随机分配给两个不同的工作策略绑定。这些配置会在智能体首次进入环境时完成,并在智能体离开环境之前持续工作。最后,我们需要定义不止一个策略配置。这是作为上级智能体配置的一部分来完成的:trainer = PPOAgent(env=\u0026quot;control_env\u0026quot;, config={ \u0026quot;multiagent\u0026quot;: { \u0026quot;policy_mapping_fn\u0026quot;: policy_mapper, \u0026quot;policy_graphs\u0026quot;: { \u0026quot;supervisor_policy\u0026quot;: (PPOPolicyGraph, sup_obs_space, sup_act_space, sup_conf), \u0026quot;worker_p1\u0026quot;: ( (PPOPolicyGraph, work_obs_s, work_act_s, work_p1_conf), \u0026quot;worker_p2\u0026quot;: (PPOPolicyGraph, work_obs_s, work_act_s, work_p2_conf), }, \u0026quot;policies_to_train\u0026quot;: [ \u0026quot;supervisor_policy\u0026quot;, \u0026quot;worker_p1\u0026quot;, \u0026quot;worker_p2\u0026quot;], },})while True: print(trainer.train()) # distributed training step这将生成一个如图5所示的配置。你可以为每个策略定制个性化的策略图类,以及不同的策略配置字典。任何RLib的支持的定制(例如,自定义模型和预处理)都可以用于每个策略,以及新的策略类的批量定义。
其他示例:Sharing layers across policies、 Implementing a centralized critic
级别3:自定义训练策略
对于一些高级的应用于研究情景,不可避免地会遇到一些框架方面的限制。
例如,假设需要多种训练方法的情况:一些智能体将使用PPO进行学习,一些则使用DQN。这种情况下,可以通过在两个不同的训练器之间交换权重来完成(参考代码),但这种方法的可扩展性较差,例如想加入新的算法或是想同时使用经验对环境模型进行训练的时候。
为了应对这种情况,RLib的底层系统Ray可以按需分配计算。Ray提供了两个简单的并行接口:
- Tasks,通过func.remote()被异步执行的Python函数。
- Actors,通过class.remote()在集群中被创建的Python类。Actor方法可以被actor.method.remote()调用。
RLib在Ray的tasks和actors上构建,为分布式强化学习提供工具包。其中包括:
- 策略图(之前示例已展示)
- 策略评估:PolicyEvaluator类会对生成批量经验的环境交互循环进行管理。当创建为Ray actors时,它可以用于在分布式环境中收集经验。
- 策略优化:这一部分用于对策略的优化。你可以使用现有的优化器,也可以使用自定义策略。
例如,你可以创建策略优化器以收集多智能体的输出,然后对他们进行处理以提高策略:
# 初始化一个单节点的Ray集群ray.init()# 为自定义策略图创建局部实例sup, w1, w2 = SupervisorPolicy(), WorkerPolicy(), WorkerPolicy()# 创建策略优化器 (Ray actor进程会在集群中运行)evaluators = []for i in range(16): ev = PolicyEvaluator.as_remote().remote( env_creator=lambda ctx: ControlEnv(), policy_graph={ \u0026quot;supervisor_policy\u0026quot;: (SupervisorPolicy, ...), \u0026quot;worker_p1\u0026quot;: ..., ...}, policy_mapping_fn=policy_mapper, sample_batch_size=500) evaluators.append(ev)while True: # Collect experiences in parallel using the policy evaluators futures = [ev.sample.remote() for ev in evaluators] batch = MultiAgentBatch.concat_samples(ray.get(futures)) # \u0026gt;\u0026gt;\u0026gt; print(batch) # MultiAgentBatch({ # \u0026quot;supervisor_policy\u0026quot;: SampleBatch({ # \u0026quot;obs\u0026quot;: [[...], ...], \u0026quot;rewards\u0026quot;: [0, ...], ... # }), # \u0026quot;worker_p1\u0026quot;: SampleBatch(...), # \u0026quot;worker_p2\u0026quot;: SampleBatch(...), # }) your_optimize_func(sup, w1, w2, batch) # Custom policy optimization # Broadcast new weights and repeat for ev in evaluators: ev.set_weights.remote({ \u0026quot;supervisor_policy\u0026quot;: sup.get_weights(), \u0026quot;worker_p1\u0026quot;: w1.get_weights(), \u0026quot;worker_p2\u0026quot;: w2.get_weights(), })总之,RLib提供了多个层级的API,旨在提高其可定制性。在最高层级,这里提供了几个简单的“开箱即用”的训练过程,但用户也可以从核心的多智能体抽象对象中选择使用自定义的算法和训练策略。这里有一些可以直接运行的脚本供使用: multiagent_cartpole.py, multiagent_two_trainers.py.
性能表现
RLlib旨在扩展到大型集群以及多智能体模式,同时也提供类似向量化这种针对单核心效率的优化。这允许在小型机器上高效地使用多智能体API。
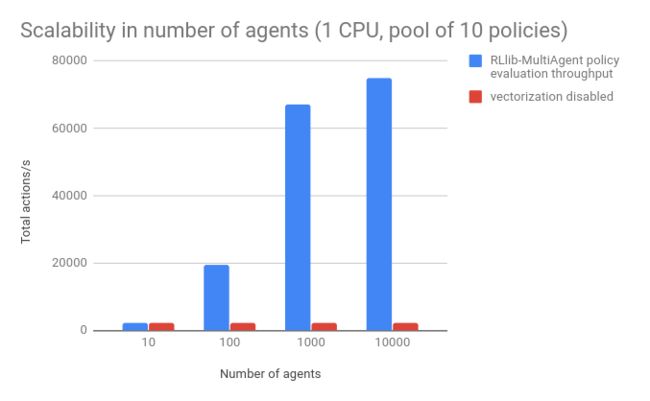
为了说明这些优化方法的重要性,下图分析了单核心策略评估与环境中智能体数量的关系。在这个基准测试中,观测值是小浮点向量,策略是小型16*16的全连接网络。每个智能体被随机分配给10个这样的策略网络。RLib在每个环境中的10000个智能体上管理超过70k actions/s/core(此时Python的计算开销就变成了瓶颈)。当向量化功能关闭的时候,经验累积的速度降低了40倍:
RISELab还评估了在环境中使用多个不同策略网络的更具挑战性的情况。在这里,仍然可以利用向量化将多个TensorFlow调用融合为一个,从而获得更稳定的单核性能,下图是不同策略的数量从1扩展到50的评估结果:

结论
这篇博文介绍了一个快速,通用的多智能体强化学习框架。
RISELab目前正与BAIR,Berkeley FLow team和行业的早期用户合作,以进一步改进RLlib。
快尝试使用’pip install ray [rllib]'快速安装RLib,并运行你自己的测试用例吧。
有关RLlib和多代理支持的文档,请访问https://rllib.io。
查看英文原文:An Open Source Tool for Scaling Multi-Agent Reinforcement Learning
