机器学习中的损失函数(交叉熵损失、Hinge loss)
损失函数
文章目录
- 损失函数
-
- 1 交叉熵损失
-
- 1.1 从最大似然估计到交叉熵损失
-
- 概率论中的MLE
- 机器学习中的MLE
- 交叉熵损失
- 1.2 多分类的交叉熵损失函数
- 1.3 比较
- 2. Hinge loss 铰链损失
1 交叉熵损失
1.1 从最大似然估计到交叉熵损失
概率论中的MLE
最大似然估计用于估计能得到当前数据(分布)的最好的参数组合。对于最简单的x为一维的概率分布我们有
θ ^ M L E = a r g m a x θ f X ( x 1 , x 2 , . . . , x n ; θ ) = a r g m a x θ ∏ i f X ( x i ; θ ) \hat\theta_{MLE}=\underset{\theta}{\mathrm{argmax}}\ f_X(x_1,x_2,...,x_n;\theta)=\underset{\theta}{\mathrm{argmax}}\prod_i\ f_X(x_i;\theta) θ^MLE=θargmax fX(x1,x2,...,xn;θ)=θargmaxi∏ fX(xi;θ)
**maximum likelihood estimate (MLE)**是要找使得似然函数最大的参数,而似然函数是数据的pdf即概率密度函数的乘积。我们希望找到这样的参数使得出现我们现在拿到的这一组数据 { x 1 , x 2 , . . . , x n } \{x_1,x_2,...,x_n\} {x1,x2,...,xn}的可能性最大,这里可能性我们用pdf来衡量。
PDF:概率密度函数(probability density function), 连续型随机变量的概率密度函数是一个描述某个确定的取值点附近的可能性的函数。
机器学习中的MLE
机器学习中的二分类任务,对于有**真实标签 y 1 , y 2 , . . . , y n , y i ∈ { 0 , 1 } y_1,y_2,...,y_n,y_i\in\{0,1\} y1,y2,...,yn,yi∈{0,1}**的数据 { x 1 , x 2 , . . . , x n } \{x_1,x_2,...,x_n\} {x1,x2,...,xn},我们可以将这些数据看成来自不同伯努利分布的数据,即 y i ∼ B ( 1 , p i ) y_i\sim B(1,p_i) yi∼B(1,pi),我们获得尽量准确的每个数据 x i x_i xi来自类别1的努利分布概率,也即找到所有参数 p 1 , p 2 , . . . , p n p_1,p_2,...,p_n p1,p2,...,pn,使得在这样的分布下,出现 y 1 , y 2 , . . . , y n , y i ∈ { 0 , 1 } y_1,y_2,...,y_n,y_i\in\{0,1\} y1,y2,...,yn,yi∈{0,1}这种真实数据的情况的可能性最大(可能性最大这里即是“似然”的思想)。
p ^ 1 , p ^ 2 , . . . , p ^ n = a r g m a x p 1 , p 2 , . . . , p n f X ( y 1 , y 2 , . . . , y n ; p 1 , p 2 , . . . , p n ) = a r g m a x p 1 , p 2 , . . . , p n ∏ i f X ( y i ; p i ) = a r g m a x p 1 , p 2 , . . . , p n ∏ i p i y i ( 1 − p i ) 1 − y i \hat p_1,\hat p_2,...,\hat p_n=\underset{p_1,p_2,...,p_n}{\mathrm{argmax}}\ f_X(y_1,y_2,...,y_n;p_1,p_2,...,p_n)\\ =\underset{p_1,p_2,...,p_n}{\mathrm{argmax}}\prod_i\ f_X(y_i;p_i)\\ =\underset{p_1,p_2,...,p_n}{\mathrm{argmax}}\prod_i\ p_i^{y_i}(1-p_i)^{1-y_i} p^1,p^2,...,p^n=p1,p2,...,pnargmax fX(y1,y2,...,yn;p1,p2,...,pn)=p1,p2,...,pnargmaxi∏ fX(yi;pi)=p1,p2,...,pnargmaxi∏ piyi(1−pi)1−yi
而每个数据 x i x_i xi来自类别1的概率 p i p_i pi,则与通过其他方法得到的 y i y_i yi的预测值 y ^ i \hat y_i y^i有关,即对于每个数据 x i x_i xi,我们会得到预测值 y ^ i \hat y_i y^i对应为两类别的概率,即
