复现实验:文本数据的分类与分析
声明:实验来源全部参照https://github.com/hycsy2019/TextClassification
实验操作-->实验目的:
对训练集数据进行预处理-->掌握数据预处理的方法。
对语料库的文档进行建模-->掌握文本建模的方法。
基于有监督的机器学习方法训练文本分类器-->掌握分类算法原理。
利用学习的文本分类器对未知文本进行分类判别,掌握评价分类器性能的评估方法。
实验内容:
通过分类算法对文本进行数据挖掘。
1、收集web文档进行语料库的构建。
2、对语料库进行数据的预处理,预处理包含(文档建模、去噪、分词、简历数据字典、使用词袋模型、主题模型表示文档等)。
3、选择分类算法,训练文本分类器,理解所选分类算法的建模原理,实现过程和相关参数的含义。
4、对测试集的文本进行分类,计算每类正确率、召回率、计算总体的正确率和召回率。
实验数据:
数据来源:github 上的“大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP”项目https://github.com/brightmart/nlp_chinese_corpus使用了其中的“百科类问答json版”语料库。
数据处理:
1、json文件转成txt文件。
JsonTotxt.py
import json
import os
'''''返回类别修正后的类别名'''
def rename(s):
'''''对类别名进行切片,将多个大类拆分为小类,或将多个小类合并为大类'''
type0 = s[0:2]
type1 = s[5:7]
type2 = s[3:5]
type3 = s[8:10]
type4 = s[6:8]
type5 = s[11:13]
type6 = s[10:12]
if type5 in {'生物', '数学', '工程'}:
s = type5
elif type6 == '上网':
s = type6
elif type3 == '诛仙':
s = type3
elif type4 in {'财务', '股票', '基金', '文学', '外语'}:
s = type4
elif type1 == '手机': # {'军事','法律'}:
s = type1
elif type2 in {'精神', '恋爱', '夫妻', '财务', '宝宝'}: # {'博彩','度假','星座','音乐','购物','交通','美食'} :
s = type2
elif type0 == '体育': # {'电脑','电子','烦恼','汽车','商业','文化','游戏','教育','健康'}:
s = type0
else:
return ""
return s
fr = open("baike_qa_train.json", "r", encoding='utf-8')
data = []
typenum = {'体育': 0, '精神': 0, '恋爱': 0, '夫妻': 0, '财务': 0, '宝宝': 0, '手机': 0, '财务': 0, '股票': 0, '基金': 0, '文学': 0, '外语': 0,
'诛仙': 0, '上网': 0, '生物': 0, '数学': 0, '工程': 0} # 设置词典标识每个类的文本数量
# {'娱乐':0,'健康':0,'美食':0,'教育':0,'军事':0,'法律':0,'博彩':0,'度假':0,'星座':0,'音乐':0,'购物':0,'交通':0,'电脑':0,'电子':0,'烦恼':0,'汽车':0,'商业':0,'文化':0,'游戏':0}
'''''将json文件转化成不同类别文件夹下的txt'''
for line in fr.readlines():
'''''以字典形式读取json文件'''
ls = json.loads(line)
data.append(ls["title"])
data.append(ls["desc"])
data.append(ls["answer"])
s = ""
'''''转化为字符串'''
for each in data:
s = s + each + '\n'
'''''过滤长度小于60字的文本'''
if s.__len__() > 60:
'''''转化为对应的类别'''
type = rename(ls["category"])
'''''是所选择的类别,并且文档数未达到10000篇'''
if type != "" and typenum[type] <= 9999:
typenum[type] += 1
'''''新建文件夹'''
if not os.path.exists('QAsamples2/' + type):
os.makedirs('QAsamples2/' + type)
'''''写txt'''
file = 'QAsamples2/' + type + '/' + str(typenum[type]) + '.txt'
fw = open(file, 'w', encoding='utf-8')
print(type + '/' + str(typenum[type]))
fw.write(s)
fw.close()
data.clear() 代码执行后的生成的示例文档:
2、分词并利用stop_words.txt去停用词。
stop_word.txt文档已上传至百度网盘链接:
https://pan.baidu.com/s/1SPsxZop-kHWFRI3z5zfJzw
提取码:1111
