知识图谱论文阅读(十七)【WWW2021】DGCN: Diversified Recommendation with Graph Convolutional Networks

本论文是很明显是基于KGCN的! 如果不懂KGCN,可以看我上一篇博文
论文题目: DGCN: Diversified Recommendation with Graph Convolutional
Networks
论文链接:
论文代码: https://github.com/tsinghua-fib-lab/DGCN
想法
- similar but negative items: 指的是同一类别的items,但是是用户不喜欢的,所以称为是消极的
创新
- (1)和(2)没有改变生成阶段的顺序,而(3)则是存在实际问题。 那么我们就是添加上游任务中,生成一个排序结果,而不仅仅是候选items + 多样性排序
- Rebalanced Neighbor Discovering(邻居取样器,提高劣势类别样本的提取率,降低优势类别样本的提取率;)
- 提高同一类别的消极样本,从而迫使系统能够更加细化user的对同一类别的items,从而使得结果更多样性(Category-Boosted Negative Sampling)
- 对抗学习
摘要
动机:
多样性是衡量推荐items的一个关键因素,但是却很少受到审查!多样性通常会在生成候选项之后考虑,然而这种多样性和生成候选项的分步骤设计使得整个系统表现的不好。
我们:
因此本论文中我们的目标就是将多样性添加到候选items生成阶段! 利用GCN! 但是GCN在CF上有很大的提高,但是本身是没有多样性的! 我们提出在GCN上进行重平衡的邻居发现、类别增强负抽样和对抗学习。
1 INTRODUCTION
我们方法的必要性:
除了相关性,新鲜感、多样性和可解释性等也会影响用户对推荐内容的感知。
- 生成阶段顺序
为了保证用户的满意度,提出了后处理、行列式点过程(determinanting point Process, DPP)和学习排序(Learning to Rank, LTR)三个方向的方法来提高推荐结果[60]的多样性。
(1)在早期,一般都是在生成候选items后再增加一个re-rank或者是post-processing module,最后推荐的item由相关性和多样性之间平衡来定。 许多解决方法被提出,但是都是将重排序当作独立于候选items生成的模块,从优化推荐模型中解耦,这使得多样性信号没有反应到上游相关匹配模型中。
(2) 最近,另一个研究方向利用DPP来取代post-processing based methods,但是该过程仍然在生成阶段之后。
(3)再之后,需要based on LTR方法被提出,它直接生成排序的items,而不是候选items,然而需要收集可行的数据集,存在实际问题。
综上,(1)和(2)没有改变生成阶段的顺序,而(3)则是存在实际问题。
- 要有特定于多样性的设计,使的弱势类别更加容易获得
user-item双部分图,一个用户的高阶邻居往往覆盖多种items,因此很适合在图上进行多样性训练。 然而,如果没有针对多样性的特定设计,这些高阶连接可能无法自动用于寻找彼此不相似的item。 比如,推荐系统可以很容易的学会提供交互最频繁的类别项,因为,它们占了大部分边,虽然GCN这样提高了准确性,但是却忽略了多样性。
我们的方法:
很明显,本工作中将会更加专注于多样化的邻居的发现,所以会更改相关算法,从而使得弱势类别更加容易获得。 我们对负抽样过程进行调整,以提高抽样similar but negative。 此外,我们利用对抗性学习来提取学习后的嵌入空间中的隐含类别偏好。 end-to-end model called DGCN。