P [ y ^ i = 1 ] = p i P [ y ^ i = 0 ] = 1 − p i \Bbb P[\hat y_i=1]=p_i\\ \Bbb P[\hat y_i=0]=1-p_i P[y^i=1]=piP[y^i=0]=1−pi
所以现在问题其实变化成了我们要去找到最好的预测结果 { y ^ i , y ^ 2 , . . . , y ^ n } \{\hat y_i,\hat y_2,...,\hat y_n\} {y^i,y^2,...,y^n},这也就是机器学习方法的“打标签”的目标
y ^ i , y ^ 2 , . . . , y ^ n = a r g m a x y ^ i , y ^ 2 , . . . , y ^ n ∏ i ( P [ y ^ i = 1 ] ) y i ( 1 − P [ y ^ i = 1 ] ) 1 − y i \hat y_i,\hat y_2,...,\hat y_n=\underset{\hat y_i,\hat y_2,...,\hat y_n}{\mathrm{argmax}}\prod_i\ (\Bbb P[\hat y_i=1])^{y_i}(1-\Bbb P[\hat y_i=1])^{1-y_i} y^i,y^2,...,y^n=y^i,y^2,...,y^nargmaxi∏ (P[y^i=1])yi(1−P[y^i=1])1−yi
记似然函数为
L = ∏ i ( P [ y ^ i = 1 ] ) y i ( 1 − P [ y ^ i = 1 ] ) 1 − y i ⇒ log L = ∑ i y i log ( P [ y ^ i = 1 ] ) + ( 1 − y i ) log ( 1 − P [ y ^ i = 1 ] ) \mathcal L=\prod_i\ (\Bbb P[\hat y_i=1])^{y_i}(1-\Bbb P[\hat y_i=1])^{1-y_i} \\ \Rightarrow \log\mathcal L=\sum_i\ {y_i}\log(\Bbb P[\hat y_i=1])+(1-y_i)\log(1-\Bbb P[\hat y_i=1]) \\ L=i∏ (P[y^i=1])yi(1−P[y^i=1])1−yi⇒logL=i∑ yilog(P[y^i=1])+(1−yi)log(1−P[y^i=1])
则我们的目标是要最大化 log L \log\mathcal L logL.
在这个基础上,考虑我们机器学习中的方法常常表述为“最小化loss损失”,所以我们对似然函数取负号,得到loss的形式
l o s s = − ∑ i y i log ( P [ y ^ i = 1 ] ) + ( 1 − y i ) log ( 1 − P [ y ^ i = 1 ] ) loss=-\sum_i\ {y_i}\log(\Bbb P[\hat y_i=1])+(1-y_i)\log(1-\Bbb P[\hat y_i=1]) loss=−i∑ yilog(P[y^i=1])+(1−yi)log(1−P[y^i=1])
另外常常需要对结果作一个归一化,所以除以总的样本数,得到
l o s s = − 1 n ∑ i n y i log ( P [ y ^ i = 1 ] ) + ( 1 − y i ) log ( 1 − P [ y ^ i = 1 ] ) l o s s = − 1 n ∑ i n y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) loss=-\frac{1}{n}\sum_i^n\ {y_i}\log(\Bbb P[\hat y_i=1])+(1-y_i)\log(1-\Bbb P[\hat y_i=1])\\ loss=-\frac{1}{n}\sum_i^n\ {y_i}\log(p_i)+(1-y_i)\log(1-p_i) loss=−n1i∑n yilog(P[y^i=1])+(1−yi)log(1−P[y^i=1])loss=−n1i∑n yilog(pi)+(1−yi)log(1−pi)
可以发现,对于单个样本 i i i,如果真实标签 y i = 1 y_i=1 yi=1,其 l o s s = − log ( P [ y ^ i = 1 ] ) loss=-\log(\Bbb P[\hat y_i=1]) loss=−log(P[y^i=1])随 P [ y ^ i = 1 ] \Bbb P[\hat y_i=1] P[y^i=1]增大而减小;如果真实标签 y i = 0 y_i=0 yi=0,其 l o s s = − log ( 1 − P [ y ^ i = 1 ] ) loss=-\log(1-\Bbb P[\hat y_i=1]) loss=−log(1−P[y^i=1])随 P [ y ^ i = 0 ] \Bbb P[\hat y_i=0] P[y^i=0]增大而减小。
