常用本体建模工具
常用本体建模工具:
Apollo、OntoStudio、TopBraid Composer、Semantic Turkey、Knoodl、Chimaera、OliEd、WebODE、Kmgen和DOME
Protégé
Protégé[1]是一款由斯坦福大学编写并维护的开源本体建模和编辑工具,其支持Web版本和PC版本,使用OWL语言(关于OWL的详细介绍可参看前文2.1节内容)对知识进行表示,读者可以通过Protégé的官方网站访问Web版本或下载桌面版本。Protégé最早开发于1987年,最初目的是通过减少知识工程师的手动操作来消除知识建模的瓶颈,经过若干次的版本迭代,逐渐演化成了现在的基于框架的本体编辑建模工具。Protégé的主要用途包括类建模、实体编辑、模型处理以及模型交换等。Protégé主要支持Protégé-Frames(通过Protégé的用户界面使用其框架构建本体)以及Protégé-OWL(使用OWL语言直接进行构建)两种方式的本体建模。
1.决定本体的领域和范围
使用Protégé构建本体的第一步,是确定本体覆盖的范围。此时需要根据即将创建的本体回答如下几个问题。1)本体需要覆盖的领域是什么?2)该本体的用途是什么?3)本体中的数据会被应用到怎样的场景?4)该本体将如何进行维护?
2. 考虑使用已有本体
在Protégé中,既可以直接在顶部菜单中选择File →Open打开已经保存的本体文件,也可以选择本体界面下方的Importontologies处进行导入,如图所示,这里需要选择导入的本体源,可以选择从本体文件导入(选项1)、从网络源导入(选项2)以及将已经加载的本体文件重新导入当前工程(选项3)。

3. 列举本体中的关键项
在构建本体时,为了让本体的构建者和使用者都有一个清晰的概念,可以将本体中的关键项列举出来。在这里,关键项是指领域中的一些重要概念。在列举的过程中,一些关键性信息也应该被同时提及,比如关键项的属性、描述等。在构建更复杂的本体时,在列举时往往不需要考虑每个属性的具体描述,以及它们之间是否有重叠,抑或是否需要添加类的概念。考虑例子中想要分析企业间竞争关系的需求,毫无疑问此时企业应当作为关键元素之一。同时,考虑到企业中的关键人物,以及企业所在地点也会对企业的发展和竞争力起到至关重要的作用,故把人物和地点也作为本体中的关键元素。综合以上分析,需要构建的本体应当包括企业、人物和地点这三个重要元素。如果想要进一步分析企业与企业之间的竞争关系,需要把企业的所属行业、注册资金、成立时间都作为企业关键项的关键属性。
4. 确定类和类的结构
目前最常用的三种类的定义方法是自顶向下定义、自底向上定义和二者结合定义。自顶向下定义是使用最多的定义方法,该方法会从定义最抽象的概念入手,再逐渐细化。比如在金融企业领域本体中,我们可以先定义企业类,再通过创建一些子类对其概念进行细化,比如:私营企业、有限责任公司和股份有限公司。进一步还可以将有限责任公司分为国有独资公司、其他有限责任公司等。

使用自顶向下的方法构建类的结构。首先,需要使用最宏观的概念对关键项进项分类,可以将其分为三类:企业、人物和地点。相应的,我们在Protégé中创建三个类。在创建了新本体后,点击Entity标签,进入实体标签页,可以看到位于左侧的类层级结构,如图3-8所示。

接下来,点击“创建兄弟类”按钮,创建企业的兄弟类“地点”和“人物”。若需要删除类,点击最右侧的按钮即可。值得注意的是,前面列举的关键项还有不完善的地方,所以需要在这里根据需求对每一个类进行细化,最终制定出无法再分的子类,比如之前提到的有限责任公司类应当被分为国有独资公司和其他有限责任公司两个子类。相应的,对于股份有限公司和私营公司也应进行对应的划分。同时,同一层级的不同类应该是互斥的(在这里互斥表示某个实体只可以属于同一层级的其中一类,不能同时属于多个类)。为了达到这样的效果,选中企业类,在右下方的Disjoint with处添加与其互斥的类:地点,结果如图3-10所示。