stopword.py
import os
import jieba.posseg as pseg
path = r'C:\Users\17974\Desktop\restart\graduate\Code\TextClassification-main\result7'
'''''读取停用词文件'''
f_stop = open('stop_words.txt', 'rb')
stopwords = f_stop.readlines()
'''''判断是否为中文'''
def is_Chinese(word):
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
def wordSplit(path):
'''''生成指定文件夹下文件列表'''
for file in os.listdir(path):
type = file
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
for each_file in os.listdir(file_path):
f = open(file_path + '/' + each_file, 'rb')
p = f.read().decode('utf-8')
'''''去空格'''
p = p.replace(" ", "")
print(type + '\t' + each_file)
'''''分词'''
words = pseg.cut(p)
'''''创建结果目录文件夹与txt'''
if not os.path.exists('result7/' + type):
os.makedirs('result7/' + type)
r = open('result7/' + type + '/' + each_file, 'w', encoding='utf-8')
'''''过滤停用词与非中文词,取名词和惯用语'''
for w in words:
if ('n' or 'l') in w.flag and not w.word in stopwords and is_Chinese(w.word):
r.write(w.word + '\n')
r.close()
'''''获取所有文件夹名称'''
wordSplit(path)处理过的示例文本如图:
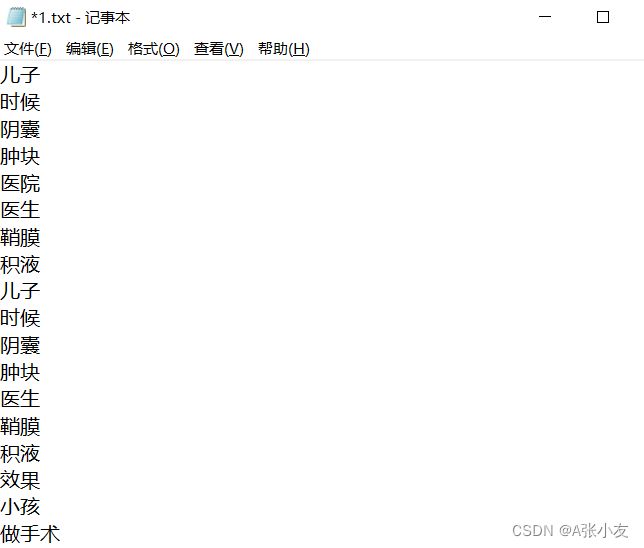
3、划分测试集和训练集(前5000分为test,后5000分为train)。
import os
import shutil
path = 'C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/result7'
#生成每个类的文件目录
for file in os.listdir(path):
type = file
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
i = 1
#创建train、test文件夹
if not os.path.exists(file_path + '/train'):
os.makedirs(file_path + '/train')
if not os.path.exists(file_path + '/test'):
os.makedirs(file_path + '/test')
#将txt前5000移动到train文件夹中,后50000移动到test文件夹中
for each_file in os.listdir(file_path):
ori_path = file_path + '/' + each_file
des_path = ''
if not os.path.isdir(ori_path):
if i <= 5000:
des_path = file_path + '/train/' + str(i) + '.txt'
else:
des_path = file_path + '/test/' + str(i - 5000) + '.txt'
print(type + '\t' + each_file)
shutil.move(ori_path, des_path)
i += 1
4、计算idf(逆向文件频率)。
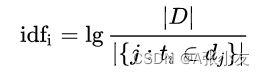
- |D|:语料库中的文件总数。
- j:包含词语t的文件数目。
idfcount.py
import os
import re
import operator
import math
'''''path这里改成clean_data文件夹的位置'''
path = 'C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/result7'
tf = {}
idf = {}
'''''索引每一类路径'''
for file in os.listdir(path):
type = file
file_path = path + '/' + file
tf_sum = 0
tf = {}
if os.path.isdir(file_path):
i = 1
sp = []
file_path += '/train'
'''''进入每一类的train文件夹'''
for each_file in os.listdir(file_path):
each_path = file_path + '/' + each_file