有时将 p i = P [ y ^ i = 1 ] p_i=\Bbb P[\hat y_i=1] pi=P[y^i=1]记为 y ^ i \hat y_i y^i,则变为
l o s s = − 1 n ∑ i n y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) loss=-\frac{1}{n}\sum_i^n\ {y_i}\log(\hat y_i)+(1-y_i)\log(1-\hat y_i) loss=−n1i∑n yilog(y^i)+(1−yi)log(1−y^i)
交叉熵损失
信息熵的定义为
H ( X ) = − ∑ x ∈ X p ( x ) log p ( x ) H(X)=-\sum_{x\in \mathcal X}p(x)\log p(x) H(X)=−x∈X∑p(x)logp(x)
现在再来看交叉熵的公式,它表示分布在共同空间 X \mathcal X X的两个概率分布 p , q p,q p,q之间的差异
H ( p , q ) = − ∑ x ∈ X p ( x ) l o g q ( x ) H(p,q) = -\sum_{x\in \mathcal X}p(x)logq(x) H(p,q)=−x∈X∑p(x)logq(x)
我们想借用交叉熵的概念,来衡量真实数据标签分布 y 1 , y 2 , . . . , y n y_1,y_2,...,y_n y1,y2,...,yn和预测的标签分布 y ^ i , y ^ 2 , . . . , y ^ n \hat y_i,\hat y_2,...,\hat y_n y^i,y^2,...,y^n之间的差异,并把它称为交叉熵损失。注意它们要么都是连续分布,要不都是离散分布,考虑到真实数据标签是离散分布,即每个 y i y_i yi要么等于1的概率为1,要么等于0的概率为1,故预测数据标签也应该是离散分布,即每个 y ^ i \hat y_i y^i等于1、等于0的概率都在0到1之间,即这里共同的空间 Y = { 0 , 1 } \mathcal Y=\{0,1\} Y={0,1}
举例如下表:
| 真实标签 y i ∈ Y = { 0 , 1 } y_i\in\mathcal Y =\{0,1\} yi∈Y={0,1} | y 1 y_1 y1 | y 2 y_2 y2 | y 3 y_3 y3 |
|---|---|---|---|
| P [ y i = 1 ] \Bbb P[y_i=1] P[yi=1] | 1 | 1 | 0 |
| P [ y i = 0 ] \Bbb P[y_i=0] P[yi=0] | 0 | 0 | 1 |
| 预测标签 y ^ i ∈ Y = { 0 , 1 } \hat y_i\in\mathcal Y =\{0,1\} y^i∈Y={0,1} | y 1 y_1 y1 | y 2 y_2 y2 | y 3 y_3 y3 |
|---|---|---|---|
| P [ y ^ i = 1 ] \Bbb P[\hat y_i=1] P[y^i=1] | 0.7 | 0.9 | 0.2 |
| P [ y ^ i = 0 ] \Bbb P[\hat y_i=0] P[y^i=0] | 0.3 | 0.1 | 0.8 |
则在这个空间下每个样本的两个分布 p ( y i ) , q ( y ^ i ) p(y_i),q(\hat y_i) p(yi),q(y^i)的交叉熵为
H ( p ( y i ) , q ( y ^ i ) ) = − ∑ y i , y ^ i ∈ Y p ( y i ) l o g ( q ( y ^ i ) ) = − ∑ y i , y ^ i ∈ { 0 , 1 } p ( y i ) l o g ( q ( y ^ i ) ) = − P [ y i = 1 ] log ( P [ y ^ i = 1 ] ) − P [ y i = 0 ] log ( P [ y ^ i = 0 ] ) = { − log ( P [ y ^ i = 1 ] ) = − log p i , if y i = 1 − log ( P [ y ^ i = 0 ] ) = − log ( 1 − p i ) , if y i = 0 H\Big(p(y_i),q(\hat y_i)\Big)= -\sum_{y_i,\hat y_i\in \mathcal Y}p(y_i)log(q(\hat