数据分析师的个人修养
数据分析师的个人修养
前言
- 先分享:分享给别人后,别人会有不一-样的理解、疑问、 质疑和新想法,会增强我们的认识程度。
- 再使用:每一节课的内容都只是我经历的一一个沉淀,每个人都要结合自己的实际情况去使用,而只有多和同事同学交流,你才能督促自己去对每个知识点进行更深入的理解。
- 在开源知识分享这件事上,1+1>>2
- 使用方法:截屏,花更多的时间去和同事探讨、并独立思考
- 最近遇到一件事的思考:工作中如果别人向你提一个需求 ,双方商定好完成时间后,你真的要按时去完成,如有特殊情况一定要提前解释好。 每- -次交互都是名片的传递,管理好生活点滴
文章目录
- 数据分析师的个人修养
- 前言
- 第一部分
-
- 1. 岗位情况
-
- 1.1 国企
-
- 1.1.1 工作模块
- 1.1.2 专题分析
- 1.1.3 软技能和面试技巧
- 1.2 BAT
-
- 1.2.1 日常主要工作
-
- 数据异常排查:
-
- 前期准备
- 方法论
- 1.2.2 专题分析
- 1.2.3 面试技巧
- 1.3 中小企业
-
- 1.3.1 三个问题解答
- 1.3.2 工作角色:斜杠青年
- 1.3.3 转型:为了让自己及家人更好的生活
-
- 转型分析
-
- 1. 规划好自己,再评估和准备
- 2. 评估自己
- 3. 优化自己
- 4. 寻找对象并实践
- 2. 数据分析工具
-
- 2.1 数据分析整体流程
- 2.2 EXCEL常用操作
-
- 2.2.1 对比分析
- 2.2.2 时间序列拆解分析
- 2.2.3 相关性分析
- 2.2.4 临界点分析
- 2.3 SQL常见问题
-
- 2.3.1 如何训练SQL
- 2.3.2 SQL常见问题
- 2.4 R语言、Python脚本案例
-
- 2.4.1 R语言机器学习
- 2.4.2 Python相比R的其他价值
- 总结
- 第二部分
-
- 3. 数据分析多元思维模型
-
- 3.1 背景
- 3.2 中观能力
- 3.3 微观能力
-
- 3.3.1 微观能力理解
-
- 3.3.1.1 有效沟通能力的两个技巧
- 3.3.1.2 快速发散收敛能力
- 3.3.1.3 微观能力的培养
- 3.4 宏观能力
- 3.5 总结:
- 案例部分
- 4. 电商数据分析——以京东APP为例
-
- 4.1 如何去看京东APP
-
- 4.1.1 用户视角
- 4.1.2 分析师视角
- 4.2 首页的分发效率
-
- 4.2.1 分发效率评估
- 4.2.2 分发效率总结
- 4.3 绕不过的漏斗分析
-
- 4.3.1 背景
- 4.3.2 了解每层漏斗的影响因素
- 4.3.3 漏斗模型总结:
- 4.4 新用户分析
-
- 4.4.1 背景
- 4.4.2 新用户优惠券策略思考
- 4.4.3 新用户分析建议
- 4.5 总结
- 5. 互联网金融toC授信模型——以芝麻信用为例
-
- 5.1 背景介绍
-
- 5.1.1 互联网金融行业数据分析师的角色
- 5.1.2 数据建模师到底干什么活
- 5.2 授信模型
-
- 5.2.1 芝麻信用分结构
- 5.2.2 数据源的数据变量为何那么多
- 5.2.3 数据处理
- 5.2.4 数据标准化
- 5.2.5 数据建模前思考
- 5.2.6 模型离线效果指标
- 5.2.7 模型运行周期
- 5.3 模型落地
-
- 5.3.1 落地前
-
- 5.3.2 落地中
- 5.3.3 落地后
- 5.4 总结
- 6.游戏数据分析——以欢乐斗地主为例
-
- 6.1 背景
- 6.2 指标口径
-
- 6.2.1 重要指标业务理解——常规指标
- 6.2.2 重要指标业务理解——商业化指标
- 6.3 用户流失分析
-
- 6.3.1 流失定义
- 6.3.2 欢乐斗地主流失分析
- 6.4 付费分析
-
- 6.4.1 背景
- 6.4.2 欢乐斗地主付费分布
- 6.4.3 付费分析
- 6.4.4 用户群针对性建议
- 6.5 总结
- 7. 传统销售行业数据分析案例讲解
-
- 7.1 背景
-
- 7.1.1 需求解读
- 7.2 提炼:如何去分析一个陌生行业
- 案例部分总结
-
- 宏观思维模块
- 微观模块部分
- 8. 指标体系的那些事儿
-
- 8.1 指标体系的定义和选取原则
-
- 8.1.1 背景
- 8.1.2 原因解释
- 8.1.3 定义和选取原则
- 8.2 指标体系的四步法
-
- 8.2.1 指标的构成
- 8.2.2 四步法
- 8.3 知乎APP指标体系实操
-
- 8.3.1 当前业务发展阶段
- 8.3.2 核心指标及拆解
- 8.3.3 会议、存档、建表
- 8.4 总结
- 第三部分
-
- 9. 流量分析
-
- 9.1 背景介绍
- 9.2 渠道分析
-
- 9.2 1 常见渠道及渠道分类
- 9.2.2 渠道的整个过程
- 9.2.3 渠道的关键指标
- 9.3 转化及价值分析
-
- 9.3.1 漏斗分析
- 9.3.2 功能模块价值分析
- 9.4 波动分析
-
- 9.4.1 日活
- 9.4.2 留存
- 9.5 总结
- 10. 路径分析
-
- 10.1 路径分析定义
-
- 10.1.1 背景
- 10.2 路径分析案例——以美团APP为例
-
- 10.2.1 日志
- 10.2.2 路径分析步骤
-
- 筛选
- 数据进一步关联及标准化——美食
- 数据进一步关联及标准化——附近
- 数据进一步关联及标准化——订单
- 10.3 路径分析思考
- 11. 竞品分析
-
- 11.1 为何要做竞品分析
-
- 11.1.1 背景
- 11.1.2 工作中竞品分析的场景
- 11.1.3 什么是竞品分析
- 11.2 竞品分析的步骤
-
- 11.2.1 分析的目的是什么
- 11.2.2 挑选1-2家竞品,进行对比分析
- 11.2.3 给出初步分析结论
- 11.3 案例介绍
- 12. 营销活动分析
-
- 12.1 当前现状
- 12.2 怎么分析
-
- 12.2.1 活动前准备
- 12.2.2 活动中
- 12.2.3 活动后
- 12.2.4 总结
- 12.3 案例分析——百度APP为例
-
- 12.3.1 指标体系搭建
- 12.3.2 活动后复盘——绝不是简单的数字罗列
- 12.4 总结
- 13. 用户增长分析
-
- 13.1 用户增长模型理解
-
- 13.1.1 用户增长基本模型
- 13.2 国内的用户增长现状
-
- 13.2.1 看似很唬的几个用户增长方法
- 13.2.2 实际很好的2个增长思维
- 13.3 增长案例解析
- 13.4 总结
- 第四部分
-
- 14. 找到本质问题和逻辑树拆解
- 15. SQL提数和分析
-
- 15.1 前期准备
- 15.2 集中时间和精力
- 15.3 踩坑
- 15.3 如何分析
-
- 15.3.1 结构分析
- 15.3.2 对比分析
- 15.3.3 时间序列拆解分析
- 15.3.4 相关性分析
- 15.3.5 临界点分析
- 15.4 总结
- 16. 报告撰写
-
- 16.1 报告撰写原则
- 16.2 报告组成部分
-
- 标准化组成部分
- 16.3 报告案例
- 16.4 总结
- 17. ABTest
-
- 17.1 AB测试介绍
-
- 17.1.1 概念
- 17.1.2 AB测试流程
- 17.1.3 常见的AB测试类型——UI界面型
- 17.1.4 常见的AB测试类型——算法策略型
- 17.1.5 实际工作中的问题
- 17.2 AB测试注意事项
- 17.3 AB测试案例
- 17.4 思考总结
- 第五部分 数据分析师个人修养提升
-
- 18. 行业分析
-
- 18.1 行业分析的两种背景
- 18.2 行业分析——问题的识别与拆解
- 19. 数据仓库
-
- 19.1 大数据体系:高度要够,熟悉整个行业,专注某个模块
- 19.2 数据研发工程师和数据分析师的关系
-
- 19.2.1 APP日志采集中的埋点
- 19.2.2 建模
- 19.2.3 主要步骤
- 19.2.4 数据管理
- 19.3 总结
- 20. 用户研究
-
- 20.1 什么是用户研究
- 20.2 什么时候做用户研究
- 20.3 用户研究的步骤和关键点
- 20.4 用户研究和分析师的关系
- 21. 时间管理
-
- 21.1 时间管理
- 21.2 关键点1——早起
- 21.3 关键点2——阶段性熬夜
- 21.4 关键点3——上下班时间
- 21.5 关键点4——会议时间
- 21.6 关键点5——周六日
- 后记
第一部分
1. 岗位情况
1.1 国企
对比JD,我分析我自己,分析公司目前处于的状态,以及日常需要做什么
1.1.1 工作模块
-
日报每天必须要看,通过日报了解业务现状,培养数据敏感性;
-
周报一般用于ppt,因为是短期趋势;
-
月报用于评估目标及战略决策;
-
管理层需要了解背景,提交数据需要一再核对;
-
业务人员需要在处理需求是要思考,怎么样闭环,一定要多沟通。
坚决不做提数机器
-
针对每一个业务单点问题,先追根溯源,简历该业务类的分析框架,由点到面,彻底解决该类问题;同时,在这个过程中,要不断的利用互惠原理和社交技巧,只给业务方做最核心的需求,其他的延申需求让业务自己动手去完成。
-
学会自动化发日报,不要自己做工具人;目标建立,即使在杂事中仍然能够保持清醒;必要时要寻求领导帮助,不轻易给自己挖坑填坑。
-
1.1.2 专题分析
-
需求解读
- 至少花20%的时间分配在沟通上,一定要当面沟通。原始需求->了解需求->本质需求
-
建立逻辑树
- 逻辑树的目的就是让思路更加简单清晰
-
SQL提数及分析
-
提数:SQL三段论,SELECT,FROM,W,ERE
-
分析:组成部分,数量比较,有何变化,各项分布,各项相关性,其他深层次挖掘
-
-
撰写报告
- 90%图10%文,图为主,图表标题说结论:

典型的图表标题说结论
- 结论前置:漏斗结构
- 讲故事:报告的逻辑性一定要强
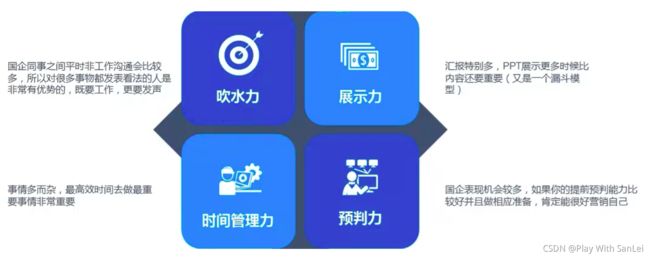
1.1.3 软技能和面试技巧
- 吹水力
- 展示力
- 时间管理力
- 预判力
面试
- 正装微笑
- 多看书
- 框架性
- 大心脏