PRELIMINARIES
2.1 多样性
推荐的多样性可以是用户内部级别的,也可以是用户间级别的。 intra-user是单个用户的推荐内容的不相似性; inter-user则是集中于为不同用户提供内容。本论文中,我们目标是提高intra-user的多样性。
推荐给每个用户的类别中第一种便是按照他购买物品类别的比例来推荐,比如买的东西是电子设备: 衣服: 饮品。 那么在推荐的时候也要按照个比例来推荐; 其二便是给用户提供他本身没有意识到的物品,比如他可能也喜欢读书,但是书本本来平时搜的少!
本论文中, 我们关注的是多种类别!因此有不同的评判标准:
- Converage:这个指标衡量推荐类别的数量。覆盖范围反映了推荐系统的整体性和全面性。
- entropy: 这关注的是不同类别的分布。用前面的例子,4个电子设备,3件衣服,3杯饮料的熵值比推荐7个电子设备,3杯饮料的熵值高。
- gini index:该指标在经济学中被广泛采用,用于衡量财富或收入不平等,[2]对该指标进行了进一步调整,并将其引入推荐。属于某一特定类别的项目的数量可以解释为该类别的财富。
需要注意的是,在覆盖度和熵值方面,值越大,多样性越强,而基尼系数则相反(越低越好)。
2.2 推荐pipeline
推荐系统典型流程包含三个阶段:(1)匹配(2)评分(3)重排名; 匹配阶段的时候,就是海选的时候,得到一大部分items; 评分阶段需要深度学习模型来得到分数,从而几十项items会被选择;重排名中,选择的items会被重新排序来满足额外的约束。
现有的方法往往将多样性约束放到重排序中,这样使得与上游匹配和评分模型无关,系统则效果不好;其次,匹配模型不知道多样性的信号使得信息本来就是冗余的。
2.3 Accuracy-Diversity dilemma
准确率和多样性往往是反比,比如下图中,随机的、矩阵分解的、神经图CF和需要的多样性算法(MMR、DUM、PFM+α+β 和 DPP),使用了一个真实世界最大的交易数据集TAOBAO
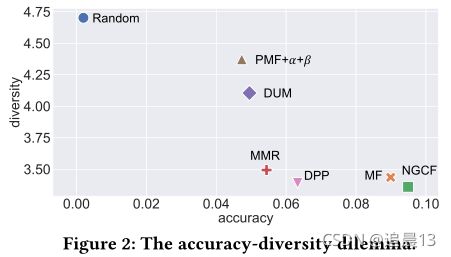
这需要找到一个平衡点!
3 METHOD
3.1 Overview
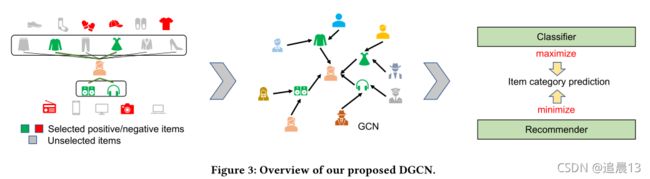
首先建立一个user-item图,边代表了行为,同时是一个无向图。
其次我们提出重新平衡邻居发现来解决不同类别的不一致问题, 为了多样性,我们对负抽样过程做出了调整,增加了选择相似items的概率。 同时我们添加了一个item类别的对抗性任务来增加多样性。
-
Rebalanced Neighbor Discovering 为了在图中发现更多不同的项,我们根据邻居的分布设计了一个邻居采样器,其中提高了选择劣势类别的概率,限制了优势类别。 同时,在邻居采样器的引导下,多个类别的更容易到达
-
Category-Boosted Negative Sampling 我们建议选择相似且负的样本,并增加其选择概率,而不是随机采样。 通过扭曲负样本的分布,user和item的表示会更好地被学习。
-
Adversarial Learning
在item的类别上玩一个最大最小的游戏。 我们提取用户的类别偏好基于item偏好,但是却使得学习到的嵌入没有类别。 因此,这种最大最小博弈使得嵌入空间会有更多的类别。
3.2 GCN
我们的GCN由一个嵌入层和一堆图卷积层组成,其中每个图卷积层包含一个广播操作和一个聚合操作。
3.2.1 Embedding Layer
GCN的输入仅仅是users和items的ID features(也就是说是one-hot ID后学习到的);因此我们有了下面的嵌入查询表:
![]()