y_i)) =-\sum_{y_i,\hat y_i\in \{0,1\}}p(y_i)log(q(\hat y_i))\\ =-\Bbb P[y_i=1]\log(\Bbb P[\hat y_i=1]) -\Bbb P[y_i=0]\log(\Bbb P[\hat y_i=0]) \\ =\begin{cases} -\log(\Bbb P[\hat y_i=1])=-\log p_i, & \text {if $y_i=1$ } \\ -\log(\Bbb P[\hat y_i=0])=-\log (1-p_i), & \text{if $y_i=0$ } \end{cases} H(p(yi),q(y^i))=−yi,y^i∈Y∑p(yi)log(q(y^i))=−yi,y^i∈{0,1}∑p(yi)log(q(y^i))=−P[yi=1]log(P[y^i=1])−P[yi=0]log(P[y^i=0])={−log(P[y^i=1])=−logpi,−log(P[y^i=0])=−log(1−pi),if yi=1 if yi=0
则整体样本的交叉熵为
H = − ∑ i n y i log p i + ( 1 − y i ) log ( 1 − p i ) H=-\sum_i^n y_i\log p_i +(1-y_i)\log (1-p_i)\\ H=−i∑nyilogpi+(1−yi)log(1−pi)
加上除以样本数
l o s s = − 1 n ∑ i n y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) loss=-\frac{1}{n}\sum_i^n\ {y_i}\log(p_i)+(1-y_i)\log(1-p_i) loss=−n1i∑n yilog(pi)+(1−yi)log(1−pi)
至此,我们发现二分类问题从MLE推出的损失函数,和交叉熵是一样的,这种损失函数我们称之为交叉熵损失函数。
1.2 多分类的交叉熵损失函数
举例如下表:
| 真实标签 y i ∈ Y = { 1 , 2 , 3 } y_i\in\mathcal Y =\{1,2,3\} yi∈Y={1,2,3} | y 1 y_1 y1 | y 2 y_2 y2 | y 3 y_3 y3 |
|---|---|---|---|
| P [ y i = 1 ] \Bbb P[y_i=1] P[yi=1] | 1 | 0 | 0 |
| P [ y i = 2 ] \Bbb P[y_i=2] P[yi=2] | 0 | 0 | 1 |
| P [ y i = 3 ] \Bbb P[y_i=3] P[yi=3] | 0 | 1 | 0 |
| 预测标签 y ^ i ∈ Y = { 1 , 2 , 3 } \hat y_i\in\mathcal Y =\{1,2,3\} y^i∈Y={1,2,3} | y 1 y_1 y1 | y 2 y_2 y2 | y 3 y_3 y3 |
|---|---|---|---|
| P [ y ^ i = 1 ] \Bbb P[\hat y_i=1] P[y^i=1] | 0.7 | 0 | 0.1 |
| P [ y ^ i = 2 ] \Bbb P[\hat y_i=2] P[y^i=2] | 0.1 | 0.1 | 0.8 |
| P [ y ^ i = 3 ] \Bbb P[\hat y_i=3] P[y^i=3] | 0.2 | 0.9 | 0.1 |
- 从交叉熵来看,若共 C C C个类别
H ( p ( y i ) , q ( y ^ i ) ) = − ∑ y i , y ^ i ∈ { 1 , 2 , . . . , C } p ( y i ) l o g ( q ( y ^ i ) ) = − P [ y i = 1 ] log ( P [ y ^ i = 1 ] ) − P [ y i = 2 ] log ( P [ y ^ i = 2 ] ) − ⋯ − P [ y i = C ] log ( P [ y ^ i = C ] ) H\Big(p(y_i),q(\hat y_i)\Big) =-\sum_{y_i,\hat y_i\in \{1,2,...,C\}}p(y_i)log(q(\hat y_i))\\ =-\Bbb P[y_i=1]\log(\Bbb P[\hat y_i=1])-\Bbb P[y_i=2]\log(\Bbb P[\hat y_i=2])-\cdots-\Bbb P[y_i=C]\log(\Bbb P[\hat y_i=C]) H(p(yi),q(y^i))=−yi,y^i∈{1,2,...,C}∑p(yi)log(q(y^i))=−P[yi=1]log(P[y^i=1])−P[yi=2]log(P[y^i=2])−⋯−P[yi=C]log(P[y^i=C])