1.2 BAT
同样还是分析岗位JD,透过现象看到本质,了解岗位真正需求
1.2.1 日常主要工作
数据异常排查:
数据异常是每个分析师最常见的工作之一,大部分人都缺乏方法论,排查起来没有方向感和层次感,这里看看,那里看看,非常耽误时间,可能最后也没结果。所以,我们要有一套标准化流程去做这件事 ,只有这样,才能成为这块的专家。
数据波动大的原因无非是数据有问题或者业务有问题。
前期准备
- 业务理解
- 指标口径
- 当前数据产出过程
方法论
-
判断是否异常
亲自去看数据准确性,不要人云亦云
时间轴拉长,看看近期异常还是历史异常
看和该指标关联的其他指标或者其他核心指标是否也异常
找到一个关键人物(产品/数据) , 提前沟通一下
-
最大概率法则归类
假期效应:开学季、暑期、四大节、当地节日
热点事件:常规热点如世界杯、突发热点某爆款IP
活动影响:双11,618 ,公司层面活动
政策影响:互联网金融监管、快递行业实名
底层系统故障:数据传输、存储、清洗有无问题
统计口径:业务逻辑更改、指标计算方式更改
-
闭环
持续跟踪后期数据是否再次异常
沉淀、文档化
邮件化:只有确认了没有问题再邮件,描述影响范围和主要结论即可
1.2.2 专题分析
-
有目标:紧贴项目KPI
目的:摸清数据现状,同时找到若干切入点
关键点:不要太注重细节,该过程讲究报告产出的时效性,让其他人员感受到分析师的存在
-
有节奏:2-3周时间输出一份完整报告
-
有闭环:所有的报告说人话,干人事
每一次分析报告都要有能够落地的点,并且真的落地了
1.2.3 面试技巧
最重要的是前三面:
-
一面:电话面
要特别熟悉自己的简历,说话要有条理性和逻辑性,大心脏能力
-
二面:boss1面
准备一些技术,带上一份优秀的专题报告
-
三面:boss2面
了解产品宏观知识,多使用产品APP,要考虑的非常全面。
必问的三个问题:
-
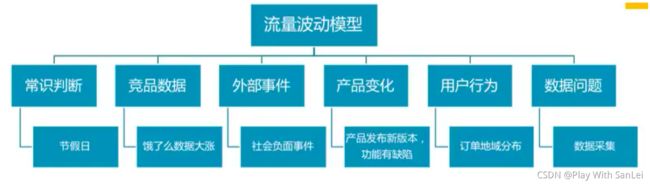
流量波动
-
三个常用APP
-
商业模式
-
1.3 中小企业
1.3.1 三个问题解答
-
流量波动:分析师的经验怎么样
千万不要单点分析,首先要对命题进行解析,有结构有逻辑地分析。快速定位问题,有架构地回答。
-
常用的三个APP:分析师的思考深度怎么样
建议说跟应聘岗位相关的APP,上升到高于普通用户的境界。
-
商业化变现:对商业的最终目的是否敏感
1.3.2 工作角色:斜杠青年
横向上:埋点、口径、指标体系、报表统计、数据清洗、平台研发、专题报告、数据培训
纵向上:对接产品、运营、市场、财务、销售
说白了就是SQL BOY背锅侠
1.3.3 转型:为了让自己及家人更好的生活
作为一名职业打工人,当前的工作要符合下两者之一才能证明挺好
- 当前薪酬不错,在行业中处于前列
- 当前岗位能学到很多有效知识,在你想的到的时间内能快速变现看得见、摸得着,能得到,才最真实
转型分析
1. 规划好自己,再评估和准备
数据分析师这个职位未来有三条线
- 业务线:适合对事物感到好奇并深入研究,思维发散并且能收敛的同学,喜欢展示自我,逻辑思维较强
- 研发线:适合写代码的同学,喜欢安静独处,计算机功底好,天生的程序员基因
- 算法线:适合做研究的同学,数学功底好,很多时候要看各种国外论文
2. 评估自己
这里以业务线为例,这条路线的考量标准有:
- 产品理解能力:各种数据熟悉度、用户从哪里来,进来后做了什么,用户反馈最多问题是什么,竞品数据怎么样
- 分析方法论:常见分析方法有哪些, ab测试,最大概率法则, 28定理,幸存者偏差理解怎么样
- 可视化能力: ppt功底怎么样,专题报告逻辑性、金字塔原理、审美怎么样
- 演讲能力:表达能力、讲故事能力、形象化能力、大心脏能力怎么样
- 协作能力:跟产品、业务、研发沟通时的软技能、如何在团队中定义好自己位置并让其他人很舒服
- 逻辑思维:分析推导过程的全面性、合理性、价值性
- 技术: excel的常见操作、sql能不能闭着眼睛写、r能不能搭建模型并知道有哪些坑、pyt,on是否能很好的用上
3. 优化自己
补短板,最重要的是深入而不是略懂,只有深入才能能自己的洞见
方法论:能快速从一个较全面、逻辑性、价值性的角度去分析,而不是单点无架构性分析,所有方法论都是通过不
断提炼、总结、实践得出来的。这个是评估一个分析师水平的重要标准
4. 寻找对象并实践
- 挑选3家一般公司——面试训练
- 挑选2家规模较大、知名度较高的公司——保底要进
- 挑选2家业内知名公司——尝试
- 设定一个跳槽时间段,比如3个月,期间最重要的事情是瞄准那两家保底要进的公司。注意:由于这两家是你职业生涯的一个转折点,所有简历要单独写,要花几天时间去不断打磨。
- 每一次面试后都有多总结, 找到自己的不足并多训练
- 最后就是面试环节后,最重要的还是表达、表达、表达。所以真正的面试时间是非常长的,前期的准备是要花几个月时间。只有经过这种训练,才能有优秀的企业要你
2. 数据分析工具
2.1 数据分析整体流程
背景:数据分析也是有一套标准化流程的 ,无论是新人还是老司机遇到一个问题时,都要从这一套流程出发去解决问题,而不是直接提数解决战斗

- 明确问题:先把问题定义清楚
- 搭建框架:再把问题考虑全面,找到一条主线
- 数据提取: mysql、Hive为主
- 数据处理:Excel、R、Python为主
- 数据分析:数据分析方法论为主
- 数据展现:Tableau、excel、 R、Python
- 撰写报告:文笔功底,整体逻辑性
- 报告演讲:沟通能力,表达能力,被提问能力
- 报告闭环:最难也是最大价值
工具说明
| 工具 | 应用场景 | 掌握程度 |
|---|---|---|
| MySQL、Hive | 基本上所有的数据获取方式 可以进一步学习一些Linux命令 |
超级熟练 数据提取不能出错 |
| Excel | 最高频、最有机会展示的数据处理工具 | 超级熟练 |
| R | 统计语言,就是为数据分析而生,简单易学,但是计算能力较差,可能稍微大点的数据导入就死机了 | 熟练 |
| Python | 脚本工具,可扩展性极强,算法研发同学必备,数据分析以pandas包为主,其他包含爬虫,文本挖掘 | 熟练 |
2.2 EXCEL常用操作
2.2.1 对比分析
对比分析:所有的数据只有对比才有意义,每年的双11都会与之前的双11进行消费额对比;实际工作中,最常见的对比对象就是大盘,比如新上线一个功能 ,怎么样评估这功能效果,除了看功能使用人数,更加要做的是这个功能的留存和大盘的留存对比。
2.2.2 时间序列拆解分析
时间序列二次拆解分析:一般看某指标时,都会把时序周期拉长,看数据趋势,而数据都是波动的,所以都会进行拆解分析,寻找具体波动项
2.2.3 相关性分析
相关性分析:在做某个子产品的时候,都会被问到你这个子产品对大盘的贡献度或者说影响度,这个时候就可以用相关性去说话
2.2.4 临界点分析
临界点分析:对于任何一款产品,高活跃用户与低活跃用户在产品使用上必然不同,那么就可能存在,某个指标,一旦用户在这个指标上的消费超过某个临界值时,后面用会变得非常粘性,这就是Magic number
2.3 SQL常见问题
不是会,而是要闭着眼睛都能写
2.3.1 如何训练SQL
常见现象: 一旦表关联较多,内部逻辑稍微复杂,就怀疑自己的代码准确性系
解决方案:
- 公司内有一个写sql高手,那么在前期每次怀疑时,一 定要把代码给对方review ,多请教,同时看他写代码的风格和逻辑,模仿。2个月之后再评估自己水平
- 公司内大家SQL水平都差不多,这个时候只能靠自己,可以这样做:
利用下班时间,把你怀疑的代码,按照你认为应该的几种逻辑,全部运行一遍 ,然后看哪个数据跟当前已知数据(一定要有一个已知数据作为参考,否则真不知道对与错)最为靠近,再去反推为何这样写看着更加合理。 - SQL是否熟练的标准:当别人让你快速跑一个数的时候,你的内心非常自信和高兴
2.3.2 SQL常见问题
-
**Max函数:**对某一个误认为是数值型但实际是字符串型字段取最大值,采用max函数,发现结果一直有错,如13<9, -60<-70
**解决方法:**select max(a+0)
-
**日期处理:**日期取年月份,时间戳取日期,日期格式转换等等需求,经常出现各种问
**解决方法:**先百度看用什么函数来转,在正式跑数据前,直接select函数(a)测试下
一种特殊的日期处理 是北京时间和Unix时间转换:
selectfomunixtime(time), select from_ _unixtime(cast(substr(time,1,10) as int))(毫秒计时)
-
**先聚合再计数:**如果要计算某个维度下的用户数,不要直接count(distinct imei) ,而应该是
Select city,count(1) as uv from ( select city,imei,count(1) from a group by city imei ) t1 group by city
-
**一列变多行:**ab测试中会对一个用户打很多标签,而这些标签都是存在一个字段中 ,所以要看标签维度指标,就要对该字段进行列变行拆解
Select *,b from t1 Lateral view explode(a) table as b
-
**取TOP:**要看某分类下的top10消费额子分类(金额一致就并列)
Select *,rank() over(partition by a order by b desc) as rank from table t1 (窗口函数)
-
避免数据倾斜:
小表在左大表在右,使用map join,同时对空值进行过滤
Select /*+mapjoin(a)*/ t1.city,t2.type,count(t1.imei) as uv
From
( select imei,city,count(1) as pv from a w,ere imei != " group by imei,city ) t1
Join
( select imei,type,count(1) as pv from a w,ere imei !=“group by imei,type ) t2
On t1 .imei=t2.imei
Group by t1.cty,t2.type
2.4 R语言、Python脚本案例
2.4.1 R语言机器学习
常见问题:对于一个产品的重要指标如留存,影响的因素非常多, 那么就需要找出这些影响因素的重要性,从而知道围绕哪些因素运营更好提升留存
SQL和excel明显都解决不了
换种方式理解上面这段话:哪些指标最能够区分用户留存还是未留存,越是阴显区分,越重要
转化为机器学习语言: 对于一个用户,他有一个y (留存/未留存),还有很多x(各种影响因素),需要找出x与y的关系,并给出x的重要度排序,可以用随机森林,逻辑回归,决策树来实现
2.4.2 Python相比R的其他价值
-
爬虫:实际价值很大,比如爬取一些竞品数据,用R就不太方便
举例:资讯类APP的很多文章就是通过爬取下发给大家
-
文本挖掘:对评论数据的研究,比如APP评论数据分析,从而知道如何去做评论运营闭环
举例:京东网易APP的评论运营,其他APP的热点评论置前
-
UDF函数:
,IVE自定义函数有时并不能满足需求,此时就需要自己定义函数来实现需求,这个时候就可以用Pyt,on写UDF
举例:计算基尼系数, ,IVE中直接调用UDF能够很快输出
-
算法研发同学:个性化推荐、底层运维、WEB开发
非常强大的第三方库,在基础库的基础上再开发,避免重复造轮子
总结
- 国企的数据分析:打磨好综合技能
- BAT的数据分析:方法论研究
- 中小企业数据分析:如何准备去转型
- 数据分析常见工具:常见的工具操作,关键还是要提升业务能力
第二部分
3. 数据分析多元思维模型
3.1 背景
整个行业中,大部分同学偏数据库和机器学习,造成一种错觉:
只要会点技术,再能做个PPT ,就可以做数据分析了,门槛太低,部分同学做了几年数据分析,觉得就到瓶颈了,同时很难去界定一个分析师是否优秀 ,觉得大家可能都差不多
真实情况是:
你做出的分析别人能很快的发现问题,你也认可,但就是不知道如何避免,针对某个问题,有些人总是能有很多想法,你也不知道怎么理解,有些人职业发展的很顺利,有些人始终在瓶颈
3.2 中观能力
- 真正的专业度,能够很好的发现其他分析师分析中的问题
- 需要长期总结和思考,但多数同学都没掌握
中观能力:专业度,包括技术理解,逻辑性,价值点三个点
中观能力是反映分析师基本功怎么样、套路熟不熟练、思考到不到位的一种标准
技术理解:对分析需要用到的技术是否理解到位,是停留在理论阶段还是实践阶段
一定要理解这个只是理论上的方法,只有理解到数据标准化的本质目的是去除量纲量级的差异性,才能用好这个方法
技术是为了让业务更加方便高效,而不是让人困惑
逻辑性:整体思考的逻辑性是否欠缺。
每一环节的推导必须要讲究严谨性
价值点:做出来的东西价值在哪,如果现在你是决策者,你敢不敢立马规划落地。
有没有价值不是分析师说了算,是业务方说了算,有些点很好但暂时无法落地,就先不要管他
中观能力的提升相对比较容易,基本上就是从他人那里获得有效反馈,然后多实践就行
3.3 微观能力
-
有效沟通力+快速发散收敛力,能够从业务的交流中发现问题,找到方向
-
很多同学都没有意识到这个点
在中观能力相同的情况下,有些分析师总是表现的比其他分析师更加优秀,比如:
-
针对某个问题,总是能产生很多想法,找到切入点——想象力
-
业务方如果遇到问题就会优先找他,而他总是能在最短的时间内给业务方一个较好的答复——解决问题能力
-
对于数据有更好的敏感度,能够第一个 发现数据问题并给出解法——敏感度
-
会议上,总是能提出自己的独到观点,让别人觉得他很聪明一一快速发现提问
-
总是能很好的知道业务在干啥,而他的视角又一直是高于业务,所有人都认可——高维视角
这些都是分析师微观能力的表现:始于经验,终于沉淀,注重点点滴滴,思维高度活跃,总是能找到一些线索
-
3.3.1 微观能力理解
微观能力:包括有效沟通能力和快速发散收敛能力
微观能力是反映分析师平时的微观体感怎么样,作为一名分析师,你必须要能够发现到很多业务方发现不到的点,然后从数据上给出策略建议
前提:先知道业务是怎么想的,怎么做的,然后从中发现问题或者切入点,解决问题,这样就能高于业务
有效沟通能力:与业务方核心人员沟通,从谈话中快速捕捉到很多有用信息(说者无心听者有意)
快速发散收敛能力:基于沟通中的有效信息,快速提炼总结找到最好的分析切入点
所谓的好奇心或者说想象力,实都不是凭空产生的,回归到数据分析本质,只有和相关业务方(不一定是直接接触业务方)多沟通,从他们那里获得有效信息,再自身提炼加工(多学习、思考) ,才是可落地的天马行空,这个也就是优秀分析师厉害的地方(快速捕捉,提炼,找到问题,解决问题)
3.3.1.1 有效沟通能力的两个技巧
-
技巧1:黄金思维圈法则
在了解业务的情况下,反问业务方为何要做这件事,基本上,业务方都会有一个很具体的回答,往往都能在这里找到切入点
多问为何要做这件事往往就能找到问题的本质,解法自然就多了
-
技巧2:做一些准备工作再沟通
与业务沟通中,如果没有提前准备一些业务知识和数据 ,整个过程就是业务在主导,你还怎么发现问题呢
实际工作中,分析师都不一定知道会议主题、或者知道主题没有思考就去参加会议,可想而知整个讨论,除了了解一些基础信息外,还能干什么,也就是说,你只是知道这些信息,却无法获得有效信息
会议是一个很好的公共场合,也是分析师证明自己独特视角的地方,所以沟通前做好一定准备 ,不仅没有浪费时间,还能让别人觉得你很厉害
3.3.1.2 快速发散收敛能力
**发散:**对于某一个全新业务问题,跟业务沟通之后,分析师想法很多
**收敛:**在众多想法中,快速找到当前做哪个比较实际、合理,并且知道如何做的深入
3.3.1.3 微观能力的培养
- 尽可能多的和业务核心人员,特别是业务Leader沟通,看他们是如何思考业务的
- 多看心理学、社交学、记忆力、科普类、经济学的书籍
- 刻意练习,慢慢养成习惯
3.4 宏观能力
- 洞见性的全局观,能够从社会事件、整个行业发展中找到业务的决策方向
- 极难,平台和天赋缺一不可
宏观能力:能够把当前业务与实际社会热点、行业风口联系起来,提前预判,获得更好的决策
宏观能力非常难,如果做好了基本就是顶级CEO了,大部分同学都没有机会接触到这一层面(需要你有一定的决策权)
宏观能力案例:

3.5 总结:
-
中观能力:套路,在大公司能够很好学到
-
微观能力:微观体感,注重套路的真实落地过程,需要大量的积累,从不同业务方捕捉,提炼,沉淀
-
宏观能力:需要关注行业内动态,新闻联播、财经类节目是重要的数据源
一个公司的CEO其实就是顶级数据分析师这个角色
案例部分
4. 电商数据分析——以京东APP为例
4.1 如何去看京东APP
4.1.1 用户视角

4.1.2 分析师视角
作为一名数据分析师,应该要能更深入,并且有层次性的去看这个APP的数据
有三个问题需要大家思考:
-
引流(场):首页作为最大的带量位,分发效率怎么评估
-
漏斗(货):北极星指标交易额只是一个数字,更加重要的是理解这个数字转化的过程
-
用户(人):作为一款非常成熟的APP ,老用户相对比较稳定,但新用户获取应该怎么优化
其中引流是对整个APP的分析,漏斗是对核心路径的分析,用户是对产品的当前痛点进行分析
4.2 首页的分发效率
4.2.1 分发效率评估
除了要关注日活、留存、渗透率这些常规指标外,更加重要的是找到一些能够反映产品问题的指标
-
CTR:点击UV/曝光UV ,反映用户点击欲望的指标,非常重要,只有点击才能产生交易,如果较小,首页问题较大
-
人均访问(点击)页面数:总访问页面数( PV ) /总访问UV ,只有多访问页面,才可能产生交易
而围绕这两个指标,按照维度拆解方法,可以发现更多问题
比如CTR突然低了,那么是所有坑位的CTR均低还是个别引起
4.2.2 分发效率总结
基于日活、留存、渗透、分发效率,基本上就能够对APP的整体数据有个大概了解
作为一名优秀的分析师,除了要把自负责的产品做好外,更加重要的是不要设定边界,主动去了解整体数据,在这个过程中,你需要找到负责的产品跟大盘的数据关系
-
该产品确实很好的带来了大盘的提升
-
该产品只是在抢大盘的流量
-
该产品部分抢大盘流量,部分提升, 那么提升度到底多少
找到:业务功能与产品核心指标的关联性,量化,量化,量化
4.3 绕不过的漏斗分析
4.3.1 背景
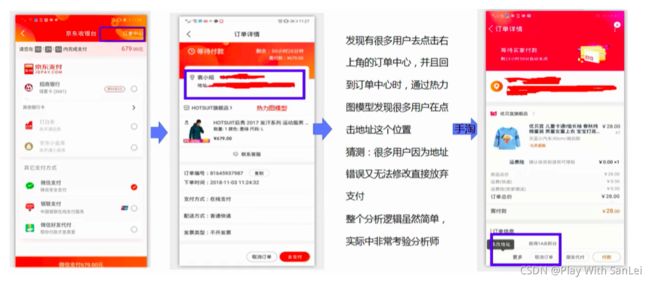
了解完整体数据后,肯定要看具体细分数据,虽然整个APP坑位很多,但一切都是围绕交易额这个目标,而电商交易额的本质是转化率,所以任何一个坑位都绕不开漏斗模型
在所有的坑位中,搜索是最大的一个流量入口,因此以搜索为例,作为一名分析师,一定要多体验产品 ,找到新认知,这也是微观能力
4.3.2 了解每层漏斗的影响因素
-
请教老同事
-
买电商书籍回来查看
-
多机型体验产品
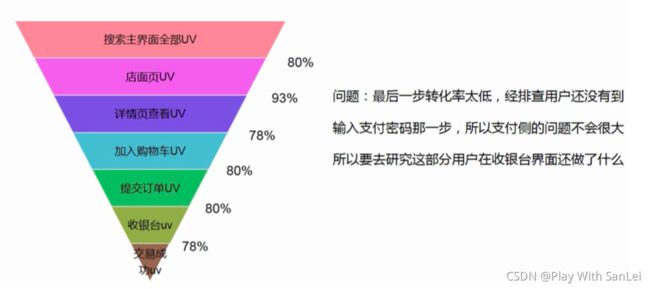
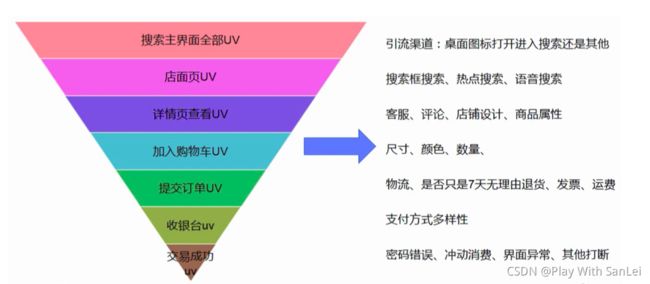
4.3.3 漏斗模型总结:
应该说电商的大部分数据分析都会跟漏斗有关,除了经验之外,更加重要的是对产品本身的多体验,以及对竞品的学习, 保持好奇心和敬畏心
也只有这样,才能慢慢关注到其他同学关注不到的点,而这些是培养良好微观体感的重要一步
4.4 新用户分析
4.4.1 背景
作为一款非常成熟,在一线城市有很多忠实用户的APP ,当前在用户体量上与手淘相差仍然较大,因此我们会看到京东与各方APP战略性合作,共同拉新。拉新必然就要衡量拉新效果和拉新优化,拉新效果内部数据不太清楚,但是作为一名分析师,可以去看整个APP在拉新上可以优化的点。实际上拉新如果做的好,比老用户分析更容易出成绩
新用户产品体验:

4.4.2 新用户优惠券策略思考
-
**逻辑性:**作为一名新用户,对于任何APP都是陌生的,第一感觉就是 先浏览,给用户发优惠券固然能提升用户的首日消费概率,用户的第一心智是先逛逛,结果你引导用户去注册,这在用户视角上有点不通,点击率必然不会很高
-
**优惠券分发:**首页曝光的是6元京东支付券和35元全品类券,而在188元大礼包里面实际上有8元运费券、40元电子文娱券、20元超市券。对于一名新用户,京东支付就很陌生。35元全品类券需要消费500元才能使用,要求有点高,是否可以做两点优化:
- 在首页优惠券曝光上,把6元京东支付券替换为每个用户都知道并且在意的8元运费券
- 京东本身的主流用户群体是电子,所以用40元电子文娱券去替换35元全品类券, 一方面是优惠更大,另一方面会让用户有一定惊喜感,当然更好的是在优惠券推荐的时候也加入个性化(肯定有数据)
-
**文案:**第二幅图片除了优惠券占用了中间坑位外,上下位置均没有有效内容,可以增加更多坑位曝光,植入识别度高的文字:可用换成立减(可用是描述性词汇,立减是动作性词汇)
4.4.3 新用户分析建议
新用户与老用户相比,由于对APP不熟悉,因此在漏斗环节,可能会有几个特征:
-
用户行为较为离散化,数据上可能有几个主要漏斗
-
在某个环节转化率远比老用户低
-
新用户当天以逛为主,不下单,过一定时间段后再下单
数据分析师能做的就是:把自己当作一个新用户去体验各种路径,并对异常漏斗进行维度拆解(比如,是不是某个渠道的新用户转化率低引起整体低)
4.5 总结
- 对于一款电商APP,分发效率是非常重要的一个产品指标
- 漏斗模型套路很重要
- 新用户的分析会更加有挑战性和有趣感
5. 互联网金融toC授信模型——以芝麻信用为例
5.1 背景介绍
5.1.1 互联网金融行业数据分析师的角色
互联网金融的本质是风控,数据分析师在这个行业基本上有两种角色:
-
风控分析师,除了一定的模型理解能力,还需要大量的行业和法律法规经验
-
数据建模师,要求对算法的理解较深,相对来说对行业经验要求不是很高
基本上数据挖掘分析师,数据建模师和产品经理都会去兼职这块,而在产品对象上分为toB和toC:
**toB:**定量打分卡+定性行业经验
**toC:**个人信用分
而无论是toB和toC,在决策上当前最依赖的都是央行征信报告
5.1.2 数据建模师到底干什么活
关键词:数据源、信用评分卡模型、模型上线监控维护、其他数据挖掘
5.2 授信模型
5.2.1 芝麻信用分结构
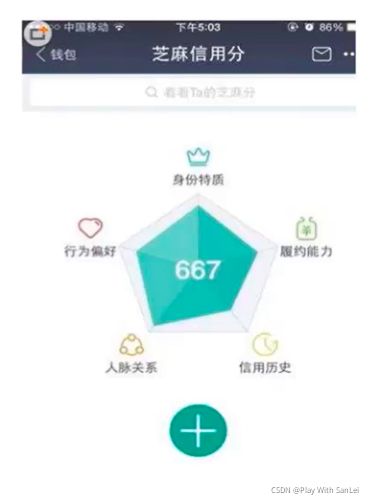
- **身份(WHO):**小学毕业还是博士毕业——稳定性
- **履约能力(WHAT):**有没有房车——兜底性
- **信用历史(WHEN):**信用卡有无逾期——历史性
- **人脉关系(WHO):**你的支付宝朋友是不是土豪——稳定性验证+弱价值性
- **行为偏好(WHAT):**喜欢买奢侈品还是地摊货——真正价值
5.2.2 数据源的数据变量为何那么多
-
数据变量分为原始变量和衍生变量
-
原始变量:直接存储在数据库里的最基础变量,如你的每天交易额
-
衍生变量:因为金融的本质是风险,所以都要对原始变量进行加工转化,一般是三种
时间维度衍生:最近1个月交易额、最近3个月交易额
函数衍生:最大交易额、最小交易额、交易额方差
比率衍生:最近1个月胶易额/最近3个胶易额
5.2.3 数据处理
实际上,所有的数据处理、数据建模都是为业务服务, 真实工作中,数据处理和数据建模都是慢慢迭代优化的,所以数据处理在前期不会搞的很复杂,一般就3种:
- 数值型和字符串型字段缺失性和合理性检验,剔除无效字段(50%以上即可去掉)
- 数值型字段的相关性验证:前期基本上所有的字段都会拿出来,肯定有非常多的变量相关性非常强,而这个对于模型训练是没有帮助的,因此会把相关性强的先过滤掉
- 字符串型字段的离散化处理
5.2.4 数据标准化
所有的变量都已经数值化了, 但是在量级和量刚上相差很大,如交易额和交易次数,这就没有可比性,所以要对所有的字段进行标准化,标准化的方法很多,选择合适的都行,这块对后面的模型效果没有影响。无论你是MAX-MIN还是Z-score
数据标准化之后(假设就是max-min) , 所有的变量取值区间都在[0,1]范围内了,这个时候就可以数据建模了
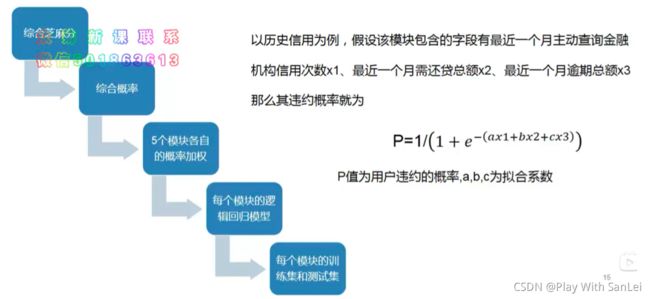
5.2.5 数据建模前思考
根据用户的数据,算出用户违约的概率,而这个概率也可以转化为用户的分数,所以逻辑回归模型就自然而然用上了