f = open(each_path, 'r', encoding='utf-8')
print(type + '\t' + each_file)
rf = f.readlines()
'''''将所有词加入列表sp中'''
for each in rf:
sp += each.split()
f.close()
for each in set(sp):
if each in idf.keys():
idf[each] += 1
else:
idf[each] = 1
'''''输出'''
f = open('idf.txt', 'w')
for (word, count) in idf.items():
s = '%s %7lf' % (word, math.log(50001 / count, 10)) # 50000为总文档数,+1防止log1导致idf=0
f.write(s + '\n')
f.close()
5、生成词袋
![]()
计算TF(词频),然后将词和其对应的词频整合到dict.txt。之后合并成总词典total_dict.txt。
Grdict.py
import os
'''''此处改成clean_data的位置'''
path = 'C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/result7'
idf = {}
'''''读取idf值'''
f = open('idf.txt', 'r')
p = f.readlines()
for each in p:
idf[each.split()[0]] = float(each.split()[1])
f.close()
'''''索引每一类路径'''
for file in os.listdir(path):
type = file
file_path = path + '/' + file
tf = {}
if os.path.isdir(file_path):
i = 1
sp = []
f_dict = open(file_path + '/dict.txt', 'w')
file_path += '/train'
'''''进入每一类的train文件夹'''
for each_file in os.listdir(file_path):
each_path = file_path + '/' + each_file
f = open(each_path, 'r', encoding='utf-8')
print(type + '\t' + each_file)
rf = f.read()
'''''将所有词加入列表sp中'''
sp = [one for one in rf.split()]
f.close()
for each in sp:
if each in tf.keys():
tf[each] += 1
else:
tf[each] = 1
'''''找出前2000,根据tfidf降维'''
tf = dict((sorted(tf.items(), key=lambda kv: ((kv[1] * idf[kv[0]]), kv[0]), reverse=True))[0:1999])
'''''写单类dict,输出单词 词频'''
for (word, fre) in tf.items():
s = '%s %7d' % (word, fre)
f_dict.write(s + '\n')
f_dict.close()
生成的词袋如图: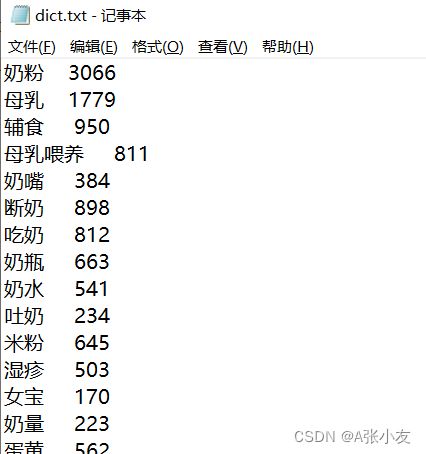
TogetherDict.py
import os
'''''path这里改成data文件夹的位置'''
path = 'C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/result7'
total_dict = set()
'''''索引每一类路径'''
for file in os.listdir(path):
type = file
file_path = path + '/' + file
if os.path.isdir(file_path):
i = 1
sp = []
f = open(file_path + '/dict.txt', 'r')
print(type + '\tdict.txt')
p = f.readlines()
for each in p:
total_dict.add(each.split()[0])
f.close()
'''''将每一类的dict合并为total_dict'''
f = open(path + '/total_dict.txt', 'w')
for word in total_dict:
f.write(word + '\n')
f.close()
数据处理完成后进行两种分类器的实现:
朴素贝叶斯分类器:
代码报错未实现,报错原因猜测是处理的数据源导致的,具体为在取对数时出现负值,错误提示如附件1。
beiyesi.py
import os
import math
import time
import numpy as np
ROOTPATH = 'C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/result7'
global categories # = ['健康', '商业', '娱乐', '教育', '文化', '游戏', '烦恼', '生活', '电脑', '社会']#注意不可改变顺序!!!!