故可以推导出交叉熵损失为
⇒ l o s s = − 1 n ∑ i H ( p ( y i ) , q ( y ^ i ) ) = − 1 n ∑ i n ∑ k = 1 C 1 ( y i = k ) log P [ y ^ i = k ] \Rightarrow loss=-\frac{1}{n}\sum_i H\Big(p(y_i),q(\hat y_i)\Big) \\ =-\frac{1}{n}\sum_i^n \sum_{k=1}^C {1}(y_i=k)\log\Bbb P[\hat y_i=k] ⇒loss=−n1i∑H(p(yi),q(y^i))=−n1i∑nk=1∑C1(yi=k)logP[y^i=k]
- 从MLE看同样可以得到类似的结果
现在是多分类不再是伯努利分布,而是多项式分布(Multinomial distribution,投骰子问题) y i ∼ P ( p i 1 , p i 2 , . . . , p i C ) y_i\sim P(p_i^1,p_i^2,...,p_i^C) yi∼P(pi1,pi2,...,piC),这里 y i y_i yi表示one-hot的一种情况 [ y i 1 , y i 2 , . . . , y i C ] = [ 0 , 0 , . . . , 1 , . . . , 0 ] [y_i^1,y_i^2,...,y_i^C]=[0,0,...,1,...,0] [yi1,yi2,...,yiC]=[0,0,...,1,...,0],即 y i k = 1 y_i^k=1 yik=1时表示为第 k k k类,预测值为 [ y ^ i 1 , y ^ i 2 , . . . , y ^ i C ] = [ 0.1 , 0.2 , . . . , 0.7 , . . . , 0 ] [\hat y_i^1,\hat y_i^2,...,\hat y_i^C]=[0.1,0.2,...,0.7,...,0] [y^i1,y^i2,...,y^iC]=[0.1,0.2,...,0.7,...,0]。其实二分类也可以表示成这种形式, [ y i 1 , y i 2 ] = [ 0 , 1 ] , [ y ^ i 1 , y ^ i 2 ] = [ 0.1 , 0.9 ] [y_i^1,y_i^2]=[0,1],[\hat y_i^1,\hat y_i^2]=[0.1,0.9] [yi1,yi2]=[0,1],[y^i1,y^i2]=[0.1,0.9]
对二分类的稍作变换
a r g m a x ∏ i p i y i ( 1 − p i ) 1 − y i = a r g m a x ∏ i p i 1 { y i = 1 } ( 1 − p i ) 1 { y i = 0 } {\mathrm{argmax}}\prod_i p_i^{y_i}(1-p_i)^{1-y_i}={\mathrm{argmax}}\prod_i p_i^{1\{y_i=1\}}(1-p_i)^{1\{y_i=0\}}\\ argmaxi∏piyi(1−pi)1−yi=argmaxi∏pi1{yi=1}(1−pi)1{yi=0}
得到多分类
⇒ a r g m a x ∏ i ( p i 1 ) 1 { y i = 1 } ( p i 2 ) 1 { y i = 2 } ⋯ ( p i C ) 1 { y i = C } = a r g m a x ∏ i n ∏ k C ( p i k ) 1 { y i = k } ⇒ log L = log ∏ i n ∏ k C ( p i k ) 1 { y i = k } = ∑ i n log ∏ k C ( p i k ) 1 { y i = k } = ∑ i n ∑ k C 1 { y i = k } log ( p i k ) \Rightarrow \\ {\mathrm{argmax}}\prod_i (p_i^1)^{1\{y_i=1\}}(p_i^2)^{1\{y_i=2\}}\cdots(p_i^C)^{1\{y_i=C\}}={\mathrm{argmax}}\prod_i^n \prod_k^C (p_i^k)^{1\{y_i=k\}}\\ \Rightarrow \\ \log \mathcal L=\log \prod_i^n \prod_k^C (p_i^k)^{1\{y_i=k\}}=\sum_i^n\log\prod_k^C (p_i^k)^{1\{y_i=k\}}=\sum_i^n\sum_k^C {1\{y_i=k\}}\log(p_i^k)\\ ⇒argmaxi∏(pi1)1{yi=1}(pi2)1{yi=2}⋯(piC)1{yi=C}=argmaxi∏nk∏C(pik)1{yi=k}⇒logL=logi∏nk∏C(pik)1{yi=k}=i∑nlogk∏C(pik)1{yi=k}=i∑nk∑C1{yi=k}log(pik)