在OWL中构建本体时,可以发现很多类与类之间的约束,例如互斥、子类、等价类以及原子类等。如图3-10所示,Protégé中已经实现了一些常见约束,并可以通过图形化界面来建立。如果希望进一步了解这些约束,读者可以查阅OWL官方文档[7]。实际上,这些约束对于上层的知识推理是至关重要的。

5. 确定类的属性
当定义了类之后,必须定义每个类内部的数据结构。这一步决定了类的独特性。实际上,决定类的关键因素除了类的名字这一简单标识符外,更关键的是组成类的不同属性。为了给类的内部添加信息,需要回顾第3步中定义的若干关键项,在类的构建结束之后,剩下的关键项大多可以成为类的属性。对于金融领域本体的例子来说,可以包括企业的所属行业、注册资金、成立时间等信息。在为类添加属性时,必须要明确属性描述的信息属于哪一类。通常,在使用Protégé构建本体时,可以通过以下划分方式对类的属性进行分类。
1)类的内部属性:比如企业的注册资金、成立时间等,可以理解为类的先天属性,通常与实体同时生成且一般不可修改。
2)类的外部属性:比如企业的人数,可以理解为类的后天属性,通常可修改。
3)类的部分属性:如果某个实体是结构化的,那么它也可以拥有物理上以及逻辑上的“部分”,比如要构建一个计算机类,其部分属性可以包括CPU、硬盘和内存等。在物理上,这些属性组合构成了计算机。
4)与其他个体的关系:根据在第四步中提到的,某个类的子类会继承该类的所有属性,不难发现与类相关的属性应该尽可能置于抽象程度高的类中,使得其子类可以继承。
经过前面步骤,我们已经基于Protégé完成了本体中类的定义,现在需要进一步完善每个类的属性以及它与其他类的关系。首先,需要创建类与其他类之间的关系,也称作类的对象属性。这里所说的对象属性需要与后文创建的数据属性区分开,对象属性的属性值必须为另一个类,表示类与类之间的关系。而数据属性的属性值为数据类型,只存在于类本身。在Protégé主界面选择Entities标签,再选择Object properties,可以看到如图3-12所示界面。