global cateCount
global CATENUM # 类别总数
global VOCABULARYNUM
global bigDic
global gmatrix
global idfBook;
def form_big_dic():
# 构造所有类别的词典
global bigDic, categories
bigDic = dict()
contents = os.listdir(ROOTPATH) # 电脑、烦恼、健康。。。。
categories = []
for each in contents: # each是电脑、烦恼、健康等某一类
if os.path.isdir(ROOTPATH + '\\' + each): # 判断是文件夹,打开
categories.append(each)
bigDic[each] = read_file(ROOTPATH + '\\' + each + '\\' + 'dict.txt')
#print(bigDic)
# print(len(bigDic['电脑']))
# #读一个字典向量文件,返回一个字典
def read_file(filepath):
with open(filepath) as fp:
content = fp.read();
book = content.split('\n')
d = dict();
for each in book:
if each: # each不为空
temp = each.split()
# print(temp)
if len(temp) == 2:
d[temp[0]] = float(temp[1])
else:
d[temp[0]] = 0
return d
def P(word, vj):
# P(wk|vj)=(nk+1) / (n+|Vocabulary|)
nk = bigDic[vj].get(word, 0) # 单词wk出现在Textj中的次数,若没有出现,则为0
n = cateCount[vj]
ans = (nk + 1) / (n + VOCABULARYNUM)
# if(ans == 0):
# print("Im 0000000000000000000000")
# exit()
return ans
# V为所有类的向量,text为待分类文本string,返回值为分类结果
def Vnb(text, V):
max = -9999999999999999999999999999999999999
tans = 0
retu = ''
l = text.split()
for j in V: # 对于每一类
for word in l: # 对弈一篇文本中的每一个单词
idf = idfBook.get(word, math.log(50000, 10))
time.sleep(0.001)
# print("idf:", idf)
# print(math.log(P(word, j) * idf, 10))
# exit()
tans = tans + math.log(P(word, j) * idf, 10)
# print("tans=", tans)
# exit()
if tans > max:
max = tans
retu = j
tans = 0
# print("j=",retu,"max=",max)
return retu
def cal_cateCount(categories):
n = 0
for vj in categories: # each为健康等类别
for key in bigDic[vj]:
# print("key=",key)
n = n + bigDic[vj][key]
cateCount[vj] = n
n = 0
# 打印混淆矩阵
def print_matrix(matrix):
print('{:>8}'.format(''), end='')
for label in range(len(categories)):
print('{:>7}'.format(categories[label]), end='')
print('\n')
for row in range(len(categories)):
print('{:>8}'.format(categories[row]), end='')
for col in range(len(categories)):
print('{:>8}'.format(matrix[row][col][0]), end='')
print('\n')
# def print_matrix(matrix):
# print(categories)
# for i in range(len(categories)):
# print(categories[i],matrix[i])
def classify_all_texts(rootpath, matrix):
contents = os.listdir(rootpath) # 电脑、烦恼、健康。。。。
print(contents) # 注意顺序!!!
for each in contents: # each是电脑、烦恼、健康等某一类
if os.path.isdir(rootpath + '\\' + each): # 判断是文件夹,打开
texts = os.listdir(rootpath + '\\' + each + '\\' + 'test')
for text in texts:
with open(rootpath + '\\' + each + '\\' + 'test' + '\\' + text, encoding='utf-8') as fp:
string = fp.read()
vj = Vnb(string, categories)
i = categories.index(each) # 实际值
j = categories.index(vj) # 预测值