故可以推导出损失为和前面交叉熵导出的相同
l o s s = − 1 n ∑ i n ∑ k C 1 { y i = k } log ( p i k ) = − 1 n ∑ i n ∑ k C 1 { y i = k } log P [ y ^ i = k ] loss=-\frac{1}{n}\sum_i^n\sum_k^C {1\{y_i=k\}}\log(p_i^k)=-\frac{1}{n}\sum_i^n\sum_k^C {1\{y_i=k\}}\log\Bbb P[\hat y_i=k] loss=−n1i∑nk∑C1{yi=k}log(pik)=−n1i∑nk∑C1{yi=k}logP[y^i=k]
1.3 比较
| 二分类 | 多分类 | |
|---|---|---|
| MLE形式argmax | a r g m a x p 1 , p 2 , . . . , p n ∏ i p i y i ( 1 − p i ) 1 − y i \underset{p_1,p_2,...,p_n}{\mathrm{argmax}}\prod_i\ p_i^{y_i}(1-p_i)^{1-y_i} p1,p2,...,pnargmax∏i piyi(1−pi)1−yi | a r g m a x ∏ i ( p i 1 ) 1 { y i = 1 } ( p i 2 ) 1 { y i = 2 } ⋯ ( p i C ) 1 { y i = C } {\mathrm{argmax}}\prod_i (p_i^1)^{1\{y_i=1\}}(p_i^2)^{1\{y_i=2\}}\cdots(p_i^C)^{1\{y_i=C\}} argmax∏i(pi1)1{yi=1}(pi2)1{yi=2}⋯(piC)1{yi=C} |
| 单个样本交叉熵表达式 | H ( p ( y i ) , q ( y ^ i ) = − ∑ y i , y ^ i ∈ { 0 , 1 } p ( y i ) l o g ( q ( y ^ i ) ) H(p(y_i),q(\hat y_i)=-\sum_{y_i,\hat y_i\in \{0,1\}}p(y_i)log(q(\hat y_i)) H(p(yi),q(y^i)=−∑yi,y^i∈{0,1}p(yi)log(q(y^i)) | H ( p ( y i ) , q ( y ^ i ) ) = − ∑ y i , y ^ i ∈ { 1 , 2 , . . . , C } p ( y i ) l o g ( q ( y ^ i ) ) H(p(y_i),q(\hat y_i))=-\sum_{y_i,\hat y_i\in \{1,2,...,C\}}p(y_i)log(q(\hat y_i)) H(p(yi),q(y^i))=−∑yi,y^i∈{1,2,...,C}p(yi)log(q(y^i)) |
| 交叉熵损失 | − 1 n ∑ i n y i log ( P [ y ^ i = 1 ] ) + ( 1 − y i ) log ( P [ y ^ i = 0 ] ) -\frac{1}{n}\sum\limits_i^n\ {y_i}\log(\Bbb P[\hat y_i=1])+(1-y_i)\log(\Bbb P[\hat y_i=0]) −n1i∑n yilog(P[y^i=1])+(1−yi)log(P[y^i=0]) | − 1 n ∑ i n ∑ k C 1 { y i = k } log P [ y ^ i = k ] -\frac{1}{n}\sum\limits_i^n\sum\limits_k^C {1\{y_i=k\}}\log\Bbb P[\hat y_i=k] −n1i∑nk∑C1{yi=k}logP[y^i=k] |
2. Hinge loss 铰链损失
Ref:
https://blog.csdn.net/hustqb/article/details/78347713
wiki
在机器学习中,hinge loss作为一个损失函数(loss function),通常被用于最大间隔算法(maximum-margin),而最大间隔算法又是SVM(支持向量机support vector machines)用到的重要算法(注意:SVM的学习算法有两种解释:1. 间隔最大化与拉格朗日对偶;2. Hinge Loss)。
Hinge loss专用于二分类问题,标签值 y = ± 1 y = ±1 y=±1,预测值 y ^ = w x + b ∈ R \hat y=wx+b\in \Bbb R y^=wx+b∈R.