5.2.6 模型离线效果指标
离线模型中,混淆矩阵和ROC这两个指标就够了,因为真实工作中,最重要的还是坏账率这个评估指标。
5.2.7 模型运行周期
在产品初期,因为模型的变量太多,所以模型的迭代速度都非常快,基本上每个月都要跑一次分数,这个时候可能会出现某个用户的分数奇高,这些都是正常的,而这些都需要不断的调整权重和系数,慢慢优化才行,不过最重要的还是落地效果,就是用了这个模型之后坏账率怎么样,这就是模型落地了
5.3 模型落地
5.3.1 落地前
有了这样一套模型之后,你要出去找落地场景,我们看到芝麻信用围绕吃喝玩乐进行各种产品服务。
举例:
如根据芝麻信用分就可以申请招联金融信用额度,那么这就涉及到两个公司的产品合作了。金融行业的合作都是非常小心的,所以在正式合作前:
- 招联金融会提供一批样本给芝麻这边 ,芝麻这边数据建模师根据模型给出这批用户的违约概率
- 招联金融根据芝麻给出的用户违约概率,算模型的准确度
- 如果模型准确度还可以,双方才会正式展开合作(用户群覆盖度和模型准确度)
5.3.2 落地中
正式落地时,招联在给每个用户评估信用时,实际上芝麻信用分只是一个参考维度而已,一般都是这样:
-
机器调用该用户的央行征信报告评估值X ,这个是最重要的
-
接口调用用户的芝麻信用分Y
-
该用户在招联的信用评估情况Z
基于X,Y,Z ,内部再根据专家规则法出一套授信方案(很灵活),到这一步,基本上模型就正式使用了
5.3.3 落地后
前期一般是每一周 ,招联金融都会和芝麻这边对一次坏账情况,只有到这个时候,模型的参数调整才是最有意义的,这个时候也是最考验数据建模师的时候。调参方法:
-
先找出是因为某个子模型引起还是所有模型引起
-
如果是子模型引起,直接调整该模型的参数即可,如果是整体模型都有问题,那就要重新进行数据处理了,如WOE分组,更换衍生变量,字符型字段重新打分等等
在前期,数据建模师是最忙的一一个人,一旦模型稳定之后,数据建模师更多的时候就是兼职数据挖掘师
5.4 总结
-
授信模型:数据源、数据处理、数据标准化、数据建模、模型落地、模型优化,这一套跟数据分析标准化流程非常像,模型最终的评估指标就是坏账率
-
数据建模师:数据源在前期就已经决定了模型的效果,要具备良好的沟通能力和快速反馈能力,金融行业本身比较成熟,比模型更加重要的是分析师自身的想法和验证。在前期重点是围绕数据源和数据处理,模型无论是逻辑回归决策树GBDT随机森林神经网络问题都不会很大,与纯互联网行业对比,金融行业数据建模师的价值更容易得到体现,而且相对更有趣
6.游戏数据分析——以欢乐斗地主为例
6.1 背景
电商——非常互联网
互联网金融——直接就是跟钱打交道
游戏——互联网思维+钱都要具备
游戏行业用户两极分化比较严重:要么快速流失,要么就玩的时间很长
所以本案例重点围绕两个目标:
- 尽量让用户晚点流失——流失分析
- 让花时间的用户多变现——商业分析
坑位:
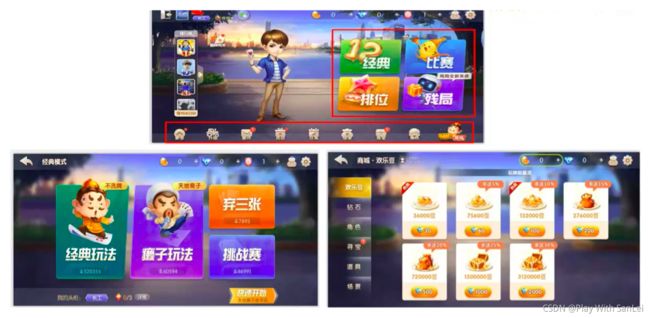
6.2 指标口径
6.2.1 重要指标业务理解——常规指标
-
DAU、WAU、MAU
一个产品的日活、周活、月活
以欢乐斗地主为例,日活是每天打开该APP的用户数
-
留存率
一般看次留、7留、30留存率
次留率:第一天打开欢乐斗地主并且第二天也打开欢乐斗地主的人数/第一天打开欢乐斗地主的人数
-
渗透率
某功能模块的使用人数该产品的日活
欢乐斗地主商城渗透率:进入商城的用户数/DAU
-
转化率
针对某个连贯路径,使用下一个节点的用户数/使用上一 个节点的用户数
打开APP——进入房间——参加比赛
6.2.2 重要指标业务理解——商业化指标
-
ARPU
一个时间段内的每用户平均收入
APPU=付费金额/活跃人数
欢乐斗地主付费金额200万,活跃人数100万,每个用户平均收入2元
-
CPM
千次曝光的成本
CPM= (广告投入总额/所投广告的展示数) *1000
某广告主在欢乐斗地主的闪屏界面投入一个广告10万,共1000万次展示, CPM=10
-
CPC
每个点击用户的成本
CPC=广告投入总额/所投广告
带来的点击用户数
某广告主在欢乐斗地主里面投了一个闪屏广告100万,产生点击50万, CPC=2
-
ROI
投资回报率
ROI=收入支出=ARPU*用户数/所有支出
双11在欢乐斗地主内部投放一个广告100万,最终带来收入200万, ROI=2
6.3 用户流失分析
6.3.1 流失定义
行业内一般对流失用户的定义都是:一个月内不使用产品即定义为流失
实际上,不同的产品形态用户行为差异非常大,像住宿类APP那就是低频高价值用户,欢乐斗地主7天不上线可能就已经流失,所以要合理的定义流失用户,对于流失用户,发现的越早越好
不能很好的定义流失就是因为用户有可能回流,比如拍脑袋30天,结果30天的时候,大量用户回流
所以实际上流失周期确定=回流率稳定,一但这个指标稳定 ,就定义这个时间段天数为用户流失周期
回流率=回流用户数/流失用户数=某个周期内的流失用户数在周期结束后又回来了/某个周期内的流失用户数
所以,只要按照枚举法,周期=1,2…30,然后分别计算回流率,一旦回流率趋于收敛 ,该周期就是流失周期
假设欢乐斗地主流失数据是这样:
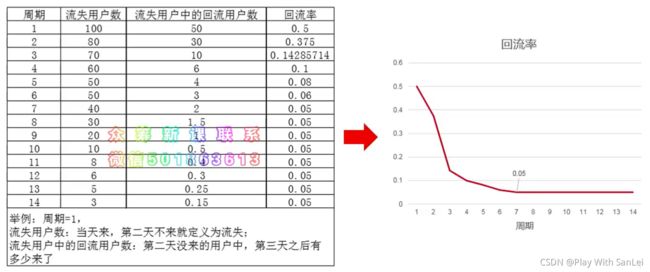
6.3.2 欢乐斗地主流失分析
对于游戏行业的用户流失分析,即有其他行业的类似套路但又有一-些差异化很大的点
- 类似套路:看流失前最后一步在干啥

- 差异化很大的点:作为一款非常复杂,需要花用户大量时间的APP ,分析师要想好好研究用户为何流失,也必须要去很深入的玩游戏,找到游戏中的快感和痛点,跟其他玩家多交流,否则就是脱离业务

6.4 付费分析
6.4.1 背景
游戏这个行业前期投入大,本身迭代快,所以对付费变现有非常高的要求
在付费分析上,整体思路是:
- 以付费金额分布和付费模块为切入点
- 根据第一点确定未来重点是在高、中、低哪个群体
- 进行AB测试,并每天看收入情况
6.4.2 欢乐斗地主付费分布
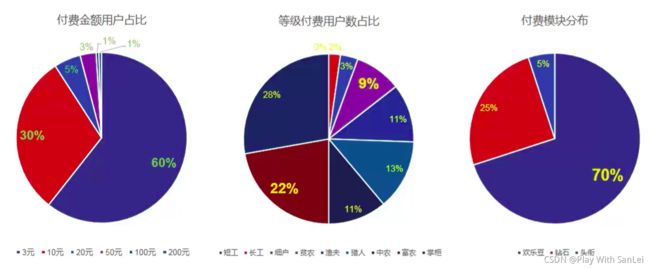
6.4.3 付费分析
很奇怪为何没有5元的付费金额?
无论是信息还是坑位都出现较大问题,只能说产品功能没有体验到位
- 当前用户付费金额以3, 10元为主,也就是超过10元就很敏感
- 贫农和富农是两个重要付费等级节点
- 以欢乐豆充值为主,进一步看钻石坑位点击发现点击的人比不高

6.4.4 用户群针对性建议
-
当前APP的用户群对钱很敏感,高端用户并不多,并且高端群体整体价值也不大一一直接结论
-
在剩下80%未付费用户中,必然存在一部分群体欢乐豆少于3000无法游戏 ,同时也去了商城查看,但未消费(假设比例是30%)——数据结论
-
玩游戏都是有兴奋点的,兴奋点是多久,用户在什么级别时最想充值?——体验结论
因此结合1,2 ,3,是否可以- 推出0.99元15000欢乐豆限名额抢卡片,同时在首界面就提示充值9.5折,进一步让用户觉得有便宜可占
- 对于日活少豆用户,可以多送几次欢乐豆,让他体验时长久一点,先兴奋起来
- 当用户在贫农和富农等级左右时,加强付费引导,满足其成就感
6.5 总结
游戏行业非常注重收入,分析师要每天看收入数据,所做的各种分析都要和收入挂钩。除了互联网那些分析方法,游戏行业更加注重分析师的深度体验,单纯的数据只能解决交互式的失误,而不能让游戏变得更好玩,所以分析师最大的价值是让用户玩的更爽,只有到这一步,才能实现真正的增长
7. 传统销售行业数据分析案例讲解
7.1 背景
针对一个陌生行业的数据分析需求,给如何去入手
(本节案例不好总结,因此完成度比较低)
7.1.1 需求解读
原始需求往往都是模糊的,但是:分析师不要带着不好的态度去推脱业务的需求,而应该跟业务良好沟通,有些业务方就是表达能力不太好
销售行业的核心指标是销售额完成率:按照正常业务理解进行维度拆解