在当前界面中,依旧选中基对象属性,点击“创建子属性”按钮来创建一个对象属性。比如,已知一个公司必定存在一个法人,在目前定义的金融本体中存在企业类和人物类,那么它们之间应该至少存在“法人”关系,并且方向为从人物类出发指向企业类。点击左上角的Add sub property,在弹出如图3-13所示的窗口中输入要添加的属性名称,并点击确定。
这样就添加了一条对象属性,但是这个对象属性的范围和作用域还没有确定,接着在左侧的属性层级列表中点击刚刚添加的法人属性,在右下角可以看到可选属性的范围(Domains)及作用域(Ranges),范围即该对象属性的出发类,而作用域即为该属性指向的类,定义这样的约束可以使得对象属性具有唯一性。首先点击Domains旁边的加号,在弹出的窗口中选择人物类,这样就确定了属性的范围。同理,在Ranges中选择该属性作用的作用域。在这个属性中,即企业。创建后的结果如图3-14所示。如果想保证该属性与其他属性互斥,点击Disjoint with,从中选择需要与该属性保持互斥的属性即可。值得注意的是,作用域和作用范围不仅适用于当前类,还适用于这个类的所有子类。同时,在构建复杂本体时,若两个对象属性的意义相反,同时它们的作用域和范围也相反,则可以点击Inverse of(相反)对其进行约束。例如,“法人”与“拥有法人”两个关系便形成了Inverse of的约束。
我们还需要为类创建数据属性。进入Data properties子标签,选中topDataProperty,点击左上角的“添加子属性”按钮并输入名称“所属行业”,即创建数据属性成功,如图所示
与对象属性不同的是,对于数据属性,由于其属性值为数据类型,所以目前只需要确定它的作用域。点击Domains右侧的加号,为该数据属性选择作用的类。至此,我们就为创建的类添加了对象属性和数据属性。
6. 确定属性的特点
不同的属性拥有不同的描述方式,比如某些属性可以拥有多个值,某些属性必须使用字符串类型等。举例来说,企业的所属行业必须使用字符串类型。在不同的系统中,用来描述属性的值的数量往往不同,在这里会引入一个新的概念,即属性的“基数”。在系统中,可能会对属性值的最大基数和最小基数做出规定,即属性值的数量必须大于等于最小基数且小于等于最大基数。有时属性的基数也可能被规定为0,这代表类中的某些属性可以不需要任何值来描述。
在Protégé中,也需要确定数据属性的特点。在第5步中,我们给数据属性添加了作用域,这里会为属性添加特点(数据类型)。在Domains标签下方找到Ranges标签,点击右侧的加号,选择Build in datatypes,如图所示,即可为数据属性确定数据类型。
在这里,将所属行业确定为string类型,在列表中找到string类型并选中,这样属性的数据类型就设置好了,如图3-17所示。值得考虑的是,在创建数据属性后,要如何对数据属性进行约束?例如对于企业的成立日期,是否需要统一其日期表示格式?这个问题留给读者思考。
7. 创建实例(实体)
在Protégé中重复第4~6步,即可完善本体中的类以及属性信息。当完成上述步骤后,就可以进入基于Protégé构建本体的最后一步,即创建结构化本体中的实例。定义一个个体实例需要:
1)为实例选择一个类;
2)创建一个该类的实例;
3)为实例填充属性值。
举例来说,我们可以在金融领域本体中创建一个“小米公司”,并定义它属于“其他有限责任公司”类,所属类的父类为有限责任公司,祖先类为企业。使用企业名称来对企业进行唯一标识,然后填充所需要的属性信息。进入Entity标签下的Individuals子标签。假设已经创建了两个对象属性:法人和总经理,作用域都是人物,作用范围都是企业。同时企业类包含三个数据属性:所属行业、注册资金和成立时间,且数据类型都是string。首先我们会创建一个人物实例,点击左上角的Add individual选项,在弹出的窗口中输出实例名字如“雷军”,点击确定即可创建成功,如图所示。
本体建模工具的选择
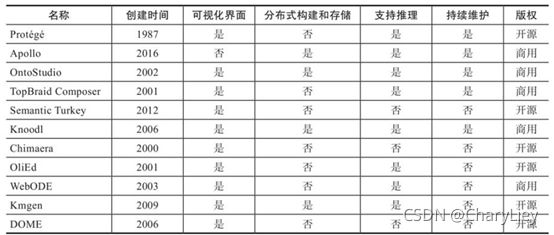
通过前面两节对多种本体建模工具的了解可以得知,在选择合适的本体建模工具时需要额外关注以下特性。
1)该工具是否拥有可视化用户界面。
拥有可视化界面的本体构建工具往往会使本体构建简单很多,因为用户通过对可视化界面进行操作,而无须掌握复杂的程序语言即可构建本体。这对于缺乏计算机知识的领域专家而言相对友好。然而,拥有可视化界面往往会带来一些问题,比如无法批量建立本体中的元素或批量构建本体等。
2)该工具是否支持分布式构建和存储。
在3.1.1节中我们构建的本体只包含简单的几个元素,其对于存储空间的消耗微乎其微。然而一些包含更多领域知识的大型本体可能会含有海量元素,导致本体会消耗大量的存储空间。这时分布式存储即可发挥作用。同时,对于需要异地协同工作来创建本体的场景,也应当选择支持分布式构建的本体建模工具。
3)该工具是否支持推理。
在本体构建完毕后,应该如何验证本体的正确性?根据本体进行推理是一种常用的方法。当面对庞大的数据规模时,逐一对数据进行验证是不现实的,此时可以按照指定的规则在本体中进行推理。若推理可以得到正确的结果,即相当于对本体中结构和数据的正确性进行了验证。
4)该工具是否被持续维护。
在使用本体建模工具构建本体时,可能会遇到各种各样的问题,工具的开发者无法仅仅使用一个版本就满足用户的所有需求且不会出现任何漏洞。同时,系统环境和需求的不断变化也对本体建模工具的兼容性和功能性不断提出新的要求。选择一个有开发者持续维护甚至有完整成熟的社区的本体建模工具尤为重要,这将决定使用者是否可以专注于本体的构建而不是不断对工具进行调整,进而提升本体建模的效率。根据以上四点需要关注的特性,表3-1对本节提到的本体建模工具做出了详细对比,供读者参考。
参考文献:
从零构建知识图谱:技术、方法与案例Knowledge Graph from Scratch: Techniques,Methods and Cases邵浩 张凯 李方圆 张云柯 戴锡强 著