每个实体都会被喂入GCN中在图中传递信息。
3.2.2 Graph Convolutional Layer.
卷积层包含了一个发送和一个聚合!
发送方面:
图卷积层中,每个节点向所有邻居广播自己的嵌入,同时呢,也聚合发送给它本身的的所有消息来更新它自己的嵌入(因为每个节点既是下一跳的发送者,同时也是上一跳的接受者)!
聚合方面:
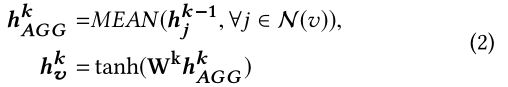

h v k h_v^k hvk是节点 v v v的 k k k-th层的特征向量, N ( v ) \mathcal{N}(v) N(v)表明了节点 v v v的取样邻居的集合。 在[59]的研究中,添加自环在图卷积网络中是至关重要的,因为它压缩了归一化拉普拉斯的频谱。因此我们也会将 v v v本身添加到 N ( v ) \mathcal{N}(v) N(v)中,通过这种方式,节点的嵌入以分层的方式在图上传播。
3.2.3 Interaction Modeling.
在匹配阶段,由于计算成本和延迟要求,所以内积和L2距离被广泛使用,而且在线服务中,也是很有效果的! 因此可以加快邻居的寻找算法。 因此,我们在图的最后一层卷积层使用user和items的表示,并取它们的内积来估计交互概率。
![]()
3.2.4 防止过度拟合
我们会以概率p来随机的去掉连续卷积层之间的中间节点嵌入,p是超参数需要学习。
下面我们将讲解利用高阶连通性来学习多样化。
3.3 Rebalanced Neighbor Discovering
将百万级别的图直接运行GCN不现实,而分成mini-batch会影响效果。 因此,邻居取样器(neighbor sampler)应运而生! 它可以从原始图中采样出子图,同时在图上的归纳学习会被实现,并且已经证明可以在数十亿级别的图上使用。 具体而言,邻居采样器会生成 N o d e F l o w Node Flow NodeFlow,这是一个多层的子图,其中边缘只存在于连续的层中。
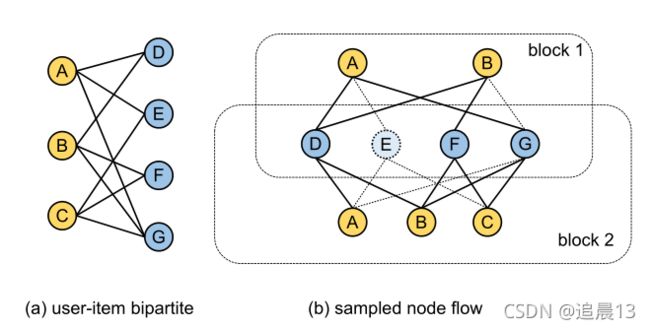
图中: 2层的GCN的邻居采样器生成的Node Flow。在该例子中,一个小批由一定数量(即批大小)的user和item组成, 组成种子集。 所以在该图中节点node A和node B是种子节点。 对于每个节点,随机取样它的两个邻居(比如A的就是D和G; B的就是D和F),然后对block 1使用GCN层; 而在block 1中激活的邻居将作为新的种子(也就是D、F和G),重复每个节点再随机取两个邻居。 再在Block 2上执行GCN。 每个卷积层对应一个块。
上面所有的都是别人东西,下面是自己的东西。
但是上面的发现策略忽略了多样性问题。 在真实世界中,不同类别的item会以不同的方式对待!根据用户花费的时间的长短, 我们大致分为优势和劣势类别。 优势类别会成为主流,而劣势类别不被关注。
因此我们提高了从劣势类别中抽取项目的概率,并限制了从优势类别中抽取项目的数量。强调了类别多样化, 重新平衡的邻居发现算法如算法1和算法2所示,由于篇幅的限制,我们省略了GetNeighbors和SampleWithProbability的详细说明,这只是在邻接类别和给出分布的随机选项的简单的查找操作。 在一个user node,我们首先生成item类别的直方图,然后取直方图的逆来增加劣势邻居的比例。 同时,一个平衡参数α会控制bias; 对于一个item node,我们平等对待与它相连的每一个user,并均匀地抽样它的邻居。 这样就会增加了多样性。

3.4 Category-Boosted Negative Sampling
从字面上就能理解个大概,就是将上面的取样概率引入到负样本取样。
当前匹配的主要挑战也被称为是隐式反馈。 隐式反馈的意思是说:负样本并不一定意味着用户真正不喜欢的! 因此探索用户的隐式反馈也是一大挑战。在实际中,消极实例是通过从那些没有交互过的items中随机抽样的。 在训练时,正样本和一定数量的负样本配对(负样本率),通过pointwise或者pairwise损失函数来优化,使得正向items与user更接近,而消极items和user越远。
很多工作在致力于negative sampler的设计,在本论文中,我们提出选择similar but negative items, 也就是与阳性样本类别相同的item。通过从positive category中抽取负面items,推荐系统将会在一个类别中区分用户的偏好。 这样会使得推荐系统在同一类别中有更强大的区分能力,使得推荐系统会多考虑多种类别的items(就是说只有top-50,现在同一类别中冗余的少了,那么腾出位置给不同类别的了!)