7.2 提炼:如何去分析一个陌生行业

感到无从下手是因为:
- 没有找到切入点
- 没有具体生动案例
案例部分总结
宏观思维模块
- 数据分析师的多元思维模型——如何成为优秀分析师
- 电商模型——界面分发效率和交易额漏斗模型
- 互联网金融模型——信用分建模及落地
- 游戏数据分析——深入玩游戏和注重收入
- 传统销售行业——个体到全局
- 让自己静下来多思考,去感受数据在跳动
微观模块部分
8. 指标体系的那些事儿
8.1 指标体系的定义和选取原则
8.1.1 背景
对于某核心数据如日活,只知道数据在变化,但是不知道为何变化。产品为了解释这种现象一会儿要这个数,一会儿要那个数
年底汇报时,产品跟数据要各种各样的数据,或者数据内部花费大量时间对各种各样的口径
每隔一段时间,产品都会拉上数据研发一起对埋点,总是觉得当前的字段不够用,底层日志越来越大,数仓要修改的越来越多,取数越来越慢,错误越来越多
8.1.2 原因解释
根本原因在于缺少指标体系的建设、宣贯、实施
业务方不重视是因为这个活是个基建活,离KPI完成太远,只有出问题时才会临时重视,数据方没重视是因为这个活是一个吃力不讨好的活,可能认为就是一一个思维导图而已
然而真实答案是:要想把指标体系真正说明白不容易,而如果你都说不明白,你怎么判断你自己真的很懂呢,作为埋点、取数、分析的一切前提,这个活如果做不好,会始终发现很乱
8.1.3 定义和选取原则
- 定义:在业务的不同阶段,分析师牵头、业务方协助,制定的一套能从各维度去反映业务状况的一套待实施框架
- 指标选取原则:根本性、可理解性、结构性
- 根本性:核心数据一定要理解到位和准确
- 可理解性:所有指标要配上业务解释性,如日活的定义是什么,打开还是点击还是进程在
- 结构性:能够充分对业务进行解读,如新增用户只是一个大数,我们还需要知道每个渠道的新增用户,每个渠道的新增转化率、每个渠道的新增用户价值等
8.2 指标体系的四步法
8.2.1 指标的构成
- 原子性指标:最基础的不可拆分指标:交易额
- 修饰词,可选:某种场景
- 时间段
- 派生指标
8.2.2 四步法
-
厘清业务阶段和方向
业务前期:创业期
业务前期,最关注用户量,此时的指标体系应该紧密围绕用户量的提升来做各种维度拆解,如渠道
业务中期:上升期
业务中期,除了关注用户量的走势,更加重要的是优化当前的用户量结构,如看用户留存,如果留存偏低,必然跟产品模块有关系,是不是某功能流量承接效果太差。
业务后期:成熟发展期
成熟发展期,一定要看收入指标,各种商业化模式的收入,同时做好市场份额和竞品的监控
-
确定核心指标
最重要的是找到正确的核心指标,相信我,这个可不是一-件容易的事,不是因为这件事很很难,而是所有人都去重新接受一些客观事实很难
-
指标核心维度拆解
核心指标的波动必然是某种维度的波动引起,所以要监控核心指标,本质上还是要监控维度核心指标
通用的拆解方法都是先对核心指标进行公式计算,再按照业务路径来拆
当前的核心指标是停留时长大于3秒的用户数
停留时长大于3秒的用户数=打开进入APP的用户数*停留时长大于3秒的占比
-
指标宣贯、存档、落地
**宣贯:**很多人都忽略了这一步,没有指标的宣贯和存档,和业务核心人员沟通好之后就开始建报表,然后就完事了。实际上搭建好指标体系后,要当面触达到所有相关的业务接口人,最好是开会并邮件
**存档:**同时要对指标的口径和业务逻辑进行详细的描述存档,如XXX功能日渗透率=该功能的日点击人数/日活。只有到这一-层 ,后面的人才能一-眼看 懂是什么意思
**落地:**就是建核心指标的相关报表了,实际工作中,报表都是在埋点前建好的,这样的话一旦版本上线就能立刻看到数据,而且这个时候各方的配合度最高
数据分析师经常抱怨临时提数需求太多,就是因为指标体系没做好
8.3 知乎APP指标体系实操
8.3.1 当前业务发展阶段
知乎当前处于业务发展期和成熟期之间, 2个论点
-
当前知乎的业务正在一个快速调整期,内容向娱乐大众化转型
-
商业化进行较大的探索,但不是做的很重
也就是说,无论是最核心的内容还是商业模式,都在探索当中
工作中,这块只需要看每年的业务规划即可得到答案
8.3.2 核心指标及拆解

有些同学可能觉得评论点赞收藏数应该是核心指标,实际上是这样:
- 评论点赞多跟产品的健康度没有直接关系,评论点赞多的本质原因是因为提问回答比较精彩,这是一个相关性而不是因果性关系
- 很多做内容的同学,都觉得评论很重要,只要我评论做上去了,日活就能涨上去,数据相关性上是这样,但业务逻辑性不对
- 所以评论点赞收藏这些都是一个二级功能,更底层的理解实际上是增加app的社交属性
8.3.3 会议、存档、建表
**会议:**产品(负责使用)、研发(负责打点)
**存档:**对不太好理解的指标要进行单独的解释,比如什么是日活
**建表:**确定好打点之后,就要建表,确保数据第一时间出来,能及时发现问题

根本不需要一套大而全的指标体系,只需要围绕当前的核心指标,解决最重要的问题即可
8.4 总结
- 指标体系这件事本质上是业务人员和分析师的逻辑性怎么样,非常重要
- 不同业务阶段指标体系不一样,核心指标一定要正确
- 核心指标的拆解通用模式都是先公式拆解, 再按照业务模块、路径来分
- 指标体系的宣贯和存档工作必不可少
第三部分
9. 流量分析
9.1 背景介绍
有了指标体系和报表之后,最重要的事情就是每天看各种数据了,这也就是流量分析
流量分析的定义:这里流量是广义的流量,从哪来,经过什么,产生什么价值,如果他波动了,为何波动
- 渠道分析——从哪来
- 转化分析——经过什么
- 价值分析——产生什么价值
- 波动分析,包括日常的监控分析
9.2 渠道分析
9.2 1 常见渠道及渠道分类
对于一款健康的APP,前期靠渠道特别是外部渠道的品牌带量,后期靠自传播或者免费推广
一般都会单独有渠道运营经理,其实分析师在这块价值不会很大
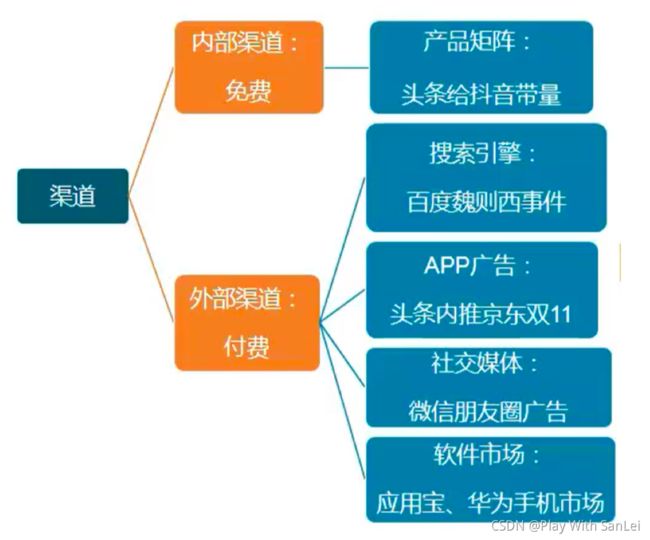
9.2.2 渠道的整个过程

9.2.3 渠道的关键指标
- 关键指标:前期看有效用户数和次留,中期看次日、7日、30日留存,后期看ROI
- 有效用户数:由于渠道都是收费的,所以会有刷量的嫌疑,所以除了看直接量级,还要看有主动行为的用户数,比如上节里面的停留大于3秒的用户数
- 渠道最终的目的还是商业变现,所以一定要计算每个渠道的ROI ,把ROl小于1的渠道砍掉
- 分析方法:结构分析+趋势分析+对比分析+作弊分析
- 结构分析:对渠道先按照一级渠道来拆解,再按照二级渠道来拆解
- 趋势分析:看每个渠道的变化趋势,包括量级和留存
- 对比分析:不同渠道闻的趋势对比课联系
- 作弊分析:用户行为分析+机器学习,这块可以用python来完成
9.3 转化及价值分析
9.3.1 漏斗分析
见4.3
9.3.2 功能模块价值分析
常规分析包括:
-
功能渗透率=功能用户数/大盘用户数:使用某功能的占比
-
功能功能留存率:第一天使用该功能同时第二天也使用该功能的用户数/第一天使用该功能的用户数
-
功能大盘留存率:第一天使用该功能同时第二天是大盘用户的用户数/第一天使用该功能用户数
另外一个必须关注数据:
大盘用户=所有功能用户排重+不使用任何功能用户:这部分群体也要监控起来
只有这样才是完整的大盘
价值分析包括:
-
功能核心用户数:符合某种要求的功能用户数,一般用使用次数、使用时长、使用天数、具备某种行为来定义"核心”一单纯用户数可能会出现一 个悖论:所有功能在涨,但大盘在跌
-
功能对大盘贡献度,比如对大盘留存提升的贡献
功能A对大盘留存的提升贡献=功能A渗透率*功能A的大盘留存率提升数
严格来说,只有AB测试才能说明功能对大盘贡献度,但实际中就这种计算可以对不同功能进行横向对比
-
功能带来的收入对比:每个功能每个月赚多少钱
总结:
- 产品的每一次决策都要基于逻辑性很强的数据证明,“我觉得” 这种词没有任何说服力,
- 很容易被挑战一先有数据再有结论 ,不要先入为主
- 每个产品经理都有自己内部的指标,但必须要去衡量你当前做的事情对大盘KPI的贡献度,只有大盘好才是真的好
- 敢于说真话,实事求是一没做好就是没做好 ,关键是你接下来怎么做,当前有没有找到真正问题
9.4 波动分析
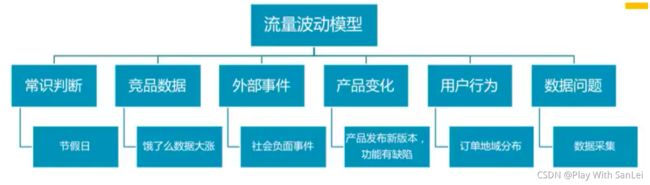
常见的流量波动分析就是两个:日活和留存,所以就围绕这两个来展开
9.4.1 日活
- 日活波动=外部影响&内部影响
- 外部影响:=行业变化&竞品变化=常识+外部事件+竞品策略
- 内部影响:=数据统计+用户基础属性+用户行为属性
- 数据统计:数有没有搞错——数据采集和统计口径
- 用户基础属性:用户从哪里来,通过什么方式进入——渠道 (新增用户变化)、入口、画像
- 用户行为属性:用户进来干了什么——具体功能的变化 ,跟版本可能有关
9.4.2 留存
-
留存波动=新用户留存&老用户留存
-
新用户留存=渠道+渠道过程有关
-
老用户留存=所有功能用户去重留存+大盘非功能用户留存=功能A留存&功能B留存&功能C留存+大盘非功能用户留存
-
实际中,会出现以下几种情况(假设留存下跌):
-
A,B,C中有1个留存下跌——最好解释
-
A,B,C中有两个以上留存下跌——看谁是主要 下跌因子,找到他,如果下跌幅度都差不多:
- 进一步观察,如果还是持续阴跌,必然是产品某核心部分出问题,围绕指标体系做一 次产品全盘分析,找到他
- 跌了几天之后回去了,可能跟外部影响因素有关,暂时不管
在留存这件事上,由于是比例,排查起来会比较费神,保持耐心,跟业务多聊,一定能够找到主要影响因子
9.5 总结
- 渠道分析——渠道的整个过程和分析方法
- 功能模块价值分析——漏斗分析、功能常规指标和价值指标分析
- 流量波动逻辑性分析——一定要有逻辑性,在过程非常严密的基础上得到正确的结果
- 流量分析最考验耐心和逻辑性严谨性
10. 路径分析
10.1 路径分析定义
10.1.1 背景
漏斗模型是非常经典的一种分析方法,但所有的漏斗都是人为假设的,也就是事前假设一条关键路径,事后看数据。
随着各类APP的功能模块,坑位越来越多,用户的行为越来越分散化,这个时候就要在用户的所有操作行为中, 发现一些产品设计初可能不知道、但非常有意思的用户前后行为,这就是路径分析
- 漏斗分析:人为设定一条或者若 干条漏斗:先有假设再数据验证
- 路径分析:基于用户的所有行为,去挖掘出若干条重要的用户路径,通过优化界面交互让产品用起来更加流畅和符合用户习惯,产生更多价值:先有数据再验证假设
10.2 路径分析案例——以美团APP为例
10.2.1 日志
日志:用户在APP内所有的行为都是以表或者文件存储的,记录了用户最详细的行为信息
路径分析是基于时间序列的用户前后行为关联分析,所以都是基于底层日志来做