matrix[i][j][0] += 1
# print(matrix)
print_matrix(matrix)
def cal_precision_and_recall(matrix):
precisionList = []
recallList = []
for j in range(CATENUM): # 先对列进行遍历
sum = 0
for i in range(CATENUM):
sum = sum + matrix[i][j][0]
a = matrix[j][j][0]
recall = a / 5000
precision = a / sum
precisionList.append(precision)
recallList.append(recall)
print("类别:", categories[j])
print("a:", a)
print("sum:", sum)
print("precision={} , recall={}".format(precision, recall))
total_precision = np.mean(precisionList)
total_recall = np.mean(recallList)
print("total_precision={} , total_recall={}".format(total_precision, total_recall))
if __name__ == '__main__':
# 计算十万篇文本的单词总数
book = read_file(ROOTPATH + '\\' + "total_dict.txt")
VOCABULARYNUM = len(book)
#print(book)
print("VOCABULARY=", VOCABULARYNUM)
idfBook = read_file(ROOTPATH + '\\' + "idf.txt")
# 构造所有类别的词典
form_big_dic()
# 计算每一类的位置总数
cateCount = dict()
cal_cateCount(categories)
CATENUM = len(cateCount)
print(cateCount)
# 测试一篇文章
# with open("C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/result7/诛仙/test/20.txt", encoding='utf-8') as fp:
# string = fp.read()
# vj=Vnb(string,categories)
# 对所有文章进行分类
gmatrix = [[[0] for j in range(CATENUM)] for i in range(CATENUM)]
classify_all_texts(ROOTPATH, gmatrix)
# 计算准确率和召回率
cal_precision_and_recall(gmatrix)
SVM(支持向量机)分类器:
操作过程利用了libsvm工具包。
实验步骤:
首先利用create_train_test_File.py将训练集和测试集转换成libsvm支持的数据类型,产生train_tfidf_File.txt和test_tfidf_File.txt。
其次运行train.py调用libsvm库进行模型的训练,然后test.py对训练好的模型进行测试,输出测试结果,包括混淆矩阵和每一类的准确率、召回率、F测度,以及总的准确率、召回率、F测度。
实验结果:
SVM分类器结果:
混淆矩阵
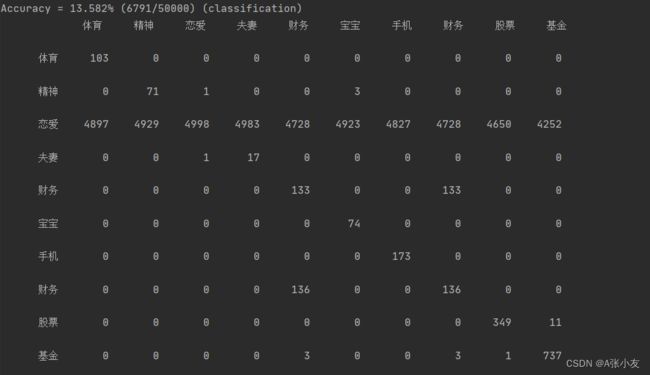
准确率、召回率、F测度
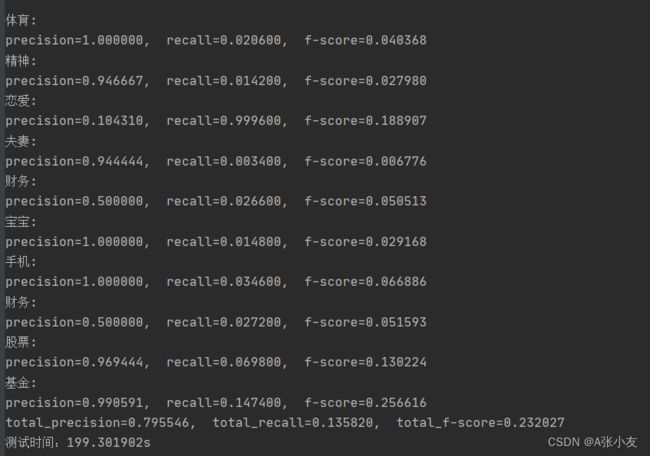
实验总结:
通过复现实验,了解到了文本分类的整体流程。从实验数据的搜集、文本格式的转换处理,到分词并去除停用词,生成词典汇总。这些文本分析的前期工作,以及SVM分类器的实现。对于各个流程的实现有了初步的认识。在实验的过程中,我了解到了一些数据预处理的方法,对于分类算法的原理也有了认识与了解,接触了机器学习中的SVM分类器,同时还按照输出混淆矩阵来观察分类器的分类结果和通过计算准确率和召回率来对分类器性能进行评估。
附件1
Traceback (most recent call last):
File "", line 1, in
File "D:\Python\PyCharm\PyCharm 2020.1\plugins\python\helpers\pydev\_pydev_bundle\pydev_umd.py", line 197, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "D:\Python\PyCharm\PyCharm 2020.1\plugins\python\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/beiyesi.py", line 169, in
classify_all_texts(ROOTPATH, gmatrix)
File "C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/beiyesi.py", line 120, in classify_all_texts
vj = Vnb(string, categories)
File "C:/Users/17974/Desktop/restart/graduate/Code/TextClassification-main/beiyesi.py", line 72, in Vnb
tans = tans + math.log(P(word, j) * idf, 10)
ValueError: math domain error