超参数β用来控制相似items的取样比例。 在训练阶段,等多similar but negative items会增强推荐系统的能力,从而从多种种类中捕获用户的兴趣。

图5:取样空间的说明。消极的实例是从积极的items中抽取的。我们提出了类别增强的负抽样,它提高了从积极类别(浅绿色区域)的项目中抽样的概率。
这里就是实际的生活,消极类别就是多于积极的类别,同时在积极类别中选取积极的items! 而这里我们取样时,在积极类别中抽样消极实例,消极类别又多于积极类别,这增加了来自消极类别的积极items被推荐的可能(解释同上)。 从而生成更多多样化的候选items
3.5 Adversarial Learning
模型训练阶段! 大多数推荐模型都是单一的准确率目标,忽略了推荐的多样性。 在只有一个准确率优化对象的情况下,用户的类别偏好是通过用户的物品偏好隐式学习的。以第2节中的相同例子为例,推荐系统可能会了解到用户对整个类别(即电子设备)的兴趣,但无法区分用户对不同电子设备的具体偏好(也就是说上面没有同类消极样本)。
所以不提取隐含的类别偏好会导致推荐更过积极类别的items! 受生成模型研究进展的启发,我们建议增加items类别分类的竞争性任务,以达到精馏的目的,进一步增强多样性。具体上说,我们将推荐模型当作生成器,同时增加了一个分类器用来预测该item的类别。 而推荐系统要尽力如fool分类器。
我们的实验中,采用全连接层作为分类器,并使用交叉熵损失进行优化。 在推荐方法,采用log loss。

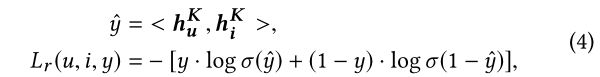

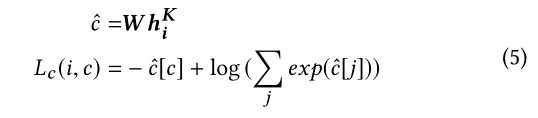
在对抗性学习的设置下,项目类别分类器的目标为最小化 L c L_c Lc, 推荐模型的目标是最小化 L r − Υ L c L_r-\Upsilon L_c Lr−ΥLc。其中 Υ \Upsilon Υ是平衡主任务和额外对抗任务的。
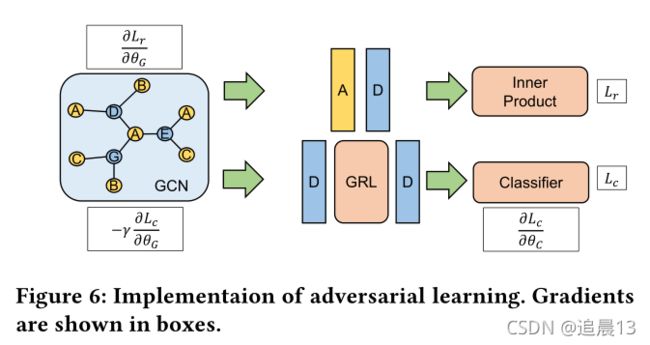
在分类器中,是通过寻找item embedding的聚类来最小化分类损失的(就是分类!! 分类就是聚类); 而推荐模型中,分类损失被逆转了,使得同一类别的item嵌入彼此远离(因为推荐系统就是要区分items使得不同的被推荐)。
在实现方面,反向传播过程中插入梯度反转层(GRL)可以很好的完成对抗学习,在领域自适应网络(GAN)中首次引入。 同时我们期望分类器最小化 L c L_c Lc,迫使GCN最大化 L c L_c Lc。 我们在从GCN中嵌入的item学习和完全连接的分类器之间插入一个GRL(两个D之间)。在反向传播过程中,最小化分类损失的梯度通过分类器反向流动,并经过GRL。梯度将被逆转(加负号),进一步流向GCN,即对于损失 L c L_c Lc,分类器的参数进行梯度下降,对GCN的参数进行梯度上升。 对于 L r L_r Lr,梯度下降会被应用到GCN。
4. Experiment
在本节中,我们通过实验回答以下研究问题:
•RQ1:与其他多样化推荐算法相比,本文提出的方法表现如何?
•RQ2: DGCN中每个拟议成分的影响是什么?
•RQ3:如何使用DGCN在准确性和多样性之间进行权衡?
数据集:Taobao、Beibei、MSD、
基线: MMR、DUM、PMF+α+β、DPP
参数设计:

评估:我们使用内积来评估交互可能性; 使用Faiss来生成候选items; 在评估的时候,我们会在Faiss中创建一个search index(IndexFlatIP6用于基于内积的最近邻搜索),将用户嵌入作为查询向量提供给搜索索引, 将检索与查询向量最大内积的项,并根据检索到的项进一步计算推荐指标。 此外,评估中会生成batch,并在GPU上加速。在最近邻搜索的帮助下,我们成功地将评估的时间成本降低到几秒。
4.2 Overall Performance (RQ1)
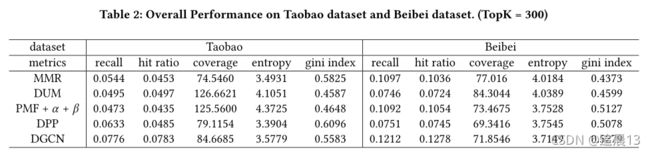
我们提出的DGCN实现了更好的整体性能。
4.3 Study on DGCN (RQ2)
在本节中,我们对我们在DGCN中提出的每个组件进行消融研究。我们比较了我们所提出的方法在重新平衡邻居发现、类别增强负抽样和对抗学习方面的性能。
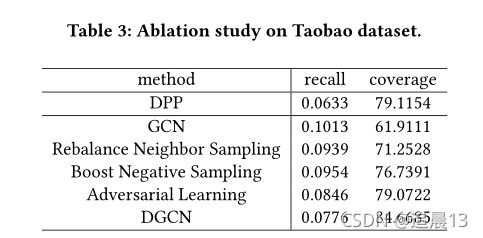
在不丢失GCN优越性能的前提下,我们提出的DGCN在GCN的基础上,采用了三种特殊的多样化设计,大大提高了多样性,同时也保证了推荐项目的相关性
4.4 Trade-off between Accuracy and Diversity(RQ3)
在提出的框架中,我们引入两个超参数α和β,以控制重平衡邻居发现和类别增强负抽样的强度。我们现在研究这两个超参数是否可以用于在准确性和多样性之间进行权衡。
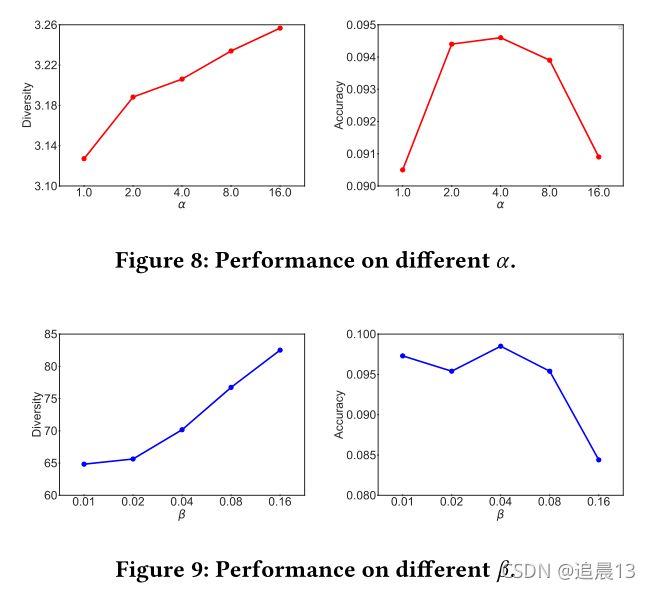
总之,我们进行了广泛的实验来评估我们提出的DGCN,特别强调多样化。在真实数据集上的整体性能证实了我们方法在改善多样性方面的有效性。对DGCN的消融研究证实了各成分的功能。进一步的实验表明,通过调整引入的超参数,可以在精度和分集之间实现平滑的平衡。