10.2.2 路径分析步骤
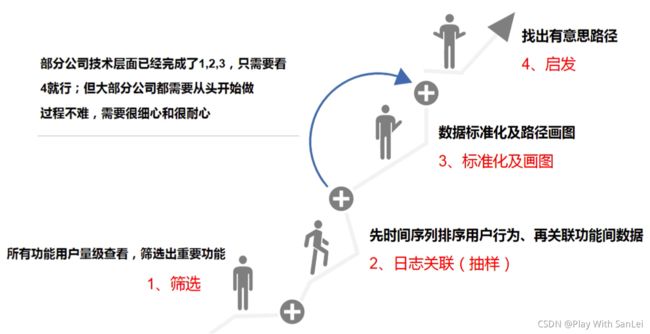
筛选

-
美食、外卖、搜索三大功能:需要进一步看之后用户路径,这里就以美食为例
-
附近作为底部第二_button ,存在什么问题,可以如何进一步优化
-
发现作为底部第三button ,用户感知度太弱,如何定位该功能价值
-
订单功能作为底部第四button,表现很好,用户进来后干什么,能进一步如何优化
-
我的作为底部第五button ,比较好奇用户进去后干啥
先找到切入点
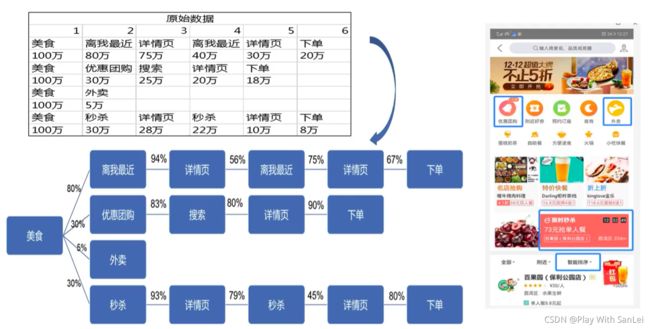
数据进一步关联及标准化——美食
数据进一步关联及标准化——附近

数据进一步关联及标准化——订单
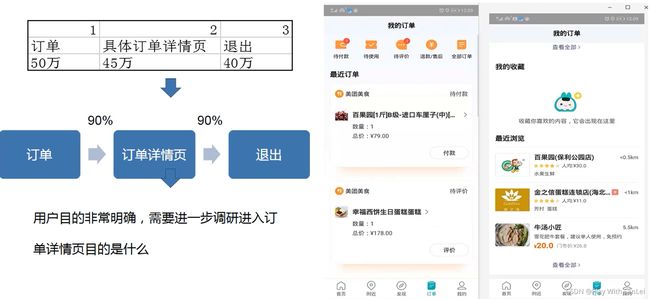
-
美食功能中,80%会切换智能排序到最近排序,其实如果把智能改为综合字眼可能会更好
-
同时用户进入详情页后会回退到上一层界面再进入详情页,这里建议在详情页内部增加相关
-
推荐,让用户逛,当前虽然有但体验很不佳;同样适用于秒杀——缩短用户下单路径
-
美食功能中,30%用户会进入优惠团购(喜欢便宜用户) ,竟然83%使用搜索功能,说明当前界面的主动推荐不太准确,需要优化一揣摩用户意图
-
附近功能中, 40%用户会回到首页, 60%用户用搜索,而享美食、惠生活、爱玩乐的渗透率
-
差异不大,享美食作为最大曝光界面占比,当前问题较大一基础功能要做好
-
订单功能中,90%用户查看订单后直接退出,在这里可以增加更多相关订单内容曝光,当前曝光内容是最近浏览曝光,效果不好一增加用户消费场景
路径分析是一件非常消耗体力的活,当前市场的大多APP恨不得把所有功能都塞进去,这就需要分析师对业务非常熟悉,分析师每天都要去体验自己的产品
每个产品经理都是负责自己的一小块功能,而分析师就是最大的产品经理,站在全局的角度去看产品,提出某个落地项,既能优化当前功能,又能对其他功能没影响,同时还能提升大盘数据,这非常考验综合思考力
10.3 路径分析思考
- 当前的路径分析是以功能点的时序整体分析为主,只有指标没有维度,而要想精细化运营,必须要进行维度拆分,如通过不同入口进来的用户,他们的路径分析差异在哪
- 对于有些APP,比如携程旅行,用户可能在今天打开APP后逛一会儿,过一周后再进来逛并下单,对于这种用户天不连续性路径,如何进行分析,其实这是一个行业难题
- PC端的路径分析和APP端的路径分析最大差异在哪,PC端有没有案例分享
11. 竞品分析
11.1 为何要做竞品分析
11.1.1 背景
前面介绍的分析方法都是针对自身APP的,假设:
-
你当前行业老大,这个时候肯定会防止外来者和警惕老二老三
-
你当前行业老二,肯定要看老大最近在做什么,模仿超越
-
你当前是行业老三以后,一方面肯定要紧跟老大老二,另一方面要放大招
所以很自然的就要去分析竞品
11.1.2 工作中竞品分析的场景
-
准备进入某个行业时,需要先把该行业的竞品分析清楚——侧重行业规模和前景
-
产品的发展处于下降阶段,需要看下竞争对手在做什么——侧重 头部玩家的玩法分析
-
产品的发展处于瓶颈阶段,需要看下竞争对手的数据和功能迭代——持续监控对手数据 ,寻找突破
-
产品的发展处于快速上升期,一般不会做竞品分析
实际上,对于一款APP ,要在初期就监控好竞品的各项数据,分析师要每天都看竞品数据,只有这样才能保持对竞品数据的敏感性,同时跟自身APP数据结合起来思考
11.1.3 什么是竞品分析
竞品分析绝不是大而全的把竞品的功能罗列一遍,这个是最初级的产品体验分析
同时也不是日常的竞品数据监控,配置一张报表就完成
竞品分析包含两个点:
- 竞品的选择:哪些才是竞品,不要小看这件事,很多产品经理都没想清楚
- 分析什么点,这就需要知道分析的背景是什么,从而有针对性切入
第二点最关键,到底你的leader想干什么,如果这件事他自己也说不清楚,那最好先别投入大量时间去做,不是你做的对和不对,而是问题都没搞清楚,即使他是leader
11.2 竞品分析的步骤
11.2.1 分析的目的是什么
- 如果只是单纯看一看数据,那就直接丢数据
- 一定是带有某种商业意图来做,不能忘记初心
尝试进入某个新的行业,需要评估可行性——唯品会做唯品金融
这种分析更加偏行业趋势、市场规模,财务收入,看大数不拘于小节。在第五章节行业分析会提到
纯粹看竞品的功能、玩法和数据,学习优点,人无我有,人有我优——学习为主
以功能体验、运营手法、具体数据为主,最常见,落地性非常强,后面举例也是这块
通过看竞品的不同版本迭代的功能、玩法和数据,揣摩竞品想干啥——预防为主
看竞品的版本迭代,思考竞品最近的战略中心在哪,往往是为了满足管理层的需要
11.2.2 挑选1-2家竞品,进行对比分析
- 如何挑选竞品
- 竞品数据
- 寻找某个切入点:竞品产品功能体验和运营玩法体验
挑选1-2家真正竞品:核心功能一-样
功能体验分析:不需要大而全
运营手法分析:某个功能的运营手法
宏观微观数据分析:数据源很关键(基础数据、财务数据、市场数据)
分析师牵头、产品运营协助的一项团队任务,可能还需要财务、市场部的参与才能完成
实际上,有时候也要对双方的技术实现做一些对比分析,这个就很底层了
11.2.3 给出初步分析结论
- 竞品分析一定要有初步结论
- 在这件事上,管理层往往看的更高更远
尝试进入某个新的行业,需要评估可行性——是否可以进入,如何开始做, SWOT分析
纯粹看竞品的功能、玩法和数据,学习优点,人无我有,人有我优——竞品什么功能好,接下
来产品运营会如何去做,预计带来收益多少,产品运营参与很重
通过看竞品的不同版本迭代的功能、玩法和数据,揣摩竞品想干啥——竞品下一步战略是什么,我们要不要也做某种尝试,这种是最难的
11.3 案例介绍
竞品分析
12. 营销活动分析
12.1 当前现状
营销活动每年花这么多钱,因此必须要找一个公正的第三方一 数据分析师,来做这件事,而数据分析师既然要做,就一定要发挥出自己的专业性,都是罗列数字,为何你就是不一样,你的强大逻辑性在哪
营销活动的运营人员:活动带来XXX用户量增长,拉来XXX新增,外界传播量XXX
数据分析师:活动期间每天进行效果播报+活动后1~2周内报告产出
-
活动参与人数
-
拉新数
-
用户画像
与营销活动运营人员对比,分析师的优势在于快和维度拆解性,劣势在于细节性
营销活动人员因为存在感不强,自己做的也比较辛苦
营销活动应该是一件长期的事务,不可能通过某一次活动就能够带来大量的用户增长,因此分析师在做这件事时,要保持:
-
分析的连贯性:活动前、活动中、活动后
-
分析的对比性:活动与活动间对比,什么样的活动比较适合产品本身
-
分析的公正性:该怎么样就怎么样,拉新促活品牌的评判都应该有一套商定好的标准
营销活动分析无非就两件事:活动效果评估(本活动和活动对比)和活动优化建议
12.2 怎么分析
在做任何活动之前,活动运营方必然要出文案,找开发,商合作,所有的这一切都会发生的很早,因此分析师要想真的做好这一块分析,在这个时候就要多与活动运营方沟通,知道大概是怎么回事
- 谁开发,靠不靠谱
- 活动形式及测试体验,文案可能存在问题
- 大概哪些指标,提前想一想
12.2.1 活动前准备
- 和运营方商定本次活动的目标——一定要有目标,现在很多活动做就做了,没有目标的运营不是一个好运营,你绝对不会使出100%的力气;这里能很好的培养业务的敏感性
- 和研发沟通好埋点——不是每个研发都很靠谱,即使很靠谱也可能犯错误,埋点这件事上就应该是分析师来主导,包括字段名、埋点位置、 上报方式
- 搭建好指标体系和报表——提前做好,活动前1天才发现问题的情况太常见
- 定好输出格式——活动中、活动后每天输出哪些数据,什么形式
12.2.2 活动中
- 观察第1天数据——详细看指标体系的报表数据 ,看是否有哪里异常,前期修改成本非常小,其实研发心里也虚
- 观察1~3天数据——预估活动目标的完成度,看是否要做适当调整
- 定时输出活动战报——每天早 上输出,让所有人都知道情况。真实情况是只有运营人员自己知道数据
- 活动1周后数据——进行一次详细复 盘,并同步给管理层,让更高视野的人来给建议
12.2.3 活动后
-
活动对大盘的影响——这件事实际 上很难做,但也是有解决方法的
-
活动的短期效果——目标完成度,参与人数、拉新、品牌传播指数
-
活动的长期效果——通过活动带来的长期用户数,而不是低价值用户数
-
活动存在的问题——包括产品设计和用户反馈
尽量在活动后1~2周内输出,其实在活动快结束时就可以做这件事,真实工作中,在这件事上真的讲究输出报告的时效性
12.2.4 总结
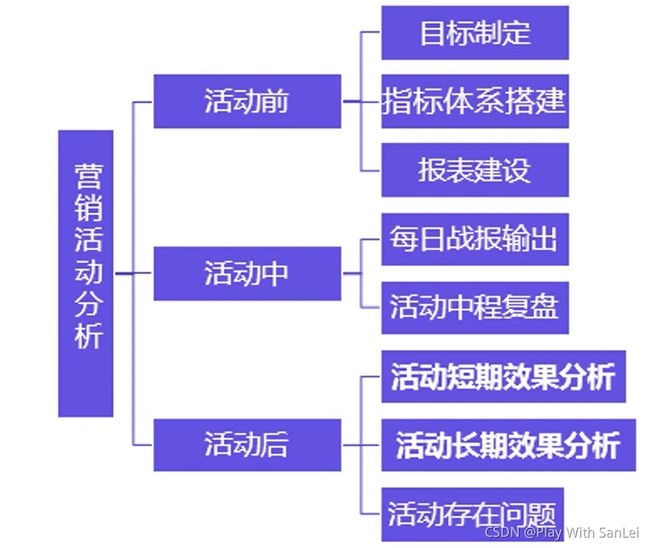
第一次分析师帮助运营人员全部做好并形成模板,后续就让运营自己去弄,活动是个非常个性化的活,分析师不应该投入太多时间在这里面
12.3 案例分析——百度APP为例
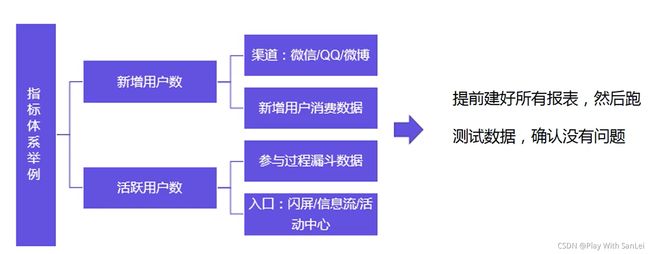
12.3.1 指标体系搭建
找到关键指标,按照用户基础属性和行为属性进行拆解:关键指标是带来新增用户和活动参与用户
12.3.2 活动后复盘——绝不是简单的数字罗列