对任意一个样本,hinge loss定义为
L ( x i , y i ) = max { 0 , 1 − y i ⋅ y ^ i } = max { 0 , 1 − y i ( w x i + b ) } \mathcal L(\mathbf x_i,y_i)=\max\{0,1-y_i\cdot \hat y_i\}=\max\{0,1-y_i(\mathbf w \mathbf x_i+b)\} L(xi,yi)=max{0,1−yi⋅y^i}=max{0,1−yi(wxi+b)}
注意这里的 y ^ i = w x i + b \hat y_i=\mathbf w \mathbf x_i+b y^i=wxi+b是没有经过sign等激活函数的,是直接在数据平面上经过变换后的值。可以取任意值。
y ^ i = w x i + b > 0 \hat y_i=\mathbf w \mathbf x_i+b>0 y^i=wxi+b>0表示一类, y ^ i = w x i + b < 0 \hat y_i=\mathbf w \mathbf x_i+b<0 y^i=wxi+b<0表示另一类。
当 y i ⋅ y ^ i > 1 y_i\cdot \hat y_i>1 yi⋅y^i>1时, L ( x i , y i ) = 0 \mathcal L(\mathbf x_i,y_i)=0 L(xi,yi)=0;
当 y i ⋅ y ^ i < 1 y_i\cdot \hat y_i<1 yi⋅y^i<1时, L ( x i , y i ) = 1 − y i ⋅ y ^ i = 1 − y i ⋅ ( w x i + b ) \mathcal L(\mathbf x_i,y_i)=1-y_i\cdot \hat y_i=1-y_i\cdot (\mathbf w \mathbf x_i+b) L(xi,yi)=1−yi⋅y^i=1−yi⋅(wxi+b).
对比感知机的loss为:
当 y i ( w x i + b ) > 0 y_i(\mathbf w \mathbf x_i+b)>0 yi(wxi+b)>0时, L ( x i , y i ) = 0 \mathcal L(\mathbf x_i,y_i)=0 L(xi,yi)=0;
当 y i ( w x i + b ) < 0 y_i(\mathbf w \mathbf x_i+b)<0 yi(wxi+b)<0时, L ( x i , y i ) = − y i ⋅ ( w x i + b ) \mathcal L(\mathbf x_i,y_i)=-y_i\cdot (\mathbf w \mathbf x_i+b) L(xi,yi)=−yi⋅(wxi+b).
如下图:
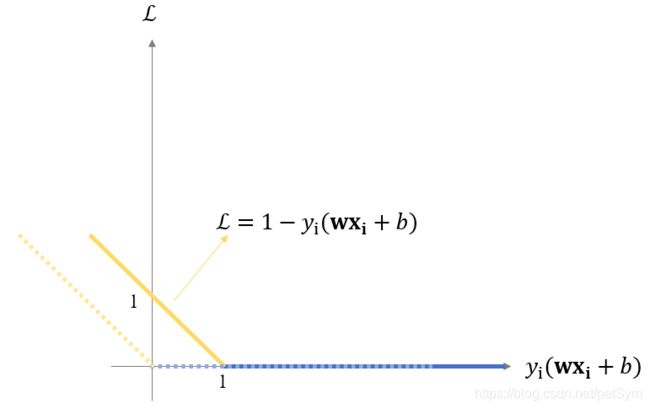
hinge loss相对于感知机的loss向右平移了一个单位,相当于不再单单要求分类正确,还对每个点离分类平面的距离有一定的要求。这其实就是SVM中,从最优化求几何间隔最大的分离超平面,到最优化函数间隔最大的分离超平面,再到约定的函数间隔的值对优化求解超平面没有影响,优化问题是等价的,故而直接取了函数间隔为1,得到约束条件
y i ( w x i + b ) ≥ 1 ⇒ y i ( w x i + b ) − 1 ≥ 0 y_i(\mathbf w \mathbf x_i+b)\geq 1\\ \Rightarrow \\ y_i(\mathbf w \mathbf x_i+b)- 1\geq 0 yi(wxi+b)≥1⇒yi(wxi+b)−1≥0
即满足以上远离超平面一定距离的条件,才认为分类是正确的。这就得到了我们的hinge loss中,满足条件的时候,分类损失为0。可以看到,它比感知机的要求更进一步、更严格。