12.4 总结
-
如果活动涉及到收入和品牌传播(百度指数微博指数), 也要加上去
-
对大盘DAU的贡献衡量:同比环比,同一拨用户前后对比其实都不太好说明问题
-
新增、首次、低活带动这三个指标比较好
-
更加重要的是这部分用户的后续留存
-
活动与活动间的数据对比更加能说明问题
-
一定要思考每次活动的本质和意义,比如某个活动本身就不针对拉新,然后新用户参与了,你能说是你带来的吗?肯定不能
-
如果是公司S级的活动,分析师是要看实时数据的,无论是资源还是精力, 都要重点投入
-
一定要敢于暴露问题,在这件事上是这样,分析师把已知的事实告知自己的上级,并邮件同步出来给活动运营的负责人
-
凡是涉及到活动使用金额等时,分析师最好不要自己出数,让业务方给,一定要自己做的话,记得邮件同步说明情况
13. 用户增长分析
13.1 用户增长模型理解
13.1.1 用户增长基本模型
如果是这样会好很多:

- 先把产品打磨好,运营服务好,挣钱再投入到渠道去拉新,这样会更加靠谱,人傻钱多的时代已经过去
- 如果一款产品在中期还要靠不断注水才能保持规模,这样的产品是有极大问题的,这样的团队也是非常不靠谱的,只有早点转型做好留存才有希望
未来可能会这样:

- 在资本越来越理性下,从流量思维切换到ROI思维,活下去是最重要的指标
- 侧重点不同,企业的打法完全不一样
- 大家想想,这套模型还可以怎么样?
最好是这样:
- 不要去纠结什么模型和玩概念
- 不要指望通过数据分析突然找到一个牛B增长点,带来大量用户增长
- 如果有大腿可以抱, 一定要坚决抱大腿
- 研究自己的产品、用户,找到当前产品真正存在的问题,慢慢去解决他,建立自己的产品壁垒
- 学习优秀产品的玩法,思考他们能成功的本质,比如QQ浏览器和腾讯视频为何能后来居上
其实:分析师的任务就是做规模和带收入,一直没变, 一定要独立思考,不要被各种风带偏
13.2 国内的用户增长现状
13.2.1 看似很唬的几个用户增长方法
- 魔法数字:一个用户阅读篇数超过3篇,留存将大大提升
- 本身是用户的一种很主动的行为
- 单独上阅读篇数小于3篇的人多阅读,本身就非常难
- 优化渠道结构提升新增用户留存
- 用户量大、质量高的渠道总是有限的,渠道人员开始的时候就想着这件事
- 渠道链路非常长,很多因素控制不了,反馈周期很久
- 流失用户召回
- 召回的手段除了push,还能干啥
- 与其精力放在召回,不如放在流失原因分析上
13.2.2 实际很好的2个增长思维
-
北极星指标:一定要找到最核心的指标
对北极星指标进行不断拆解,拆解后的指标跟每个团队的kpi挂钩起来;如果每个人都能够知道做的每件事是正向还是负向,那就很舒服了
MAU=新增+老=本月新增+上月新增留存+上月老留存+上月老回流
-
Ab测试:公正性和快速反馈性
- 要基于数据分析来做ab测试,很多算法工程师都天天ab,很枯燥
- ab测试不只是看个结果数据这么简单,还要看过程数据,排坑是第一步
13.3 增长案例解析
摩拜滴滴
13.4 总结
- 不要玩概念,要独立思考和辩证性思维
- 与其关注别人,不如多研究用户数据
- 学习他人的优点,套用到自己身上来
- 分析师要多看产品、运营的书,所有的分析增长都要靠产品运营闭环
- 只有成体系才是可传播的,可继承的
第四部分
14. 找到本质问题和逻辑树拆解
偏技巧性,请移步此处
15. SQL提数和分析
15.1 前期准备
一般来说 ,在正式写SQL之前,要花1天时间去做以下几件事:
-
哪张表、哪份日志
-
筛选条件
-
之前有什么坑
-
现在是否有坑:select* ,先跑一个核心数据看下
对数据有一点感觉的基础上,再把问题的拆解模块构思一次,哪些点不好做,有个预期
前期准备非常重要,很多同学在提数这块花了大量时间,就是因为前期工作做的不到位,太相信我们的埋点了
因为提数的最终目的就是为了分析,所以这两步是一起的,看似很简单,但是往往比较花时间:
- 各类其他事情打扰
- 遇到坑
- 突然找到一个新的点,然后一直往下挖
- 不会提数和分析,不知道如何看数据
15.2 集中时间和精力
首先要有这种意识:当前最重要的事情是SQL提数和分析
- 早上时间一定要利用好,早点到公司
- 提前了解好会议主题,确定是否参加
- 中间所有进来的插队需求,先靠边站
- 晚上回家时间、周末时间
- 专注:专注的人是能看出来的
15.3 踩坑
在"坑”这件事上,踩坑是必然的,不过我们可以通过这件事来观人阅事:某个团队中,谁比较靠谱,谁比较好说话,谁尽量不要接触
遇到坑之后,一定要文档详细记下来,这样做的好处有二
- 让团队中其他人知道,节省团队时间
- 每月总结的时候,知道自己在哪块花了大量时间,为后续做分析节省时间
- 专注:专注的人是能看出来的
15.3 如何分析
15.3.1 结构分析
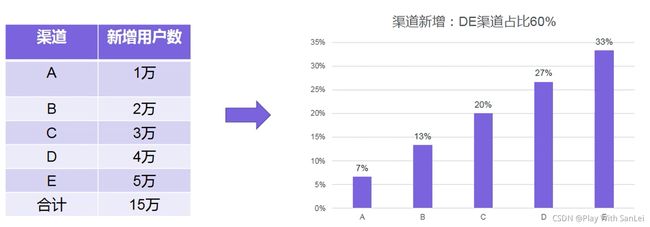
15.3.2 对比分析
对比分析:所有的数据只有对比才有意义,每年的双11都会与之前的双11进行消费额对比;实际工作中,最常见的对比对象就是大盘,比如新上线一个功能 ,怎么样评估这功能效果,除了看功能使用人数,更加要做的是这个功能的留存和大盘的留存对比。
15.3.3 时间序列拆解分析
时间序列二次拆解分析:一般看某指标时,都会把时序周期拉长,看数据趋势,而数据都是波动的,所以都会进行拆解分析,寻找具体波动项
15.3.4 相关性分析
相关性分析:在做某个子产品的时候,都会被问到你这个子产品对大盘的贡献度或者说影响度,这个时候就可以用相关性去说话
15.3.5 临界点分析
临界点分析:对于任何一款产品,高活跃用户与低活跃用户在产品使用上必然不同,那么就可能存在,某个指标,一旦用户在这个指标上的消费超过某个临界值时,后面用会变得非常粘性,这就是Magic number
15.4 总结
实际上所有的分析都是基于用户的基础属性和行为属性。如果你还是不会,那就从5W1H出发, 每次分析的时候都以这个为模板来展开
- Who:用户基础属性
- Where:渠道分析
- When:时间上特征
- What:使用了什么,哪些行为更加重要
- Why:为什么要这么做,主动还是被动
- How:怎么做的,行为路径是什么
16. 报告撰写
16.1 报告撰写原则
-
主题一脉相承分叉:只有一个主题,每页PPT都是围绕这个主题来分叉展开
常见的两种问题:
- 没有主题,是因为对需求本身就没理解到位
- 有主题,但是写的逻辑有点乱,是因为本身思维就不够严谨,受到的指导太少
解决办法:看别人报告怎么写的,一页一页去斟酌
-
通俗简单易懂:数据分析师的报告一定是简单的 ,大白话的
数据分析师是服务于业务的,所以即使你不讲PPT,业务方也是能看懂得,否则就是给自己挖坑:
- 一个数据,如果跟你最熟的业务方也理解不了,其他人绝对是天书
- 解决办法:看产品经理日常是怎么写报告的
-
结论和闭环先行:没有明确结论和落地项的报告就是数据堆积
PPT一定要有数据结论,以及在这个结论的基础上,业务方准备怎么做
是真的准备怎么做,而不是你给的建议怎么做
- 解决办法:跟业务方多沟通数据结论,让他们给出落地项
16.2 报告组成部分
标准化组成部分
-
背景:为何做这份专题报告,即问题的识别
-
分析结论:如果是面向管理层的汇报,结论可以先行
-
分析框架:即问题的拆解,往往这里不需要很细
-
第一个关键点结论
-
第一个关键点的支撑数据依次摆放
-
第二个关键点结论
-
第二个关键点的支撑数据依次摆放
(上面4步是提数和分析)
-
整体结论:这里把结论再汇总
-
落地项:产品是怎么落地的,要非常具体。时间、人、预期效果
所有的数据结论和落地项中,只要最后有1~2个真的应用了,这份专题报告就非常有含金量
16.3 报告案例
案例精选
16.4 总结
- 多看优秀的专题报告,重点是把自己代入到场景中,我会怎么去写
- 每写一次专题分析,一定要获得他人的反馈,只有这样才能进步
17. ABTest
17.1 AB测试介绍
17.1.1 概念
AB Test
关键词:组成成分相同的访客;同一时间;用户体验数据和业务数据
- 用户群要一样
- 一定要是同意时间按段对比,否则没意义
- AB测试指标体系
17.1.2 AB测试流程
- 根据数据分析得到某建议项
- 根据建议项,产品经理得到某落地项
- 根据某落地项,研发设计人员进行开发设计(往往是先设计,再丢到AB测试平台里面去跑数据)
- 研发人员数据采集:自动采集数据
- 分析师跟进AB效果:显著性在95%以上并维持一段时间 ,实验可结束
- 整体节奏:灰度、5%、 10%、 20%、50%、100%
- 业界都是一套AB测试平台(自研或者购买) , 能够每天进行大量的AB
17.1.3 常见的AB测试类型——UI界面型
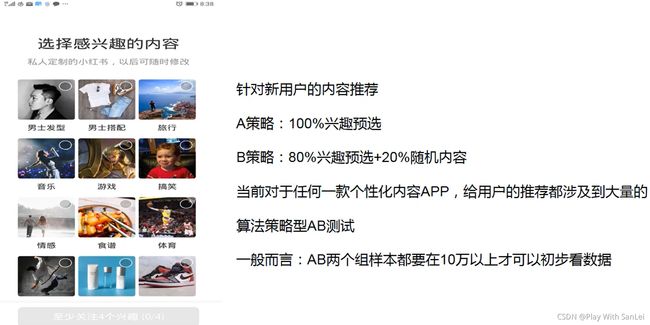
17.1.4 常见的AB测试类型——算法策略型
17.1.5 实际工作中的问题
严格模式下,所有的专题报告落地项(除了明显的bug修复和明显的用户体验) , 都要靠ab测试展开,然而,分析师经常会遇到这种问题:
-
case:2个月前产品上线了短视频功能,两个月后,大盘略涨(之前是略跌趋势) , 短视频和非短视频的数据增加也明显,现在短视频业务方希望分析师能量化出:大盘的上涨主要是因为短视频带来的
有些分析师的思路:同一批用户,在使用短视频前后的数据对比
针对这种问题:只能靠AB去解决,在上线短视频功能前就应该AB,否则后面怎么都说不清
17.2 AB测试注意事项
-
AB两个组是否真的相同——研发负责搭建,但分析师要知道大概原理
只有一个变量:
A:001002 003 004 005
B:001002 003 004
C:001002 003 004 006
D:XY 001 002 003 004
A/B/C是可以做AB测试的,但是D不行,也就是一定要确保只有一个变量,通过最终数据来看这个变量是正向还是负向效应。
分析师在做这件事的时候:可以把AB两个组的原始日志中的分组标志抽出来,看下有无问题,由于每周都会有大量的AB测试,所以一定要保证AB两组只有一个变量不同
-
策略是否生效——研发说进行 了AB测试,但分析师要去抽样看
常见现象:
产品经理根据分析师的专题报告落地项X ,进行某个AB ,研发也进行了AB,最后发现效果不明显,此时所有人都觉得X这个优化项没用,也就没有多去做更多尝试
分析师:同样要去对AB组进行抽样,看B组(实验组)的用户是否真的上线了X优化
多说一句:AB测试系统本身就很复杂,出问题是非常非常正常的,我们不一定要很了解内部详细原理,但是要知道有没有明显问题
-
AB测试评估指标体系——要在AB测试之前,就与研发沟通好看哪些综合性指标
在AB测试之前,就要考虑好最终要用哪些指标来评估效果,最好是能设计出一套综合性的指标体系,后续做实验直接看报表数据即可,不用每次去单独建表
看着很简单,实际做起来往往还挺费时间
格式举例:

-
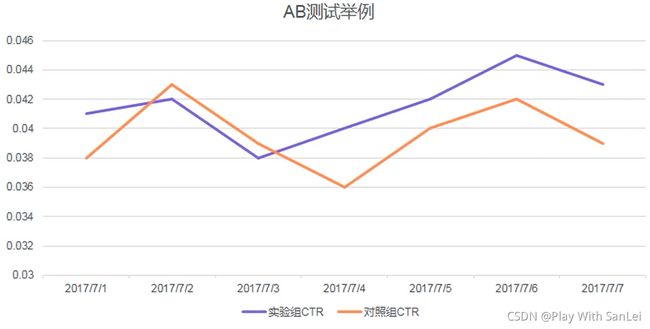
多观察几天数据——往往前几天数据可能有点问题,一般3天后数据才可正式使用
一般而言,前3天都是在一个试验阶段,数据往往参考价值不大(不过能很好的看出试验是否有问题),4-10天数据相对比较稳定,可以当作测试结论。
-
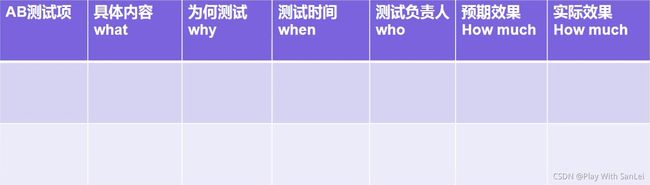
AB测试的存档规划——所有AB都要文档化,方便后续找增长点
分析师要定期复盘做了哪些AB,预期效果和实际效果,这个也是落地项的闭环
建议采用5W1H方法来管理AB测试
文档是数据分析师日常非常重要的工作之一,一定要标准化、规范化
17.3 AB测试案例
Netflix、墨迹天气
17.4 思考总结
- 对于设计师:设计思维+AB测试,无论是效率上还是效果上,都有极大的提升
- 对于产品:直觉是不靠谱的, AB测试的闭环能够让我们更好的去理解用户;同时要通过AB测试去总结出,我们的用户到底喜欢什么样的策略和界面,让AB测试本身自我迭代
- 对于分析师:
- 对大多数改动都不会带来大幅效果提升, AB测试往往效果都是略好,所以要持续迭代
- 如果某个试验效果非常好,这个时候就要非常小心了
- 所以专题分析也是一个持续的过程,越来越深入,越来越了解用户和产品
第五部分 数据分析师个人修养提升
18. 行业分析
18.1 行业分析的两种背景
-
当前公司准备进入某行业,需要分析师或者战略部门给出一根详细报告
-
业务发展遇到瓶颈,需要分析师去验证当前市场对产品的需求有无变化
18.2 行业分析——问题的识别与拆解
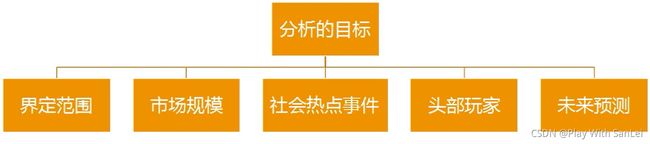
围绕分析目标,把这5大模块说清楚,不在于大而全和什么方法,而在于有所发现
举例
19. 数据仓库
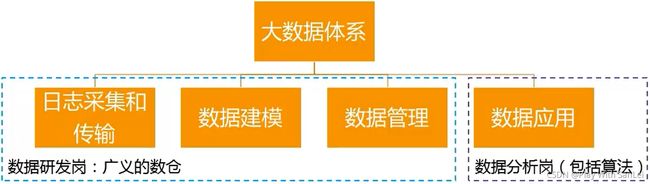
19.1 大数据体系:高度要够,熟悉整个行业,专注某个模块
19.2 数据研发工程师和数据分析师的关系
-
大公司:分工很明确,分析师这个岗位有点“风险性”,研发工程师相对比较稳
-
小公司:全部是数据研发工程师,分析师的活也干了,所以看似什么都懂,但不会很专
-
即使作为研发工程师,也要懂业务,否则你研发出来的产品真的没人用
-
即使作为分析师,也要懂研发,否则你的沟通效率、提数效率都会较低
19.2.1 APP日志采集中的埋点
前中期:数据分析师进入一家公司时,一定要参与到埋点讨论中去,不要把研发想的多专业,如果埋点出问题了,会非常耽误业务的分析。很多研发就是纯粹凭感觉埋。在这个过程中把埋点规范建立起来。
后期:不要投入太多时间,知道有哪些新的埋点,文档化即可,后面所有的人都参照这个
包括规范化好公参:这个是分析师来定,就是有些参数是所有行为日志一定要有的,日志名、业务模块、具体功能
也就是说:一定是分析师牵头,树立自己的权威性,埋点是不是很繁琐,但非常重要,任何做分析的人都要找你,所以良好的发展需要这些软的东西
19.2.2 建模
痛点:
日志量太大,跑数很慢:一个简单的Join都要半个小时才能出结果,而sql仅是非常容易出错的
结果:整个分析团队产出效率太低
日志太乱,很多重要的数拿不出来:算近一个月新增用户的订单量,如果没有好的数据建模,根本就跑不出来
结果:很多重要的思考点都无法落地,显得很不专业
为何要建模:
- 提高整体计算效率,减少重复开发
- 历史数据追踪,中间表数据可以存储一年
- 更好适应业务发展,修改影响范围较小
- 清晰数据结构,分析师更加容易理解
19.2.3 主要步骤
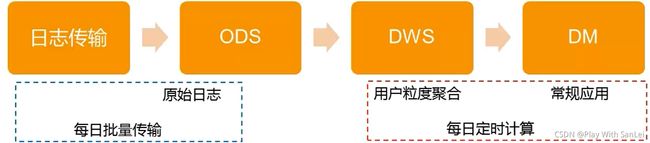
注意:
- 不要过度相信研发的话:一定要自己动手试一次,比如用表计算一次日活
- 不要去做研发做的事:调度异常、表大小、配置错误、UDF函数、 日志传输,这些东西非常耽误时间,对你做业务也没好处,可以提建议但不动手
- 不要去等研发开发表:数仓对分析师而言最直接的好处就是快,而分析师的最终目的是有数据,所以目标不要搞错
19.2.4 数据管理
- 计算管理:join注意事项,表选择, MR内部原理
- 数据存储管理:核心的表尽量保存久一点( 3个月以上) , 非核心的表1个月内即可,分析师要对表的存储周期有概念,很多时候都要去看历史数据
- 权限管理:分析师往往是管理员权限, 所以不要随便给其他人开权限
- 这件事我们这么说:你如果做好了没啥,一但有问题就是大问题,所以采用最小可满足原则给权限就行,同时给读权限
19.3 总结
- 埋点的重要性:主动性和文档化
- 数据建模的三层次:快速迭代
- 数据的管理:权限管理
20. 用户研究
20.1 什么是用户研究
用户研究是一种职业意识,任何人都应该具备用户研究思维,包括:
- 这个功能能满足户什么需求:大部分APP都是抄来抄去,这就是没想清楚
- 用户当前反馈最多的问题是什么:哪些可以重点解决
- 针对这两种问题,需要去进行线上或者线下调研,获得数据反馈
20.2 什么时候做用户研究
用户研究是贯穿整个项目生命周期的
- 项目前期:用户需求情况、用户基础画像情况:用户对于低价商品的迫切度
- 项目中期:用户行为习惯
- 项目后期:用户对产品的反馈点、竞品使用情况
- 所有的一切都是为了更好的去了解用户,与数据分析相辅相成:从数据角度有时并不能很好的反映用户的行为及原因
- 用户研究在项目启动前就应该开展,要快于其他方,所以非常考验用研人员的先见性和实操性
20.3 用户研究的步骤和关键点
- 制定研究目的:有良好的背景和具体的问题
- 选择研究方法:定量和定性方法要对
- 研究结论产出:精而快
举个例子
20.4 用户研究和分析师的关系
数据分析师一定要有用户研究的意识,常见的做法是:
- 每天体验产品
- 每周看客服数据
- 对于费解的数据分析结论,推动用户研究人员去做用户访谈或者问卷
- 新项目启动期,如果要去线下了解用户,分析师要抓住这些机会
21. 时间管理
21.1 时间管理
- 事情优先级排序:二八原则
- 状态好的时候做最重要的事,状态不好的时候做杂事:以人为本
- 对最重要的事情进行效果反馈并反思:刻意练习
- 有点可控的小压力:有压力会更高效更聪明
- 举个例子:开会,发邮件,提数,做专题分析,跟leader汇报工作
- 到底哪个重要:对你接下来一段时间的发展最有好处,比如是写专题分析,专题分析做完后,得到的效果是什么:影响力有没有增加
21.2 关键点1——早起
早起的好处:
- 明显一天做的事情更多
- 心情更好
- 身体更好
- 运气更好
- 周一早上不虚、周末两天充实
- 每天可能就那么30分钟,但这个30分钟的价值是巨大的,不同时间段的时间价值是不一样的
21.3 关键点2——阶段性熬夜
当最近的时间对你接下来的发展很重要时,这个时候就要投入大量时间去做这件事了,这就会造成相比于平时时间不够用,所以一定会有一个阶段性熬夜,熬夜的好处:
- 自己还年轻
- 打破偶尔的平静
- 让自己感觉到压力
- 夜深人静的时候,内心会变得很平静
21.4 关键点3——上下班时间
一线城市上下班时间:90分钟
- 最低目标:一周有3天能很好的利用这段时间
- 做什么:跟自己的职业规划相结合,不要花过多时间去做纯工作上的事情,如果确实不知道做啥,看书是最好的打发方式
- 所以,尽量不要开车上下班,能打的就打的
21.5 关键点4——会议时间
会议前要充分了解会议主题和参与人,跟自身没什么关系就不需要去
会议有3个目的:
- 个人汇报——必须
- 信息的同步和了解——知道方向
- 管理层的思考方式——学习他人的思维
21.6 关键点5——周六日
周六日要做到学习娱乐平衡
-
学习:少睡一个小时
-
娱乐:户外运动
实际上,一旦你在周六日进行了学习,下周的工作会变得更加自信,状态会非常好
作为数据分析师,独自去研究一些专题 ,也只有周末时间能满足你
后记
这是我大三时期智慧调研数据分析班的第一周笔记,这几百分钟的课程来源于我前同事就职于的公司——拉勾教育的一位老师的分享,在这门课中,我解决了好多在公司实习时期的疑问。这个课,全是干货,在之前我的生涯规划中,一直认为技术是最重要的,在听了这位前辈的分享之后,我对我自己的想法进行了改观。在之前的实习中,我也对职业进行过一定的思考,但是还是比较迷茫。在听了前辈的分享后,我有了方向,在个人发展方向,有了目标,Spring老师算是我的启蒙老师了。